ocrmypdf_pdf识别
安装
安装说明?
https://ocrmypdf.readthedocs.io/en/latest/installation.html#native-windows
提到需要的软件:
Python 3.7 (64-bit) or later
Tesseract 4.0 or later
Ghostscript 9.50 or later
安装 ocrmypdf
pip install ocrmypdf添加语言包
https://ocrmypdf.readthedocs.io/en/latest/languages.html
从?https://github.com/tesseract-ocr/tessdata/??,解压里面的扩展名为traineddata的文件,复制到?C:\Program?Files\Tesseract-OCR\tessdata??{Tesseract-OCR安装目录}\tessdata
使用
命令行
ocrmypdf?-l chi_sim?--pdf-renderer tesseract --output-type pdf source.pdf ocr.pdf
-l language的意思,chi_sim对应?C:\Program?Files\Tesseract-OCR\tessdata\ 路径下的 chi_sim.traineddata 文件,如果是中英文混排的情况,就把-l chi_sim改成
-l chi_sim+eng
更多使用说明?https://ocrmypdf.readthedocs.io/en/latest/cookbook.html
API
使用说明Using the OCRmyPDF API — ocrmypdf 16.0.3.dev5+g14365d1 documentation
import ocrmypdf
if __name__ == '__main__': # To ensure correct behavior on Windows and macOS
ocrmypdf.ocr('input.pdf', 'output.pdf', deskew=True)中文处理
问题
由于ocrmypdf对中文pdf识别后存在空格,根据以下链接知道
extra spaces in result when ocr chinese · Issue #991 · tesseract-ocr/tesseract · GitHub
| 1 |
|
正如这个链接所问的,extra space in the result pdf when the input pdf is in Chinese · Issue #715 · ocrmypdf/OCRmyPDF · GitHub,那么如何在ocrmypdf中设置呢?
解决过程
首先尝试的试试按照使用--tesseract-config方法(下面pdf9.2.5章节):
https://media.readthedocs.org/pdf/ocrmypdf/latest/ocrmypdf.pdf

命令:
ocrmypdf -l chi_sim --tesseract-oem 1 --tesseract-pagesegmode 6 --tesseract-config C:\Users\Administrator\Desktop\my.cfg C:\Users\Administrator\Desktop\11.pdf 121.pdf
?或者(二者均可)
ocrmypdf -l chi_sim --tesseract-config C:\Users\Administrator\Desktop\my.cfg C:\Users\Administrator\Desktop\11.pdf 121.pdf
其中my.cfg是一个本地文件:里面内容是
preserve_interword_spaces 1
经测试:上面的121.pdf还是无法实现pdf复制为不带空格的文字,但是导出txt可以实现不带空格。
这个评论是错的。https://github.com/ocrmypdf/OCRmyPDF/issues/885#issuecomment-1033367021?这个网友说了当你选择OEM选择LSTM模型(如下面说明,oem选择1或者2)时候,--tesseract-config不会生效,事实上会生效的。(被这个误导了很久)
下面资料来源于:All Tesseract OCR options – Muthukrishnan
也可以参考这里:用于光学字符识别的 Tesseract - 知乎
OCR options:
--tessdata-dir PATH Specify the location of tessdata path.
--user-words PATH Specify the location of user words file.
--user-patterns PATH Specify the location of user patterns file.
-l LANG[+LANG] Specify language(s) used for OCR.
-c VAR=VALUE Set value for config variables.
Multiple -c arguments are allowed.
--psm NUM Specify page segmentation mode.
--oem NUM Specify OCR Engine mode.
NOTE: These options must occur before any configfile.
Page segmentation modes:
0 Orientation and script detection (OSD) only.
1 Automatic page segmentation with OSD.
2 Automatic page segmentation, but no OSD, or OCR.
3 Fully automatic page segmentation, but no OSD. (Default)
4 Assume a single column of text of variable sizes.
5 Assume a single uniform block of vertically aligned text.
6 Assume a single uniform block of text.
7 Treat the image as a single text line.
8 Treat the image as a single word.
9 Treat the image as a single word in a circle.
10 Treat the image as a single character.
11 Sparse text. Find as much text as possible in no particular order.
12 Sparse text with OSD.
13 Raw line. Treat the image as a single text line,
bypassing hacks that are Tesseract-specific.
OCR Engine modes: (see https://github.com/tesseract-ocr/tesseract/wiki#linux)
0 Legacy engine only.
1 Neural nets LSTM engine only.
2 Legacy + LSTM engines.
3 Default, based on what is available.
另外,我还测试了导出txt的结果,当你使用--tesseract-config C:\Users\Administrator\Desktop\my.cfg 之后可以保证导出的txt是不带空格的,pdf还是复制空格
再次使用命令:(其中--sidecar 121.txt表示输出txt)
ocrmypdf --force-ocr --tesseract-config C:\Users\Administrator\Desktop\my.cfg -l chi_sim --sidecar 121.txt C:\Users\Administrator\Desktop\11.pdf 121.pdf
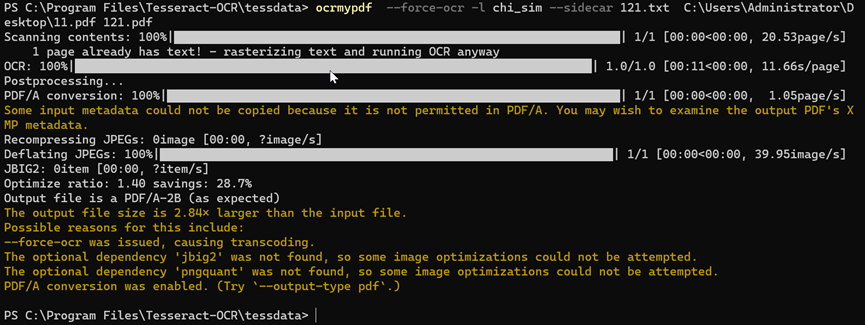
效果:输出121.txt没有空格,121.pdf复制还有空格。??


经过测试:跟这个里面extra space in the result pdf when the input pdf is in Chinese · Issue #715 · ocrmypdf/OCRmyPDF · GitHub说的一样(但是他是ocrmypdf的老版本)即输出txt才会出现没有空格,pdf还是复制有空格。
Ocrmypdf的作者@jbarlow83一直说的是阅读器问题,但是事实上不是阅读器问题。?
也就是说我们只是部分解决(曲线救国)了pdf出现文本图层含有多余空格的问题。?
目前我测试了其他的大量方法均无效。作者也从未给出有效解决方案,目前日韩网友(Detection of extra spaces while running own trained tesseract for Korean OCR · Issue #1009 · tesseract-ocr/tesseract · GitHub)也存在这个问题。
以上总结:
(1)使用--tesseract-config设置可以实现:导出txt不带空格,但是pdf复制带空格。
(2)不使用--tesseract-config设置效果:导出txt带空格,pdf复制也是带空格。
最终思路
使用config设置,输出txt以复制文字。如果有大神可以继续给我提示,谢谢!
最佳思路:
?ocrmypdf --force-ocr --tesseract-config C:\Users\Administrator\Desktop\my.cfg -l chi_sim --sidecar out.txt C:\Users\Administrator\Desktop\input.pdf output.pdf?
彩蛋:测试数据与做好的my.cfg
测试数据:11.pdf官方版下载丨最新版下载丨绿色版下载丨APP下载-123云盘? 提取码:newt
做好的my.cfg:?https://www.123pan.com/s/9Rn9-qhQpH.html?
致谢
上面链接分享者。还有这个:https://github.com/dahuoyzs/javapdf/blob/master/OCRmyPDF%E4%BD%BF%E7%94%A8%E6%95%99%E7%A8%8B.md
后续
作者给我的最新回答是,"请理解这个问题是由于Tesseract产生的PDF,一些PDF阅读器不能正确解释,目前没有人有解决办法。"
我测试了tesseract v5.3.1.20230401出现的情况:
??tesseract input.png out -l chi_sim --oem 1 --psm 6 -c preserve_interword_spaces=1 pdf?
我得到了与ocrmypdf相同的结果:输出txt没有空格,但从pdf复制的文本仍然有空格。
因此,这个问题发生在Tesseract而不是ocrmypdf。这个结论需要让更多的用户知道。
最终篇
?目前看来,要想ocrmypdf使得输出pdf不出现复制文字的空格,唯一且不算特别好的解决方案就是使用oem 0(采取非LSTM模型,但是识别效果不好)
ocrmypdf -l chi_sim --tesseract-oem 0 input.pdf output.pdf
这种方法直接复制pdf的文字,不会出现空格,但是复制的文字有的识别不正确。
?这位网友的测试证实了我的说法:Chinese recognition was incorrectly segmented by spaces · Issue #2814 · tesseract-ocr/tesseract · GitHub
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!