海量小文件备份指南
2023-12-20 21:49:14

海量小文件以其目录深且广、文件量大等特点,带来了扫描速度慢、小文件多导致网络交互高、传输效率低备份时间耗时长等痛点。要想解决好海量小文件备份场景,从文件级出发可以通过以下方式提高效率:
- 采用高效扫描算法,综合目录广度和深度的自适应扫描算法;
- 采用多线程,多线程扫描文件和目录+多线程传输数据;
- 采用生产者消费者模型,让扫描和传输同时进行;
- 传输时将小文件打包成大文件再进行传输,降低网络交互;
- 数据合并存储,降低存储数据所需要的时间;
- 通过对源文件多个维度提取关键信息,构建文件指纹,结合高效算法,快速与关联备份集进行对比,快速提取出增量信息。
- 备份系统采用多节点部署,将文件目录划分节点进行备份,横向扩展提高备份速度。
以下为系统模拟海量小文件场景实验的相关数据信息:
- 实验拓扑图,如下图:

? ? ?2.实验环境参数,如下图:

? ? 3.实验所用的数据,如下图:

第一层目录下:有10个目录,每个目录下结构一致;
第一层目录下:第二层到第七层,每个目录下都有六个目录;
第八层目录下:每个目录下都有三十六个10KB的文件。
?4.完全备份实验结果:
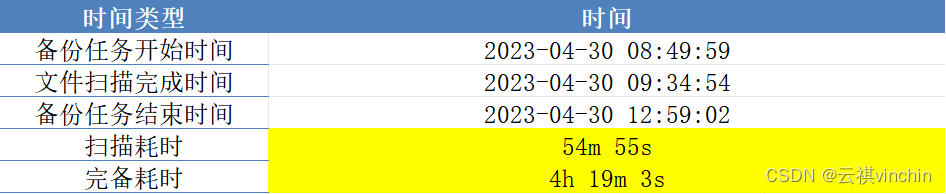
5.增量备份实验数据:
6.增量备份实验结果:

文章来源:https://blog.csdn.net/qq_42934452/article/details/135114315
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!