【Spark精讲】一文讲透SparkSQL聚合过程以及UDAF开发
SparkSQL聚合过程
这里的 Partial 方式表示聚合函数的模式,能够支持预先局部聚合,这方面的内容会在下一节详细介绍。 对应实例中的聚合语句,因为 count 函数支持 Partial 方式,因此调用的是 planAggregateWithoutDistinct 方法,生成了图 7.4 中的两个 HashAggregate (聚合执行方式中的一种,后续详细介绍)物理算子树节点,分别进行局部聚合与最终的聚合。 最后,在生成的 SparkPlan 中添加 Exchange 节点,统一排序与分区信息,生成物理执行计划(ExecutedPlan)。
聚合查询在计算聚合值的过程中,通常都需要保存相关的中间计算结果,例如 max 函数需要保存当前最大值, count 函数需要保存当前的数据总数,求平均值的 avg 函数需要同时保存 count 和 sum 的值,更复杂的函数(如 pencent让等)甚至需要临时存储全部的数据 。 聚合查询 计算过程中产生的这些中间结果会临时保存在聚合函数缓冲区。
在 SparkSQL 中,聚合过程有 4种模式,分别是 Partial模式、 ParitialMerge模式、 Final模式 和 Complete模式。
Final模式一般和 Partial模式组合在一起使用。 Partial模式可以看作是局部数据的聚合,在 具体实现中, Partial 模式的聚合函数在执行时会根据读入的原始数据更新对应的聚合缓冲区, 当处理完所有的输入数据后,返回的是聚合缓冲区中的中间数据 。 而 Final模式所起到的作用 是将聚合缓冲区的数据进行合并,然后返回最终的结果。 如下图所示,在最终分组计算总和 之前,可以先进行局部聚合处理,这样能够避免数据传输并减少计算量 。 因此,上述聚合过程 中在 map 阶段的 sum 函数处于 Partial模式,在 reduce 阶段的 sum 函数处于 Final模式 。

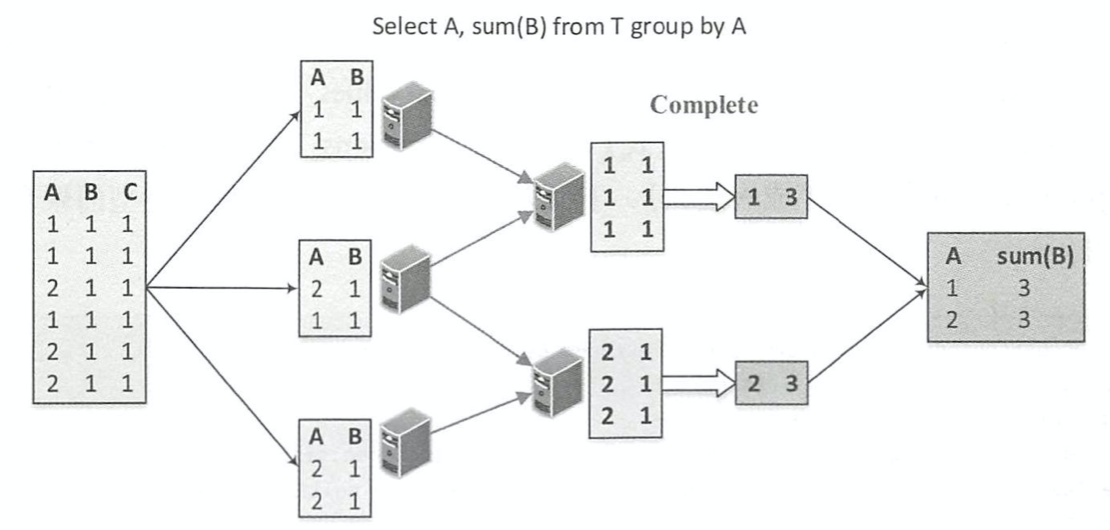
Complete模式和上述的 Partial/Final组合方式不一样,不进行局部聚合计算。 下图展示了同样的聚合函数采用 Complete模式的情形。 可以看到,最终阶段直接针对原始输入,中间没有局部聚合过程。 一般来讲, Complete模式应用在不支持Partial模式的聚合函数中。
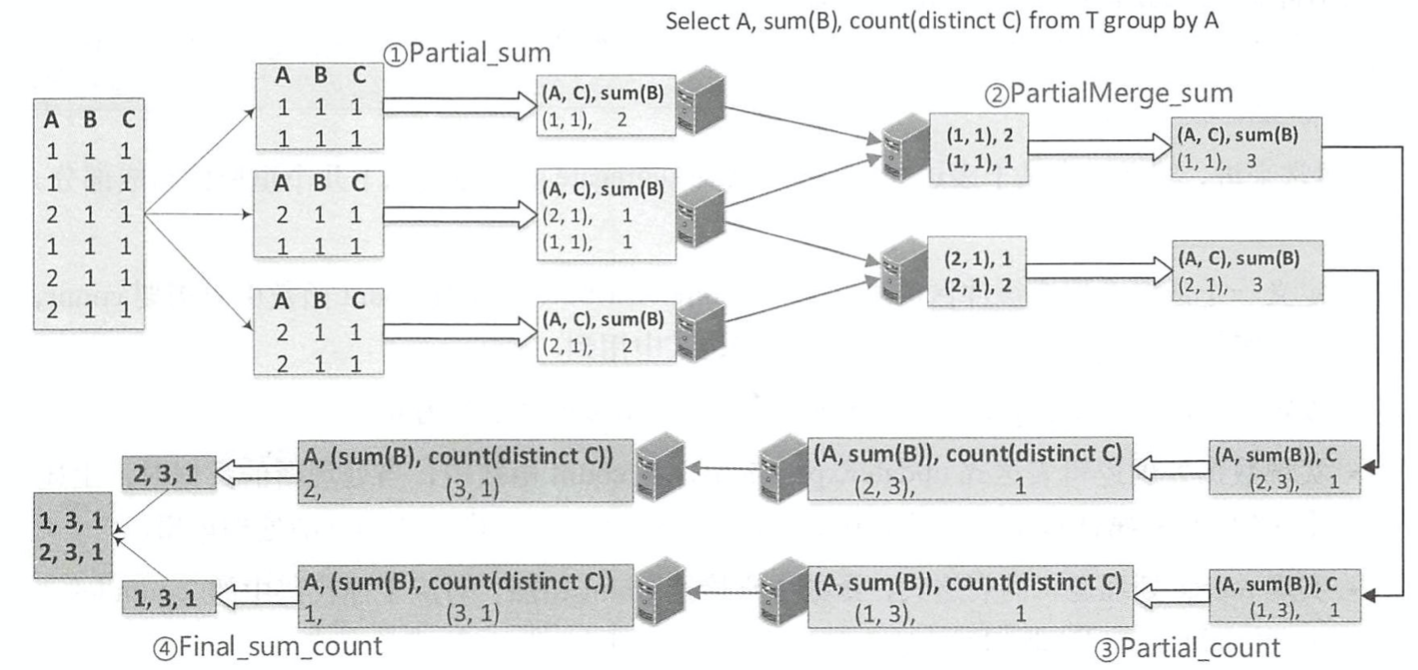
相比 Partial、 Final和 Complete模式, PartialMerge模式的聚合函数主要是对聚合缓冲区进行合并,但此时仍然不是最终的结果。 ParitialMerge主要应用在 distinct语句中,如下图所示。 聚合语句针对同一张表进行 sum 和 count (distinct)查询,最终的执行过程包含了 4 步聚合操作。 第1步按照(A,C)分组,对 sum函数进行 Partial模式聚合计算;第2步是 PartialMerge模式,对上一步计算之后的聚合缓冲区进行合井,但此时仍然不是最终的结果;第3步分组的列 发生变化,再一次进行 Partial模式的 count计算;第4步完成 Final模式的最终计算。
Hive on Spark与SparkSQL的区别
Hive on Spark是由Cloudera发起,由Intel、MapR等公司共同参与的开源项目,其目的是把Spark作为Hive的一个计算引擎,将Hive的查询作为Spark的任务提交到Spark集群上进行计算。通过该项目,可以提高Hive查询的性能,同时为已经部署了Hive或者Spark的用户提供了更加灵活的选择,从而进一步提高Hive和Spark的普及率。
Hive on Spark是从Hive on MapReduce演进而来,Hive的整体解决方案很不错,但是从查询提交到结果返回需要相当长的时间,查询耗时太长,这个主要原因就是由于Hive原生是基于MapReduce的,那么如果我们不生成MapReduce Job,而是生成Spark Job,就可以充分利用Spark的快速执行能力来缩短HiveQL的响应时间。
Hive on Spark现在是Hive组件(从Hive1.1 release之后)的一部分。
SparkSQL和Hive On Spark都是在Spark上实现SQL的解决方案。Spark早先有Shark项目用来实现SQL层,不过后来推翻重做了,就变成了SparkSQL。这是Spark官方Databricks的项目,Spark项目本身主推的SQL实现。Hive On Spark比SparkSQL稍晚。Hive原本是没有很好支持MapReduce之外的引擎的,而Hive On Tez项目让Hive得以支持和Spark近似的Planning结构(非MapReduce的DAG)。所以在此基础上,Cloudera主导启动了Hive On Spark。这个项目得到了IBM,Intel和MapR的支持(但是没有Databricks)。
结构上Hive On Spark和SparkSQL都是一个翻译层,把一个SQL翻译成分布式可执行的Spark程序。比如一个SQL:
SELECT item_type, sum(price)
FROM item
GROUP item_type;上面这个SQL脚本交给Hive或者类似的SQL引擎,它会“告诉”计算引擎做如下两个步骤:读取item表,抽出item_type,price这两个字段;对price计算初始的SUM(其实就是每个单独的price作为自己的SUM)因为GROUP BY说需要根据item_type分组,所以设定shuffle的key为item_type从第一组节点分组后分发给聚合节点,让相同的item_type汇总到同一个聚合节点,然后这些节点把每个组的Partial Sum再加在一起,就得到了最后结果。不管是Hive还是SparkSQL大致上都是做了上面这样的工作。
需要理解的是,Hive和SparkSQL都不负责计算,它们只是告诉Spark,你需要这样算那样算,但是本身并不直接参与计算。
Spark UDAF开发
分两种
- 无泛型约束的UDAF ?extends UserDefinedAggregateFunction ?extends Aggregator ?dataframe设计的
- 有泛型约束的UDAF ?extends Aggregator 该UDAF时允许添加泛型,保障函数更加安全。但是这种UDAF不可直接在SQL中被调用运算适用于强类型Datasets。
在Spark中使用
? ? 1.编写UDAF<两种类型的UDAF都可以>
? ? 2. 在spark中注册UDAF,为其绑定一个名字,使用
在Spark SQL 中使用
? ?1.编写UDAF<使用继承 UserDefinedAggregateFunction 类型编写>
? ?2. 打Jar包,并上传
? ?3. 注册临时聚合函数,并使用
ADD ?jar TestSpark.jar;
CREATE ?TEMPORARY FUNCTION ?mean_my AS ?'com.test.structure.udaf.MeanMy';
select t1.data,mean_my(t1.age)
from (
select 33 as age, ?'1' as data
union all
select 55 ?as age, '1' as data?
union all
select 66 as age, '2' as data
)t1
group by ? t1.data;自定义UDAF类
import org.apache.spark.sql.Row;
import org.apache.spark.sql.expressions.MutableAggregationBuffer;
import org.apache.spark.sql.expressions.UserDefinedAggregateFunction;
import org.apache.spark.sql.types.DataType;
import org.apache.spark.sql.types.DataTypes;
import org.apache.spark.sql.types.StructField;
import org.apache.spark.sql.types.StructType;
import java.util.ArrayList;
import java.util.List;
public class MeanFloatUDAF extends UserDefinedAggregateFunction {
/**
* 聚合函数的输入数据结构
* 函数的参数列表,不过需要写成StructType的格式
*/
@Override
public StructType inputSchema() {
List<StructField> structFields = new ArrayList<>();
structFields.add(DataTypes.createStructField( "field_nm", DataTypes.DoubleType, true ));
return DataTypes.createStructType( structFields );
}
/**
* 聚缓存区数据结构 - 产生中间结果的数据类型
* 如果是求平均数,存储总和以及计数,总和及计数就是中间结果
* count buffer.getInt(0)
* sum_field buffer.getDouble(1)
*/
@Override
public StructType bufferSchema() {
List<StructField> structFields = new ArrayList<>();
structFields.add(DataTypes.createStructField( "count", DataTypes.IntegerType, true ));
structFields.add(DataTypes.createStructField( "sum_field", DataTypes.DoubleType, true ));
return DataTypes.createStructType( structFields );
}
/**
* 聚合函数返回值数据结构
*/
@Override
public DataType dataType() {
return DataTypes.DoubleType;
}
/**
* 聚合函数是否是幂等的,即相同输入是否总是能得到相同输出
*/
@Override
public boolean deterministic() {
return true;
}
/**
* 初始化缓冲区
* buffer是中间结果,是Row类的子类
*/
@Override
public void initialize(MutableAggregationBuffer buffer) {
//相加的初始值,这里的要和上边的中间结果的类型和位置相对应 - buffer.getInt(0)
buffer.update(0,0);
//参与运算数字个数的初始值
buffer.update(1,Double.valueOf(0.0) );
}
/**
* 给聚合函数传入一条新数据进行处理
* //每有一条数据参与运算就更新一下中间结果(update相当于在每一个分区中的计算)
* buffer里面存放着累计的执行结果,input是当前的执行结果
*/
@Override
public void update(MutableAggregationBuffer buffer, Row input) {
//个数加1
buffer.update(0,buffer.getInt(0)+1);
//每有一个数字参与运算就进行相加(包含中间结果)
buffer.update(1,buffer.getDouble(1)+Double.valueOf(input.getDouble(0)));
}
/**
* 合并聚合函数缓冲区 //全局聚合
*/
@Override
public void merge(MutableAggregationBuffer buffer1, Row buffer2) {
buffer1.update(0,buffer1.getInt(0)+buffer2.getInt(0));
buffer1.update(1,buffer1.getDouble(1)+buffer2.getDouble(1));
}
/**
* 计算最终结果
*/
@Override
public Object evaluate(Row buffer) {
return buffer.getDouble(1)/buffer.getInt(0);
}
使用自定义UDAF
//在Spark中使用 extends UserDefinedAggregateFunction类型的UDAF的使用
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.RowFactory;
import org.apache.spark.sql.SparkSession;
import org.apache.spark.sql.types.DataTypes;
import org.apache.spark.sql.types.Metadata;
import org.apache.spark.sql.types.StructField;
import org.apache.spark.sql.types.StructType;
import java.util.Arrays;
import java.util.List;
public class MeanUDAFMain {
public static void main(String[] args){
try {
SparkSession spark = SparkSession
.builder()
.appName("Java Spark SQL data sources example")
.config("spark.some.config.option", "some-value")
.master("local[2]")
.getOrCreate();
List<Row> dataExample = Arrays.asList(
RowFactory.create( "2019-0801", 4,9.2),
RowFactory.create( "2020-0802", 3,8.6),
RowFactory.create( "2021-0803",2,5.5),
RowFactory.create( "2021-0803",2,5.5),
RowFactory.create( "2021-0803",7,4.5)
);
StructType schema = new StructType(new StructField[]{
new StructField("date", DataTypes.StringType, false, Metadata.empty()),
new StructField("dist_mem", DataTypes.IntegerType, false, Metadata.empty()),
new StructField("dm_mem", DataTypes.DoubleType, false, Metadata.empty())
});
Dataset<Row> itemsDF = spark.createDataFrame(dataExample, schema);
itemsDF.printSchema();
itemsDF.createOrReplaceTempView("test_mean_table");
// 注册自定义聚合函数 -2. 在spark中注册UDAF,为其绑定一个名字
spark.udf().register("mymean",new MeanFloatUDAF ());
spark.sql("select dist_mem from test_mean_table").show();
spark.sql("select date,mymean(dm_mem) memdoubleMean from test_mean_table group by date").show();
} catch (Exception e) {
e.printStackTrace();
}
}
}
Hive UDAF开发
UDF、UDAF、UDTF需要实现的方法
| 类型 | 类 | 方法 |
| UDF | 类: GenericUDF
| initialize:类型检查,返回结果类型 evaluate:功能逻辑实现 入参:DeferredObject[] 出参:Object 出参:String close:关闭函数,释放资源等 出参:void |
| UDTF | 类: 包路径: | initialize:类型检查,返回结果类型 process:功能逻辑实现 入参:Object[] 出参:void 出参:void |
| UDAF | 类: 类:
AbstractAggregationBuffer | -----AbstractGenericUDAFResolver----- getEvaluator:获取计算器 ---------GenericUDAFEvaluator---------- init: getNewAggregationBuffer: 入参:无 出参:AggregationBuffer reset: 入参:AggregationBuffer 出参:void 入参:AggregationBuffer,Object[] 出参:void merge: 入参:AggregationBuffer,Object 出参:void
入参:AggregationBuffer 出参:Object 入参:AggregationBuffer 出参:Object --------AbstractAggregationBuffer------- 入参:无 出参:int |
UDAF说明
一个Buffer作为中间处理数据的缓冲:获取getNewAggregationBuffer、重置reset
四个模式(Mode):
- PARTIAL1:
from original data to partial aggregation data:
iterate() and terminatePartial() will be called. - PARTIAL2:
from partial aggregation data to partial aggregation data:
merge() and terminatePartial() will be called. - FINAL:
from partial aggregation to full aggregation:
merge() and terminate() will be called. - COMPLETE:
from original data directly to full aggregation:
iterate() and terminate() will be called.
五个方法:
- 初始化init
- 遍历iterate:PARTIAL1和COMPLETE阶段
- 合并merge:PARTIAL2和FINAL阶段
- 终止terminatePartial:PARTIAL1和PARTIAL2阶段
- terminate:COMPLETE和FINAL阶段
?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!