一键与图片对话!LLM实现图片关键信息提取与交互
本期文心开发者说邀请到飞桨开发者技术专家徐嘉祁,主要介绍了如何通过小模型与大模型的结合,解决数据分析中的问题。

项目背景
在智能涌现的大模型时代,越来越多的企业和研究机构开始探索如何利用大模型来提升工作效率,助力业务智能化转型。但其实小模型与大模型结合后,能够更加高效、低成本地解决业务中出现的问题,带给用户不一样的体验。我想分享的内容是小模型与大模型结合后产生的理解记忆逻辑和生成能力。
在工作场景下,普遍存在效率问题。比如要想了解一张股东持股数据图的最大值与最小值,但面对密密麻麻的数据,人眼排序出错率高。比如你是一位数据工程师,领导让你对数据进行分析,如何能更快地将图片数据转为JSON格式。
在日常生活中,也常常出现难以解决或耗时过长的问题。例如,购买进口产品,国内消费者最大的困扰在于看不懂英文说明书。有些人可能会使用手机拍照翻译来理解或使用说明书,但这无法从根本上解决问题。
在这一背景下,我们的项目应运而生。
在2023年的WAVE SUMMIT+深度学习开发者大会上,文心一言通过飞桨星河社区提供一整套开发机制,社区用户可以通过API和SDK使用文心大模型的基础能力,并支持插件、多工具智能编排开发,创造AI原生应用。文心一言强大的能力也使得多个模态贯通成为可能,亦给我带来更多延伸思考:如果数据的呈现形式不是文档而是图片,我们是否依旧能对图片中的数据进行分析,甚至将其绘制成饼状图呢?
对此,我这次尝试给出的解决方案是使用小模型加大模型,也就是PP-OCR加上文心一言带来新的体验,也可以使得文心一言的应用范围更加广泛。
项目实现流程
该项目是如何实现的呢?
首先,用户上传图片,通过PP-OCR进行文本提取,将结果结合Prompt上传文心一言。文心一言同时对第一轮对话输入的Prompt和PP-OCR进行初步分析,再反馈结果给用户。
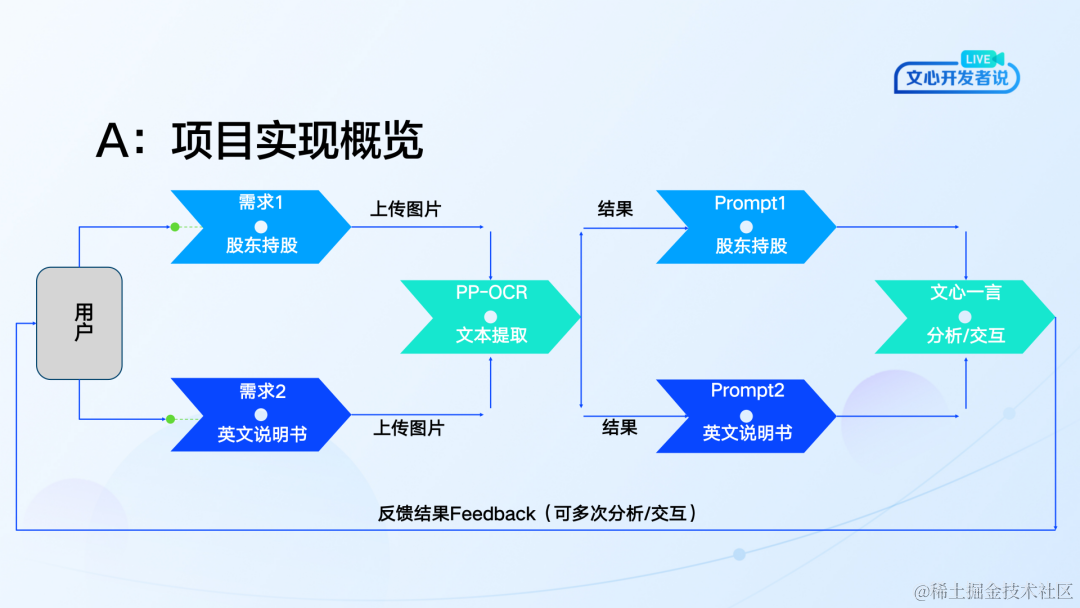
项目前储备
PP-OCR
PP-OCR应用领域广泛,如自动化录入、数据统计、档案管理等。它可以将纸质文档快速准确地转化为数字化信息,极大地提升了办公效率与工作便利性。然而,PP-OCR还存在着一些挑战,例如对于手写字体、复杂排版或图像质量的识别准确性,仍存在局限。该项目使用的是PP-OCR v3的版本,在PP-OCR v2版本的基础上有所升级,能够优化后续开发流程。

PP-OCR v3效果
飞桨星河社区 ERNIE SDK
ERNIE SDK提供便捷易用的接口,可以调用文心一言的能力,包含文本创作、通用对话、语义向量、Al作图等。
环境配置
环境配置包括星河社区的基础平台与环境,Python 3.7的版本,PaddlePaddle2.1.2,ERNIE SDK。
案例
接下来将以两个案例作为示意,说明应用的开发步骤。
股东持股
PP-OCR的配置
首先,安装PP-OCR,默认的是PP-OCR v3的版本。
!pip install paddleocr -i https://mirror.baidu.com/pypi/simple
通过以下这段代码检查是否有PP-OCR的数据集,中间需要选择股东持股的照片,因此需要先下载PP-OCR的数据集再进行解压。
import os
file_path = "ppocr_img.zip"
if os.path.isfile(file_path):
print(file_path, "OK")
else:
!wget https://paddleocr.bj.bcebos.com/dygraph_v2.1/ppocr_img.zip
file_path = "ppocr_img/imgs/00015504.jpg" #这里选择的是股东持股的图片,后面完成其他项目的时候需要改为说明书的图片
if os.path.isfile(file_path):
print(file_path, "OK")
else:
!unzip ppocr_img.zip
print("unzip OK!")
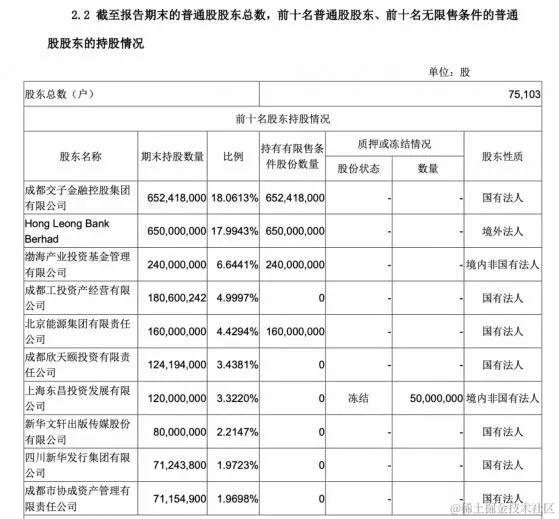
其次,将股东持股的图片路径传给变量,确认输入图片是否正确。
from IPython import display
display.Image(filename=file_path, width=640) #看看待处理图片
随后,PP-OCR对图片的文本数据进行提取。
#图片OCR识别
from paddleocr import PaddleOCR, draw_ocr
# Paddleocr目前支持的多语言语种可以通过修改lang参数进行切换
# 例如`ch`, `en`, `fr`, `german`, `korean`, `japan`
ocr = PaddleOCR(use_angle_cls=True, lang="ch")
img_path = file_path
result = ocr.ocr(img_path, cls=True)
for idx in range(len(result)):
res = result[idx]
for line in res:
print(line)
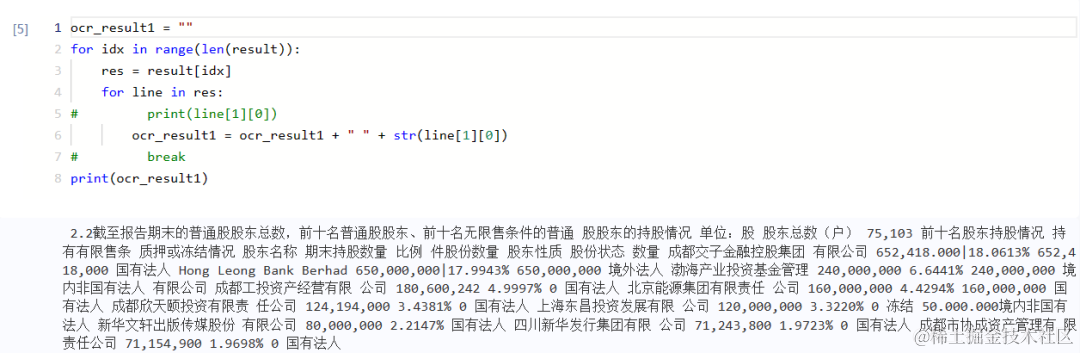
由于直接使用OCR输出结果进行文本分析和抽取的效果不佳,并且存在大量无关内容,影响大模型的处理速度,因此需要处理将识别出的内容,删除无关信息,留下关键数据。初步处理数据后,OCR输出的结果被存储在变量ocr_result1中,这是进行内容整理的基础。
ocr_result1 = ""
for idx in range(len(result)):
res = result[idx]
for line in res:
# print(line[1][0])
ocr_result1 = ocr_result1 + " " + str(line[1][0])
# break
print(ocr_result1)
与文心一言进行交互
首先,需要对Prompt进行设计,这一步会影响到文心一言输出的结果。本项目的Prompt设置为“你现在的任务是从OCR文字识别的结果中提取我指定的关键信息。OCR的文字识别结果使用符号包围,包含所识别出来的文字,顺序在原始图片从左至右、从上至下。我指定的关键信息使用符号包围。请注意OCR文字识别结果可能会存在长句子换行被切断、不合理的分词、对应错位等问题,你需要结合上下文语义进行综合判断,以抽取准确的关键信息,输出为JSON格式。”
如果希望获得更详细的信息,需要与文心一言进行多轮对话。那么需要将设计好的Prompt传给文心一言。
#多轮对话
model = 'ernie-bot'
messages = [{'role': 'user', 'content': "你现在的任务是从OCR文字识别的结果中提取我指定的关键信息。OCR的文字识别结果使用```符号包围,包含所识别出来的文字,顺序在原始图片中从左至右、从上至下。我指定的关键信息使用[]符号包围。请注意OCR的文字识别结果可能存在长句子换行被切断、不合理的分词、对应错位等问题,你需要结合上下文语义进行综合判断,以抽取准确的关键信息。输出为JSON格式。"}]
first_response = erniebot.ChatCompletion.create(
model=model,
messages=messages,
)
print(first_response.result)
接着,将OCR的结果传给文心一言,进行第二轮对话。第二轮对话的结果是基于第一轮对话的Prompt和第二轮输入的OCR的result。
messages.append({'role': 'assistant', 'content': first_response.result})
messages.append({'role': 'user', 'content': ocr_result1})
second_response = erniebot.ChatCompletion.create(
model=model,
messages=messages,
)
print(second_response.result)
随后便可以开启第三轮对话,此处Prompt设计为“请你帮我分析前十名股东持股情况中,持股比例最多的是哪个?”
messages.append({'role': 'assistant', 'content': second_response.result})
messages.append({'role': 'user', 'content': "请你帮我分析前十名普通股东持股情况中,持股比例最多的是哪个?"})
third_response = erniebot.ChatCompletion.create(
model=model,
messages=messages,
)
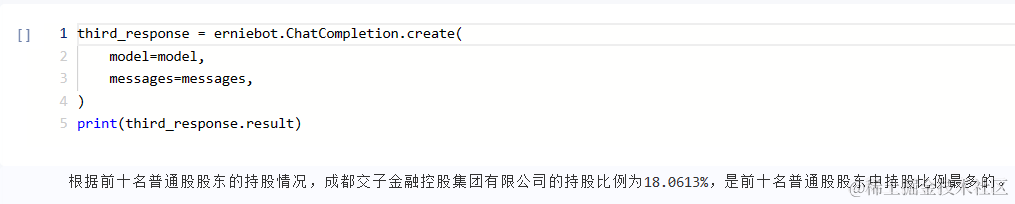
print(third_response.result)
根据提供的信息,前十名普通股东持股情况中,持股比例最多的是“成都交子金融控股集团有限公司”,其持股比例为18.0613%。可以看到,文心一言不仅对数据做出了初步处理,还对数据进行了分析,找出了占比最大值。
英文说明书
流程和股东持股基本一致,都是采用小模型加大模型的流程进行开发,需要对Prompt进行修改。第一步,将图片路径改成“说明书的图片路径”。
file_path = "/home/aistudio/sms.jpg" #这里选择的是说明书的图片
from IPython import display
display.Image(filename=file_path, width=600) #看看待处理图片
 第二步,对图片进行OCR识别。
第二步,对图片进行OCR识别。
#图片OCR识别
from paddleocr import PaddleOCR, draw_ocr
# Paddleocr目前支持的多语言语种可以通过修改lang参数进行切换
# 例如`ch`, `en`, `fr`, `german`, `korean`, `japan`
ocr = PaddleOCR(use_angle_cls=True, lang="en")
img_path = file_path
result = ocr.ocr(img_path, cls=True)
for idx in range(len(result)):
res = result[idx]
for line in res:
print(line)
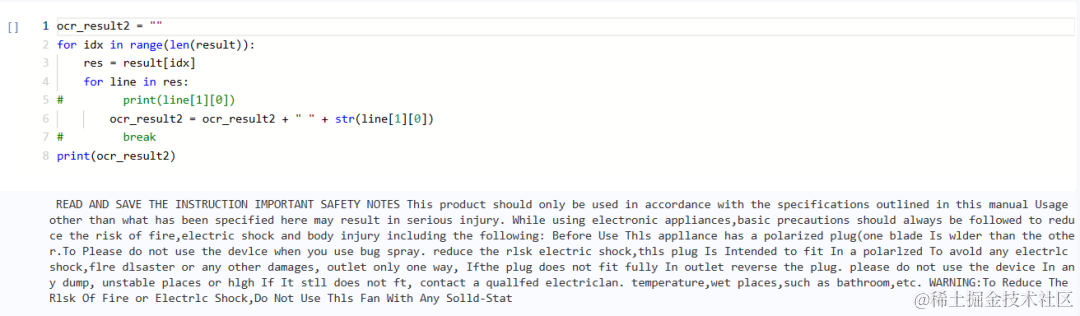
与第一个案例不同的是,该段内容由大段英文组成,需要再次对输出的结果进行处理,删除无关内容,将结果命名为OCR result 2。
第三步,对输出的result进行处理。
ocr_result2 = ""
for idx in range(len(result)):
res = result[idx]
for line in res:
# print(line[1][0])
ocr_result2 = ocr_result2 + " " + str(line[1][0])
# break
print(ocr_result2)
第四步,设计Prompt,文心一言能够进行机器翻译,将result翻译成中文格式。接下来,可以进行多轮对话。
#多轮对话
model = 'ernie-bot'
messages = [{'role': 'user', 'content': "你现在的任务是从OCR文字识别的结果中提取我指定的关键信息。OCR的文字识别结果使用符号包围,包含所识别出来的文字,顺序在原始图片中从左至右、从上至下。我指定的关键信息使用[]符号包围。请注意OCR的文字识别结果可能存在长句子换行被切断、不合理的分词、对应错位等问题,你需要结合上下文语义进行综合判断,以抽取准确的关键信息。输出为JSON中文格式。"}]
first_response = erniebot.ChatCompletion.create(
model=model,
messages=messages,
)
print(first_response.result)
messages.append({'role': 'assistant', 'content': first_response.result})
messages.append({'role': 'user', 'content': ocr_result2})
second_response = erniebot.ChatCompletion.create(
model=model,
messages=messages,
)
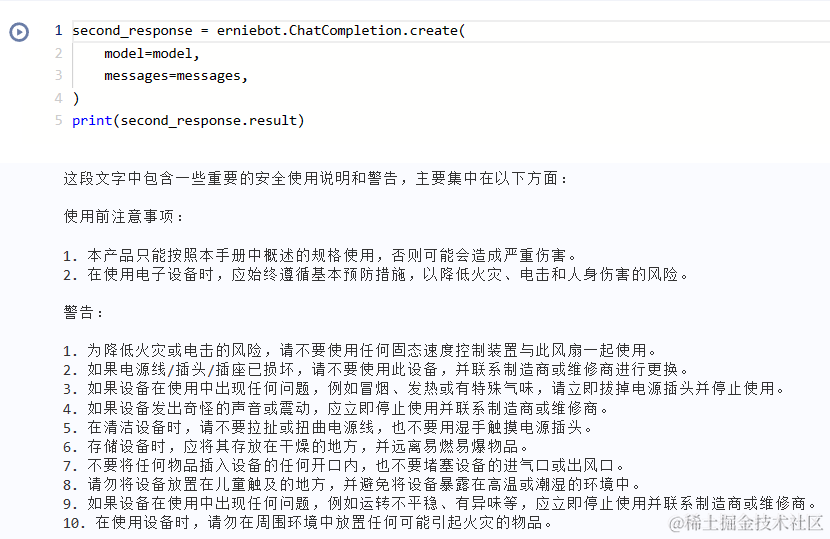
print(second_response.result)
```json
{
"重要安全说明": [
"仅按本手册中的说明使用该产品,否则可能导致严重伤害。",
"使用电子设备时,应始终遵循基本预防措施以减少火灾、电击和人身伤害的风险,包括以下内容:",
"使用前:请勿在浴室等潮湿位置使用该设备。",
"警告:为减少火灾或电击的风险,请勿将本风扇与任何固态速度控制装置一起使用。",
"清洁说明:请勿使用腐蚀性化学品清洁电源插头或电源线,以免造成损坏、电击或火灾。",
"存储说明:请将设备存放在干燥的地方,并远离易燃和可燃物品。",
"使用提示:请勿将设备放在热源(如炉子或任何有可燃气体泄漏的地方)附近。",
"使用限制:如果电源线或任何机器部件损坏,必须由制造商、其服务代理或合格人员更换,以避免危险。",
"限制使用:本产品所提供的线缆含有化学品,如果设备在运行时产生特殊气味,请勿在有自由基、铅或镉化合物的地方使用。",
"加州法规提案65:在使用后,请立即洗手。"
]
}```
此处,将Prompt设计为“上面这个产品是否可以放到潮湿的地方”,再提供给文心一言分析文本。
messages.append({'role': 'assistant', 'content': second_response.result})
messages.append({'role': 'user', 'content': "上面这个产品是否可以放到潮湿的地方?"})
third_response = erniebot.ChatCompletion.create(
model=model,
messages=messages,
)
print(third_response.result)
根据OCR文字识别结果,有一句话是“使用前:请勿在浴室等潮湿位置使用该设备。”因此,文心一言给出回答:“所以,这个产品不应该放在潮湿的地方,在使用电子设备时应该采取基本的预防措施。”文心一言不仅能基于文本提供答案,还会提供使用电子产品的建议。
总的来说,PP-OCR可以初步提取比较清晰的结果。
案例一:
案例二:
文心一言可以对数据进行预处理。例如案例一,将表格转化为图片中的格式。该技术能够极大地简化数据工程师的工作。
对话二基于上一轮提取的数据输出的结果,可以帮助用户更快了解图片的信息。

总结
针对数据转换,该项目采用PP-OCR技术识别图片的文本信息,借此更加快速、准确地提取数据,规避手动输入造成的麻烦与错误。随后对获取的数据进行排序,找出最大值与最小值,并以JSON格式输出。该方法提高了数据处理和输出的效率。其次,文心一言能将英文说明书翻译为中文,并为用户解答具体问题、提供操作建议。因此,用户无需理解全篇说明书,只需询问特定问题,就能获得满意的答案。PP-OCR与文心一言的结合,使得大量数据处理更加高效,关键信息提取更加准确,同时解决了语言障碍所导致的产品使用问题,优化用户体验。这一项目展示了人工智能技术在解决生活和工作问题的巨大潜力,引领未来科技的发展方向。
其他解决方案
PaddleX中的PP-ChatOCRv2是一个融合了LLM大模型和OCR技术,用于进行通用文本图像智能分析的利器。该技术覆盖20+高频应用场景,支持5种文本图像智能分析能力和部署,包括通用场景关键信息抽取(快递单、营业执照和机动车行驶证等)、复杂文档场景关键信息抽取(解决生僻字、特殊标点、多页pdf、表格等难点问题)、通用OCR、文档场景专用OCR、通用表格识别。此外针对垂类业务场景,也支持模型训练、微调和Prompt优化。
欢迎在线体验:
https://aistudio.baidu.com/application/detail/10368
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!