2021版吴恩达深度学习课程Deeplearning.ai 05序列模型 12.5
学习内容
05.序列模型
1.1 为什么用序列模型
1.序列模型常见的应用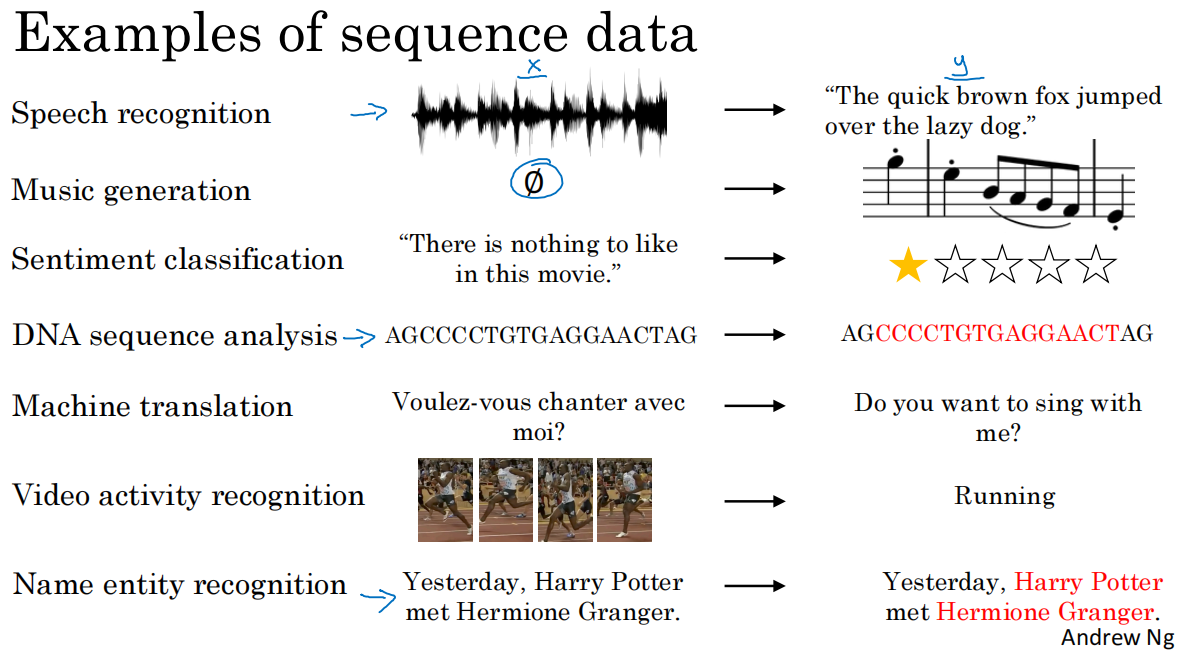
1.2 注释 notation
1.
*T_x(i)表示训练样本x(i)的序列长度,T_y(i)表示target(i)的序列长度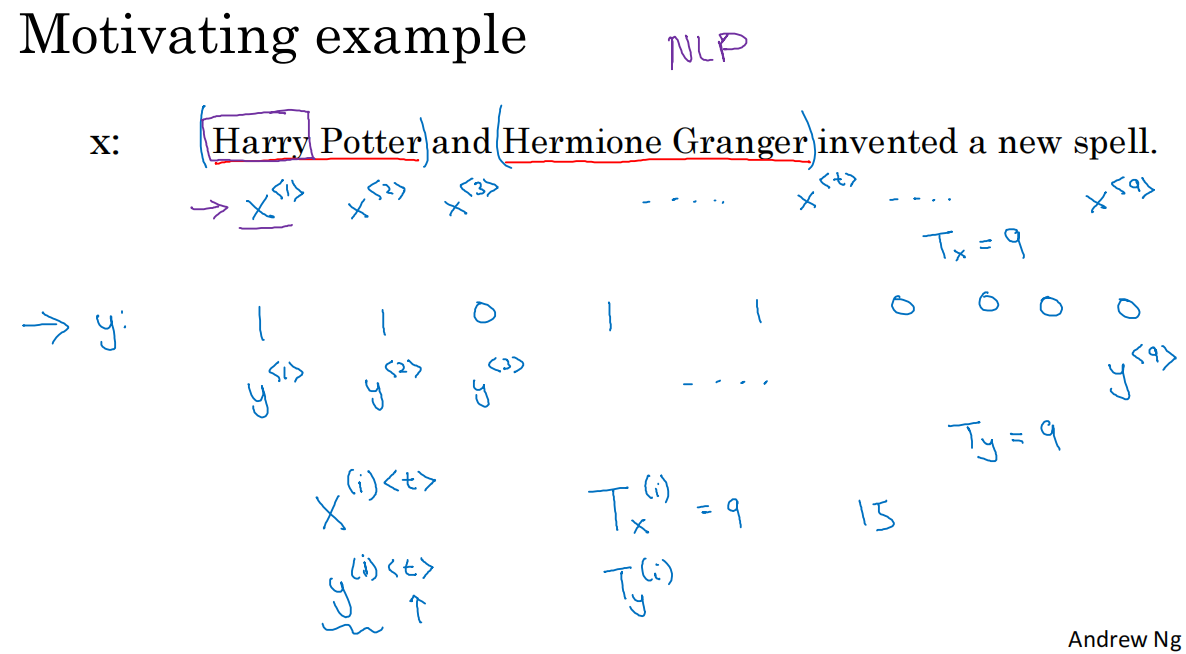
2.训练集表示单词的方式
*构建字典的方式
*在训练集中查找出现频率最高的单词
*网络搜集常用字典
3.如果遇到不在字典中的单词,需要创建一个新的标记,unknown word伪单词,用标记
1.3 循环神经网络模型
1.标准神经网络并不适合用于解决序列问题
不同的例子中输入输出数据的长度不一,虽然可以通过0-padding的方式解决,但不是好的表达方式
并不共享已学习的数据(如harry已识别出是人名,希望不用再次识别,但标准神经网络模型并不解决这一问题)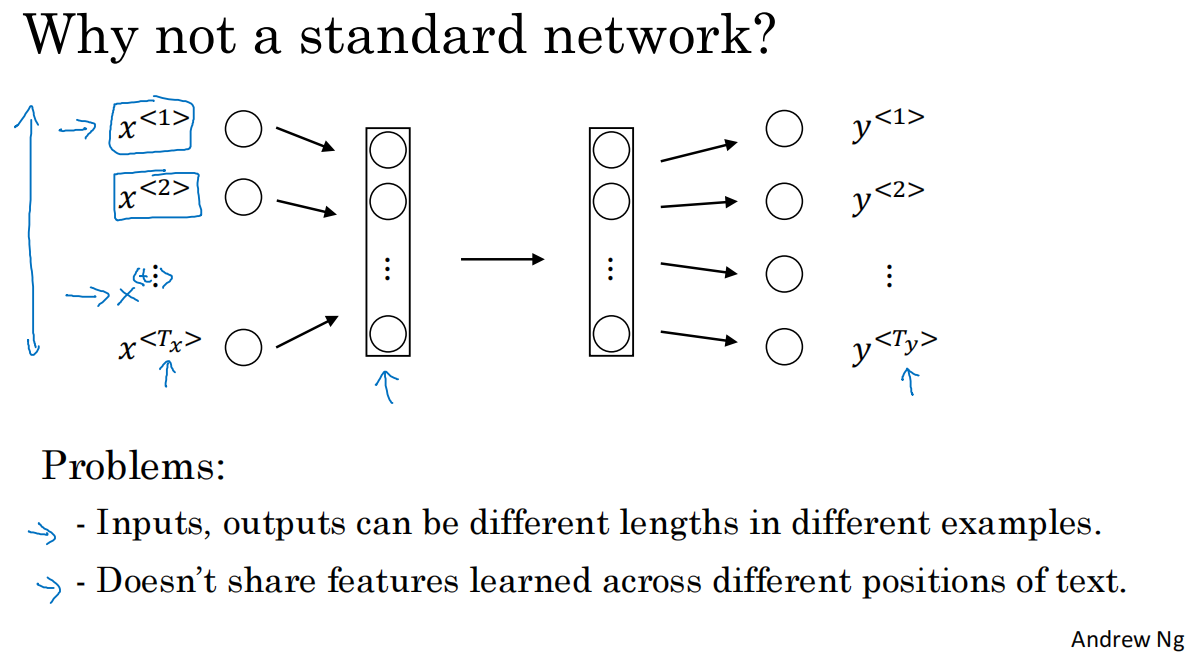
2.简单循环神经网络模型
在每一时间步t,根据输入单词x和上一时间步的激活值a,计算得到y
a<0>初始化为0向量是常见的选择
每个时间步的参数共享,激活值的水平联系由参数waa决定,输入与隐藏层的联系由参数wax决定,输出由wya决定
当前循环神经网络模型的缺点:只使用了当前序列之前的信息做出预测,如果存在如图的teddy示例,则无法判断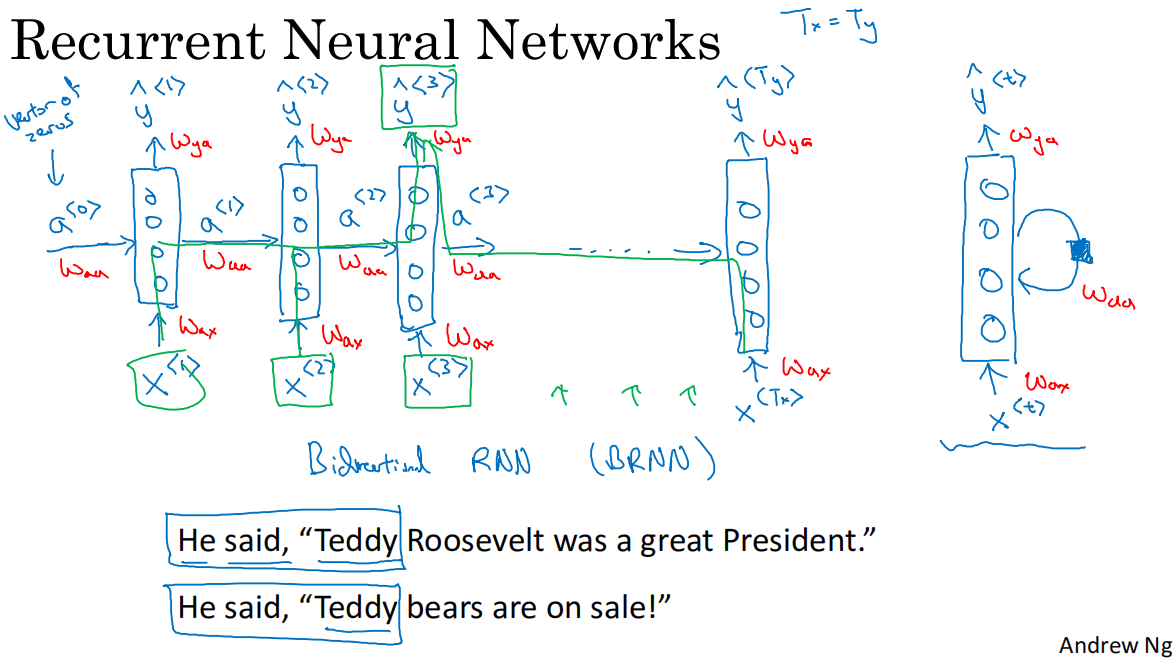
3.前向传播
a=g1(W_aaa+W_axx+b_a)
y_hat=g2(W_yaa+b_y)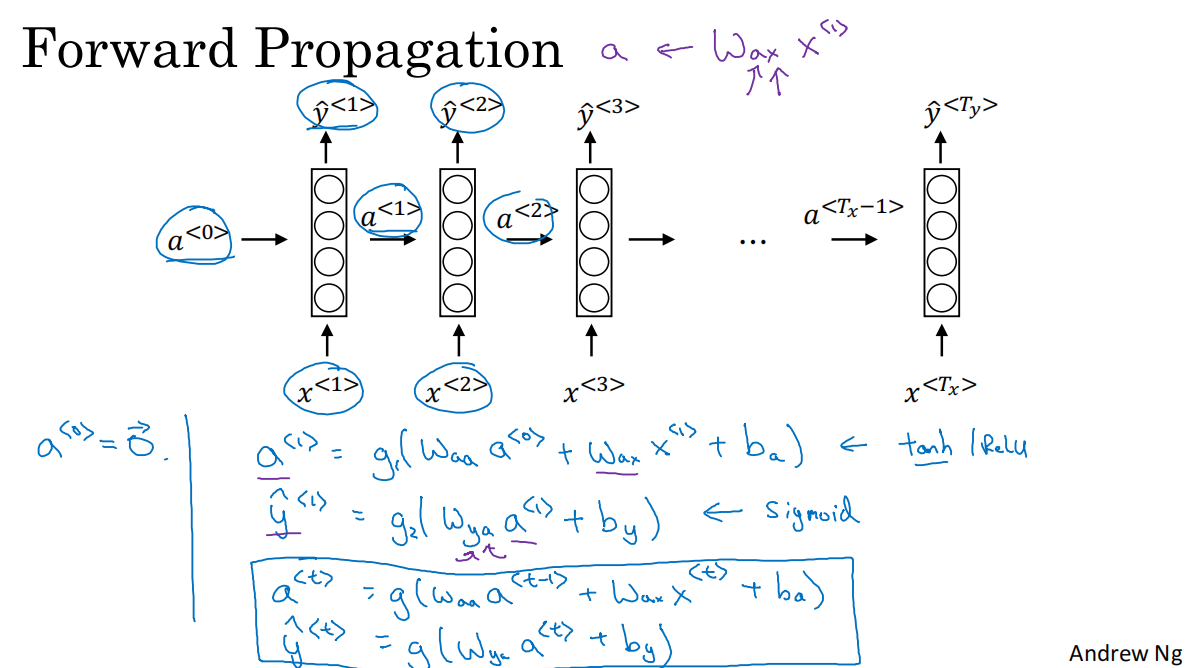
4.符号简化
W_a的简化W_aa.shape=(100,100)``W_ax.shape=(100,10000)W_a=[W_aa,W_ax]``W_a.shape=(100,10100)
[a,x]的简化a<t-1>.shape=(100,n)x<t>.shape=(10000,n)[a<t-1>,x<t>].shape=(10100,n)
*W_a*[a<t-1>,x<t>]=W_aa*a<t-1>+W_ax*x<t>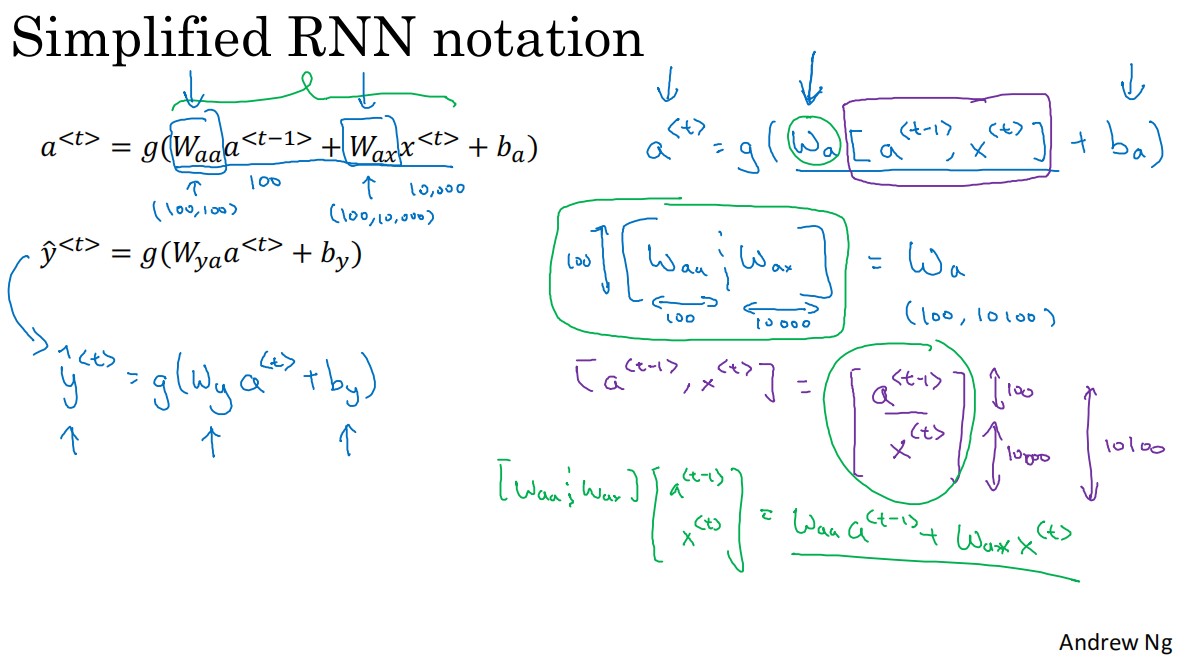
5.RNN前向传播示意图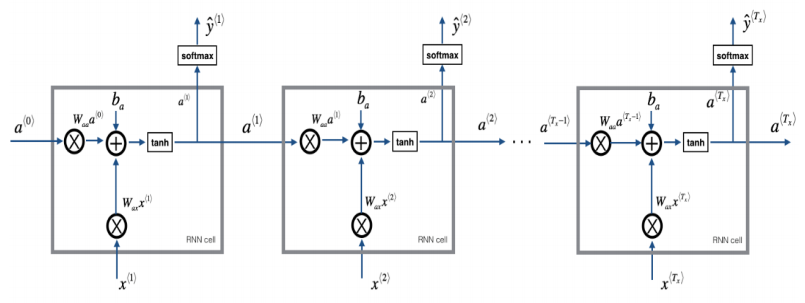
1.4 通过时间的反向传播
1.计算图
*单个元素的损失函数L(y_hat<t>,y<t>)=-y<t>*log(y_hat<t>)-(1-y<t>)*log(1-y_hat<t>)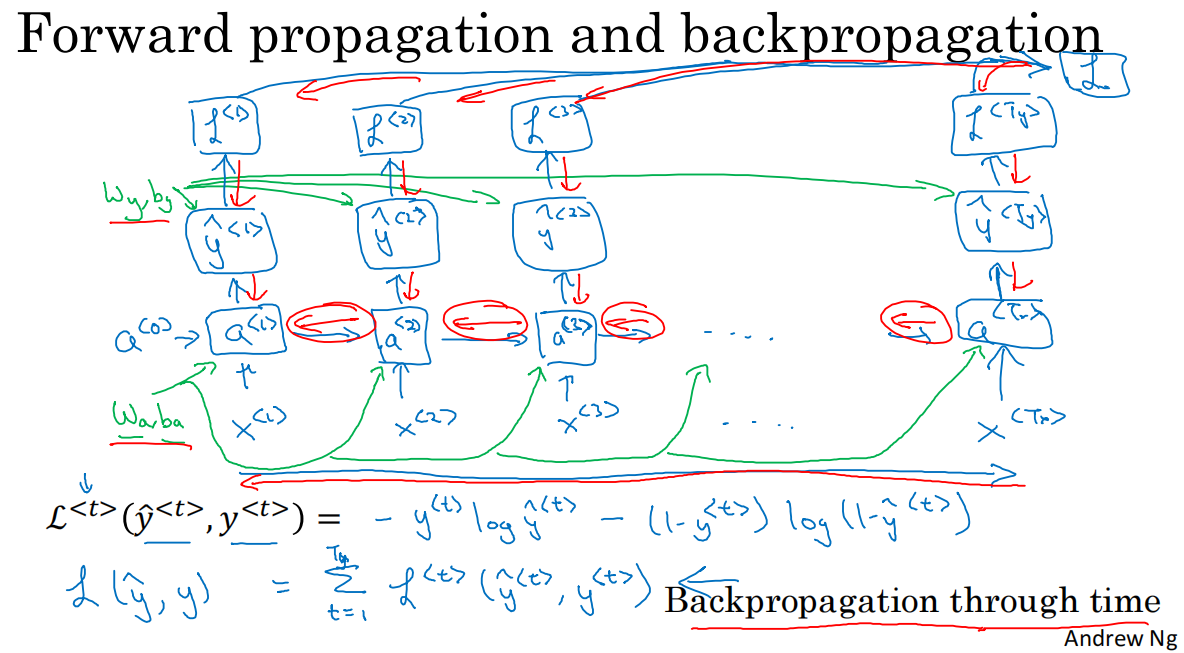
2.cache与具体计算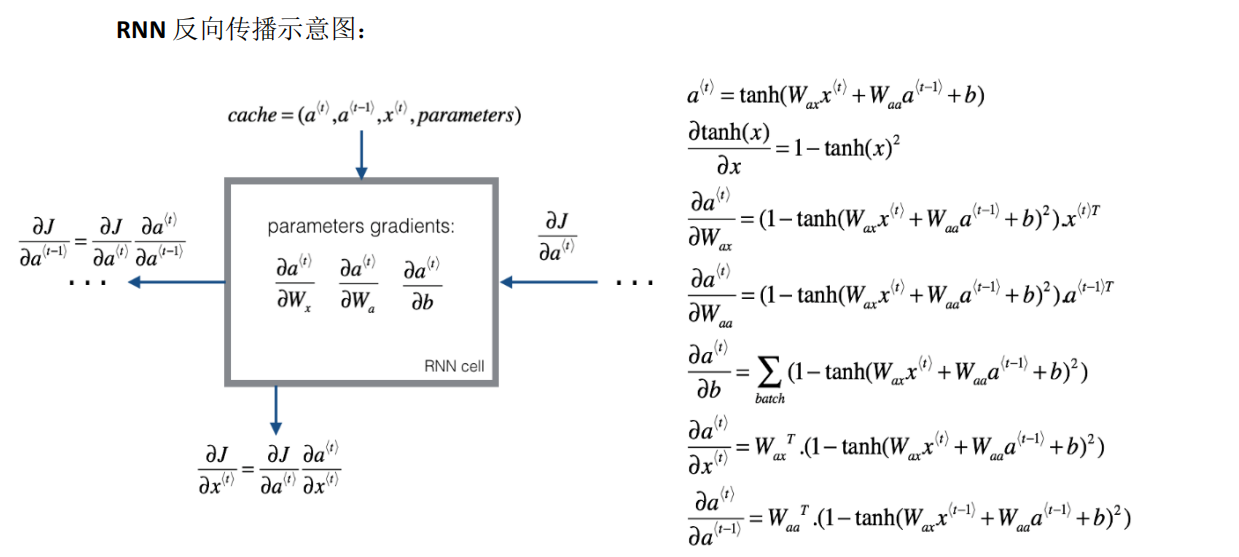
1.5 不同类型的RNNs
1.RNN有许多的架构类型,用于解决T_x和T_y长度不匹配的不同问题
*many-to-many类型Tx=Ty,常见应用:命名实体识别
*many-to-many类型Tx!=Ty,常见应用:机器翻译,网络结构说明:网络由2部分组成:decoder和encoder
*many-to-one类型Tx>Ty,常见应用:评分/情感分析,网络结构说明:RNN网络可简化,仅需要最后时间步的输出
*one/NULL-to-many类型Tx<Ty,常见应用:音乐生成,网络结构说明:输入数量为1,细节:上一层的输出也可以喂给下一层,作为输入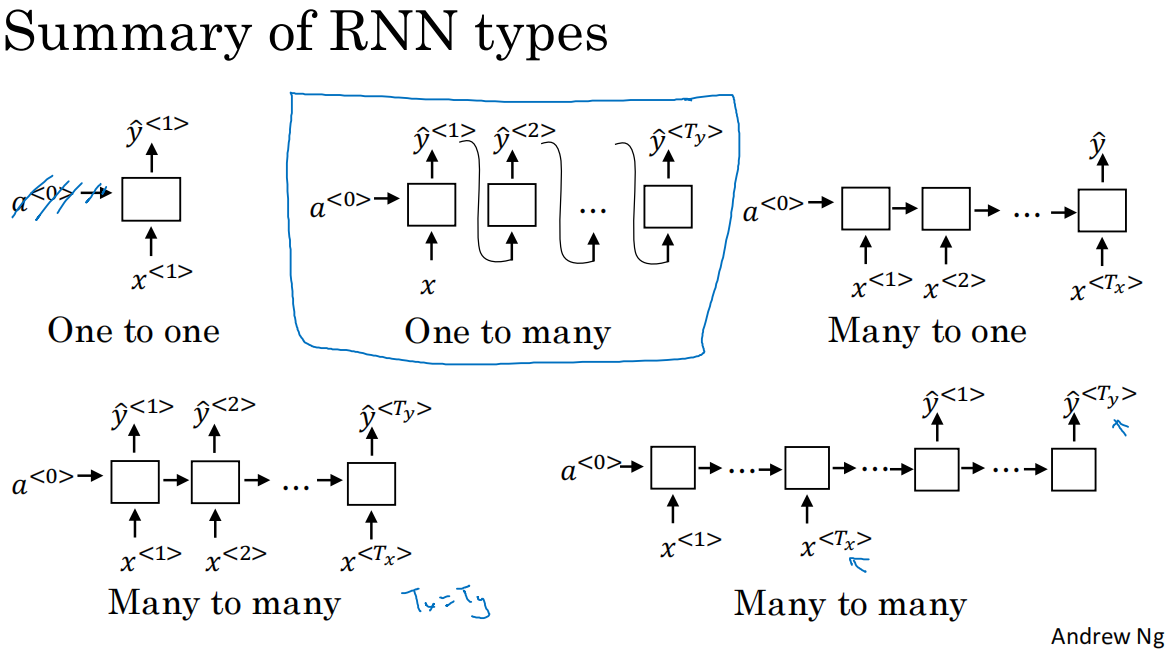
1.6 语言模型和序列生成
1.语言模型用于生成某个特定的句子出现的概率,它的输入是文本序列y<1> y<2> y<3> y<4> ... y<T_y>(一般对于语言模型,用y表示输入更好),语言模型会估计序列中各个单词出现的概率
2.通过RNN建立语言模型,训练集:语料库
3.我们需要对训练集的句子进行标记化:
*建立一个字典,将对应的单词转化为one-hot向量
需要注意的是,我们往往定义句子的末尾为<EOS>结束标记.符号可以作为输入,也可以不作为输入
*对于未识别的字符,我们将他们作为一个整体,都用UNK标记,计算他们整体的概率,而不单独对某一未标记字符计算其概率
4.通过RNN模型构造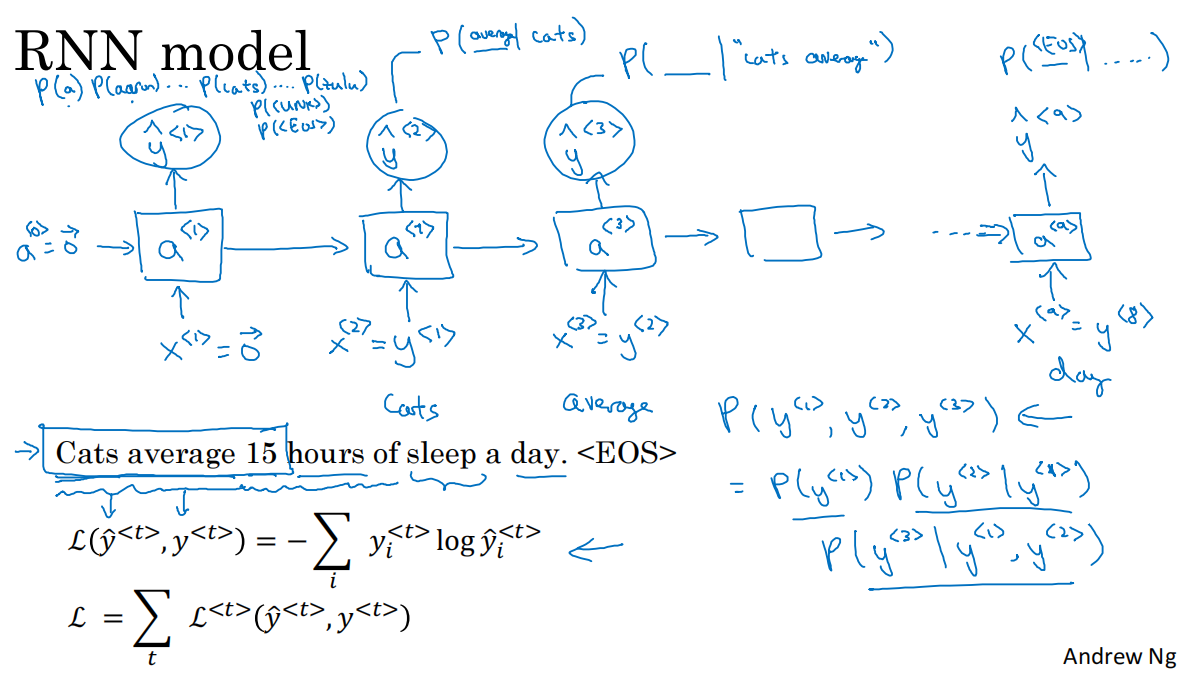
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!