模型量化 | Pytorch的模型量化基础
量化简介
量化是指执行计算和存储的技术 位宽低于浮点精度的张量。量化模型 在张量上执行部分或全部操作,精度降低,而不是 全精度(浮点)值。这允许更紧凑的模型表示和 在许多硬件平台上使用高性能矢量化操作。 与典型的 FP32 模型相比,PyTorch 支持 INT8 量化,
- 模型大小减少 4 倍
- 内存带宽减少 4 倍
- INT8 计算的硬件支持通常为 2 到 4 个 与 FP32 计算相比,速度快几倍
量化主要是一种技术 加速推理,量化仅支持前向传递 运营商。
PyTorch 支持多种量化深度学习模型的方法。在 大多数情况下,模型在 FP32 中训练,然后将模型转换为 INT8 中。此外,PyTorch 还支持量化感知训练,这 使用以下方法对前向和后向传递中的量化误差进行建模 假量化模块。请注意,整个计算是在 浮点。在量化感知训练结束时,PyTorch 提供 转换函数,用于将训练好的模型转换为较低精度的模型。
在较低级别,PyTorch 提供了一种表示量化张量和 使用它们执行操作。它们可用于直接构建模型 以较低的精度执行全部或部分计算。更高级别 提供了包含转换 FP32 模型的典型工作流的 API 以最小的精度损失降低精度。
pytorch从1.3 版开始,提供了量化功能,PyTorch 1.4 发布后,在 PyTorch torchvision 0.5 库中发布了 ResNet、ResNext、MobileNetV2、GoogleNet、InceptionV3 和 ShuffleNetV2 的量化模型。
PyTorch 量化 API 摘要
PyTorch 提供了两种不同的量化模式:Eager Mode Quantization 和 FX Graph Mode Quantization。
Eager Mode Quantization 是一项测试版功能。用户需要进行融合并指定手动进行量化和反量化的位置,而且它只支持模块而不是功能。
FX Graph Mode Quantization 是 PyTorch 中一个新的自动化量化框架,目前它是一个原型功能。它通过添加对函数的支持和自动化量化过程来改进 Eager Mode Quantization,尽管人们可能需要重构模型以使模型与 FX Graph Mode Quantization 兼容(符号上可追溯到 )。请注意,FX Graph Mode Quantization 预计不适用于任意模型,因为该模型可能无法符号跟踪,我们将它集成到 torchvision 等域库中,用户将能够量化类似于 FX Graph Mode Quantization 支持的域库中的模型。对于任意模型,我们将提供一般准则,但要真正使其工作,用户可能需要熟悉,尤其是如何使模型具有符号可追溯性。torch.fxtorch.fx
PyTorch量化结构
- PyTorch 具有与量化张量对应的数据类型,这些张量具有许多张量的特征。
- 人们可以编写具有量化张量的内核,就像浮点张量的内核一样,以自定义其实现。PyTorch 支持将常见操作的量化模块作为 和 name-space 的一部分。
torch.nn.quantizedtorch.nn.quantized.dynamic - 量化与 PyTorch 的其余部分兼容:量化模型是可跟踪和可编写脚本的。服务器和移动后端的量化方法几乎相同。可以轻松地在模型中混合量化和浮点运算。
- 浮点张量到量化张量的映射可以使用用户定义的观察者/假量化模块进行自定义。PyTorch 提供了适用于大多数用例的默认实现。
【量化张量,量化模型 ,工具上的量化】
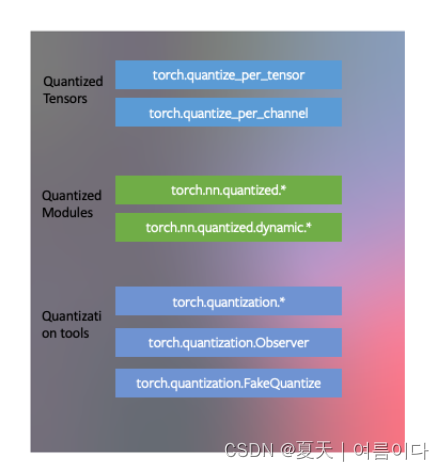
PYTORCH的三种量化模式
🫧动态量化?Dynamic qunatization:使权重为整数(训练后)
🤖训练后静态量化?Static quantization:使权值和激活值为整数(训练后)
量化感知训练?Quantization aware training:以整数精度对模型进行训练
🫧动态量化
PyTorch 支持的最简单的量化方法称为动态量化。这不仅涉及将权重转换为 int8(就像所有量化变体一样),还涉及在进行计算之前将激活转换为 int8(因此是“动态”的)。因此,计算将使用高效的 int8 矩阵乘法和卷积实现来执行,从而加快计算速度。但是,激活以浮点格式读取和写入内存。
🤖训练后静态量化
可以通过将网络转换为同时使用整数算术和 int8 内存访问来进一步提高性能(延迟)。静态量化执行额外的步骤,即首先通过网络提供批量数据并计算不同激活的结果分布(具体来说,这是通过在记录这些分布的不同点插入“观察者”模块来完成的)。此信息用于确定在推理时应如何具体量化不同的激活
量化感知训练
量化感知训练 (QAT)?是第三种方法,也是这三种方法中通常最准确的一种方法。使用 QAT,在训练的前向和后向传递期间,所有权重和激活都是“假量化”的:也就是说,浮点值被舍入以模仿 int8 值,但所有计算仍然使用浮点数完成。因此,训练期间的所有权重调整都是在“意识到”模型最终将被量化的事实的情况下进行的;因此,在量化后,该方法通常比其他两种方法产生更高的准确度。
官网中提供的一些建议,不同的网络选择不同的量化模式:
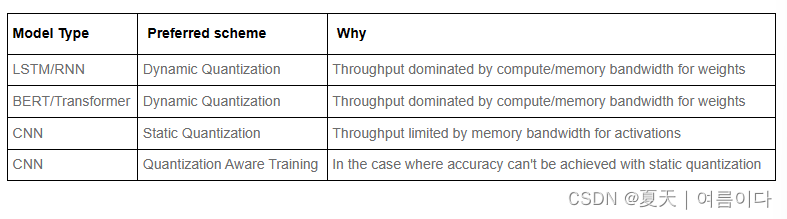 结果显示在性能和精度上都有提高
结果显示在性能和精度上都有提高
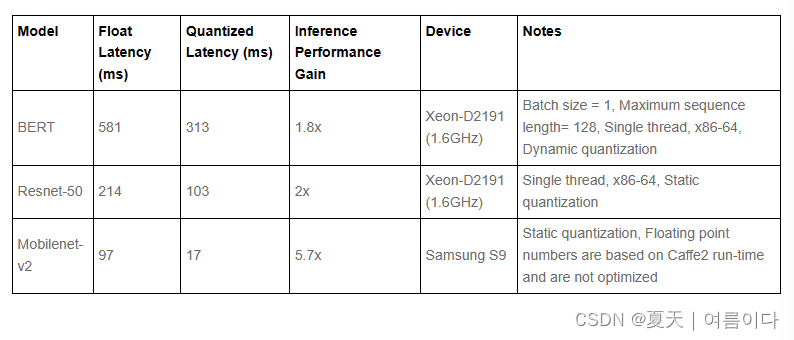
计算机视觉模型精度
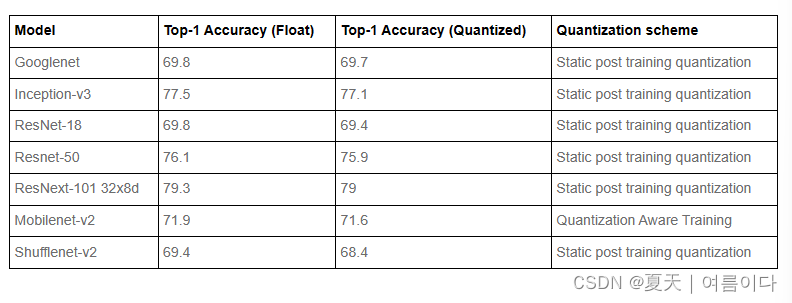
语音和自然语言处理精度

量化实例
目前torchvision【2】中提供的7个量化模型如图(截止20231227)
实例1:量化resnet18网络
?实例2:量化MobileNet v2?网络
?
Q&A
【Q&A1】模型量化,剪枝的区别是什么?
模型量化和剪枝是两种不同的技术,用于减小神经网络模型的大小、加速推理过程并降低模型的计算复杂度。它们的主要区别在于优化模型的方式和目标。
模型量化(Quantization):
- 定义:模型量化是通过减少模型中参数的表示精度来实现模型压缩的过程。通常,神经网络模型中的参数是使用浮点数表示的,而量化则将这些参数表示为更少比特的定点数或整数,从而减小了内存占用和计算成本。
- 目标:减小模型的存储空间和加速推理过程。通过使用较少位数的表示来存储权重和激活值,模型的存储需求减少,且在硬件上执行推理时,可以更快地进行计算。
剪枝(Pruning):
- 定义:剪枝是一种技术,通过减少神经网络中的连接或参数来减小模型的大小。在剪枝过程中,通过将权重较小或对模型贡献较小的连接移除或设为零,从而减少模型的复杂度。
- 目标:减小模型的尺寸和计算负载。剪枝不仅可以减少模型的存储需求,还可以在推理时减少乘法操作,因为移除了部分连接或参数,从而提高推理速度。
虽然两者都致力于减小模型的大小和计算复杂度,但方法和实现方式略有不同。模型量化侧重于减小参数表示的精度,而剪枝则专注于减少模型的连接或参数数量。通常,这两种技术可以结合使用,以更大程度地减小神经网络模型的尺寸和提高推理效率。
【Q&A2】减小模型的大小的方法有什么?
深度压缩(Deep Compression):
- 这是一种综合性的方法,包括剪枝、权重共享和 Huffman 编码等步骤。它不仅剪枝模型中的连接,还可以通过权重共享和 Huffman 编码来进一步减小模型的大小。这种方法通常能够在保持模型性能的同时大幅减小模型大小。
知识蒸馏(Knowledge Distillation):
- 这是一种将大型模型中的信息转移到小型模型的技术。通过训练一个较小的模型去模仿大型模型的行为,以捕捉大型模型的复杂性和性能。这样可以在不损失太多性能的情况下使用更小的模型。
低秩近似(Low-Rank Approximation):
- 通过矩阵分解等方法将模型中的权重矩阵近似为低秩矩阵,从而减少模型参数数量。这种方法可以有效地减小模型的尺寸,但有时会对模型性能产生一定影响。
网络架构优化:
- 重新设计模型架构以减少参数数量和计算量。可以通过精心设计模型结构,如使用轻量级网络、深度可分离卷积等技术,来降低模型的复杂度。
权重量化和编码:
- 类似于模型量化,可以对权重进行更复杂的编码或量化方式,以更有效地表示权重并减少模型大小。
这些方法可以单独使用,也可以组合使用,根据具体的情况和需求来选择合适的技术来减小模型的大小。常常需要在压缩模型尺寸和保持模型性能之间找到平衡。
参考文献
【1】Introduction to Quantization on PyTorch | PyTorch
【2】vision/torchvision/models/quantization at main · pytorch/vision (github.com)?
【3】量化自定义PyTorch模型入门教程 - 知乎 (zhihu.com)
【4】?深度学习知识六:(模型量化压缩)----pytorch自定义Module,并通过其理解DoReFaNet网络定义方法。_pytorch dorefa save_for_backward-CSDN博客
【5】端到端Transformer模型的混合精度后量化_量化 端到端-CSDN博客?
【6】transformers 保存量化模型并加载_from transformers import autotokenizer, automodel-CSDN博客?【7】使用 Transformers 量化 Meta AI LLaMA2 中文版大模型 - 苏洋博客 (soulteary.com)
【8】Model Compression - 'Quantization' | LeijieZhang (leijiezhang001.github.io)?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!