【扩散模型】ControlNet从原理到实战
ControlNet从原理到实战
ControlNet是一种通过添加额外条件来控制扩散模型的神经网络结构。它提供了一种增强稳定扩散的方法,在文本到图像生成过程中使用条件输入,如涂鸦、边缘映射、分割映射、pose关键点等。可以让生成的图像将更接近输入图像,这比传统的图像到图像生成方法有了很大的改进。

论文地址:https://arxiv.org/pdf/2302.05543.pdf
代码地址:https://github.com/lllyasviel/ControlNet
WebUI extention for ControlNet: https://github.com/Mikubill/sd-webui-controlnet
论文核心:本文介绍了 ControlNet,这是一种端到端的神经网络架构,用于学习大型预训练文本到图像扩散模型(在我们的实现中为 Stable Diffusion)的条件控制。 **ControlNet 通过锁定大型预训练模型的参数并复制其编码层,保留了该大型模型的质量和能力。这种架构将大型预训练模型视为学习各种条件控制的强大主干网络。**可训练的副本和原始锁定的模型通过零卷积层连接,权重初始化为零,以便在训练过程中逐渐增长。这种架构确保在训练开始时不会向大型扩散模型的深层特征添加有害噪声,并保护可训练副本中的大型预训练主干网络免受此类噪声的破坏。
关键点:
(1)提出了ControlNet,这是一种神经网络架构,可以通过有效的微调将空间局部化的输入条件添加到预训练的文本到图像扩散模型中。
(2)展示了预训练的ControlNets以控制Stable Diffusion,其条件包括Canny边缘、霍夫线、用户涂鸦、人体关键点、分割图、形状法线、深度以及卡通线条绘图;
(3)通过与几种替代架构进行比较的消融实验来验证该方法的有效性。
ControlNet原理
ControlNet的基本结构如下所示:
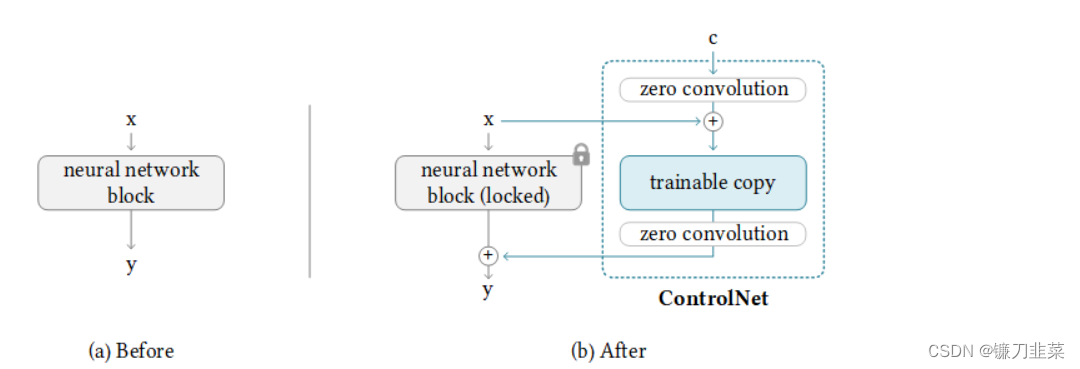
从图中可以看出,ControlNet的基本结构由一个对应的原先网络的神经网络模块和两个“零卷积”层组成。在之后的训练过程中,会“锁死”原先网络的权重,只更新ControlNet基本结构中的网络“副本”和零卷积层的权重。这些可训练的网络“副本”将学会如何让模型按照新的控制条件来生成结果,而被“锁死”的网络则会保留原先网络已经学会的所有知识。这样即使用来训练ControlNet的训练集规模较小,被“锁死”网络原本的权重也能确保扩散模型本身的生成效果不受影响。
ControlNet基本结构中的零卷积层是一些权重和偏置都被初始化为0的1×1卷积层。训练刚开始的时候,无论新添加的控制条件是什么,这些零卷积层都只输出0,因此ControlNet不会对扩散模型的生成结果造成任何影响。但随着训练过程的深入,ControlNet将学会逐渐调整扩散模型原先的生成过程,使得生成的图像逐渐向新添加的控制条件靠近。
问题1:如果一个卷积层的所有参数都为0,输出结果也为0,那么它怎么才能正常进行权重的迭代呢?
假设有一个简单的神经网络层:
y
=
w
x
+
b
y=wx+b
y=wx+b,已知
?
y
?
w
=
x
,
?
y
?
x
=
w
,
?
y
?
b
=
1
\frac{\partial y}{\partial w}=x,\frac{\partial y}{\partial x}=w,\frac{\partial y}{\partial b}=1
?w?y?=x,?x?y?=w,?b?y?=1,假设权重
w
w
w为0,输入x不为0,则有:
?
y
?
w
≠
0
,
?
y
?
x
=
0
,
?
y
?
b
≠
0
\frac{\partial y}{\partial w}\ne 0,\frac{\partial y}{\partial x}=0,\frac{\partial y}{\partial b}\ne 0
?w?y?=0,?x?y?=0,?b?y?=0这意味着只要输入x不为0,梯度下降的迭代过程就能正常地更新权重
w
w
w,使
w
w
w不再为0,于是得到:
?
y
?
x
≠
0
\frac{\partial y}{\partial x}\ne 0
?x?y?=0即,在经过若干迭代之后,这些零卷积层将逐渐变成具有正常权重的普通卷积层。
ControlNet应用于大型预训练扩散模型
以Stable Diffusion为例,介绍如何将ControlNet应用于大型预训练扩散模型以实现条件控制。Stable Diffusion本质上是一个U-Net,包含编码器、中间块和跳连接解码器。编码器和解码器都包含12个块,而整个模型包含25个块,包括中间块。在这25个块中,8个块是下采样或上采样卷积层,而其他17个块是主块,每个主块包含4个ResNet层和2个Vision Transformer(ViT)。每个ViT包含几个交叉注意力和自注意力机制。如下图所示:
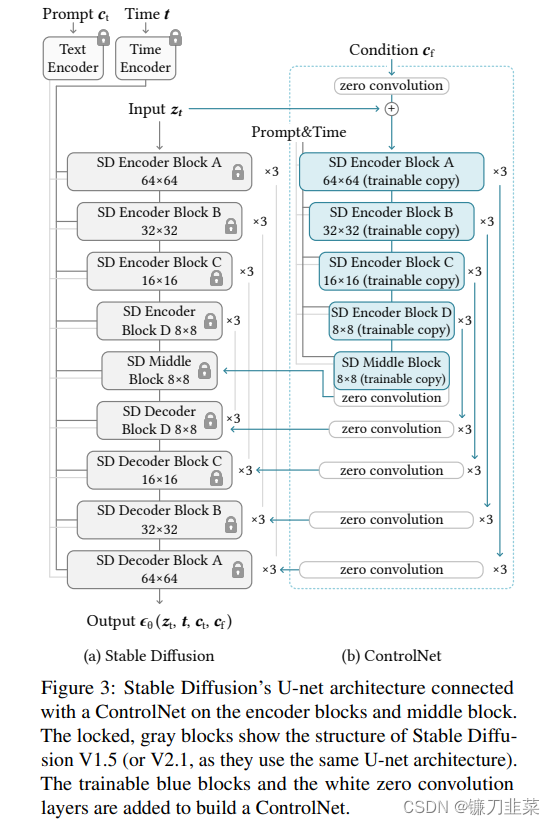
“SD Encoder Block A”包含4个ResNet层和2个ViT,而“×3”表示该块重复三次。文本提示使用CLIP文本编码器进行编码,扩散时间步使用带有位置编码的时间编码器进行编码。
将ControlNet结构应用于U-Net的每个编码器级别(图3b)。具体而言,使用ControlNet创建Stable Diffusion的12个编码块和1个中间块的训练副本。12个编码块分布在4个分辨率(64×64, 32×32,16×16,8×8)中,每个分辨率复制3次。输出被添加到U-Net的12个跳连接和1个中间块中。由于Stable Diffusion是典型的U-Net结构,这种ControlNet架构可能适用于其他模型。
这种连接ControlNet的方式在计算上是高效的——由于锁定副本的参数被冻结,在微调过程中,原始锁定编码器不需要进行梯度计算。这种方法加快了训练速度并节省GPU内存。
ControlNet实际上使用训练完成的Stable Diffusion模型的编码器模块作为自己的主干网络,而这样一个稳定又强大的主干网络,则保证了ControlNet能够学习到更多不同的控制图像生成的方法。
ControlNet训练过程
给定一个输入图像
z
0
z_0
z0?,图像扩散算法会逐步向图像添加噪声,并生成一个噪声图像
z
t
z_t
zt?,其中
t
t
t表示添加噪声的次数。给定一组条件,包括时间步
t
t
t、文本提示
c
t
c_t
ct?以及特定于任务的条件
c
f
c_f
cf?,图像扩散算法会学习一个网络
?
θ
\epsilon _\theta
?θ?来预测添加到噪声图像
z
t
z_t
zt?上的噪声,公式如下:
L
=
E
z
0
,
t
,
c
t
,
c
f
,
?
~
N
(
0
,
1
)
[
∣
∣
?
?
?
θ
(
z
t
,
t
,
c
t
,
c
f
)
∣
∣
2
2
]
\mathcal{L}=\mathbb{E}_{z_0,t,c_t,c_f,\epsilon \sim \mathcal{N}(0,1)}[||\epsilon -\epsilon _{\theta}(z_t,t,c_t,c_f)||_2^2]
L=Ez0?,t,ct?,cf?,?~N(0,1)?[∣∣???θ?(zt?,t,ct?,cf?)∣∣22?]
其中
L
\mathcal{L}
L是整个扩散模型的总体学习目标。该学习目标直接用于利用 ControlNet 对扩散模型进行微调。
训练一个附加到某个Stable Diffusion模型上的ControlNet的过程大致如下:
(1)收集想要对其附加控制条件的数据集和对应的Prompt。假如想训练一个通过人体关键点来对扩散模型生成的人体进行姿态控制的ControlNet,则首先需要收集一批人物图片,并标注好这批人物图片的Prompt以及对应的人体关键点的位置。
(2)将Prompt输入被“锁死”的Stable Diffusion模型,并将标注好的图像控制条件(如人体关键点的标注结果)输入ControlNet,然后按照稳定扩散模型的训练过程迭代ControlNet block的权重。
(3)在训练过程中,随机地将50%的文本提示语替换为空白字符串,这样做旨在“强制”网络从图像控制条件中学习更多的语义信息。
(4)训练结束后,便可以使用ControlNet对应的图像控制条件(如输入的人体关键点)来控制扩散模型生成符合条件的图像。
在训练过程中,随机用空字符串替换50%的文本提示
c
t
c_t
ct?。这种方法提高了ControlNet直接从输入条件图像中识别语义(例如边缘、姿态、深度等)的能力,作为提示的替代。在训练过程中,由于零卷积不会给网络添加噪声,模型应该始终能够预测高质量的图像。我们观察到模型并没有逐渐学习控制条件,而是在优化步骤少于10K时突然成功地遵循输入条件图像。如下图所示,称这种现象为“突然收敛现象”。

图4:突然收敛现象。 由于零卷积,ControlNet 在整个训练过程中始终预测高质量的图像。 在训练过程中的某个步骤(例如,以粗体标记的 6133 个步骤),模型突然学会遵循输入条件。
ControlNet示例
本小节将介绍一些已经训练好的ControlNet示例,都来自Huggingface。
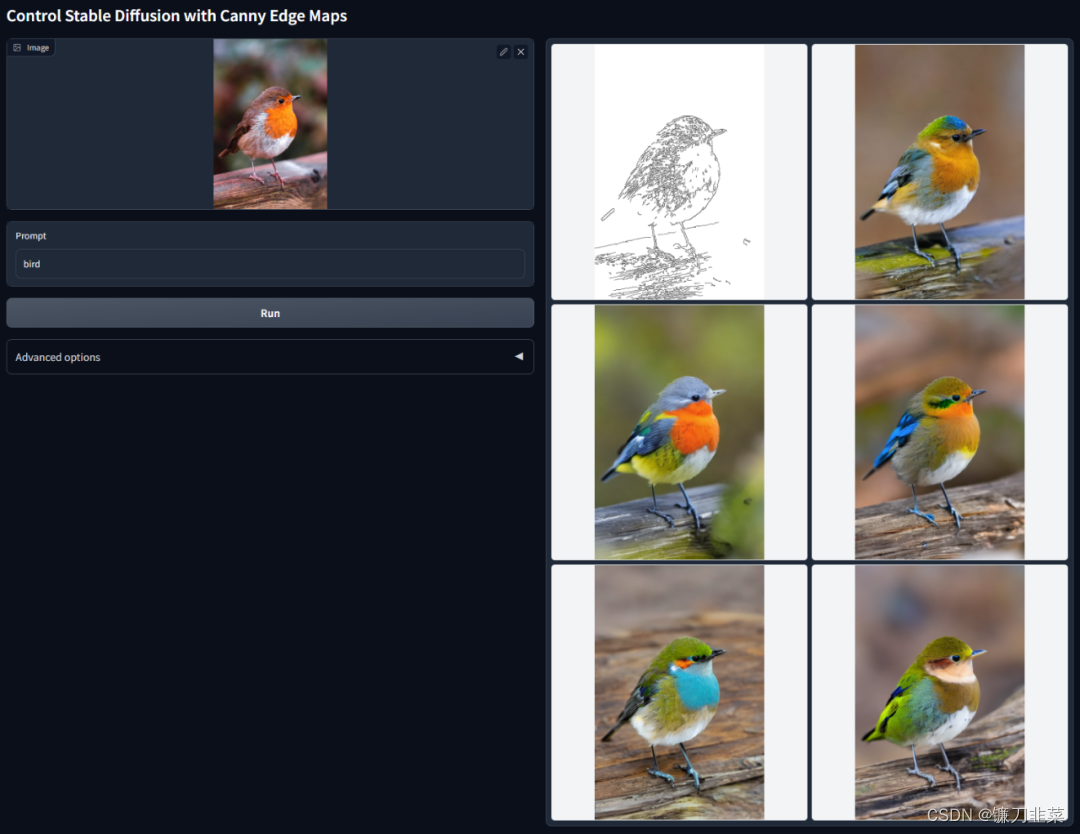
1 ControlNet与Canny Edge
Canny Edege是一种多阶段的边缘检测算法,该算法可以从不同的视觉对象中提取有用的结构信息,从而显著降低图像处理过程中的数据处理量,ControlNet与Canny Edge结合使用的效果如下图所示:
2. ControlNet与Depth
ControlNet 深度预处理器是用于处理图像中的深度信息的工具。它可以用于计算图像中物体的距离、深度图等。Depth map是跟原图大小一样的存储了深度信息的灰色尺度( gray scale )图像,白色表示图像距离更近,黑色表示距离更远。
-
MiDaS深度信息估算
MiDaS 深度信息估算,是用来控制空间距离的,类似生成一张深度图。一般用在较大纵深的风景,可以更好表示纵深的远近关系。 -
LeReS深度信息估算
LeReS 深度信息估算比 MiDaS 深度信息估算方法的成像焦点在中间景深层,这样的好处是能有更远的景深,其中距离物品边缘成像会更清晰,但近景图像的边缘会比较模糊,具体实战中需用哪个估算方法可根据需要灵活选择。
示例:通过提取原始图像中的深度信息,可以生成具有同样深度结构的图。

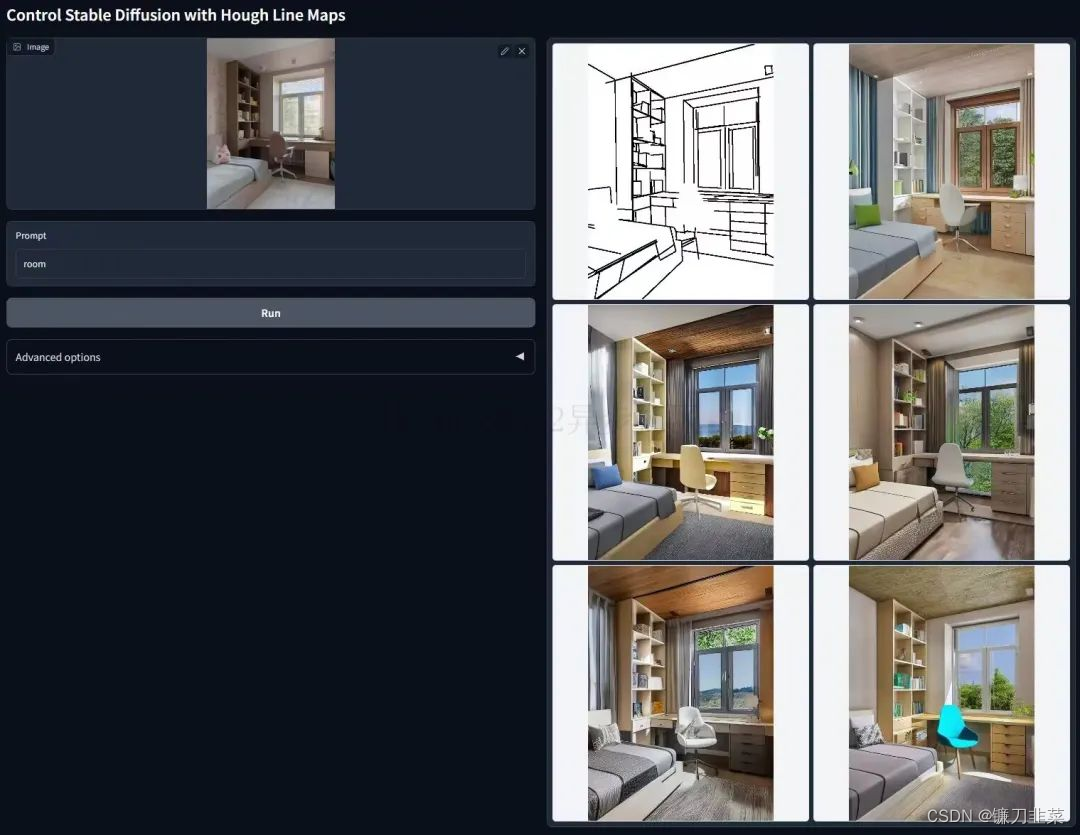
3. ControlNet与M-LSD Lines
M-LSD Lines是另一种轻量化的边缘检测算法,擅长提取图像中的直线线条。训练在M-LSD Lines上的ControlNet适合室内环境方面的图片。ControlNet与M-LSD Lines结合使用的效果,如下图所示:
4. ControlNet与HED Boundary
HED Boundary可以保持输入图像更多信息,训练在HED Boundary上的ControlNet适合用来重新上色和进行风格重构。ControlNet与HED Boundary结合使用的效果,如下图所示:

除了以上这些,ControlNet还可以:
- 训练在涂鸦画上的ControlNet能让Stable Diffusion模型学会如何将儿童涂鸦转绘成高质量的图片。
- 训练在人体关键点上的ControlNet能让扩散模型学会生成指定姿态的人体。
- 语义分割模型旨在提取图像中各个区域的语义信息,常用来对图像中的人体、物体、背景区域等进行划分。训练在语义分割数据上的ControlNet能让稳定扩散模型生成特定结构的场景图。
- 诸如深度图、Normal Map、人脸关键点等,同样可以使用ControlNet。
ControlNet实战
ControlNet 模型可以在使用小数据集进行训练。然后整合任何预训练的稳定扩散模型来增强模型,来达到微调的目的。ControNet 的初始版本带有以下预训练权重。
Canny edge— 黑色背景上带有白色边缘的单色图像。Depth/Shallow areas— 灰度图像,黑色代表深区域,白色代表浅区域。Normal map— 法线贴图图像。Semantic segmentation map——ADE20K 的分割图像。HED edge— 黑色背景上带有白色软边缘的单色图像。Scribbles— 黑色背景上带有白色轮廓的手绘单色涂鸦图像。OpenPose(姿势关键点)— OpenPose 骨骼图像。M-LSD— 仅由黑色背景上的白色直线组成的单色图像。
Canny Edge实战
安装需要的库:
!pip install -q diffusers transformers xformers git+https://github.com/huggingface/accelerate.git
为了对应选择的ControlNet,还需要安装两个依赖库来对图像进行处理,以提取不同的图像控制条件:
!pip install -q opencv-contrib-python
!pip install -q controlnet_aux
图像示例:
from diffusers import StableDiffusionControlNetPipeline
from diffusers.utils import load_image
image = load_image("https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/input_image_vermeer.png")
image

首先,使用这张图片发送给Canny Edge边缘提取器,预处理一下:
import cv2
from PIL import Image
import numpy as np
image = np.array(image)
low_threshold = 100
high_threshold = 200
# 提取图片边缘线条
image = cv2.Canny(image, low_threshold, high_threshold)
image = image[:, :, None]
image = np.concatenate([image, image, image], axis=2)
canny_image = Image.fromarray(image)
canny_image

接下来,载入runwaylml/stable-diffusion-v1-5模型以及能够处理Canny Edge的ControlNet模型。同时,为了节约计算资源以及加快推理速度,决定使用半精度(torch.dtype)的方式来读取模型:
# 使用半精度节约计算资源,加快推理速度
from diffusers import StableDiffusionControlNetPipeline, ControlNetModel
import torch
device = "cuda" if torch.cuda.is_available() else "cpu"
print(device)
controlnet = ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-canny", torch_dtype=torch.float32).to(device)
pipe = StableDiffusionControlNetPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", controlnet=controlnet, torch_dtype=torch.float32).to(device)
然后,使用当前速度最快的扩散模型调度器——UniPCMultistepScheduler。该调度器能显著提高模型的推理速度。
# 使用速度最快的扩散模型调度器UniPCMultistepScheduler
from diffusers import UniPCMultistepScheduler
pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
定义一个图片显示布局的函数:
def image_grid(imgs, rows, cols):
assert len(imgs) == rows * cols
w, h = imgs[0].size
grid = Image.new("RGB", size=(cols * w, rows * h))
grid_w, grid_h = grid.size
for i, img in enumerate(imgs):
grid.paste(img, box=(i % cols * w, i // cols * h))
return grid
生成一些人物肖像,这些肖像与上面的图片姿势一样:
prompt = ", best quality, extremely detailed"
prompt = [t + prompt for t in ["Sandra Oh", "Kim Kardashian", "rihanna", "taylor swift"]]
generator = [torch.Generator(device=device).manual_seed(2) for i in range(len(prompt))]
output = pipe(
prompt,
canny_image,
negative_prompt=["monochrome, lowres, bad anatomy, worst quality, low quality"] * len(prompt),
generator=generator,
num_inference_steps=30,
)
image_grid(output.images, 2, 2)

Open Pose
第二个有趣的应用是从一张图片中提取身体姿态,然后用它生成具有完全相同的身体姿态的另一张图片。这里使用Open Pose ControlNet做姿态迁移。
首先,下载一些瑜伽图片:
urls = ["yoga1.jpeg", "yoga2.jpeg", "yoga3.jpeg", "yoga4.jpeg"]
imgs = [load_image("https://huggingface.co/datasets/YiYiXu/controlnet-testing/resolve/main/" + url) for url in urls]
image_grid(imgs, 2, 2)

补充:安装mediapipe
!pip install mediapipe
MediaPipe 是一款由 Google Research 开发并开源的多媒体机器学习模型应用框架。在谷歌,一系列重要产品,如 YouTube、Google Lens、ARCore、Google Home 以及 Nest,都已深度整合了 MediaPipe。MediaPipe大有用武之地,可以做物体检测、自拍分割、头发分割、人脸检测、手部检测、运动追踪,等等。基于此可以实现更高级的功能。
MediaPipe 的核心框架由 C++ 实现,并提供 Java 以及 Objective C 等语言的支持。MediaPipe 的主要概念包括数据包(Packet)、数据流(Stream)、计算单元(Calculator)、图(Graph)以及子图(Subgraph)。
- 数据包是最基础的数据单位,一个数据包代表了在某一特定时间节点的数据,例如一帧图像或一小段音频信号;
- 数据流是由按时间顺序升序排列的多个数据包组成,一个数据流的某一特定时间戳(Timestamp)只允许至多一个数据包的存在;而数据流则是在多个计算单元构成的图中流动。
- MediaPipe 的图是有向的——数据包从数据源(Source Calculator或者 Graph Input Stream)流入图直至在汇聚结点(Sink Calculator 或者 Graph Output Stream) 离开。
然后使用controlnet_aux中的Open Pose预处理器提取瑜伽的身体姿势:
from controlnet_aux import OpenposeDetector
model = OpenposeDetector.from_pretrained("lllyasviel/ControlNet")
poses = [model(img) for img in imgs]
image_grid(poses, 2, 2)
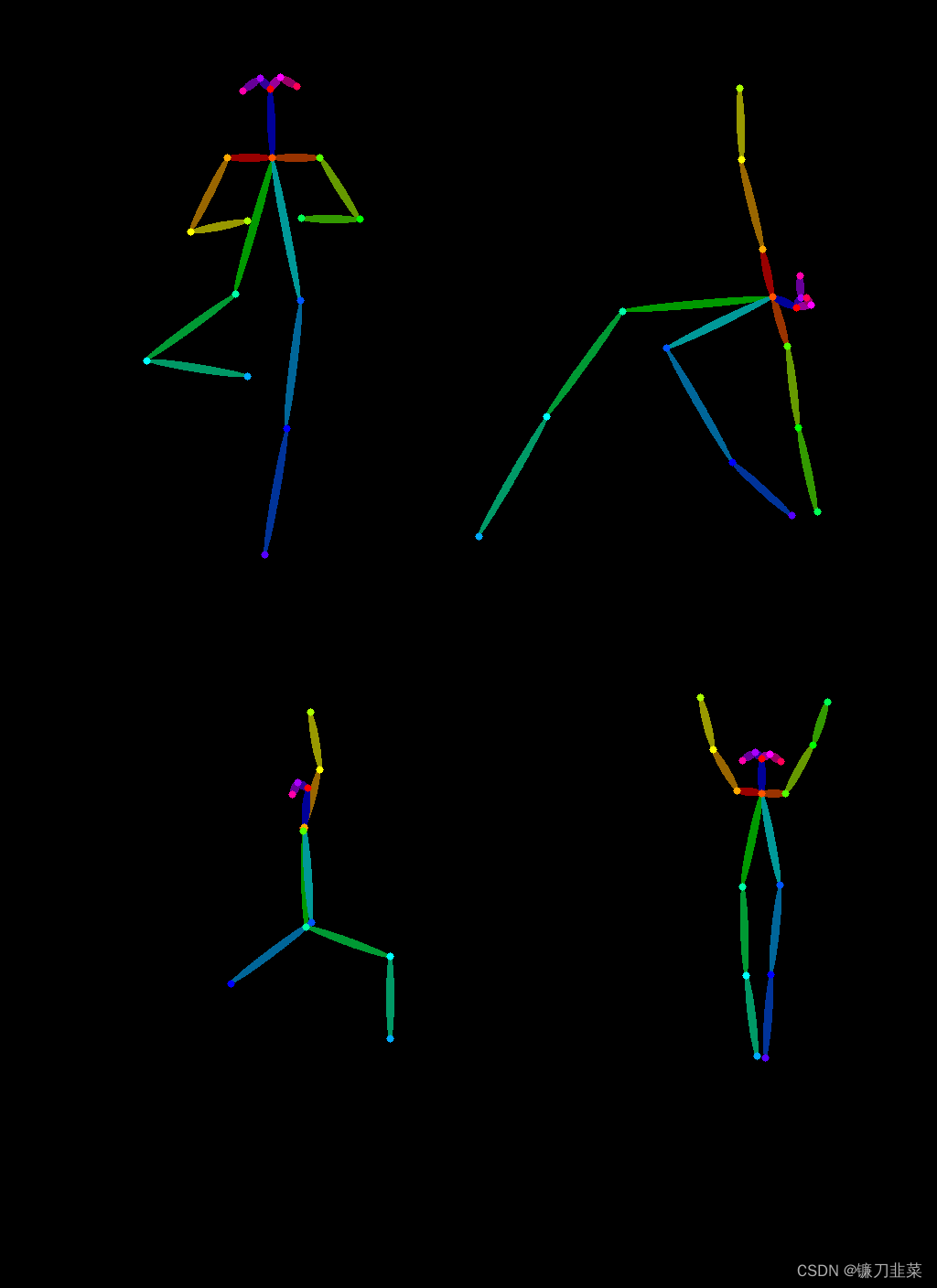
接下来使用Open Pose ControlNet生成一些正在做瑜伽的超级英雄的图片:
from diffusers import ControlNetModel, UniPCMultistepScheduler, StableDiffusionControlNetPipeline
controlnet = ControlNetModel.from_pretrained("fusing/stable-diffusion-v1-5-controlnet-openpose", torch_dtype=torch.float16)
model_id = "runwayml/stable-diffusion-v1-5"
pipe = StableDiffusionControlNetPipeline.from_pretrained(
model_id,
controlnet = controlnet,
torch_dtype=torch.float16
)
pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
pipe.enable_model_cpu_offload()
pipe.enable_xformers_memory_efficient_attention()
生成图片:
generator = [torch.Generator(device='cpu').manual_seed(2) for i in range(4)]
prompt = "super-hero character, best quality, extremely detailed"
output = pipe(
[prompt] * 4,
poses,
negative_prompt=["monochrome, lowres, bad anatomy, worst quality, low quality"] * 4,
generator=generator,
num_inference_steps=20,
)
image_grid(output.images, 2, 2)

关于ControlNet更多的使用方法,可以参考如下:
- lllyasviel/sd-controlnet-depth
- lllyasviel/sd-controlnet-hed
- lllyasviel/sd-controlnet-normal
- lllyasviel/sd-controlnet-scribbl
- lllyasviel/sd-controlnet-seg
- lllyasviel/sd-controlnet-openpose
- lllyasviel/sd-controlnet-mlsd
小结
ControlNet是一种神经网络结构,它学习大型预训练的文本到图像扩散模型的带条件控制。它重用源模型的的大规模预训练层来构建一个深度且强大的编码器,以学习特定条件。原始模型和可训练的副本通过“零卷积”层连接,这些“零卷积”层可以消除训练期间的噪音。大量实验证明,ControlNet可以有效控制带有单个或多个条件以及带/不带提示的Stable Diffusion。在多样化条件数据集上的结果展示出,ControlNet结构可能适用于更广泛的条件,并促进相关应用。
参考资料
- ICCV2023最佳论文–斯坦福大学文生图模型ControlNet,已开源!
- T2I-Adapter
- https://openai.wiki/controlnet-guide.html
- https://h1cji9hqly.feishu.cn/docx/YioKdqC0oo7XThxvW1ccOmbunEh
- lllyasviel/ControlNet
- 万字长文解读Stable Diffusion的核心插件—ControlNet
- ControlNet原理&使用实操
- ControlNet v1.1: A complete guide
- 使用ControlNet 控制 Stable Diffusion
- ubuntu + conda 的 stable-diffusion-webui 安装笔记
- Python中读取图片的6种方式
- MediaPipe 集成人脸识别,人体姿态评估,人手检测模型
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!