机器学习系列10:数据预处理——特征缩放
这里我们要换使用 UCI 上面的红酒数据集了。下载地址:
https://archive.ics.uci.edu/dataset/109/wine
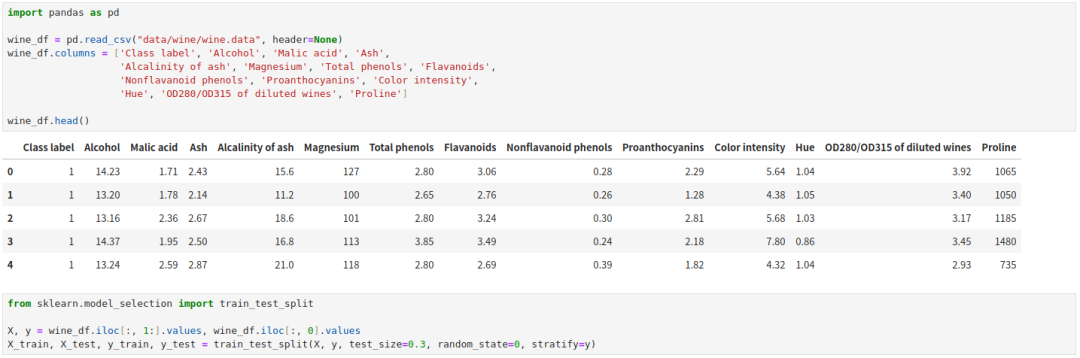
这个数据集含有三种不同的红酒,共 178 个样本,每个样本由 13 个不同化学属性。
我们首先将数据集分层采样划分 70% 出来作为训练集,剩余 30% 用作测试集。
特征缩放(feature scaling)是数据预处理步骤中及其容易被忽略的一步。除了决策树和随机森林这两种不需要进行特征缩放的算法之外。绝大多数机器学习算法及优化算法(比如梯度下降)都期望特征取值在同样的范围。
为什么要特征缩放,考虑一下?kNN?算法,如果我们有两个特征,特征 A 的取值范围在 [1,10],特征 B 的取值范围在 [1, 100000]。那么在计算欧式距离时,特征 A 的贡献几乎被特征 B 给覆盖了。
目前有归一化(normalization)和标准化(standardization)两种方法将数据集的所有特征缩放到同一个范围内。
归一化
归一化是最小最大缩放(min-max scaling)的一种特殊形式,它将特征的取值范围缩放到 [0,1]。
我们在每个特征列上执行下面的操作就可以实现最小最大缩放。
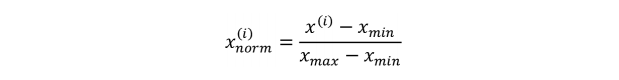
通过 scikit-learn 提供的 MinMaxScaler 实现最小最大缩放。

我们用训练集拟合(fit)了每个特征的列的最大值最小值,然后在训练集上执行最小最大缩放转换(transform),不过我们用一个 fit_transform 函数同时做了这两步。
然后根据训练集上每列的最大值最小值,我们对测试集进行转换(transform)。
标准化
尽管通过最小最大缩放实现的归一化在我们需要特征列中取值在一个限定范围时很常用。
但是对于许多机器学习算法而言,标准化更具有实际意义,尤其是像梯度下降这样的优化算法。
标准化使得我们将特征列的取值缩放成均值为 0 和标准差为 1,这样就和正态分布具有同样的参数了(0 均值、单位方差)。通过标准化,模型学习参数就更加简单,因为像逻辑回归和?SVM?算法都是将模型参数初始化成 0 或者其他很小的随机值。
但是标准化不会改变数据分布的形状,也不会将非正态分布的数据转成正态分布。
相对于最小最大缩放来说,标准化之后,算法对异常值不那么不敏感。
标准化的公式如下。
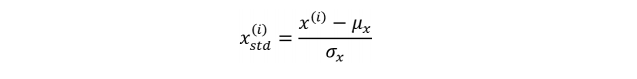
不用担心,scikit-learn 也提供了 StandardScaler 实现标准化。
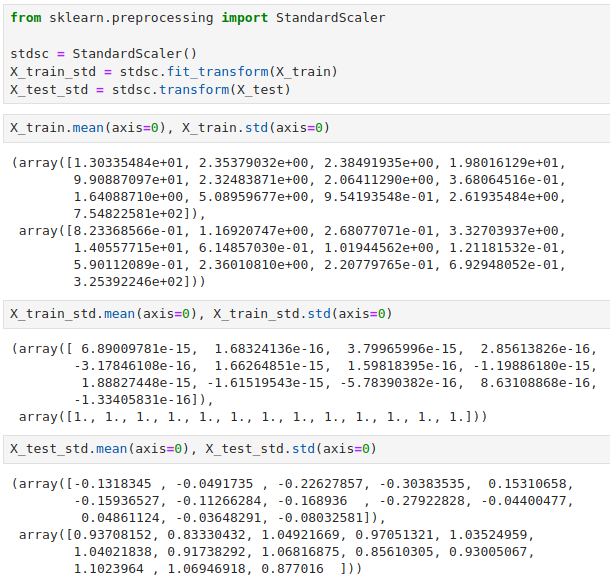
同样地,我们用训练集拟合得到每个特征列的均值和标准差,然后再去转换训练集和测试集数据。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!