基于内存的分布式NoSQL数据库Redis(三)常用命令
文章目录
知识点07:String类型的常用命令
-
目标:掌握String类型的常用命令
-
实施
- set:给String类型的Value的进行赋值或者更新
- 语法:set K V
- get:读取String类型的Value的值
- 语法:get K
- mset:用于批量写多个String类型的KV
- 语法:mset K1 V1 K2 V2 ……
- mget:用于批量读取String类型的Value
- 语法:mget K1 K2 K3 ……
- setnx:只能用于新增数据,当K不存在时可以进行新增
- 语法:setnx K V
- 应用:构建抢占锁,搭配expire来使用
- incr:用于对数值类型的字符串进行递增,递增1,一般用于做计数器
- 语法:incr K
- incrby:指定对数值类型的字符串增长固定的步长
- 语法:incrby K N
- decr:对数值类型的数据进行递减,递减1
- 语法:decr K
- decrby:按照指定步长进行递减
- 语法:decrby K N
- incrbyfloat:基于浮点数递增
- 语法:incrbyfloat K N
- strlen:统计字符串的长度
- 语法:strlen K
- getrange:用于截取字符串
- 语法:getrange s2 start end
node1:6379> keys * (empty list or set) node1:6379> set s1 hadoop OK node1:6379> get s1 "hadoop" node1:6379> mset s2 hive s3 spark OK node1:6379> keys * 1) "s3" 2) "s1" 3) "s2" node1:6379> mget s1 s3 1) "hadoop" 2) "spark" node1:6379> set s1 oozie OK node1:6379> get s1 "oozie" node1:6379> node1:6379> setnx s4 hue (integer) 1 node1:6379> get s4 "hue" node1:6379> setnx s4 flume (integer) 0 node1:6379> get s4 "hue" node1:6379> set s5 2 OK node1:6379> get s5 "2" node1:6379> incr s5 (integer) 3 node1:6379> get s5 "3" node1:6379> incr s5 (integer) 4 node1:6379> get s5 "4" node1:6379> incrby s5 3 (integer) 7 node1:6379> get s5 "7" node1:6379> decr s5 (integer) 6 node1:6379> get s5 "6" node1:6379> decrby s5 2 (integer) 4 node1:6379> get s5 "4" node1:6379> set s6 19.2 OK node1:6379> get s6 "19.2" node1:6379> incrbyfloat s6 2.5 "21.7" node1:6379> get s6 "21.7" node1:6379> get s1 "oozie" node1:6379> strlen s1 (integer) 5 node1:6379> getrange s1 0 2 "ooz" node1:6379> getrange s1 2 2 "z" node1:6379> - set:给String类型的Value的进行赋值或者更新
-
小结
- 掌握String类型的常用命令
知识点08:Hash类型的常用命令
-
目标:掌握Hash类型的常用命令
-
实施
-
hset:用于为某个K添加一个属性
- 语法:hset K k v
-
hget:用于获取某个K的某个属性的值
- 语法:hget K k
-
hmset:批量的为某个K赋予新的属性
- 语法:hmset K k1 v1 k2 v2 ……
-
hmget:批量的获取某个K的多个属性的值
- 语法:hmget K k1 k2 k3……
-
hgetall:获取所有属性的值
- 语法:hgetall K
-
hdel:删除某个属性
- 语法:hdel K k1 k2 ……
-
hlen:统计K对应的Value总的属性的个数
- 语法:hlen K
-
hexists:判断这个K的V中是否包含这个属性
- 语法:hexists K k
-
hvals:获取所有属性的value的
- 语法:hvals K
node1:6379> hget m1 name "zhangsan" node1:6379> hget m1 age "19" node1:6379> hmset m1 gender male phone 110 addr shanghai OK node1:6379> hmget m1 name phone gender 1) "zhangsan" 2) "110" 3) "male" node1:6379> hgetall m1 1) "name" 2) "zhangsan" 3) "age" 4) "19" 5) "gender" 6) "male" 7) "phone" 8) "110" 9) "addr" 10) "shanghai" node1:6379> hdel m1 gender (integer) 1 node1:6379> hgetall m1 1) "name" 2) "zhangsan" 3) "age" 4) "19" 5) "phone" 6) "110" 7) "addr" 8) "shanghai" node1:6379> hlen m1 (integer) 4 node1:6379> hexists m1 name (integer) 1 node1:6379> hexists m1 gender (integer) 0 node1:6379> hgetall m1 1) "name" 2) "zhangsan" 3) "age" 4) "19" 5) "phone" 6) "110" 7) "addr" 8) "shanghai" node1:6379> hvals m1 1) "zhangsan" 2) "19" 3) "110" 4) "shanghai" -
-
小结
- 掌握Hash类型的常用命令
知识点09:List类型的常用命令
-
目标:掌握List类型的常用命令
-
实施
-
lpush:将每个元素放到集合的左边,左序放入
- 语法:lpush K e1 e2 e3……
-
rpush:将每个元素放到集合的右边,右序放入
- 语法:rpush K e1 e2 e3……
-
lrange:通过下标的范围来获取元素的数据
-
语法:lrange K start end
-
注意:从左往右的下标从0开始,从右往左的下标从-1开始,一定是从小的到大的下标
-
lrange K 0 -1:所有元素
-
-
**llen:**统计集合的长度
-
语法:llen K
-
lpop:删除左边的一个元素
- 语法:lpop K
-
rpop:删除右边的一个元素
- 语法:rpop K
node1:6379> lpush list1 1 2 2 3 (integer) 4 node1:6379> rpush list1 4 5 6 6 7 8 (integer) 10 node1:6379> lrange list1 0 9 1) "3" 2) "2" 3) "2" 4) "1" 5) "4" 6) "5" 7) "6" 8) "6" 9) "7" 10) "8" node1:6379> lrange list1 4 9 1) "4" 2) "5" 3) "6" 4) "6" 5) "7" 6) "8" node1:6379> llen list1 (integer) 10 node1:6379> lrange list1 0 -1 1) "3" 2) "2" 3) "2" 4) "1" 5) "4" 6) "5" 7) "6" 8) "6" 9) "7" 10) "8" node1:6379> lrange list1 0 -3 1) "3" 2) "2" 3) "2" 4) "1" 5) "4" 6) "5" 7) "6" 8) "6" node1:6379> lrange list1 -3 -1 1) "6" 2) "7" 3) "8" node1:6379> lpop list1 "3" node1:6379> rpop list1 "8" node1:6379> lrange list1 0 -1 1) "2" 2) "2" 3) "1" 4) "4" 5) "5" 6) "6" 7) "6" 8) "7" node1:6379> -
-
小结
- 掌握List类型的常用命令
知识点10:Set类型的常用命令
-
目标:掌握Set类型的常用命令
-
实施
-
sadd:用于添加元素到Set集合中
- 语法:sadd K e1 e2 e3 e4 e5……
-
smembers:用于查看Set集合的所有成员
- 语法:smembers K
-
sismember:判断是否包含这个成员
- 语法:sismember K e1
-
srem:删除其中某个元素
- 语法:srem K e
-
scard:统计集合长度
- 语法:scard K
-
sunion:取两个集合的并集
- 语法:sunion K1 K2
-
sinter:取两个集合的交集
- 语法:sinter K1 K2
-
node1:6379> sadd set1 1 1 2 2 3 4 3 4
(integer) 4
node1:6379> smembers set1
1) "1"
2) "2"
3) "3"
4) "4"
node1:6379> scard set1
(integer) 4
node1:6379> sismember set1 1
(integer) 1
node1:6379> sismember set1 5
(integer) 0
node1:6379> srem set1 3
(integer) 1
node1:6379> smembers set1
1) "1"
2) "2"
3) "4"
node1:6379> sadd set2 1 3 6 9 8 9
(integer) 5
node1:6379> sunion set1 set2
1) "1"
2) "2"
3) "3"
4) "4"
5) "6"
6) "8"
7) "9"
node1:6379> sinter set1 set2
1) "1"
node1:6379>
?
-
小结
- 掌握Set类型的常用命令
知识点11:Zset类型的常用命令
-
目标:掌握Zset类型的常用命令
-
实施
-
zadd:用于添加元素到Zset集合中
- 语法:zadd K score1 k1 score2 k2 ……
-
zrange:范围查询
- 语法:zrange K start end [withscores]
-
zrevrange:倒序查询
- 语法:zrevrange K start end [withscores]
-
zrem:移除一个元素
- 语法:zrem K k1
-
zcard:统计集合长度
- 语法:zcard K
-
zscore:获取评分
- 语法:zscore K k
node1:6379> zadd zset1 99.5 yingyu 30.7 shuxue 29.9 yuwen 100 shengwu 56.73 dili (integer) 5 node1:6379> zrange zset1 0 -1 1) "yuwen" 2) "shuxue" 3) "dili" 4) "yingyu" 5) "shengwu" node1:6379> zrevrange zset1 0 -1 1) "shengwu" 2) "yingyu" 3) "dili" 4) "shuxue" 5) "yuwen" node1:6379> zrevrange zset1 0 -1 withscores 1) "shengwu" 2) "100" 3) "yingyu" 4) "99.5" 5) "dili" 6) "56.729999999999997" 7) "shuxue" 8) "30.699999999999999" 9) "yuwen" 10) "29.899999999999999" node1:6379> node1:6379> zrem zset1 yuwen (integer) 1 node1:6379> zrevrange zset1 0 -1 withscores 1) "shengwu" 2) "100" 3) "yingyu" 4) "99.5" 5) "dili" 6) "56.729999999999997" 7) "shuxue" 8) "30.699999999999999" node1:6379> node1:6379> zcard zset1 (integer) 4 node1:6379> zscore zset1 shuxue "30.699999999999999"- 注意:Redis中不建议存储小数值,存在精度问题,建议转换为整形存储
-
-
小结
- 掌握Zset类型的常用命令
知识点12:BitMap类型的常用命令
-
目标:掌握BitMap类型的常用命令
-
实施
-
功能:通过一个String对象的存储空间,来构建位图,用每一位0和1来表示状态

-
Redis中一个String最大支持512M = 2^32次方,1字节 = 8位
-
使用时,可以指定每一位对应的值,要么为0,要么为1,默认全部为0
-
用下标来标记每一位,第一个位的下标为0

-
-
举例:统计UV
-
一个位图中包含很多位,可以用每一个位表示一个用户id
-
读取数据,发现一个用户id,就将这个用户id对应的那一位改为1
-
统计整个位图中所有1的个数,就得到了UV
-
-
setbit:修改某一位的值
-
语法:setbit bit1 位置 0/1
setbit bit1 0 1
-
-
getbit:查看某一位的值
-
语法:getbit K 位置
getbit bit1 9
-
-
bitcount:用于统计位图中所有1的个数
-
语法:bitcount K [start end]
bitcount bit1 #start和end表示的是字节:1 字节 = 8 位 bitcount bit1 0 10
-
-
bitop:用于位图的运算:and/or/not/xor
-
语法:bitop and/or/xor/not bitrs bit1 bit2
bitop and bit3 bit1 bit2 bitop or bit4 bit1 bit2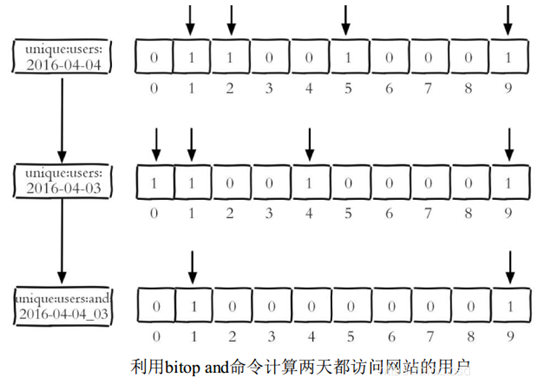
-
-
-
小结
- 掌握BitMap类型的常用命令
知识点13:HyperLogLog类型的常用命令
-
目标:掌握HyperLogLog类型的常用命令
-
实施
-
功能:类似于Set集合,用于实现数据的去重
-
区别:底层实现原理不一样
-
应用:适合于数据量比较庞大的情况下的使用,存在一定的误差率
-
-
pfadd:用于添加元素
-
语法:pfadd K e1 e2 e3……
pfadd pf1 userid1 userid1 userid2 userid3 userid4 userid3 userid4 pfadd pf2 userid1 userid2 userid2 userid5 userid6
-
-
-
pfcount:用于统计个数
-
语法:pfcount K
pfcount pf1
-
-
pfmerge:用于实现集合合并
-
语法:pfmerge pfrs pf1 pf2……
pfmerge pf3 pf1 pf2
-
-
小结
- 掌握HyperLogLog类型的常用命令
后记
📢博客主页:https://manor.blog.csdn.net
📢欢迎点赞 👍 收藏 ?留言 📝 如有错误敬请指正!
📢本文由 Maynor 原创,首发于 CSDN博客🙉
📢不能老盯着手机屏幕,要不时地抬起头,看看老板的位置?
📢专栏持续更新,欢迎订阅:https://blog.csdn.net/xianyu120/category_12394313.html
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!