雪花算法(几种常见的雪花算法生成ID方案简单介绍:Hutool、百度Uid-Generator、美团Leaf、Yitter)
文章目录
- 1.生成id的几种方式
- 2. 雪花算法
- 2.1 雪花算法介绍
- 2.2 市面上几种雪花算法的实现
- ---------------百度UidGenerator 介绍开始--------------
- Snowflake算法
- CachedUidGenerator
- Quick Start
- ---------------百度UidGenerator 介绍结束--------------
- ---------------美团Leaf 介绍开始--------------
- Introduction
- Quick Start
- ---------------美团Leaf 介绍结束--------------
- ---------------yitter SnowFlake IdGenerator 介绍开始--------------
- ? idgenerator-Java
1.生成id的几种方式
-
- UUID (无序,基本可以认为不会重复,有根据mac地址生成(这种会暴露隐私)、时间、或者名称生成)
-
- 数据库自增主键(分表的情况下会有问题,无法保证唯一性)
-
- redis的INCR和INCEBY(实际项目中没见过这样做的)
-
- 雪花算法生成id(有序,不需要依赖中间件,但是因为有序可能会暴露隐私,导致安全问题;依赖时间戳,若时间快了重新校准,有时钟回拨问题)
2. 雪花算法
2.1 雪花算法介绍
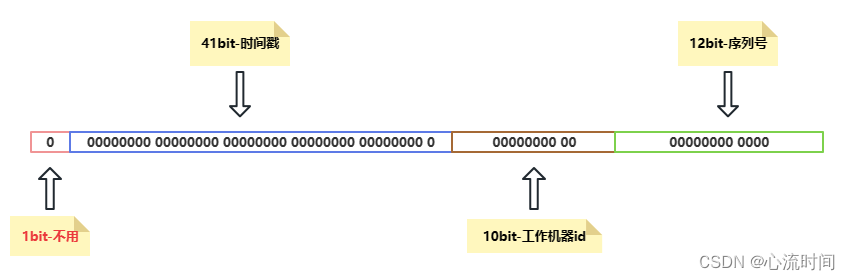
雪花算法的原理就是生成一个的 64 位比特位的 long 类型的唯一 id。
- 1:最高 1 位是符号位,固定值 0,表示id 是正整数
- 41:接下来 41 位存储毫秒级时间戳,2^41/(1000606024365)=69,大概可以使用 69 年。
- 10:再接下 10 位存储机器码,包括 5 位 datacenterId 和 5 位 workerId。最多可以部署 2^10=1024 台机器。
- 12:最后 12 位存储序列号。同一毫秒时间戳时,通过这个递增的序列号来区分。即对于同一台机器而言,同一毫秒时间戳下,可以生成 2^12=4096 个不重复 id。
可以将雪花算法作为一个单独的服务进行部署,然后需要全局唯一 id 的系统,请求雪花算法服务获取 id 即可。
对于每一个雪花算法服务,需要先指定 10 位的机器码,这个根据自身业务进行设定即可。例如机房号+机器号,机器号+服务号,或者是其他可区别标识的 10 位比特位的整数值都行。
2.2 市面上几种雪花算法的实现
-
- hutool版
-
- 百度UidGenerator
-
- 美团Leaf
-
- twitter-archive/snowflake(github仓库已经不对外开放)
-
- yitter / 多语言新雪花算法(SnowFlake IdGenerator),没上面几个出名,是码云上较火的一个snowflake项目
2.2.1 hutool版
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.5.1</version>
</dependency>
Snowflake snowflake = IdUtil.createSnowflake(workerId, datacenterId);
long id = snowflake.nextId();
---------------百度UidGenerator 介绍开始--------------
2.2.2 百度版:UidGenerator
UidGenerator是Java实现的, 基于Snowflake算法的唯一ID生成器。UidGenerator以组件形式工作在应用项目中,
支持自定义workerId位数和初始化策略, 从而适用于docker等虚拟化环境下实例自动重启、漂移等场景。
在实现上, UidGenerator通过借用未来时间来解决sequence天然存在的并发限制; 采用RingBuffer来缓存已生成的UID, 并行化UID的生产和消费,
同时对CacheLine补齐,避免了由RingBuffer带来的硬件级「伪共享」问题. 最终单机QPS可达600万。
依赖版本:Java8及以上版本,
MySQL(内置WorkerID分配器, 启动阶段通过DB进行分配; 如自定义实现, 则DB非必选依赖)
Snowflake算法

Snowflake算法描述:指定机器 & 同一时刻 & 某一并发序列,是唯一的。据此可生成一个64 bits的唯一ID(long)。默认采用上图字节分配方式:
-
sign(1bit)
固定1bit符号标识,即生成的UID为正数。 -
delta seconds (28 bits)
当前时间,相对于时间基点"2016-05-20"的增量值,单位:秒,最多可支持约8.7年 -
worker id (22 bits)
机器id,最多可支持约420w次机器启动。内置实现为在启动时由数据库分配,默认分配策略为用后即弃,后续可提供复用策略。 -
sequence (13 bits)
每秒下的并发序列,13 bits可支持每秒8192个并发。
以上参数均可通过Spring进行自定义
CachedUidGenerator
RingBuffer环形数组,数组每个元素成为一个slot。RingBuffer容量,默认为Snowflake算法中sequence最大值,且为2^N。可通过boostPower配置进行扩容,以提高RingBuffer
读写吞吐量。
Tail指针、Cursor指针用于环形数组上读写slot:
-
Tail指针
表示Producer生产的最大序号(此序号从0开始,持续递增)。Tail不能超过Cursor,即生产者不能覆盖未消费的slot。当Tail已赶上curosr,此时可通过rejectedPutBufferHandler指定PutRejectPolicy -
Cursor指针
表示Consumer消费到的最小序号(序号序列与Producer序列相同)。Cursor不能超过Tail,即不能消费未生产的slot。当Cursor已赶上tail,此时可通过rejectedTakeBufferHandler指定TakeRejectPolicy
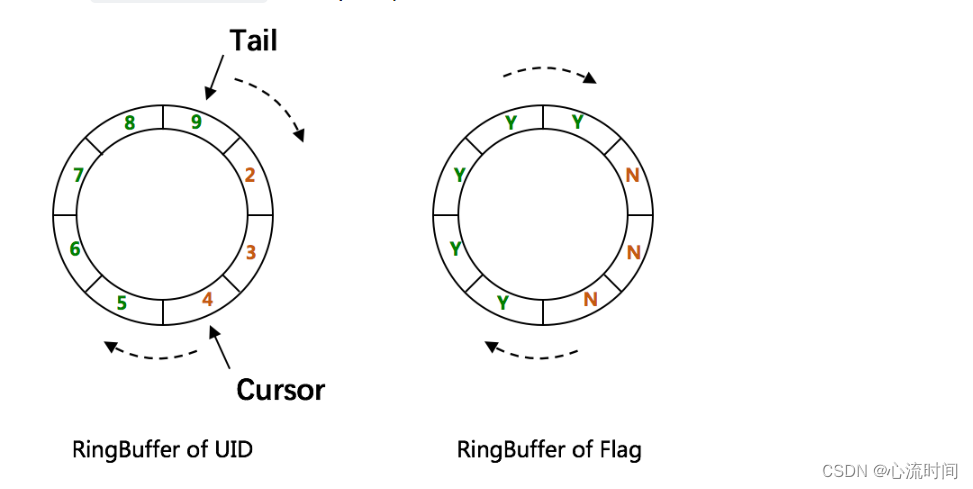
CachedUidGenerator采用了双RingBuffer,Uid-RingBuffer用于存储Uid、Flag-RingBuffer用于存储Uid状态(是否可填充、是否可消费)
由于数组元素在内存中是连续分配的,可最大程度利用CPU cache以提升性能。但同时会带来「伪共享」FalseSharing问题,为此在Tail、Cursor指针、Flag-RingBuffer中采用了CacheLine
补齐方式。
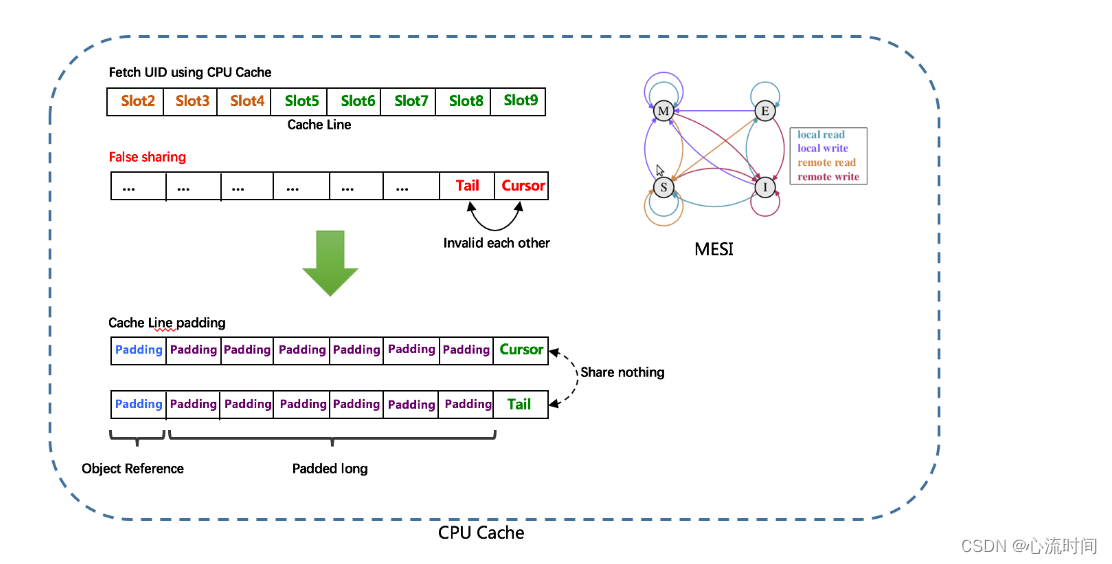
RingBuffer填充时机
-
初始化预填充
RingBuffer初始化时,预先填充满整个RingBuffer. -
即时填充
Take消费时,即时检查剩余可用slot量(tail-cursor),如小于设定阈值,则补全空闲slots。阈值可通过paddingFactor来进行配置,请参考Quick Start中CachedUidGenerator配置 -
周期填充
通过Schedule线程,定时补全空闲slots。可通过scheduleInterval配置,以应用定时填充功能,并指定Schedule时间间隔
Quick Start
这里介绍如何在基于Spring的项目中使用UidGenerator, 具体流程如下(现在应该都是springboot项目,大家自己适配即可,官网还是spring的安装介绍):
步骤1: 安装依赖
设置环境变量
maven无须安装, 设置好MAVEN_HOME即可. 可像下述脚本这样设置JAVA_HOME和MAVEN_HOME, 如已设置请忽略.
export MAVEN_HOME=/xxx/xxx/software/maven/apache-maven-3.3.9
export PATH=$MAVEN_HOME/bin:$PATH
JAVA_HOME="/Library/Java/JavaVirtualMachines/jdk1.8.0_91.jdk/Contents/Home";
export JAVA_HOME;
步骤2: 创建表WORKER_NODE
运行sql脚本以导入表WORKER_NODE, 脚本如下:
DROP DATABASE IF EXISTS `xxxx`;
CREATE DATABASE `xxxx` ;
use `xxxx`;
DROP TABLE IF EXISTS WORKER_NODE;
CREATE TABLE WORKER_NODE
(
ID BIGINT NOT NULL AUTO_INCREMENT COMMENT 'auto increment id',
HOST_NAME VARCHAR(64) NOT NULL COMMENT 'host name',
PORT VARCHAR(64) NOT NULL COMMENT 'port',
TYPE INT NOT NULL COMMENT 'node type: ACTUAL or CONTAINER',
LAUNCH_DATE DATE NOT NULL COMMENT 'launch date',
MODIFIED TIMESTAMP NOT NULL COMMENT 'modified time',
CREATED TIMESTAMP NOT NULL COMMENT 'created time',
PRIMARY KEY(ID)
)
COMMENT='DB WorkerID Assigner for UID Generator',ENGINE = INNODB;
修改mysql.properties配置中, jdbc.url, jdbc.username和jdbc.password, 确保库地址, 名称, 端口号, 用户名和密码正确.
步骤3: 修改Spring配置
提供了两种生成器: DefaultUidGenerator、CachedUidGenerator。如对UID生成性能有要求, 请使用CachedUidGenerator
对应Spring配置分别为: default-uid-spring.xml、cached-uid-spring.xml
DefaultUidGenerator配置
<!-- DefaultUidGenerator -->
<bean id="defaultUidGenerator" class="com.xin.demo.baidu.fsg.uid.impl.DefaultUidGenerator" lazy-init="false">
<property name="workerIdAssigner" ref="disposableWorkerIdAssigner"/>
<!-- Specified bits & epoch as your demand. No specified the default value will be used -->
<property name="timeBits" value="29"/>
<property name="workerBits" value="21"/>
<property name="seqBits" value="13"/>
<property name="epochStr" value="2016-09-20"/>
</bean>
<!-- 用完即弃的WorkerIdAssigner,依赖DB操作 -->
<bean id="disposableWorkerIdAssigner" class="com.xin.demo.baidu.fsg.uid.worker.DisposableWorkerIdAssigner"/>
CachedUidGenerator配置
<!-- CachedUidGenerator -->
<bean id="cachedUidGenerator" class="com.xin.demo.baidu.fsg.uid.impl.CachedUidGenerator">
<property name="workerIdAssigner" ref="disposableWorkerIdAssigner"/>
<!-- 以下为可选配置, 如未指定将采用默认值 -->
<!-- Specified bits & epoch as your demand. No specified the default value will be used -->
<property name="timeBits" value="29"/>
<property name="workerBits" value="21"/>
<property name="seqBits" value="13"/>
<property name="epochStr" value="2016-09-20"/>
<!-- RingBuffer size扩容参数, 可提高UID生成的吞吐量. -->
<!-- 默认:3, 原bufferSize=8192, 扩容后bufferSize= 8192 << 3 = 65536 -->
<property name="boostPower" value="3"></property>
<!-- 指定何时向RingBuffer中填充UID, 取值为百分比(0, 100), 默认为50 -->
<!-- 举例: bufferSize=1024, paddingFactor=50 -> threshold=1024 * 50 / 100 = 512. -->
<!-- 当环上可用UID数量 < 512时, 将自动对RingBuffer进行填充补全 -->
<property name="paddingFactor" value="50"></property>
<!-- 另外一种RingBuffer填充时机, 在Schedule线程中, 周期性检查填充 -->
<!-- 默认:不配置此项, 即不实用Schedule线程. 如需使用, 请指定Schedule线程时间间隔, 单位:秒 -->
<property name="scheduleInterval" value="60"></property>
<!-- 拒绝策略: 当环已满, 无法继续填充时 -->
<!-- 默认无需指定, 将丢弃Put操作, 仅日志记录. 如有特殊需求, 请实现RejectedPutBufferHandler接口(支持Lambda表达式) -->
<property name="rejectedPutBufferHandler" ref="XxxxYourPutRejectPolicy"></property>
<!-- 拒绝策略: 当环已空, 无法继续获取时 -->
<!-- 默认无需指定, 将记录日志, 并抛出UidGenerateException异常. 如有特殊需求, 请实现RejectedTakeBufferHandler接口(支持Lambda表达式) -->
<property name="rejectedTakeBufferHandler" ref="XxxxYourTakeRejectPolicy"></property>
</bean>
<!-- 用完即弃的WorkerIdAssigner, 依赖DB操作 -->
<bean id="disposableWorkerIdAssigner" class="com.xin.demo.baidu.fsg.uid.worker.DisposableWorkerIdAssigner"/>
Mybatis配置
mybatis-spring.xml配置说明如下:
<!-- Spring annotation扫描 -->
<context:component-scan base-package="com.baidu.fsg.uid" />
<bean id="sqlSessionFactory" class="org.mybatis.spring.SqlSessionFactoryBean">
<property name="dataSource" ref="dataSource" />
<property name="mapperLocations" value="classpath:/META-INF/mybatis/mapper/M_WORKER*.xml" />
</bean>
<!-- 事务相关配置 -->
<tx:annotation-driven transaction-manager="transactionManager" order="1" />
<bean id="transactionManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager">
<property name="dataSource" ref="dataSource" />
</bean>
<!-- Mybatis Mapper扫描 -->
<bean class="org.mybatis.spring.mapper.MapperScannerConfigurer">
<property name="annotationClass" value="org.springframework.stereotype.Repository" />
<property name="basePackage" value="com.baidu.fsg.uid.worker.dao" />
<property name="sqlSessionFactoryBeanName" value="sqlSessionFactory" />
</bean>
<!-- 数据源配置 -->
<bean id="dataSource" parent="abstractDataSource">
<property name="driverClassName" value="${mysql.driver}" />
<property name="maxActive" value="${jdbc.maxActive}" />
<property name="url" value="${jdbc.url}" />
<property name="username" value="${jdbc.username}" />
<property name="password" value="${jdbc.password}" />
</bean>
<bean id="abstractDataSource" class="com.alibaba.druid.pool.DruidDataSource" destroy-method="close">
<property name="filters" value="${datasource.filters}" />
<property name="defaultAutoCommit" value="${datasource.defaultAutoCommit}" />
<property name="initialSize" value="${datasource.initialSize}" />
<property name="minIdle" value="${datasource.minIdle}" />
<property name="maxWait" value="${datasource.maxWait}" />
<property name="testWhileIdle" value="${datasource.testWhileIdle}" />
<property name="testOnBorrow" value="${datasource.testOnBorrow}" />
<property name="testOnReturn" value="${datasource.testOnReturn}" />
<property name="validationQuery" value="${datasource.validationQuery}" />
<property name="timeBetweenEvictionRunsMillis" value="${datasource.timeBetweenEvictionRunsMillis}" />
<property name="minEvictableIdleTimeMillis" value="${datasource.minEvictableIdleTimeMillis}" />
<property name="logAbandoned" value="${datasource.logAbandoned}" />
<property name="removeAbandoned" value="${datasource.removeAbandoned}" />
<property name="removeAbandonedTimeout" value="${datasource.removeAbandonedTimeout}" />
</bean>
<bean id="batchSqlSession" class="org.mybatis.spring.SqlSessionTemplate">
<constructor-arg index="0" ref="sqlSessionFactory" />
<constructor-arg index="1" value="BATCH" />
</bean>
步骤4: 运行示例单测
运行单测CachedUidGeneratorTest, 展示UID生成、解析等功能
@Resource
private UidGenerator uidGenerator;
@Test
public void testSerialGenerate() {
// Generate UID
long uid = uidGenerator.getUID();
// Parse UID into [Timestamp, WorkerId, Sequence]
// {"UID":"180363646902239241","parsed":{ "timestamp":"2017-01-19 12:15:46", "workerId":"4", "sequence":"9" }}
System.out.println(uidGenerator.parseUID(uid));
}
关于UID比特分配的建议
对于并发数要求不高、期望长期使用的应用, 可增加timeBits位数, 减少seqBits位数. 例如节点采取用完即弃的WorkerIdAssigner策略, 重启频率为12次/天,
那么配置成{"workerBits":23,"timeBits":31,"seqBits":9}时, 可支持28个节点以整体并发量14400 UID/s的速度持续运行68年.
对于节点重启频率频繁、期望长期使用的应用, 可增加workerBits和timeBits位数, 减少seqBits位数. 例如节点采取用完即弃的WorkerIdAssigner策略, 重启频率为24*12次/天,
那么配置成{"workerBits":27,"timeBits":30,"seqBits":6}时, 可支持37个节点以整体并发量2400 UID/s的速度持续运行34年.
吞吐量测试
在MacBook Pro(2.7GHz Intel Core i5, 8G DDR3)上进行了CachedUidGenerator(单实例)的UID吞吐量测试.
首先固定住workerBits为任选一个值(如20), 分别统计timeBits变化时(如从25至32, 总时长分别对应1年和136年)的吞吐量, 如下表所示:
| timeBits | 25 | 26 | 27 | 28 | 29 | 30 | 31 | 32 |
|---|---|---|---|---|---|---|---|---|
| throughput | 6,831,465 | 7,007,279 | 6,679,625 | 6,499,205 | 6,534,971 | 7,617,440 | 6,186,930 | 6,364,997 |
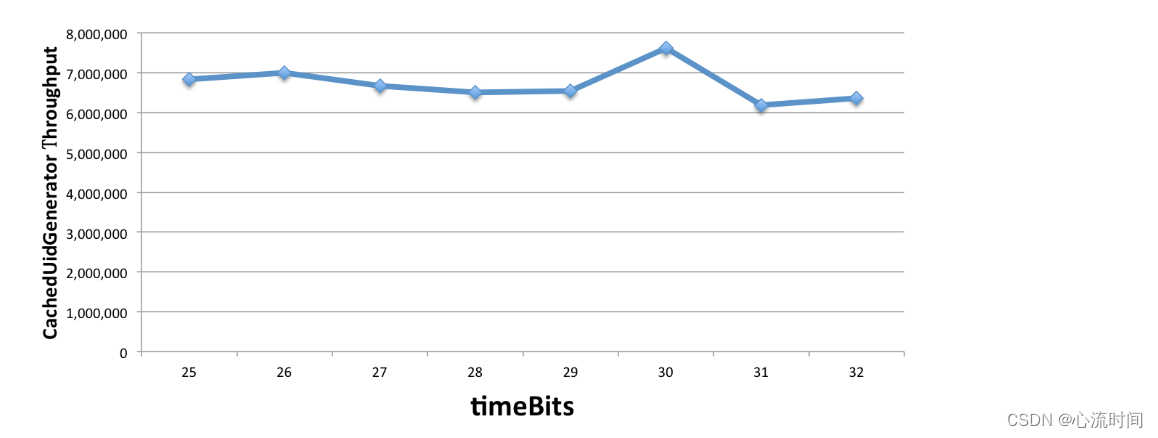
再固定住timeBits为任选一个值(如31), 分别统计workerBits变化时(如从20至29, 总重启次数分别对应1百万和500百万)的吞吐量, 如下表所示:
| workerBits | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 |
|---|---|---|---|---|---|---|---|---|---|---|
| throughput | 6,186,930 | 6,642,727 | 6,581,661 | 6,462,726 | 6,774,609 | 6,414,906 | 6,806,266 | 6,223,617 | 6,438,055 | 6,435,549 |
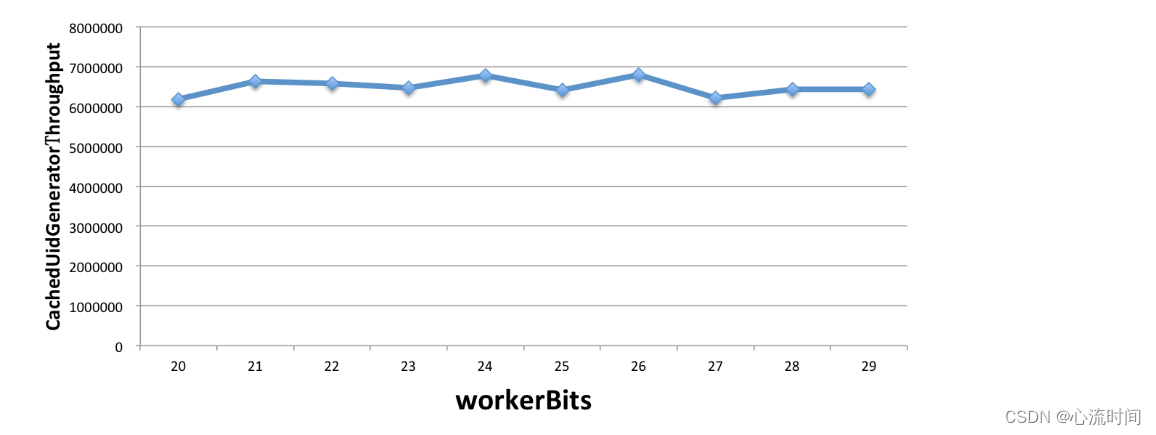
由此可见, 不管如何配置, CachedUidGenerator总能提供600万/s的稳定吞吐量, 只是使用年限会有所减少. 这真的是太棒了.
最后, 固定住workerBits和timeBits位数(如23和31), 分别统计不同数目(如1至8,本机CPU核数为4)的UID使用者情况下的吞吐量,
| workerBits | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|---|
| throughput | 6,462,726 | 6,542,259 | 6,077,717 | 6,377,958 | 7,002,410 | 6,599,113 | 7,360,934 | 6,490,969 |
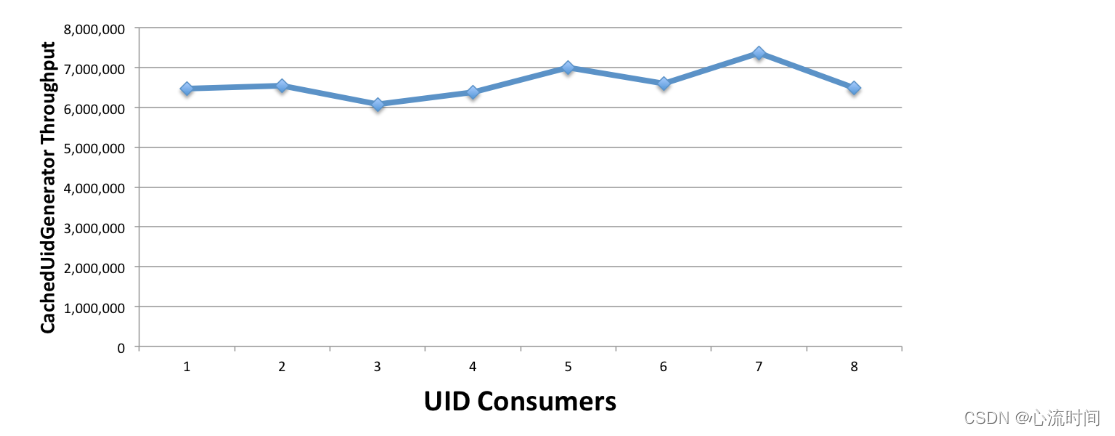
---------------百度UidGenerator 介绍结束--------------
---------------美团Leaf 介绍开始--------------
2.2.3 美团版:Leaf
There are no two identical leaves in the world.
世界上没有两片完全相同的树叶。
? — 莱布尼茨
Introduction
Leaf 最早期需求是各个业务线的订单ID生成需求。在美团早期,有的业务直接通过DB自增的方式生成ID,有的业务通过redis缓存来生成ID,也有的业务直接用UUID这种方式来生成ID。以上的方式各自有各自的问题,因此我们决定实现一套分布式ID生成服务来满足需求。具体Leaf 设计文档见: leaf 美团分布式ID生成服务
目前Leaf覆盖了美团点评公司内部金融、餐饮、外卖、酒店旅游、猫眼电影等众多业务线。在4C8G VM基础上,通过公司RPC方式调用,QPS压测结果近5w/s,TP999 1ms。
Quick Start
使用starter注解启动leaf
https://github.com/Meituan-Dianping/Leaf/blob/feature/spring-boot-starter/README_CN.md
Leaf Server
我们提供了一个基于spring boot的HTTP服务来获取ID
配置介绍
Leaf 提供两种生成的ID的方式(号段模式和snowflake模式),你可以同时开启两种方式,也可以指定开启某种方式(默认两种方式为关闭状态)。
Leaf Server的配置都在leaf-server/src/main/resources/leaf.properties中
| 配置项 | 含义 | 默认值 |
|---|---|---|
| leaf.name | leaf 服务名 | |
| leaf.segment.enable | 是否开启号段模式 | false |
| leaf.jdbc.url | mysql 库地址 | |
| leaf.jdbc.username | mysql 用户名 | |
| leaf.jdbc.password | mysql 密码 | |
| leaf.snowflake.enable | 是否开启snowflake模式 | false |
| leaf.snowflake.zk.address | snowflake模式下的zk地址 | |
| leaf.snowflake.port | snowflake模式下的服务注册端口 |
号段模式
如果使用号段模式,需要建立DB表,并配置leaf.jdbc.url, leaf.jdbc.username, leaf.jdbc.password
如果不想使用该模式配置leaf.segment.enable=false即可。
创建数据表
CREATE DATABASE leaf
CREATE TABLE `leaf_alloc` (
`biz_tag` varchar(128) NOT NULL DEFAULT '',
`max_id` bigint(20) NOT NULL DEFAULT '1',
`step` int(11) NOT NULL,
`description` varchar(256) DEFAULT NULL,
`update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`biz_tag`)
) ENGINE=InnoDB;
insert into leaf_alloc(biz_tag, max_id, step, description) values('leaf-segment-test', 1, 2000, 'Test leaf Segment Mode Get Id')
配置相关数据项
在leaf.properties中配置leaf.jdbc.url, leaf.jdbc.username, leaf.jdbc.password参数
Snowflake模式
算法取自twitter开源的snowflake算法。
如果不想使用该模式配置leaf.snowflake.enable=false即可。
配置zookeeper地址
在leaf.properties中配置leaf.snowflake.zk.address,配置leaf 服务监听的端口leaf.snowflake.port。
运行Leaf Server
打包服务
git clone git@github.com:Meituan-Dianping/Leaf.git
//按照上面的号段模式在工程里面配置好
cd leaf
mvn clean install -DskipTests
cd leaf-server
运行服务
注意:首先得先配置好数据库表或者zk地址
mvn方式
mvn spring-boot:run
脚本方式
sh deploy/run.sh
测试
#segment
curl http://localhost:8080/api/segment/get/leaf-segment-test
#snowflake
curl http://localhost:8080/api/snowflake/get/test
监控页面
号段模式:http://localhost:8080/cache
Leaf Core
当然,为了追求更高的性能,需要通过RPC Server来部署Leaf 服务,那仅需要引入leaf-core的包,把生成ID的API封装到指定的RPC框架中即可。
注意事项
注意现在leaf使用snowflake模式的情况下 其获取ip的逻辑直接取首个网卡ip【特别对于会更换ip的服务要注意】避免浪费workId
---------------美团Leaf 介绍结束--------------
2.2.4 Twitter版:twitter-archive/snowflake(github仓库已经不对外开放)
---------------yitter SnowFlake IdGenerator 介绍开始--------------
2.2.5 yitter / 多语言新雪花算法(SnowFlake IdGenerator),没上面几个出名,但也是码云上较火的一个snowflake项目
? idgenerator-Java
运行环境
JDK 1.8+
引用 maven 包
<dependency>
<groupId>com.github.yitter</groupId>
<artifactId>yitter-idgenerator</artifactId>
<version>1.0.6</version>
</dependency>
调用示例(Java)
第1步,全局 初始化(应用程序启动时执行一次):
// 创建 IdGeneratorOptions 对象,可在构造函数中输入 WorkerId:
IdGeneratorOptions options = new IdGeneratorOptions(Your_Unique_Worker_Id);
// options.WorkerIdBitLength = 10; // 默认值6,限定 WorkerId 最大值为2^6-1,即默认最多支持64个节点。
// options.SeqBitLength = 6; // 默认值6,限制每毫秒生成的ID个数。若生成速度超过5万个/秒,建议加大 SeqBitLength 到 10。
// options.BaseTime = Your_Base_Time; // 如果要兼容老系统的雪花算法,此处应设置为老系统的BaseTime。
// ...... 其它参数参考 IdGeneratorOptions 定义。
// 保存参数(务必调用,否则参数设置不生效):
YitIdHelper.setIdGenerator(options);
// 以上过程只需全局一次,且应在生成ID之前完成。
第2步,生成ID:
// 初始化后,在任何需要生成ID的地方,调用以下方法:
long newId = YitIdHelper.nextId();
示例代码
public static void main(String[] args) {
for (int i = 0; i < 20; i++) {
long id = YitIdHelper.nextId();
if (i < 9) {
System.out.println("雪花算法生成第0" + (i + 1) + "个id:" + id);
} else {
System.out.println("雪花算法生成第"+(i +1)+"个id:"+ id);
}
}
}
打印
雪花算法生成第01个id: 494222368878661
雪花算法生成第02个id: 494222368878662
雪花算法生成第03个id: 494222368878663
雪花算法生成第04个id: 494222368882757
雪花算法生成第05个id: 494222368882758
雪花算法生成第06个id: 494222368882759
雪花算法生成第07个id: 494222368882760
雪花算法生成第08个id: 494222368882761
雪花算法生成第09个id: 494222368882762
雪花算法生成第10个id: 494222368882763
雪花算法生成第11个id: 494222368882764
雪花算法生成第12个id: 494222368882765
雪花算法生成第13个id: 494222368882766
雪花算法生成第14个id: 494222368882767
雪花算法生成第15个id: 494222368882768
雪花算法生成第16个id: 494222368882769
雪花算法生成第17个id: 494222368882770
雪花算法生成第18个id: 494222368882771
雪花算法生成第19个id: 494222368882772
雪花算法生成第20个id: 494222368882773
---------------yitter SnowFlake IdGenerator 介绍结束--------------
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!