selenium自动化(中)
显式等待与隐式等待
简介
在实际工作中等待机制可以保证代码的稳定性,保证代码不会受网速、电脑性能等条件的约束。
等待就是当运行代码时,如果页面的渲染速度跟不上代码的运行速度,就需要人为的去限制代码执行的速度。
在做 Web 自动化时,一般要等待页面元素加载完成后,才能执行操作,否则会报找不到元素等各种错误,这样就要求在有些场景下加上等待。
最常见的有三种等待方式:隐式等待、显式等待、强制等待,下面介绍以下这三种等待方式。
隐式等待
设置一个等待时间,轮询查找(默认 0.5 秒)元素是否出现,如果没出现就抛出异常。这也是最常见的等待方法。
隐式等待的作用是全局的,是作用于整个 session 的生命周期,也就是说只要设置一次隐式等待,后面就不需要设置。如果再次设置隐式等待,那么后一次的会覆盖前一次的效果。
当在 DOM 结构中查找元素,且元素处于不能立即交互的状态时,将会触发隐式等待。
self.driver.implicitly_wait(30)
显式等待
显式等待是在代码中定义等待条件,触发该条件后再执行后续代码,就能够根据判断条件进行等待。程序每隔一段时间进行条件判断,如果条件成立,则执行下一步,否则继续等待,直到超过设置的最长时间。核心用法如下:
# 导入显式等待
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions
...
# 设置10秒的最大等待时间,等待 (By.TAG_NAME, "title") 这个元素点击
WebDriverWait(driver, 10).until(
expected_conditions.element_to_be_clickable((By.TAG_NAME, "title"))
)
...
这里通过导入 expected_conditions 这个库来满足显式等待所需的使用场景,但是 expected_conditions 库并不能满足所有场景,这个时候就需要定制化开发来满足特定场景。
实战演示
假设:要判断某个元素超过指定的个数,就可以执行下面的操作。
def ceshiren():
# 定义一个方法
def wait_ele_for(driver):
# 将找到的元素个数赋值给 eles
eles = driver.find_elements(By.XPATH, '//*[@id="site-logo"]')
# 放回结果
return len(eles) > 0
driver = webdriver.Chrome()
driver.get('https://ceshiren.com')
# 显式等待10秒,直到 wait_ele_for 返回 true
WebDriverWait(driver, 10).until(wait_ele_for)
强制等待
强制等待是使线程休眠一定时间。强制等待一般在隐式等待和显式等待都不起作用时使用。示例代码如下:
# 等待十秒
time.sleep(10)
实战演示
访问测试人社区(https://ceshiren.com),点击分类,然后点击开源项目:

当点击分类时,元素还未加载完成,这里就需要隐式等待。在点击开源项目时,元素已加载完成,但是还处在不可点击的状态,这时要用到显式等待。
web控件定位与常见操作
简介
在做 Web 自动化时,最根本的就是操作页面上的元素,首先要能找到这些元素,然后才能操作这些元素。工具或代码无法像测试人员一样用肉眼来分辨页面上的元素。那么要如何定位到这些元素,本章会介绍各种定位元素的方法。
web控件定位
通过id
Selenium 自带 id 定位,可以通过元素的 id 属性进行定位,以下代码演示。
driver.find_element(By.ID,'query')
 通过name
通过name
Selenium 自带 name 定位,可以通过元素的 name 属性进行定位,以下代码演示。
driver.find_element(By.NAME,'query')
通常来说 name 属性与 id 属性在页面中唯一,推荐使用这两个属性进行定位。
通过XPath
XPath 是一个定位语言,英文全称为:XML Path Language,用来对 XML 上的元素进行定位,但也适用于 HTML,下面来看一个例子。
要定位的元素是Sogou首页的搜索输入框。
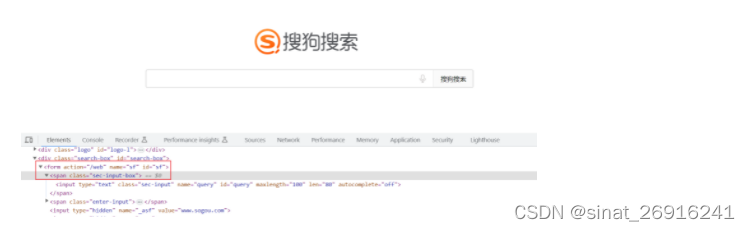
首先寻找 id 为 sf 的 form 元素,然后再寻找它的子元素 span,span 的 class 属性为?sec-input-box,最后找 span 的子元素 input,以下代码演示。
driver.find_element(By.XPATH,"//form[@id='sf']/span[@class='sec-input-box']/input")
下面的定位也可以找到这个 input,请注意,这里使用了双斜杠//,它可以找到子孙节点,而但斜杠/只能找到子节点,以下代码演示。
driver.find_element(By.XPATH,"//form[@id='sf']//input[@id='query']")
XPath 表达式更多内容可参考下面表格。
| 表达式 | 描述 |
|---|---|
| nodename | 选取此节点的所有子节点。 |
| / | 从根节点选取。 |
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。 |
| . | 选取当前节点。 |
| .. | 选取当前节点的父节点。 |
| @ | 选取属性。 |
如何检验 XPath 定位是否正确?可以使用 chrome 的检查模式 -> Console,输入$x('XPath 表达式')即可。
通过css_selector
XPath 可以定位绝大多数元素,但是XPath采用从上到下的遍历模式,速度并不快,而 css_selector 采用样式定位,速度要优于 XPath,而且语法更简洁。下面是 Selenium 使用 css_selector 的例子。
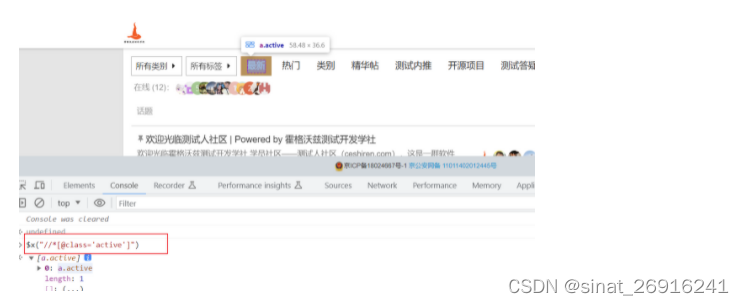
css_selector 找到 class 属性为 active 的元素,然后?>?表示找 class 属性为 active 的元素的子节点,以下代码演示。
driver.driver.find_element(By.CSS_SELECTOR,'.logo-big')
下表列出了常用的 css_selector 表达式的用法。
| 表达式 | 描述 |
|---|---|
| .intro | class="intro" 的所有元素 |
| #firstname | id="firstname" 的所有元素 |
| a[target=_blank] | 具有属性 target="_blank" 的所有 a 元素 |
| p:nth-child(2) | 属于其父元素的第二个 p 元素 |
使用 Chrome 的检查模式 -> Console 也可以在当前页面检测 css_selector 是否正确,输入$('css selector 表达式')即可。

通过link
元素中会出现文字,比如下面的分类,可以利用这段文字进行定位,以下是代码演示。

driver.driver.find_element(By.LINK_TEXT, '欢迎光临测试人社区 | Powered by 霍格沃兹测试开发学社')
也可以采用部分匹配方式,不必写全:“欢迎光临”、“欢迎光临测试人社区”、“霍格沃兹”,以下是代码演示。
driver.find_element(By.PARTIAL_LINK_TEXT, '测试人社区')
要注意partial_link_text 与 link_text 的区别,partial_link_text 不用写全,只需写部分即可,比如上面使用“霍格沃兹”即可匹配到“欢迎光临霍格沃兹测试学院”。
通过tag_name
DOM 结构中,元素都有自己的 tag,比如 input tag,button tag,anchor tag 等等,每一个 tag 拥有多个属性,比如 id,name,value class等等。
下面的高亮部分就是 tag:
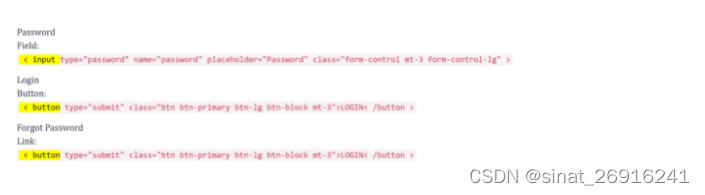
可以使用 tag 进行定位:
driver.driver.find_element(By.TAG_NAME,'input')
要注意,尽量避免使用 tag_name 定位元素,因为有大量重复的元素!
通过class_name
可以通过元素的 class 属性值进行定位:
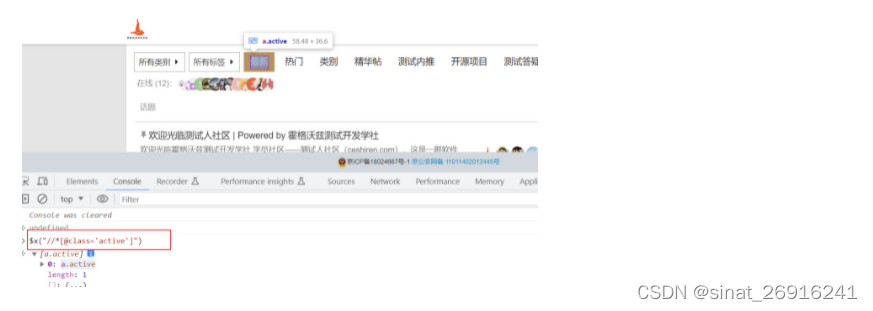
这里的 active 用的就是上图 class 的值。
driver.driver.find_element(By.CLASS_NAME, 'active')
推荐使用

1)ID/Name 是最安全的定位选项。根据 W3C 标准,它在页面中是唯一的,ID 在树结构中也是唯一的。 2)CSS Selector 语法简洁,搜索速度快于 XPath。 3)XPath 定位功能强大,采用遍历搜索,速度略慢。 4)link,class name, tag name:不推荐使用,无法精准定位。
常见操作
Selenium 常见操作有:
- 输入、点击、清除。
- 关闭窗口、浏览器。
- 获取元素属性。
- 获取网页源代码、刷新页面。
- 设置窗口大小。
输入、点击、清除
输入、点击、清除在 Selenium 中对应的方法分别是 send_keys、click、clear,以下代码演示。
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('http://www.baidu.com')
driver.find_element(By.NAME,'wd').send_keys('霍格沃兹测试学院')
driver.find_element(By.ID,'su').click()
driver.find_element(By.NAME,'wd').clear()
关闭窗口、浏览器
关闭当前句柄窗口(不关闭进程)close(),关闭整个浏览器进程?quit(),以下代码演示。
#导入对应的依赖
from selenium import webdriver
#初始化webdriver
driver = webdriver.Chrome()
#访问网站
driver.get('http"//www.baidu.com')
#关闭当前窗口
driver.close()
#关闭浏览器
driver.quit()
获取元素属性
获取元素标签上的属性 get_attribute('value'),元素的坐标 location,元素的大小 size,以下代码演示。
import logging
from selenium import webdriver
def test_baidu():
driver = webdriver.Chrome()
driver.get('https://www.baidu.com')
search = driver.find_element(By.ID,'su')
logging.basicConfig(level=logging.INFO)
logging.info(search.get_attribute('value'))
#获取search的value属性值并打印
logging.info(search.get_attribute('value'))
#打印search的位置坐标
logging.info(search.location)
#打印search的元素大小
logging.info(search.size)
输出结果为:
INFO:root:百度一下
INFO:root:百度一下
INFO:root:{'x': 844, 'y': 188}
INFO:root:{'height': 44, 'width': 108}
获取网页源代码、刷新页面
网页源代码 page_source,刷新页面 refresh()。
import logging
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('http"//www.baidu.com')
#刷新页面
driver.refresh()
logging.basicConfig(level=logging.INFO)
#打印当前页面的源代码
logging.info(driver.page_source)
设置窗口大小
设置窗口大小主要有最小化、最大化和自定义设置窗口具体的大小。
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('http"//www.baidu.com')
#最小化窗口
driver.minimize_window()
#最大化窗口
driver.maximize_window()
#将浏览器设置为1000*1000的大小
driver.set_window_size(1000, 1000)#导入依赖
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions
from selenium.webdriver.support.wait import WebDriverWait
class TestHogwarts():
def setup(self):
self.driver = webdriver.Chrome()
self.driver.get('https://ceshiren.com/')
# 加入隐式等待
self.driver.implicitly_wait(5)
def teardown(self):
# 强制等待
time.sleep(10)
self.driver.quit()
def test_hogwarts(self):
# 点击类别
self.driver.find_element(By.CSS_SELECTOR, '[title="按类别分组的所有话题"]').click()
# 元素定位,这里的category_name是一个元组。
category_name = (By.XPATH, "//*[@class='category-text-title']//*[text()='开源项目']")
# 加入显式等待
WebDriverWait(self.driver, 10).until(
expected_conditions.element_to_be_clickable(category_name))
# 点击开源项目
self.driver.find_element(*category_name).click()本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!