The Annotated Transformer的中文教程
The Annotated Transformer


- v2022: Austin Huang, Suraj Subramanian, Jonathan Sum, Khalid Almubarak,
and Stella Biderman. - Original:
Sasha Rush.
The Transformer has been on a lot of
people’s minds over the last five years.
This post presents an annotated version of the paper in the form of a line-by-line implementation. It reorders and deletes some sections from the original paper and adds comments throughout. This document itself is a working notebook, and should be a completely usable implementation. Code is available here.
在过去的五年里,Transformer 一直是很多人关注的焦点。这篇文章以逐行实现的形式呈现了论文的带注释版本。它重新排序并删除了原始论文中的一些部分,并在全文中添加了评论。本文档本身是一个notebook ,并且应该是一个完全可用的实现。代码可以在这里找到。
Table of Contents
- Prelims
- Background
- Part 1: Model Architecture
- Model Architecture
- Part 2: Model Training
- Training
- A First Example
- Part 3: A Real World Example
- Additional Components: BPE, Search, Averaging
- Results
- Conclusion
Prelims 预备
# !pip install -r requirements.txt
# # Uncomment for colab
# #
# !pip install -q torchdata==0.3.0 torchtext==0.12 spacy==3.2 altair GPUtil
# !python -m spacy download de_core_news_sm
# !python -m spacy download en_core_web_sm
import os
from os.path import exists
import torch
import torch.nn as nn
from torch.nn.functional import log_softmax, pad
import math
import copy
import time
from torch.optim.lr_scheduler import LambdaLR
import pandas as pd
import altair as alt
from torchtext.data.functional import to_map_style_dataset
from torch.utils.data import DataLoader
from torchtext.vocab import build_vocab_from_iterator
import torchtext.datasets as datasets
import spacy
import GPUtil
import warnings
from torch.utils.data.distributed import DistributedSampler
import torch.distributed as dist
import torch.multiprocessing as mp
from torch.nn.parallel import DistributedDataParallel as DDP
# Set to False to skip notebook execution (e.g. for debugging)
# 设置为 False 以跳过notebook 执行(例如用于调试)
warnings.filterwarnings("ignore")
RUN_EXAMPLES = True
# Some convenience helper functions used throughout the notebook
# 整个notebook中使用的一些方便的辅助功能
def is_interactive_notebook():
return __name__ == "__main__"
def show_example(fn, args=[]):
if __name__ == "__main__" and RUN_EXAMPLES:
return fn(*args)
def execute_example(fn, args=[]):
if __name__ == "__main__" and RUN_EXAMPLES:
fn(*args)
class DummyOptimizer(torch.optim.Optimizer):
def __init__(self):
self.param_groups = [{"lr": 0}]
None
def step(self):
None
def zero_grad(self, set_to_none=False):
None
class DummyScheduler:
def step(self):
None
My comments are blockquoted. The main text is all from the paper itself.
我的评论被块引用了。正文全部来自论文本身。
Background
减少顺序计算的目标也构成了扩展神经 GPU、ByteNet 和 ConvS2S 的基础,所有这些都使用卷积神经网络作为基本构建块,并行计算所有输入和输出位置的隐藏表示。在这些模型中,关联来自两个任意输入或输出位置的信号所需的操作数量随着位置之间的距离而增加,对于 ConvS2S 呈线性增长,对于 ByteNet 呈对数增长。这使得学习远距离位置之间的依赖关系变得更加困难。在 Transformer 中,这被减少到恒定数量的操作,尽管由于平均注意力加权位置而导致有效分辨率降低,我们用多头注意力来抵消这种影响。
自注意力(有时称为内部注意力)是一种将单个序列的不同位置相关联的注意力机制,以便计算序列的表示。自注意力已成功应用于各种任务,包括阅读理解、抽象概括、文本蕴涵和学习任务无关的句子表示。端到端记忆网络基于循环注意机制而不是序列对齐循环,并且已被证明在简单语言问答和语言建模任务上表现良好。
然而,据我们所知,Transformer 是第一个完全依赖自注意力来计算其输入和输出表示而不使用序列对齐 RNN 或卷积的转换模型。
Part 1: Model Architecture
Model Architecture
Most competitive neural sequence transduction models have an encoder-decoder structure(cite). Here, the encoder maps an input sequence of symbol representations ( x 1 , . . . , x n ) (x_1, ..., x_n) (x1?,...,xn?) to a sequence of continuous representations z = ( z 1 , . . . , z n ) \mathbf{z} = (z_1, ...,z_n) z=(z1?,...,zn?). Given z \mathbf{z} z, the decoder then generates an output sequence ( y 1 , . . . , y m ) (y_1,...,y_m) (y1?,...,ym?) of symbols one element at a time. At each step the model is auto-regressive (cite), consuming the previously generated symbols as additional input when generating the next.
大多数竞争性神经序列转导模型都具有编码器-解码器结构(cite)。这里,编码器将符号表示的输入序列 ( x 1 , . . . , x n ) (x_1, ..., x_n) (x1?,...,xn?) 映射到连续表示序列 z = ( z 1 , . . . , z n ) \mathbf{z} = (z_1, ...,z_n) z=(z1?,...,zn?)。给定 z \mathbf{z} z,解码器然后生成一个符号输出序列 ( y 1 , . . . , y m ) (y_1,...,y_m) (y1?,...,ym?),一次一个元素。在每个步骤中,模型都是自回归的(cite),在生成下一个符号时将先前生成的符号用作附加输入。
class EncoderDecoder(nn.Module):
"""
A standard Encoder-Decoder architecture. Base for this and many other models.
标准编码器-解码器架构。该模型和许多其他模型的基础。
"""
def __init__(self, encoder, decoder, src_embed, tgt_embed, generator):
super(EncoderDecoder, self).__init__()
self.encoder = encoder
self.decoder = decoder
self.src_embed = src_embed
self.tgt_embed = tgt_embed
self.generator = generator
def forward(self, src, tgt, src_mask, tgt_mask):
"Take in and process masked src and target sequences."
"接收并处理屏蔽的源序列和目标序列。"
return self.decode(self.encode(src, src_mask), src_mask, tgt, tgt_mask)
def encode(self, src, src_mask):
return self.encoder(self.src_embed(src), src_mask)
def decode(self, memory, src_mask, tgt, tgt_mask):
return self.decoder(self.tgt_embed(tgt), memory, src_mask, tgt_mask)
class Generator(nn.Module):
"Define standard linear + softmax generation step."
"定义标准线性+softmax生成步骤。"
def __init__(self, d_model, vocab):
super(Generator, self).__init__()
self.proj = nn.Linear(d_model, vocab)
def forward(self, x):
return log_softmax(self.proj(x), dim=-1)
The Transformer follows this overall architecture using stacked self-attention and point-wise, fully connected layers for both the encoder and decoder, shown in the left and right halves of Figure 1, respectively.
Transformer 遵循这一整体架构,对编码器和解码器使用堆叠自注意力和逐点、全连接层,分别如图1的左半部分和右半部分所示。
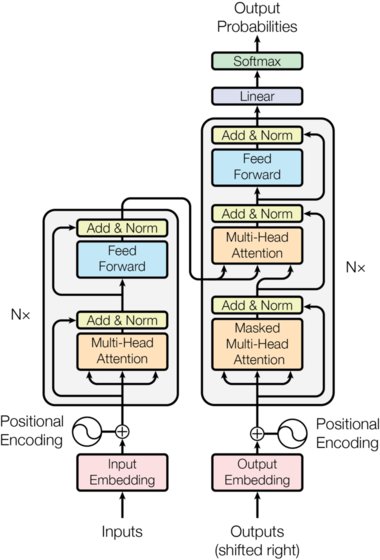
Encoder and Decoder Stacks编码器和解码器堆栈
Encoder编码器
The encoder is composed of a stack of
N
=
6
N=6
N=6 identical layers.
编码器由
N
=
6
N=6
N=6 个相同层的堆栈组成。
def clones(module, N):
"Produce N identical layers."
"产生 N 个相同的层。"
return nn.ModuleList([copy.deepcopy(module) for _ in range(N)])
class Encoder(nn.Module):
"Core encoder is a stack of N layers"
"核心编码器是 N 层的堆栈"
def __init__(self, layer, N):
super(Encoder, self).__init__()
self.layers = clones(layer, N)
self.norm = LayerNorm(layer.size)
def forward(self, x, mask):
"Pass the input (and mask) through each layer in turn."
"将输入(和掩码)依次通过每一层。"
for layer in self.layers:
x = layer(x, mask)
return self.norm(x)
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!