python命令大全及说明,python命令大全下载
2024-01-01 23:44:03
大家好,本文将围绕python命令大全及说明展开说明,python命令大全下载是一个很多人都想弄明白的事情,想搞清楚python简单命令语句需要先了解以下几个事情。

Python有哪些常用但容易忘记的命令?
1 如何忽略报错信息
import warnings
warnings.filterwarnings('ignore')
2 Python常见绘图系列代码
在数据分析的过程中,经常会遇到一个很麻烦的问题,就是中文无法显示,这个困难真的会困扰很多同学包括我在内,还好终于找到了问题的解决办法,在之前的一篇博客中已经涉及到了,详情戳:机器学习 | 特征重要性判断
下面就详细分开的说下每种图该怎么画!
2.1 绘制对比箱线图
参数:
- 直接x和y即可。x表示分类型变量,y表示数值型变量
- data表示数据框
- 如果绘图希望箱子有顺序,就加上order这个参数!
p1 = sns.boxplot(x = 'type_now', y = '7_active_days', data=df, order=['高活','中活','低活','不活'])
plt.savefig('plot/3-1.png')
plt.show()
注:倒数第二行的命令是保存图片,具体看需求,最后一个命令是显示图片python使用turtle函数绘制树图形。有时候jupyter无法显示图片,还得再运行一下ok,有点玄学,不过在命令框的前面加上一个魔法命令就可以解决了:
%matplotlib inline
绘制后的效果见下图:
2.2 分区绘制图形
有时候希望画成1×2 或者 2×1的图形,具体如何实现呢?
代码:
f, (ax1,ax2) = plt.subplots(1, 2, figsize=(10, 6))
sns.distplot(df['event_columnx'], ax=ax1)
sns.distplot(df['event_columnx_now'], ax=ax2)
plt.savefig('plot/3-4.png')
plt.show()
参数:
- 首先是plt.subplots 注意有s 其中1 2 表示1行2列,即第一个参数为行数,第二个参数为列数。figsize调节大小。
- 在分图中加入参数ax,即ax=ax1或者ax2 表示具体位置!
效果:
2.3 绘制相关系数图(热图)
import seaborn as sns
import matplotlib.pyplot as plt
def test(df):
dfData = df.corr()
plt.subplots(figsize=(9, 9)) # 设置画面大小
sns.heatmap(dfData, annot=False, vmax=1, square=True, cmap="Blues")
plt.savefig('./相关系数图.png')
plt.show()
绘图后效果见下图:
2.4 绘制计数的条形图countplot
先上图:
起到的作用:
- 统计分类型变量1不同水平下各自有分类变量2的频数。绘制条形图!
- 是不是有点绕!看上面的图就懂了!还是很强的一个绘图函数
代码:
ax = sns.countplot(x = 'type', hue = 'type_now', data = df, order=['高活','中活','低活','不活'])
plt.savefig('plot/3-1-2.png')
plt.show()
参数:
- x:表示分类型变量1
- hue:表示分类型变量2
- data:数据框
- order:表示分类变量1的顺序
补充:
- 对于上图中标签和图形重叠在一起,有一种解决方式是调大图形的长和宽!具体见下图:

一开始加一行代码即可:
# 调整figsize
f, ax = plt.subplots(figsize=(12, 8))
2.5 直方图和核密度图的合体distplot
代码:
f, ax = plt.subplots(figsize=(10, 8))
sns.distplot(df['session_count'], kde=True)
plt.savefig('plot/3-3-3.png')
plt.show()
效果:
参数:
- kde=True 表示核密度估计的曲线也画出来!
- 直接displot
3 绘图函数封装
3.1 1×2的直方图封装
代码:
def PlotHis2(col1, col2, pic_name):
# 函数作用:绘制1×2的直方图
# col1:表示变量1
# col2:表示变量2
# pic_name:图片保存后的名称
# 注:其实更合适一点是加入数据框的名称
import numpy as np
np.set_printoptions(suppress=True)
f, (ax1,ax2) = plt.subplots(1, 2, figsize=(10, 6))
sns.distplot(df[col1], ax=ax1)
sns.distplot(df[col2], ax=ax2)
plt.savefig('plot/' + pic_name + '.png')
plt.show()
效果见下图:
3.2 1×2的对比箱线图封装
代码:
def PlotBox2(col1, col2, pic_name):
# 函数作用:绘制1×2的直方图
# col1:表示变量1
# col2:表示变量2
# pic_name:图片保存后的名称
# 注:其实更合适一点是加入数据框的名称
import numpy as np
np.set_printoptions(suppress=True)
f, (ax1,ax2) = plt.subplots(1, 2, figsize=(10, 6))
sns.boxplot(x = 'type_now', y=col1, data=df, ax=ax1, order=['高活','中活','低活','不活'])
sns.boxplot(x = 'type_now', y=col2, data=df, ax=ax2, order=['高活','中活','低活','不活'])
plt.savefig('plot/' + pic_name + '.png')
plt.show()
效果见下图:
3.3 1×2的【1+对数】对比箱线图封装
代码:
import numpy as np
def to_log(x):
return np.log(1+x)
def PlotBoxLog2(col1, col2, pic_name):
f, (ax1,ax2) = plt.subplots(1, 2, figsize=(10, 6))
log_col1 = 'log_' + col1
log_col2 = 'log_' + col2
df[log_col1] = df[col1].map(to_log)
df[log_col2] = df[col2].map(to_log)
sns.boxplot(x = 'type_now', y=log_col1, data=df, ax=ax1, order=['高活','中活','低活','不活'])
sns.boxplot(x = 'type_now', y=log_col2, data=df, ax=ax2, order=['高活','中活','低活','不活'])
plt.savefig('plot/' + pic_name + '.png')
plt.show()
效果见下图:
3.4 统计量计算的函数封装
代码:
def CalVar(col1, col2):
import numpy as np
np.set_printoptions(suppress=True)
cols = [col1, col2]
for col in cols:
print('变量 %s 描述统计计算结果如下:' % col)
print(df[col].describe())
print('--------********-------')
代码执行层面:
CalVar('event_columnx', 'event_columnx_now')
实现效果:
4 如何取消科学计数法
import numpy as np
np.set_printoptions(suppress=True)
5 删去几倍标准差之外的离群值
5.1 单变量独自剔除
函数代码:
def RemoveValue_sole(df_model, col, s):
# 其中s作用是统计总共有多少行记录被删去
r1 = df_model.shape[0]
v_mean = df_model[col].mean()
v_std = df_model[col].std()
thrhol = v_mean + 10 * v_std
df_model = df_model[df_model[col]<=thrhol]
r2 = df_model.shape[0]
s = s + r1 - r2
print('列 %s 删除10倍以上标准差的数值 共删除的行数为: %d ' % (col, r1-r2))
return s
实现剔除代码:
s = 0
for col in model_col:
# 其中model_col为事先定义好的需要剔除异常值的变量!
s = RemoveValue_sole(df_model, col, s)
print(s)
实现效果见下:
可以看到总共是4027个被单独剔除!但是df_model好像是不动的?
5.2 滚动剔除
啥叫滚动剔除?就是一个变量异常值被剔除之后,在这个被剔除异常值的数据框的基础之上再考虑下一个变量,继续下去!应用相较于第一种应该是广泛的!
代码:
def RemoveValue(df_model, col):
r1 = df_model.shape[0]
v_mean = df_model[col].mean()
v_std = df_model[col].std()
thrhol = v_mean + 10 * v_std
df_model = df_model[df_model[col]<=thrhol]
r2 = df_model.shape[0]
print('列 %s 删除10倍以上标准差的数值 共删除的行数为: %d ' % (col, r1-r2))
return df_model
滚动剔除代码:
for col in model_col:
df_model = RemoveValue(df_model, col)
# 每一次赋值返回均为df_model 这样就能起到滚动的作用!
print(df_model.shape)
实现效果见下: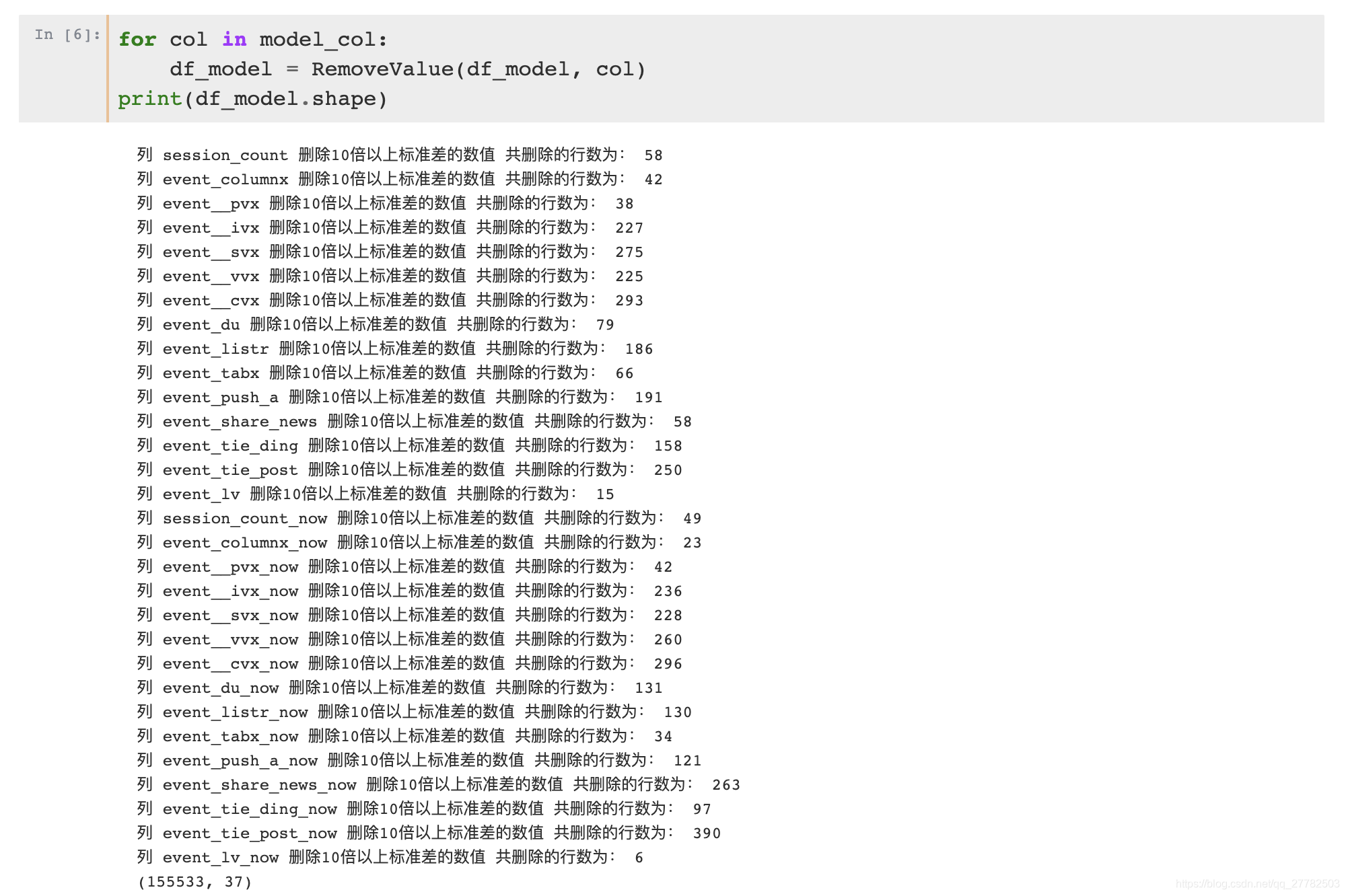
6 参考
- https://www.cnblogs.com/noahzn/p/4133252.html
- displot参考:https://www.jianshu.com/p/844f66d00ac1
- mac的jupyter绘图中文如何显示:机器学习 | 特征重要性判断_机器学习特征重要性排序-CSDN博客
文章来源:https://blog.csdn.net/i_like_cpp/article/details/135329930
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!