《ORANGE’S:一个操作系统的实现》读书笔记(十九)输入输出系统(一)
我们刚刚实现了简单的进程,你现在可能很想把它做得更加完善,比如进一步改进调度算法、增加通信机制等。但是这些工作不但做起来没有尽头,而且有些也是难以实现的,因为进程必须与I/O、内存管理等其它模块一起工作。而且,简单的进程更有利于我们思考和控制。
那么现在,从这篇文章开始记录实现简单的I/O。
键盘
到目前为止,我们的操作系统一旦启动就不再受我们的控制了,只能静静地等待结果的出现。但这显然不是我们想要的,我们的操作系统是要可以交互的。而交互手段,首先当然是键盘。
从中断开始——键盘初体验
说起键盘,你可能还有印象,8259A的IRQ1对应的就是键盘,我们在之前的文章记录中做过这样一个小试验。那时我们没有为键盘中断指定专门的处理程序,所以当按下键盘时只能打印一行“spurious_irq:0x1”。现在我们来写一个专门的处理程序。
新建一个文件keyboard.c,添加一个非常简单的键盘中断处理程序。
代码 kernel/keyboard.c,键盘中断处理程序。
PUBLIC void keyboard_handler(int irq)
{
disp_str("*");
}结果是每按一次键,打印一个星号,有点像在输入密码。为了不受其它进程输出的影响,我们把其它进程的输出都注释掉。然后添加指定中断处理程序的代码并打开键盘中断。
代码 kernel/keyboard.c,打开键盘中断。
PUBLIC void init_keyboard()
{
put_irq_handler(KEYBOARD_IRQ, keyboard_handler); /* 设定键盘中断处理程序 */
enable_irq(KEYBOARD_IRQ); /* 开启键盘中断 */
}不要忘记在proto.h中声明init_keyboard()并调用。
代码 kernel/main.c,调用init_keyboard()。
PUBLIC int kernel_main()
{
...
init_keyboard();
...
}修改Makefile之后,就可以make并运行了,结果如下图所示。
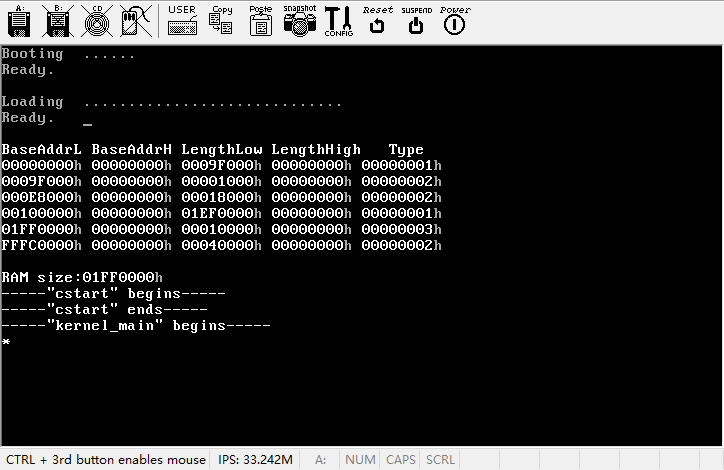
点击键盘,屏幕上出现一个星号,但是,不管点击几次键盘,屏幕上就只显示一个星号,这是什么原因呢?看来事情不像我们想像的这么简单。我们还是要从头说起。
AT、PS/2 键盘
PS/2键盘和USB键盘是当今最流行的两种键盘。现在,可以看看你的键盘连接计算机的接口,如果看上去很像下图左图的样子,那么你用的应该是个PS/2键盘;如果是一个有棱有角的扁口,那么它很可能是USB键盘。再有一种可能,你还在使用一种稍微老一点的AT键盘,它看上去就像下图右图的形状(看这本书的时候,我是第一次知道AT键盘)。有人把AT键盘称为”大口“键盘,把PS/2称为“小口”键盘。因为AT键盘的接口稍微大一些而PS/2的稍微小一些。它们的接口分别叫做“5-pin DIN”和“6-pin Mini-DIN”。
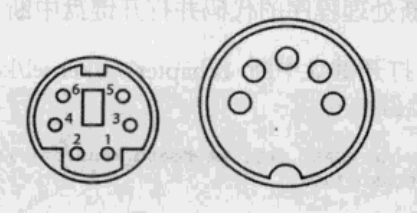
实际上在更早的时候,IBM还推出过XT键盘,它也使用5-pin DIN,不过现在早就不再使用了。如今的主流键盘主要是AT、PS/2、USB三种。在书中,作者只介绍AT和PS/2两种。实际上,PS/2键盘只是在AT键盘的基础上做了一点点扩充而已,在大多数情况下,尤其是最初接触它们的时,你可以认为它们是一样的。
键盘敲击过程
在键盘中存在一枚叫做键盘编码器(Keyboard Encoder)的芯片,它通常是Intel 8048芯片以及兼容芯片,作用是监视键盘的输入,并把适当的数据传送给计算机。另外,在计算机主板上还有一个键盘控制器(Keyboard Controller),用来接收和解码来自键盘的数据,并与8259A以及软件等进行通信。
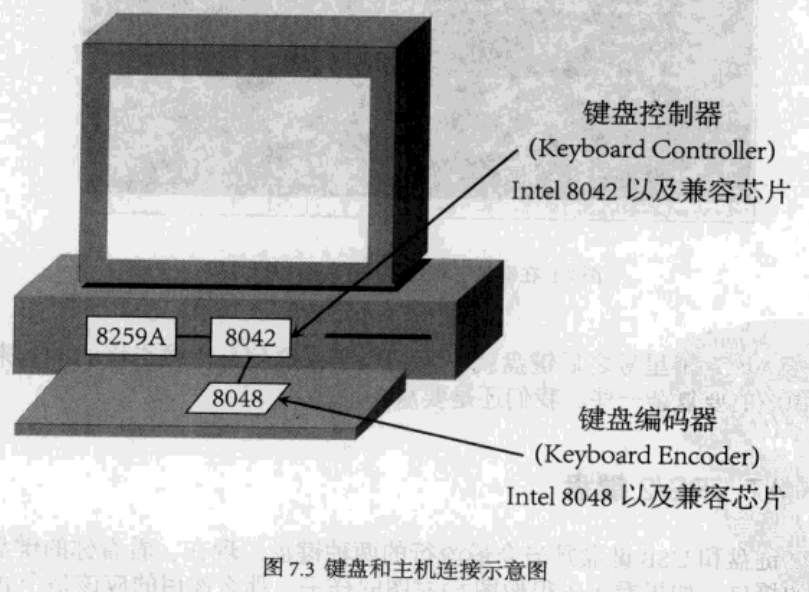
敲击键盘有两个方面的含义:动作和内容。动作可以分解成三类:按下、保持住的状态以及放开;内容则是键盘上不同的键,字母键还是数字键。回车键还是箭头键。所以,根据敲击动作产生的编码,8048既要反映“哪个”按键产生了动作,还要反映产生了“什么”动作。
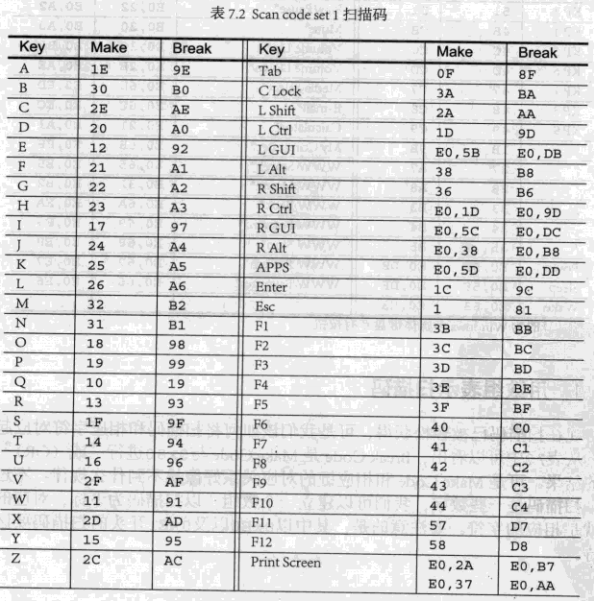
敲击键盘所产生的编码被称作扫描码(Scan Code),它分为Make Code和Break Code两类。当一个键被按下或者保持按下时,将会产生Make Code,当键弹起时,产生Break Code。除了Pause键之外,每一个按键都对应一个Make Code和一个Break Code。
扫描码共有三套,叫做Scan code set 1、Scan code set 2和Scan code set 3。Scan code set 1是早期的XT键盘使用的,现在的键盘默认都支持Scan code set 2,而Scan code set 3很少使用。
当8048检测到一个键的动作后,会把相应的扫描码发送给8042,8042会把它转换成相应的Scan code set1扫描码,并将其放置在输入缓冲区中,然后8042告诉8259A产生中断(IRQ1)。如果此时键盘又有新的键被按下,8042将不再接收,一直到缓冲区被清空,8042才会收到更多的扫描码。
现在,你可能已经明白了为什么我们上面的代码只打印了一个字符,因为我们的键盘中断处理例程什么都没做。只有我们把扫描码从缓冲区读出来后,8042才能继续响应新的按键。
那么如何从缓冲区读取扫描码呢?这就需要我们来看一看8042了。
8042包含下表所示的一些寄存器。
| 寄存器名称 | 寄存器大小 | 端口 | R/W | 用法 |
| 输出缓冲区 | 1 BYTE | 0x60 | Read | 读输出缓冲区 |
| 输入缓冲区 | 1 BYTE | 0x60 | Write | 写输入缓冲区 |
| 状态寄存器 | 1 BYTE | 0x64 | Read | 读状态寄存器 |
| 控制寄存器 | 1 BYTE | 0x64 | Write | 发送命令 |
注意:由于8042处在8048和系统的中间,所以输入和输出是相对的。比如,8042从8048输入数据,然后输出到系统。因此,上表中的“出”和“入”是相对于系统而言的。
对于输入和输出缓冲区,可以通过in和out指令来进行相应的读取操作。也就是说,一个in al, 0x60指令就可以读取扫描码了。
事不宜迟,我们马上修改程序,在keyboard_handler中添加下面一句:
in_byte(0x60);make,运行,结果如下图所示。
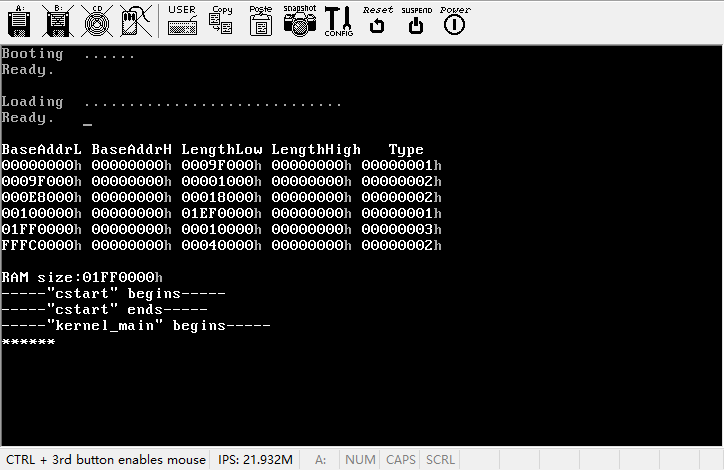
按一下键,出现两个星号,再按一下,又出现两个。按了3下按键出现了6个星号,因为每次按键都产生一个Make Code和一个Break Code,所以总共产生了6次中断。
只打印星号显然没有意义,我们把收到的扫描码打印一下看看,进一步修改keyboard_handler。
代码 kernel/keyboard.c,修改键盘中断。
PUBLIC void keyboard_handler(int irq)
{
u8 scan_code = in_byte(0x60);
disp_int(scan_code);
}make,运行,然后按下两个按键:字母“a”和“9”(不要按小键盘上的9,我这里实验的时候小键盘上的9和字母键盘区域上的9值不一样),结果如下图所示。
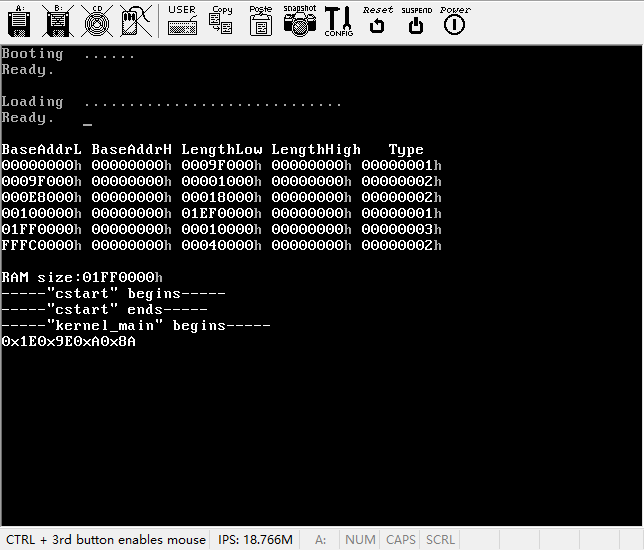
总共出现4组代码:0x1E、0x9E、0xA、0x8A。对照下表可知,它们对应的就是字符“a”和“9”的Make Code和Break Code。
注意:由于a和A是同一个键,所以它们的扫描码是一样的(事实上根本就不是“它们”,而是“它”,因为是同一个键),如果按下“左Shift+a”,将得到这样的输出:0x2A0x1E0x9E0xAA,分别是左Shift键的Make Code、a的Make Code、a的Break Code以及左Shift键的Break Code。所以,按下“Shift+a”得到A是软件的功劳,甚至可以让“Shift+a”去对应S或者T。同理,按下任何键,不管是单键还是组合键,想让屏幕输出什么,或者产生什么反应,都是由软件来控制的。虽然增加了操作系统的复杂性,但这种机制无疑是相当灵活的。

同时你可以看到,虽然键盘支持的是Scan code set 2,但最终又转化成了Scan code set 1。这是基于为XT键盘写的程序兼容性而考虑的。
用数组表示扫描码
现在扫描码已经获得,可是我们应该如何将扫描码和相应的字符对应起来呢?从上表中可以看出,Break Code是Mack Code与0x80进行“或(OR)”操作的结果。可是Make Code和相应键的对应关系好像找不到什么规律。不过还好,扫描码是一些数字,我们可以建立一个数组,以扫描码为下标,对应的元素就是相应的字符。要注意的是,其中以0xE0以及0xE1开头的扫描码要区别对待。
我们把这个数组做成如下面代码所示的样子。其中每3个值是一组(MAP_COLS被定义成3),分别是单独按某键、Shift+某键和有0xE0前缀的扫描码对应的字符。Esc、Enter等被定义成了宏,宏的具体数值无所谓,只要不会造成冲突和混淆,让操作系统认识就可以了。
代码 include/keymap.h,扫描码解析数组。
u32 keymap[NR_SCAN_CODES * MAP_COLS] = {
/* scan-code !Shift Shift E0 XX */
/* ==================================================================== */
/* 0x00 - none */ 0, 0, 0,
/* 0x01 - ESC */ ESC, ESC, 0,
/* 0x02 - '1' */ '1', '!', 0,
/* 0x03 - '2' */ '2', '@', 0,
/* 0x04 - '3' */ '3', '#', 0,
/* 0x05 - '4' */ '4', '$', 0,
/* 0x06 - '5' */ '5', '%', 0,
/* 0x07 - '6' */ '6', '^', 0,
/* 0x08 - '7' */ '7', '&', 0,
/* 0x09 - '8' */ '8', '*', 0,
/* 0x0A - '9' */ '9', '(', 0,
/* 0x0B - '0' */ '0', ')', 0,
/* 0x0C - '-' */ '-', '_', 0,
/* 0x0D - '=' */ '=', '+', 0,
/* 0x0E - BS */ BACKSPACE, BACKSPACE, 0,
/* 0x0F - TAB */ TAB, TAB, 0,
/* 0x10 - 'q' */ 'q', 'Q', 0,
/* 0x11 - 'w' */ 'w', 'W', 0,
/* 0x12 - 'e' */ 'e', 'E', 0,
/* 0x13 - 'r' */ 'r', 'R', 0,
/* 0x14 - 't' */ 't', 'T', 0,
/* 0x15 - 'y' */ 'y', 'Y', 0,
/* 0x16 - 'u' */ 'u', 'U', 0,
/* 0x17 - 'i' */ 'i', 'I', 0,
/* 0x18 - 'o' */ 'o', 'O', 0,
/* 0x19 - 'p' */ 'p', 'P', 0,
/* 0x1A - '[' */ '[', '{', 0,
/* 0x1B - ']' */ ']', '}', 0,
/* 0x1C - CR/LF */ ENTER, ENTER, PAD_ENTER,
/* 0x1D - l. Ctrl */ CTRL_L, CTRL_L, CTRL_R,
/* 0x1E - 'a' */ 'a', 'A', 0,
/* 0x1F - 's' */ 's', 'S', 0,
/* 0x20 - 'd' */ 'd', 'D', 0,
/* 0x21 - 'f' */ 'f', 'F', 0,
/* 0x22 - 'g' */ 'g', 'G', 0,
/* 0x23 - 'h' */ 'h', 'H', 0,
/* 0x24 - 'j' */ 'j', 'J', 0,
/* 0x25 - 'k' */ 'k', 'K', 0,
/* 0x26 - 'l' */ 'l', 'L', 0,
/* 0x27 - ';' */ ';', ':', 0,
/* 0x28 - '\'' */ '\'', '"', 0,
/* 0x29 - '`' */ '`', '~', 0,
/* 0x2A - l. SHIFT */ SHIFT_L, SHIFT_L, 0,
/* 0x2B - '\' */ '\\', '|', 0,
/* 0x2C - 'z' */ 'z', 'Z', 0,
/* 0x2D - 'x' */ 'x', 'X', 0,
/* 0x2E - 'c' */ 'c', 'C', 0,
/* 0x2F - 'v' */ 'v', 'V', 0,
/* 0x30 - 'b' */ 'b', 'B', 0,
/* 0x31 - 'n' */ 'n', 'N', 0,
/* 0x32 - 'm' */ 'm', 'M', 0,
/* 0x33 - ',' */ ',', '<', 0,
/* 0x34 - '.' */ '.', '>', 0,
/* 0x35 - '/' */ '/', '?', PAD_SLASH,
/* 0x36 - r. SHIFT */ SHIFT_R, SHIFT_R, 0,
/* 0x37 - '*' */ '*', '*', 0,
/* 0x38 - ALT */ ALT_L, ALT_L, ALT_R,
/* 0x39 - ' ' */ ' ', ' ', 0,
/* 0x3A - CapsLock */ CAPS_LOCK, CAPS_LOCK, 0,
/* 0x3B - F1 */ F1, F1, 0,
/* 0x3C - F2 */ F2, F2, 0,
/* 0x3D - F3 */ F3, F3, 0,
/* 0x3E - F4 */ F4, F4, 0,
/* 0x3F - F5 */ F5, F5, 0,
/* 0x40 - F6 */ F6, F6, 0,
/* 0x41 - F7 */ F7, F7, 0,
/* 0x42 - F8 */ F8, F8, 0,
/* 0x43 - F9 */ F9, F9, 0,
/* 0x44 - F10 */ F10, F10, 0,
/* 0x45 - NumLock */ NUM_LOCK, NUM_LOCK, 0,
/* 0x46 - ScrLock */ SCROLL_LOCK, SCROLL_LOCK, 0,
/* 0x47 - Home */ PAD_HOME, '7', HOME,
/* 0x48 - CurUp */ PAD_UP, '8', UP,
/* 0x49 - PgUp */ PAD_PAGEUP, '9', PAGEUP,
/* 0x4A - '-' */ PAD_MINUS, '-', 0,
/* 0x4B - Left */ PAD_LEFT, '4', LEFT,
/* 0x4C - MID */ PAD_MID, '5', 0,
/* 0x4D - Right */ PAD_RIGHT, '6', RIGHT,
/* 0x4E - '+' */ PAD_PLUS, '+', 0,
/* 0x4F - End */ PAD_END, '1', END,
/* 0x50 - Down */ PAD_DOWN, '2', DOWN,
/* 0x51 - PgDown */ PAD_PAGEDOWN, '3', PAGEDOWN,
/* 0x52 - Insert */ PAD_INS, '0', INSERT,
/* 0x53 - Delete */ PAD_DOT, '.', DELETE,
/* 0x54 - Enter */ 0, 0, 0,
/* 0x55 - ??? */ 0, 0, 0,
/* 0x56 - ??? */ 0, 0, 0,
/* 0x57 - F11 */ F11, F11, 0,
/* 0x58 - F12 */ F12, F12, 0,
/* 0x59 - ??? */ 0, 0, 0,
/* 0x5A - ??? */ 0, 0, 0,
/* 0x5B - ??? */ 0, 0, GUI_L,
/* 0x5C - ??? */ 0, 0, GUI_R,
/* 0x5D - ??? */ 0, 0, APPS,
/* 0x5E - ??? */ 0, 0, 0,
/* 0x5F - ??? */ 0, 0, 0,
/* 0x60 - ??? */ 0, 0, 0,
/* 0x61 - ??? */ 0, 0, 0,
/* 0x62 - ??? */ 0, 0, 0,
/* 0x63 - ??? */ 0, 0, 0,
/* 0x64 - ??? */ 0, 0, 0,
/* 0x65 - ??? */ 0, 0, 0,
/* 0x66 - ??? */ 0, 0, 0,
/* 0x67 - ??? */ 0, 0, 0,
/* 0x68 - ??? */ 0, 0, 0,
/* 0x69 - ??? */ 0, 0, 0,
/* 0x6A - ??? */ 0, 0, 0,
/* 0x6B - ??? */ 0, 0, 0,
/* 0x6C - ??? */ 0, 0, 0,
/* 0x6D - ??? */ 0, 0, 0,
/* 0x6E - ??? */ 0, 0, 0,
/* 0x6F - ??? */ 0, 0, 0,
/* 0x70 - ??? */ 0, 0, 0,
/* 0x71 - ??? */ 0, 0, 0,
/* 0x72 - ??? */ 0, 0, 0,
/* 0x73 - ??? */ 0, 0, 0,
/* 0x74 - ??? */ 0, 0, 0,
/* 0x75 - ??? */ 0, 0, 0,
/* 0x76 - ??? */ 0, 0, 0,
/* 0x77 - ??? */ 0, 0, 0,
/* 0x78 - ??? */ 0, 0, 0,
/* 0x78 - ??? */ 0, 0, 0,
/* 0x7A - ??? */ 0, 0, 0,
/* 0x7B - ??? */ 0, 0, 0,
/* 0x7C - ??? */ 0, 0, 0,
/* 0x7D - ??? */ 0, 0, 0,
/* 0x7E - ??? */ 0, 0, 0,
/* 0x7F - ??? */ 0, 0, 0
};举个例子,如果获得的扫描码是0x1F,我们在上面代码中看到它对应的是字母“s”。在写程序的时候,应该用keymap[0x1F*MAP_COLS]来表示0x1F对应的字符。如果获得的扫描码是0x2A0x1E,它是左Shift键的Make Code和字符“a”的Make Code连在一起,说明按下Shift还没有弹起的时候a又被按下,因此应该用keymap[0x1E*MAP_COLS+1]表示这一行为的结果,即大写字母A。
存在0xE0的情况也是类似的,如果我们收到的扫描码是0xE00x47,就应该去找keymap[0x47*MAP_COLS+2],它对应的是Home。
但是现在有一个问题,就是8042的输入缓冲区大小只有一个字节,所以当一个扫描码有不只一个字符时,实际上会产生不只一次中断。也就是说,如果我们按下一次Shift+A,产生的0x2A0x1E0x9E0xAA是4次中断接收来的。这就给我们的程序实现带来了困难,因为第一次中断接收到的0x2A无法让我们知道用户最终会完成什么,说不定是按下Shift又释放,也可能是Shift+Z而不是Shift+A。
于是,当接收到类似0x2A这样的值的时候,需要先把它保存起来,在随后的过程中慢慢解析用户到底做了什么。保存一个值可以用全局变量来完成。可是,由于扫描码的值和长度都不一样,这项工作做起来可能并不简单。而且我们可以想象,键盘操作必将是频繁而复杂的,如果把得到扫描码之后相应的后续操作都放在键盘中断处理中,最后keyboard_handler会变得很大,这不是一个好主意。在这里,可以建立一个缓冲区,让keyboard_handler将每次收到的扫描码放入这个缓冲区,然后建立一个新的任务专门用来解析它们并做相应处理。
键盘输入缓冲区
我们先来建立一个缓冲区,用以放置中断例程收到的扫描码。
代码 include/keyboard.h,键盘缓冲区。
/* Keyboard structure, 1 per console. */
typedef struct s_kb {
char* p_head; /* 指向缓冲区中下一个空闲位置 */
char* p_tail; /* 指向键盘任务应处理的字节 */
int count; /* 缓冲区中共有多少字节 */
char buf[KB_IN_BYTES]; /* 缓冲区 */
}KB_INPUT;这个缓冲区的用法如下图所示,白色框表示空闲字节,灰色框表示已用字节。在执行写操作的时候要注意,如果已经到达缓冲区末尾,则应将指针移到开头。

对照上图,我们可以容易地对缓冲区进行添加操作。
代码 kernel/keyboard.c,修改后的keyboard_handler。
PRIVATE KB_INPUT kb_in;
PUBLIC void keyboard_handler(int irq)
{
u8 scan_code = in_byte(KB_DATA);
if (kb_in.count < KB_IN_BYTES) {
*(kb_in.p_head) = scan_code;
kb_in.p_head++;
if (kb_in.p_head == kb_in.buf + KB_IN_BYTES) {
kb_in.p_head = kb_in.buf;
}
kb_in.count++;
}
}代码不难,但要注意,如果缓冲区已满,这里使用的策略是直接就把收到的字节丢弃。其中的kb_in,由于我们只在keyboard.c中使用,于是把它声明成了一个PRIVATE变量(PRIVATE的定义位于const.h中,被定义成了static)。
kb_in的成员需要初始化,初始化的代码放在init_keyboard()中。
代码 kernel/keyboard.c,修改后的init_keyboard。
PUBLIC void init_keyboard()
{
kb_in.count = 0;
kb_in.p_head = kb_in.p_tail = kb_in.buf;
put_irq_handler(KEYBOARD_IRQ, keyboard_handler); /* 设定键盘中断处理程序 */
enable_irq(KEYBOARD_IRQ); /* 开启键盘中断 */
}为了保持kernel_main()的整洁,我们把时钟中断的设定和开启也放到单独的函数init_clock()中。
代码 kernel/clock.c,init_clock。
PUBLIC void init_clock()
{
/* 初始化 8253 PIT */
out_byte(TIMER_MODE, RATE_GENERATOR);
out_byte(TIMER0, (u8) (TIMER_FREQ / HZ));
out_byte(TIMER0, (u8) ((TIMER_FREQ / HZ) >> 8));
put_irq_handler(CLOCK_IRQ, clock_handler); /* 设定时钟中断处理程序 */
enable_irq(CLOCK_IRQ); /* 让8259A可以接收时钟中断 */
}这样,在kernel_main()中调用这两个函数就可以了。
用新加的任务处理键盘操作
添加一个任务对现在的我们来说是很简单的,在“《ORANGE’S:一个操作系统的实现》读书笔记(十五)进程(三)”这篇文章记录中已经做过总结。书上这里告诉我们,我们下面要添加的这个任务将来不仅会处理键盘操作,还将处理诸如屏幕输出等内容,这些操作工作组成同一个任务:终端任务。
关于终端任务所做的其它工作书中会在后面的章节进行介绍,现在我们认为它只处理键盘输入。
为了简化程序,在这个任务中,我们只是不停地调用keyboard.c中的函数keyboard_read()。
代码 kernel/tty.c,tty任务。
PUBLIC void task_tty()
{
while (1) {
keyboard_read();
}
}我们暂时把所有对扫描码的处理都写进keyboard.c中。代码tty.c中使用的keyboard_read()可以如下面代码这样来定义。
代码 kernel/keyboard.c,keyboard_read。
PUBLIC void keyboard_read()
{
u8 scan_code;
if (kb_in.count > 0) {
disable_int();
scan_code = *(kb_in.p_tail);
kb_in.p_tail++;
if (kb_in.p_tail == kb_in.buf + KB_IN_BYTES) {
kb_in.p_tail = kb_in.buf;
}
kb_in.count--;
enable_int();
disp_int(scan_code);
}
}其中,disable_int()和enable_int()的定义也很简单,如下代码所示。
代码 lib/kliba.asm,disable_int和enable_int。
global disable_int
global enable_int
...
; void disable_int();
disable_int:
cli
ret
; void enable_int();
enable_int:
sti
ret我们现在来看一下keyboard_read()这个函数,该函数首先判断kb_in.count是否为0,如果不为0,表明缓冲区中有扫描码,就开始读。读缓冲区开始时关闭了中断,到结束时才打开,因为kb_in作为一个整体,对其中的成员的操作应该是一气呵成不受打扰的。读操作相当于写操作的反过程。
好了,这样我们就完成了通过任务来处理扫描码的代码,修改Makefile之后就可以make运行了,不过运行结果显然和过去一样,因为我们并没有对扫描码进行解析。
解析扫描码
对扫描码的解析工作有一点烦琐,所以我们分步骤来完成它。
让字符显示出来
虽然我们已经有了一个数组keymap[],但是解析扫描码还是很复杂的,因为它不但区分为Make Code和Break Code,而且有长有短,功能也很多样,比如Home键对应的是一种功能而不是一个ASCII码,所以要区别对待。我们还是由简到繁,先把能打印的打印出来。
代码 kernel/keyboard.c,解析扫描码。
PUBLIC void keyboard_read()
{
u8 scan_code;
char output[2];
int make; /* TURE: make; FALSE: break. */
memset(output, 0, 2);
if (kb_in.count > 0) {
disable_int();
scan_code = *(kb_in.p_tail);
kb_in.p_tail++;
if (kb_in.p_tail == kb_in.buf + KB_IN_BYTES) {
kb_in.p_tail = kb_in.buf;
}
kb_in.count--;
enable_int();
/* 下面开始解析扫描码 */
if (scan_code == 0xE1) {
/* 暂时不做任何操作 */
} else if (scan_code == 0xE0) {
/* 暂时不做任何操作 */
} else { /* 下面处理可打印字符 */
/* 首先判断是 Make Code 还是 Break Code */
make = (scan_code & FLAG_BREAK ? FALSE : TRUE);
/* 如果是 Make Code 就打印,是 Break Code 则不做处理 */
if (make) {
output[0] = keymap[(scan_code & 0x7F) * MAP_COLS];
disp_str(output);
}
}
}
}由于要判断的东西太多,所以一下子把这个函数写得完善几乎是不可能的。所以我们一步一步来,每完成一步就make并运行一下看看效果,然后就知道接下来该怎么做了。
比如在上面的代码中,总体的思想就是0xE0和0xE1单独处理,因为从Scan code set 1表中知道,除去以这两个数字开头的扫描码,其余的都是单字节的。
暂时对0xE0和0xE1不加理会。如果遇到的不是以它们开头的,则判断是Make Code还是Break Code,如果是后者同样不加理会,如果是前者就打印出来。我们前面说过,Break Code是Make Code与0x80进行“或(OR)”操作的结果,代码中的FLAG_BREAK就是被定义成了0x80。
这里你可能注意到一个细节,就是从keymap[]中取出字符的时候进行了一个“与”操作(scan_code & 0x7F)。一方面,如果当前扫描码是Break Code,“与”操作之后就变成Make Code了;另一方面,这样做也是为了避免越界的发生,因为数组keymap[]的大小是0x80。
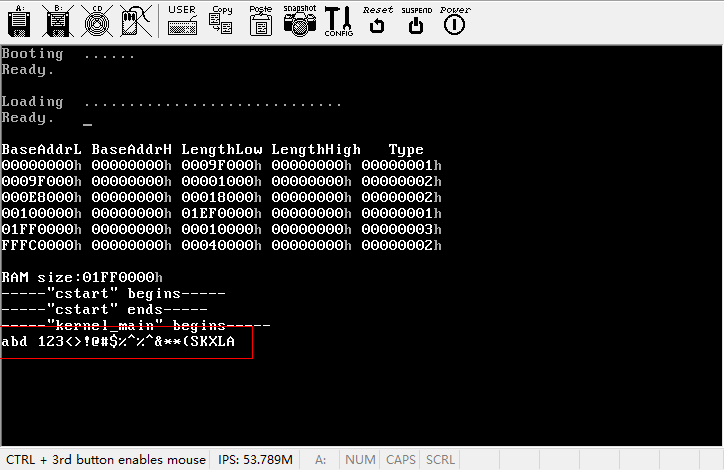
接下来就可以make并运行了,下图就是初步运行的结果。

运行时,我们敲入了“abc123”共6个字符,它们被显示在了屏幕上。
处理 Shift、Alt、Ctrl
现在可以输入简单的字符和数字了,你一定迫不及待地想搞点更复杂的输入,比如按个Shift组合什么的。现在按下Shift只能看到一个奇怪的字符。下面就来添加代码,使其能够响应这些功能键。
代码 kernel/keyboard.c,解析扫描码。
PUBLIC void keyboard_read()
{
u8 scan_code;
char output[2];
int make; /* TURE: make; FALSE: break. */
u32 key = 0; /* 用一个整数来表示一个键。比如:如果 Home 被按下,则 key 值将为定义在 keyboard.h 中的 'HOME' */
u32* keyrow; /* 指向 keymap[] 的某一行 */
// memset(output, 0, 2);
if (kb_in.count > 0) {
disable_int();
scan_code = *(kb_in.p_tail);
kb_in.p_tail++;
if (kb_in.p_tail == kb_in.buf + KB_IN_BYTES) {
kb_in.p_tail = kb_in.buf;
}
kb_in.count--;
enable_int();
/* 下面开始解析扫描码 */
if (scan_code == 0xE1) {
/* 暂时不做任何操作 */
} else if (scan_code == 0xE0) {
code_with_E0 = 1;
} else { /* 下面处理可打印字符 */
/* 首先判断是 Make Code 还是 Break Code */
make = (scan_code & FLAG_BREAK ? FALSE : TRUE);
/* 先定位到 keymap 中的行 */
keyrow = &keymap[(scan_code & 0x7F) * MAP_COLS];
column = 0;
if (shift_l || shift_r) {
column = 1;
}
if (code_with_E0) {
column = 2;
code_with_E0 = 0;
}
key = keyrow[column];
switch(key) {
case SHIFT_L:
shift_l = make;
key = 0;
break;
case SHIFT_R:
shift_r = make;
key = 0;
break;
case CTRL_L:
ctrl_l = make;
key = 0;
break;
case CTRL_R:
ctrl_r = make;
key = 0;
break;
case ALT_L:
alt_l = make;
key = 0;
break;
case ALT_R:
alt_r = make;
key = 0;
break;
default:
if (!make) { /* 如果是 Break Code */
key = 0; /* 忽略之 */
}
break;
}
/* 如果 key 不为0说明是可打印字符,否则不做处理 */
if (key) {
output[0] = key;
disp_str(output);
}
}
}
}在上面代码中,我们不但添加了处理Shift的代码,而且也对Alt和Ctrl键的状态进行了判断,只是暂时对它们还没有做任何处理。
Shift、Alt、Ctrl键共有6个(左右各3个),注意,最好不要把左右两个键不加区分,因为有一些软件需要区分对待。为了充分识别它们而不把左右键混为一谈,我们声明了6个变量来记录它们的状态。当其中的某一个键被按下时,相应的变量值变为TRUE。比如,当我们按下左Shift键,shift_l就变为TRUE,如果它立即释放,则shift_l又变回FALSE。如果当左Shift键被按下且未被释放时,又按下a键,则if (shift_l || shift_r)成立,于是column值变为1,keymap[column]的值就是keymap[]中第二列中相应的值,即大写字母A。
同时,在这段代码中对以0xE0开头的扫描码也做了处理。其实它与按下Shift键类似,甚至还要更简单。当检测到一个扫描码的第一个字节是0xE0时,在将code_with_E0赋值为TRUE之后整个函数实际上就返回了。但动作显然没有结束,下一个字节马上进入处理过程,由于code_with_E0为TRUE,所以column值变成2,于是Key就变成keymap[]中第二列的值了。
整个过程我们还看到,虽然开始变量key的值是从keymap[]中得到的,但从整个函数执行的角度来看,遵循这样的原则:如果一个完整的操作还未结束(比如一个2字节的扫描码还未完全读入),则key赋值为0,等到下一次keyboard_read()被执行时再继续处理。也就是说,目前的情况是,一个完整的操作需要再keyboard_read()多次调用时完成。
好了,现在运行一下,结果如下图所示。
从上图看到,如今我们的OS已经可以识别大写字母,以及“!”、“@”等字符了。
处理所有按键
到现在为止,我们已经可以处理大部分的按键了,但是至少还存在两个问题。
- 如果扫描码更加复杂一些,比如超过3个字符,如今的程序还不足以很好地处理。
- 如果按下诸如F1、F2这样的功能键,系统会尝试把它当做可打印字符来处理,从而打印出一个奇怪的符号。
我们首先来解决第一个问题。目前的情况是,一个完整的操作需要在keyboard_read()多次调用时完成。这不但让我们增加了一些全局变量,比如code_with_E0,而且让keyboard_read()理解起来也有些困难。符合逻辑的方法是,既然按下一个键会产生一到几字节的扫描码,就最好能够在一个过程中把它们全都读出来。这其实并不困难,只需要将从kb_in中读取字符的代码单独拿出来作为一个函数,在用到的时候调用它就可以了。
代码 kernel/keyboard.c,解析扫描码。
PRIVATE int code_with_E0;
PRIVATE int shift_l; /* l shift state */
PRIVATE int shift_r; /* r shift state */
PRIVATE int alt_l; /* l alt state */
PRIVATE int alt_r; /* r alt state */
PRIVATE int ctrl_l; /* l ctrl state */
PRIVATE int ctrl_r; /* r ctrl state */
PRIVATE int caps_lock; /* Caps Lock */
PRIVATE int num_lock; /* Num Lock */
PRIVATE int scroll_lock; /* Scroll Lock */
PRIVATE int column;
PRIVATE u8 get_byte_from_kbuf();
...
PUBLIC void keyboard_read()
{
u8 scan_code;
char output[2];
int make; /* TURE: make; FALSE: break. */
u32 key = 0; /* 用一个整数来表示一个键。比如:如果 Home 被按下,则 key 值将为定义在 keyboard.h 中的 'HOME' */
u32* keyrow; /* 指向 keymap[] 的某一行 */
if (kb_in.count > 0) {
code_with_E0 = 0;
scan_code = get_byte_from_kbuf();
/* 下面开始解析扫描码 */
if (scan_code == 0xE1) {
int i;
u8 pausebrk_scode[] = {0xE1, 0x1D, 0x45,
0xE1, 0x9D, 0xC5};
int is_pausebreak = 1;
for (i = 1; i < 6; i++) {
if (get_byte_from_kbuf() != pausebrk_scode[i]) {
is_pausebreak = 0;
break;
}
}
if (is_pausebreak) {
key = PAUSEBREAK;
}
} else if (scan_code == 0xE0) {
scan_code = get_byte_from_kbuf();
/* PrintScreen 被按下 */
if (scan_code == 0x2A) {
if (get_byte_from_kbuf() == 0xE0) {
if (get_byte_from_kbuf() == 0x37) {
key = PRINTSCREEN;
make = 1;
}
}
}
/* PrintScreen 被释放 */
if (scan_code == 0xB7) {
if (get_byte_from_kbuf() == 0xE0) {
if (get_byte_from_kbuf() == 0xAA) {
key = PRINTSCREEN;
make = 0;
}
}
}
/* 不是PrintScreen,此时scan_code为0xE0紧跟的那个值 */
if (key == 0) {
code_with_E0 = 1;
}
}
if ((key != PAUSEBREAK) && (key != PRINTSCREEN)) {
/* 首先判断是 Make Code 还是 Break Code */
make = (scan_code & FLAG_BREAK ? FALSE : TRUE);
/* 先定位到 keymap 中的行 */
keyrow = &keymap[(scan_code & 0x7F) * MAP_COLS];
column = 0;
if (shift_l || shift_r) {
column = 1;
}
if (code_with_E0) {
column = 2;
code_with_E0 = 0;
}
key = keyrow[column];
switch(key) {
case SHIFT_L:
shift_l = make;
key = 0;
break;
case SHIFT_R:
shift_r = make;
key = 0;
break;
case CTRL_L:
ctrl_l = make;
key = 0;
break;
case CTRL_R:
ctrl_r = make;
key = 0;
break;
case ALT_L:
alt_l = make;
key = 0;
break;
case ALT_R:
alt_r = make;
key = 0;
break;
default:
if (!make) { /* 如果是 Break Code */
key = 0; /* 忽略之 */
}
break;
}
/* 如果 key 不为0说明是可打印字符,否则不做处理 */
if (key) {
output[0] = key;
disp_str(output);
}
}
}
}
/* 从键盘缓冲区读取下一个字节 */
PRIVATE u8 get_byte_from_kbuf()
{
u8 scan_code;
while (kb_in.count <= 0) {} /* 等待下一个字节到来 */
disable_int();
scan_code = *(kb_in.p_tail);
kb_in.p_tail++;
if (kb_in.p_tail == kb_in.buf + KB_IN_BYTES) {
kb_in.p_tail = kb_in.buf;
}
kb_in.count--;
enable_int();
return scan_code;
}这段代码有点长,但实际上除了把函数get_byte_from_kbuf()单独拿出来之外,只是单独处理了Pause和Print Screen两个按键而已。不过这样一来,整个处理过程就发生了变化,每一次调用keyboard_read()都可以处理一个相对完整的过程。如果按下右侧的Alt键产生0xE0、0x38,不必调用两次keyboard_read()。而且,如今所有的按键都已经在处理范围之内了。
不过,组合键的情况还是要多次调用keyboard_read()。想想也是,多个按键调用多次读操作,这也是合理的。
下面来解决第二个问题,就是关于非打印字符的处理。
keyboard_read()这个函数只是负责读取扫描码就可以了,至于如何处理,不应该是它的职责,因为只有更高层次的软件才能根据具体情况做出不同的反应。这样看来,之前我们的打印操作其实也是越俎代庖了。
那么我们再将代码进行如下修改。
代码 kernel/keyboard.c,解析扫描码。
PUBLIC void keyboard_read()
{
...
if ((key != PAUSEBREAK) && (key != PRINTSCREEN)) {
/* 首先判断是 Make Code 还是 Break Code */
make = (scan_code & FLAG_BREAK ? FALSE : TRUE);
/* 先定位到 keymap 中的行 */
keyrow = &keymap[(scan_code & 0x7F) * MAP_COLS];
column = 0;
if (shift_l || shift_r) {
column = 1;
}
if (code_with_E0) {
column = 2;
code_with_E0 = 0;
}
key = keyrow[column];
switch(key) {
case SHIFT_L:
shift_l = make;
break;
case SHIFT_R:
shift_r = make;
break;
case CTRL_L:
ctrl_l = make;
break;
case CTRL_R:
ctrl_r = make;
break;
case ALT_L:
alt_l = make;
break;
case ALT_R:
alt_r = make;
break;
default:
break;
}
if (make) { /* 忽略 Break Code */
key |= shift_l ? FLAG_SHIFT_L : 0;
key |= shift_r ? FLAG_SHIFT_R : 0;
key |= ctrl_l ? FLAG_CTRL_L : 0;
key |= ctrl_r ? FLAG_CTRL_R : 0;
key |= alt_l ? FLAG_ALT_L : 0;
key |= alt_r ? FLAG_ALT_R : 0;
in_process(key);
}
}
}
}这样,无论是Paus、Print Screen,还是其它以0xE0开头的扫描码或普通的单字符扫描码,都会交给函数in_process()来处理。而且,Shift、Alt、Ctrl键的状态会用设置相应位的方式通过key表现出来。我们现在就来写一个简单的in_process()。
代码 kernel/tty.c,in_process。
PUBLIC void in_process(u32 key)
{
char output[2] = {'\0', '\0'};
if (!(key & FLAG_EXT)) {
output[0] = key & 0xFF;
disp_str(output);
}
}注意,这里有一个小技巧。我们打开keyboard.h来看一下,可以看到如下代码所示的情形。
代码 include/keyboard.h,键盘缓冲区。
/* Special keys */
#define ESC (0x01 + FLAG_EXT) /* Esc */
#define TAB (0x02 + FLAG_EXT) /* Tab */
#define ENTER (0x03 + FLAG_EXT) /* Enter */
#define BACKSPACE (0x04 + FLAG_EXT) /* BackSpace */
#define GUI_L (0x05 + FLAG_EXT) /* L GUI */
#define GUI_R (0x06 + FLAG_EXT) /* R GUI */
#define APPS (0x07 + FLAG_EXT) /* APPS */
/* Shift, Ctrl, Alt */
#define SHIFT_L (0x08 + FLAG_EXT) /* L Shift */
#define SHIFT_R (0x09 + FLAG_EXT) /* R Shift */
#define CTRL_L (0x0A + FLAG_EXT) /* L Ctrl */
#define CTRL_R (0x0B + FLAG_EXT) /* R Ctrl */
#define ALT_L (0x0C + FLAG_EXT) /* L Alt */
#define ALT_R (0x0D + FLAG_EXT) /* R Alt */在所有的不可打印字符的定义中,都加了一个FLAG_EXT,这就使得我们在程序中可以非常容易地识别出来。所以当(!(key & FLAG_EXT))为真时,就表明当前字符是一个可打印字符。
好了,现在我们make并执行,执行后的效果如下图所示。

我们可以成功的输出26个英文字母,包括大写和小写,同时还输出了数字以及其它一些字符。当按下F1、F2等功能键时,程序不做反应。这表明我们的修改是成功的。
另外,不管是单键还是组合键,都使用了一个32位整数key来表示。因为可打印字符的ASCII是8位,而我们将特殊的按键定义成了FLAG_EXT和一个单字节数的和,也不超过9位,这样,我们还剩余很多位来表示Shift、Alt、Ctrl等键的状态,一个整型记载的信息足够我们了解当前的按键情况。
公众号

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!