Self-Distillation from the Last Mini-Batch for Consistency Regularization中文版
Self-Distillation from the Last Mini-Batch for Consistency Regularization
从上一个小批量自发蒸馏,实现一致性正则化
摘要
知识蒸馏(Knowledge distillation,KD)展示了强大的潜力,作为一种强有力的正则化策略,通过利用学习的样本级软目标来提升泛化能力。然而,在现有的知识蒸馏中,使用复杂的预训练教师网络或一组同行学生既耗时又计算成本高昂。已经提出了各种自我蒸馏方法以实现更高的蒸馏效率。然而,它们要么需要额外的网络架构修改,要么难以进行并行化。
为了应对这些挑战,我们提出了一种高效可靠的自我蒸馏框架,名为“最后小批次自我蒸馏”(Self-Distillation from Last Mini-Batch,DLB)。具体来说,我们通过限制每个迷你批次的一半与上一次迭代一致来重新安排这些顺序采样,同时,剩下的一半将与即将到来的迭代一致,之后,前一半迷你批次将即时蒸馏上一次迭代中生成的软目标。我们提出的机制引导了训练的稳定性和一致性,使其对标签噪声具有鲁棒性。此外,我们的方法易于实现,无需额外的运行时内存或需要模型结构修改。在三个分类基准数据集上的实验结果表明,我们的方法能够始终胜过具有不同网络架构的最先进自我蒸馏方法。此外,我们的方法显示出与增强策略的强大兼容性,能够获得额外的性能提升。代码可在 https://github.com/Meta-knowledge-Lab/DLB 找到。
1.Introduction
知识蒸馏(Knowledge Distillation,KD)最初由Bucilua等人[2]提出,后来由Hinton等人[10]推广。许多先前的研究已经证明了知识蒸馏在各种学习任务中提升泛化能力的成功。例如,在网络压缩的情况下,广泛使用两阶段离线知识蒸馏,将来自繁琐预训练模型的暗知识传递给从教师的中间特征映射[21]、logits[10]、注意力图[40]或辅助输出[43]中学习的轻量级学生模型。然而,训练高容量的教师网络严重依赖于大量的计算资源和运行内存。为了缓解对静态教师耗时的准备工作,引入了在线蒸馏[44],其中一组同行学生相互学习。在线蒸馏实现了与离线蒸馏相同的性能改进,但计算效率更高。因此,许多后续工作将这一线路扩展为更强大的自组教师[3,8,14,33]。知识蒸馏的其他应用包括半监督学习、领域自适应、迁移学习等[18,26,28]。本文的主要范围集中在知识蒸馏范式本身。
传统的知识蒸馏方法,无论是在线还是离线的,都取得了令人满意的经验性能[24]。然而,现有的知识蒸馏方法在知识传输效率方面存在障碍[35]。此外,高计算和运行内存成本限制了它们部署到移动手机、数码相机等终端设备上[4]。为了应对这些限制,自我知识蒸馏受到越来越多的关注,它使得学生模型能够从自身中蒸馏知识。自我知识蒸馏中缺乏复杂的预训练教师和一组同行学生,导致在训练效率方面只有边际改进。其中一种流行的自我蒸馏形式,比如“做自己的老师”(Be Your Own Teacher,BYOT),需要进行大量的网络架构修改,这大大增加了它们推广到各种网络结构上的难度[19,32,43]。在另一条线路中,历史信息,包括先前训练的logits或模型快照,被利用来构建一个虚拟教师,作为自我蒸馏的额外监督信号。最初,Born Again Networks (BAN) 按顺序蒸馏具有相同参数的网络作为其最后一代[7]。快照蒸馏取得的一个进步是从先前的小代数,即一代中的几个时期中获得次要信息[36]。这种虚拟教师的更新频率在渐进式自我知识蒸馏[12]和回顾学习[5]中进一步提高到时代级别。然而,现有的自我知识蒸馏方法存在以下问题需要解决。首先,来自上一次迭代的最即时信息被丢弃。此外,存储过去模型的快照会消耗额外的运行内存成本,并随后增加并行化的难度[36]。最后,每次向后传播中梯度的计算与每个数据批次上两次前向过程相关联,导致计算冗余和低计算效率。
为解决现有自我知识蒸馏方法中的这些挑战,我们提出了一种简单而高效的自我蒸馏方法,称为“最后小批次自我蒸馏”(Self-Distillation from Last Mini-Batch,DLB)。与现有的自我知识蒸馏方法相比,DLB具有计算效率高、节省运行内存的特点,只存储上一次迭代产生的软目标,使得其在部署和并行化上更为简单。每个数据实例的前向处理都伴随着一次反向传播过程,减少了计算冗余。与最新技术相比,主要的不同点总结在表1中。DLB为自我蒸馏产生了即时的样本级平滑标签。利用上一次迭代的软预测,我们的方法为每个训练样本提供了最即时的蒸馏。DLB的成功归功于从最即时历史生成的软目标进行蒸馏,以强化训练的一致性和稳定性。更具体地说,在训练阶段,目标网络在每个小批次中扮演着教师和学生的双重角色。作为教师,在下一次迭代中提供软目标以规范自身。作为学生,它从上一次迭代中生成的平滑标签进行蒸馏,并最小化监督学习目标,比如交叉熵损失。
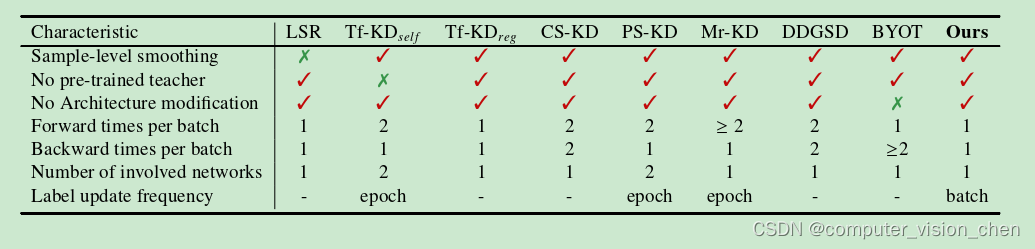
表1. 在计算成本和平滑度方面与最新技术的比较。我们将我们的方法与标签平滑正则化[27]、无教师知识蒸馏(Tf-KDself、Tf-KDreg)[37]、
类别自我知识蒸馏(CS-KD)[39]、渐进式自我知识蒸馏(PS-KD)[12]、记忆回放知识蒸馏(Mr-KD)[30]、数据失真引导的自我知识蒸馏(DDGSD)
[35]、做自己的老师(BYOT)[43] 进行了比较。
我们选择了六种代表性的主干CNN进行评估,包括ResNet-18、ResNet-110[9]、VGG-16、VGG-19[25]、DenseNet[11]和WideResNet[41]。实验结果表明,我们的DLB可以持续改善泛化能力。我们还在受损数据上测试了DLB的稳健性。DLB对受损数据的训练一致性和稳定性导致了更高的泛化能力。主要贡献有三个方面:
? 我们提出了一种简单但高效的一致性正则化方案,基于自我知识蒸馏,名为DLB。我们的方法无需对网络架构进行修改,实现时需要的额外计算成本和运行时内存都非常少。利用来自上一次迭代的最新更新,我们的DLB易于实现并行化。值得注意的是,该方法也不依赖特定模型或任务。
? 在三个常用的分类基准数据集上进行的全面实验结果展示了不同模型上的一致泛化改进。我们还在经验上证明了DLB与各种增强策略的兼容性。
? 我们系统地分析了我们方法对训练动态的影响。具体来说,其正则化效果的成功归功于利用即时样本级平滑标签引导训练一致性。在标签受损的环境下,一致性效应进一步增强,表现出对标签噪声的强大稳健性。这些实证发现可能为理解知识蒸馏的影响打开新的方向。
2.Related Works
知识蒸馏。知识蒸馏(Knowledge Distillation,KD)旨在将“知识”,如logits或中间特征映射,从高性能的教师模型传输到轻量级的学生网络[2,10]。尽管它在泛化方面具有竞争力的性能改进,但预训练复杂的教师模型需要额外的训练时间和计算成本。另一种形成经济蒸馏的方式被称为相互学习,也称为在线蒸馏,其中一组学生相互学习[44]。这个想法被许多后续工作所推广[3,14,33]。但是,在对等学习中的优化涉及多个网络,这需要额外的内存来存储所有参数。
自我知识蒸馏。为增强知识传递的效率和有效性,提出了自我知识蒸馏(Self Knowledge Distillation,SKD)来利用自身的知识,而无需额外网络的参与[31]。构建SKD模型有三种流行方式:1)基于数据失真的自我蒸馏[15,35],2)利用历史信息作为虚拟教师,3)在辅助头之间进行蒸馏[17,43]。然而,第一种方式在于数据增强效率上存在一定依赖性。第二种方式错过了来自上一次小批次的最新更新。而最后一种方式需要对网络架构进行大量修改,增加了其部署的难度。作为正则化的蒸馏。知识蒸馏(KD)在许多任务中被广泛使用,比如模型压缩、半监督学习、领域自适应等[18,26,28]。然而,对KD成功的理论分析仍然是一个巨大挑战。最近,Yuan等人将KD的成功归因于其作为从LSR(标签平滑正则化)视角提供样本级软目标的正则化效果[37]。这揭示了将KD应用于正则化领域的巨大潜力。在这一领域中,类别自我知识蒸馏(CS-KD)通过消除两批同类别样本预测之间的一致性来设计[39]。渐进式自我知识蒸馏(PS-KD)与我们的工作更相似,它逐渐从上个时期蒸馏过去的知识,以软化当前时期的硬目标[12]。记忆回放知识蒸馏(Mr-KD)通过存储一系列被放弃的网络备份进行扩展PS-KD[30]。然而,实施PS-KD或Mr-KD都需要额外的GPU内存来存储历史模型参数或者整个过去预测结果在硬盘上。前一种策略对于像深度WRN[41]这样的大模型来说计算成本很高,而后一种策略在训练像ImageNet[23]这样大型数据集时效率低下。上述缺点导致了训练效率低下,以及在移动电话、数码相机等终端设备上的实现难度[4],限制了其在正则化方面的应用。另一方面,这些方法缺乏来自最后几个小批次的最新信息。为了应对这些不足,我们提出了一种新颖的自我蒸馏框架,名为DLB,将在以下部分详细阐述。
3.Methods
3.1.Preliminary
在这项工作中,我们以监督分类任务作为案例研究。为了清晰表示,我们将一个包含K类标签的数据集表示为D={(xi,yi)}Ni=1,其中N是训练实例的总数。在每个小批次中,一个包含n个样本的批次B={(xi,yi)}ni=1?D通过数据扭曲?进行增强,得到扭曲图像集合B?={(?(xi),yi)}ni=1。然后,它们被输入到目标神经网络hθ中,优化交叉熵损失函数,其定义如下:
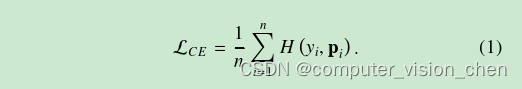
待更新
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!