102、X^3 : Large-Scale 3D Generative Modeling using Sparse Voxel Hierarchies
简介
官网
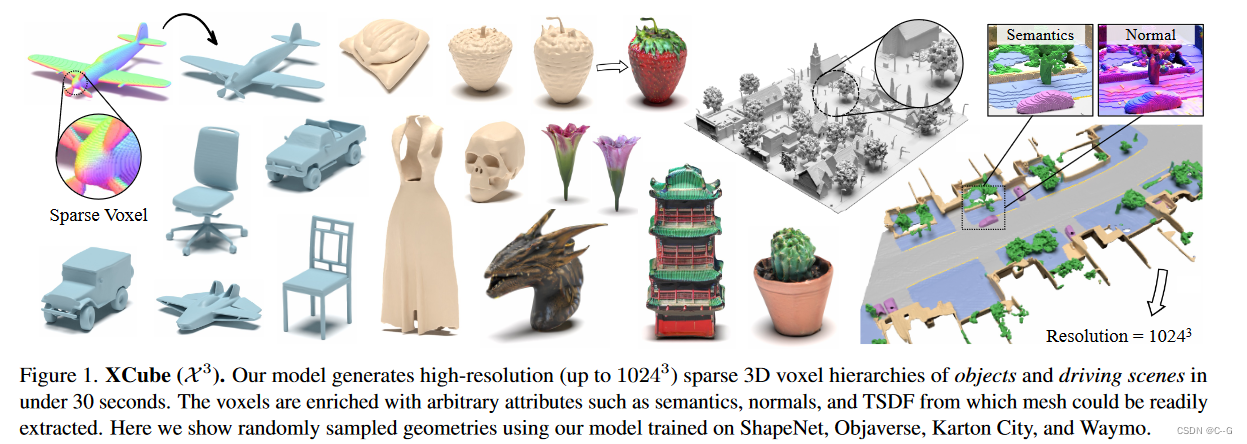
?Nvidia2023提出的一种新的生成模型,可生成具有任意属性的高分辨率稀疏3D体素网格,以前馈方式生成数百万体素,最细有效分辨率高达
102
4
3
1024^3
10243,而无需耗时的 test-time 优化,使用一种分层体素潜扩散模型,使用建立在高效VDB数据结构上的自定义框架,以从粗到细的方式生成逐步更高的分辨率网格。XCube在100 m×100 m规模的大型户外场景中的有效性,体素大小小至10 cm。
实现流程
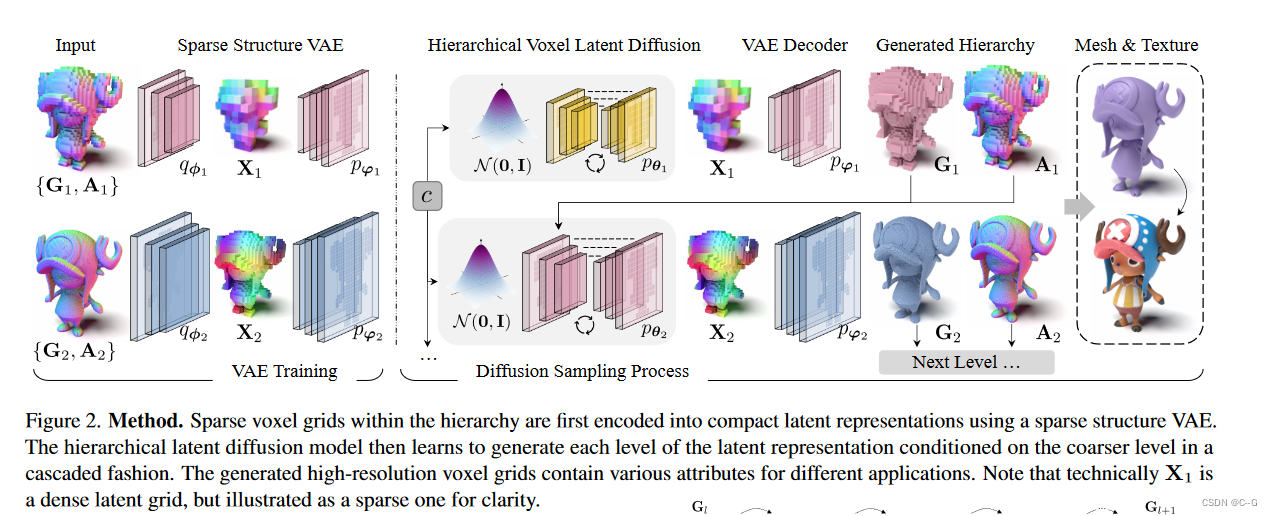
?目标是学习一个以稀疏体素层次表示的大规模3D场景的生成模型,由L层由粗到细的体素网格组成
G
=
{
G
1
,
?
,
G
L
}
G = \{G_1,\cdot, G_L\}
G={G1?,?,GL?}及其相关的每个体素属性
A
=
{
A
1
,
?
,
A
L
}
A = \{A_1,\cdot, A_L\}
A={A1?,?,AL?},如法线和语义。具有较小体素尺寸的较细网格
G
l
+
1
G_{l+1}
Gl+1? 严格包含在较粗网格
G
l
G_l
Gl? 中,网格
G
L
G_L
GL?的最细级别包含最多的细节。
Sparse Structure VAE
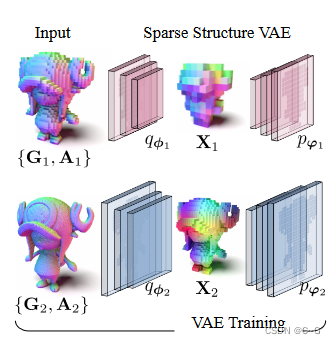
?稀疏结构VAE旨在学习层次结构中每个体素网格及其相关属性的紧凑潜表示。基于稀疏体素网格算子构建神经网络,分别以 φ 和 ψ 为编码器和解码器权重,对后验分布
q
φ
(
X
∣
G
,
A
)
q_φ(X |G, A)
qφ?(X∣G,A) 和似然分布
p
ψ
(
G
,
A
∣
X
)
p_ψ(G, A|X)
pψ?(G,A∣X) 进行建模。
?对于编码器,利用稀疏卷积神经网络通过交替应用稀疏卷积和最大池化操作,对 X 的分辨率进行下采样来处理输入G和A 。
?对于解码器,借用了[Neural Kernel Surface Reconstruction]的结构预测骨干,允许预测输入中不存在的新的稀疏体素。从 X 开始,根据细分掩模的预测逐步修剪过多的体素并细分现有的体素,最后经过几层上采样后达到 G 的分辨率
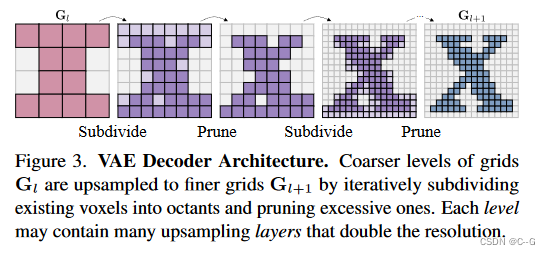
Hierarchical Voxel Latent Diffusion
Probabilistic Modeling
?现有的3D生成工作通常使用一个潜在扩散级别(即L = 1)。虽然这足以生成包含单个物体的复杂场景,但分辨率仍远远不足以生成大规模户外场景,其基础3D表示的有限可扩展性,以及缺乏捕捉数据从粗到细性质的概率建模,阻碍了这些方法的有效性,通过将分层潜在扩散模型与稀疏体素表示相结合来解决这个问题,对网格和潜的联合分布提出以下因子分解。
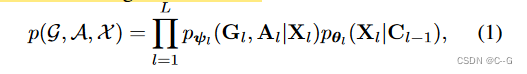
? C l ? 1 C_{l?1} Cl?1?是来自较粗层次的条件。
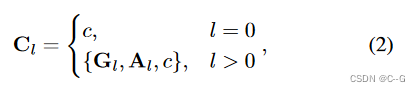
?c 是一个可选的全局条件,如类别标签或文本提示, p θ l ( ? ) p_{θ_l}(·) pθl??(?) 实例化为带有参数 θ l θ_l θl?的扩散模型。
Diffusion Model p θ p_θ pθ?
?扩散随机过程遵循马尔可夫过程,通过迭代地向随机变量添加白噪声,将随机变量的复杂分布转换为单位高斯分布 X 0 ~ N ( 0 , I ) X_0 \sim \N (0, I) X0?~N(0,I)
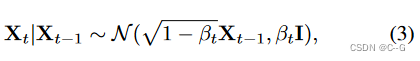
?其中 0 < β t ≤ 1 0< \beta_t \leq1 0<βt?≤1 。相反的过程是迭代地去除噪声,并在离散的步骤数 T 内达到数据分布 X T X_T XT?。
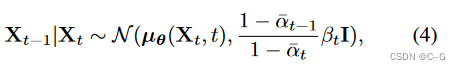
? a t = 1 ? β t , a ˉ t = ∏ s = 0 t a s , μ θ a_t = 1-\beta_t,\bar{a}_t = \prod^t_{s=0} a_s,\mu_\theta at?=1?βt?,aˉt?=∏s=0t?as?,μθ?是参数化的可学习模块。
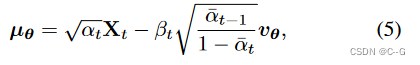
?将
v
θ
(
?
)
v_θ(·)
vθ?(?) 实例化为[Diffusion models beat gans on image synthesis]中使用的骨干的3D稀疏变体,确保
v
θ
v_θ
vθ? 解码输出的网格结构与输入匹配,为了注入条件
C
l
?
1
C_{l - 1}
Cl?1?,直接将
A
l
?
1
A_{l - 1}
Al?1?的特征与网络输入连接起来,
X
l
X_l
Xl?也与
G
l
?
1
G_{l - 1}
Gl?1?共享相同的网格结构。时间步条件使用AdaGN实现,文本条件 c 使用 [Learning transferable visual models from natural language supervision] 裁剪编码,然后使用交叉注意力注入。
Training
level-l VAE loss
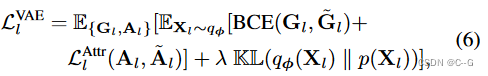
? G ~ l , A ~ t \tilde{G}_l,\tilde{A}_t G~l?,A~t?是VAE解码器 ψ 给定 X l X_l Xl? 的输出,KaTeX parse error: Undefined control sequence: \L at position 1: \?L?^{Attr}_l是监督属性预测。BCE(·)为网格结构上的二元交叉熵,使得 ψ 为混合积分布。KL(·∥·)是后验概率 p ( X l ) p(X_l) p(Xl?) 和先验概率 p ( X l ) p(X_l) p(Xl?) 之间的KL散度,将其设置为单位高斯N (0, I), λ 是其权重。
diffusion model loss
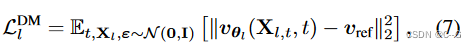
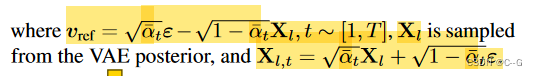
Sampling
?为了从Eq(1)的联合分布中采样,首先从扩散模型 p θ 1 p_{θ_1} pθ1??中 提取最粗的潜在 X 1 X_1 X1?。然后,使用解码器 p ψ 1 p_{ψ_1} pψ1?? 来生成最粗的网格 G 1 G_1 G1? 及其相关属性 A 1 A_1 A1? (然后由细化网络可选地对其进行细化)。以 C 1 = { G 1 , A 1 , c } C_1 = \{G_1, A_1, c\} C1?={G1?,A1?,c} 为条件,利用扩散模型 p θ 2 p_{θ_2} pθ2?? 生成下一层的潜伏 X 2 X_2 X2?,这个过程一直持续到满足 { G L , A L } \{G_L, A_L\} {GL?,AL?} 的最高分辨率。
Implementation Details
- Early dilation.在体素尺寸较大的网络层中,将稀疏体素网格扩展1,使稀疏拓扑的光晕区域也表示非零特征。这有助于后面的层更好地捕捉局部上下文并生成平滑的结构。
- Refinement network.分解模型的一个固有问题是误差累积,其中更高分辨率的网格不能轻易修复先前层的工件。通过在VAE解码器的输出中添加一个细化网络来缓解这一问题,该网络对 G l G_l Gl? 和 A l A_l Al? 进行了细化。细化网络的架构类似于[Neural kernel surface reconstruction],在解码之前,通过向VAE的后验添加噪声来增强其训练数据
利用VDB结构来存储稀疏的3D体素网格。由于其紧凑的表示(340万体素只需要11MB)和快速的查找程序,能够以非常高效的方式实现常见的神经操作符,如卷积和池化。所提出框架完全在GPU上运行(包括网格构建),能够在毫秒内处理 102 4 3 1024^3 10243大小的3D场景,比目前最先进的稀疏3D学习框架TorchSparse运行速度快3倍,内存使用率是~0.5倍
Dataset
使用ShapeNet数据集,为构建用于训练的groundtruth体素层次结构,将每个网格体素化为 51 2 3 512^3 5123 分辨率,并使用的train/val/test分割。
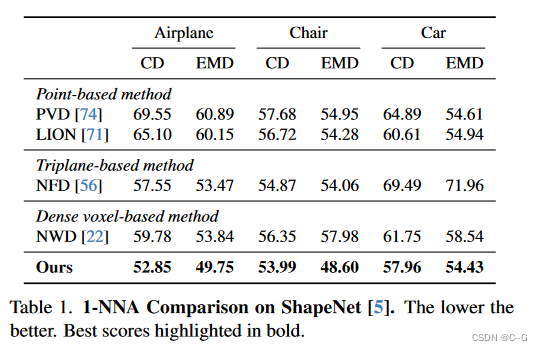
实验

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!