EVA:Exploring the Limits of Masked Visual Representation Learning at Scale
2024-01-08 18:42:03
Abstract
-
EVA是一个基础的Transformer视觉模型
-
预训练任务:训练的图片是masked掉的50%的patches, 模型的任务是预测被遮挡的图像特征。
模型经过预训练,学会了通过图像和文本的对齐关系来重构被遮挡的部分,使其能够理解图像和文本之间的关联。 -
通过这个预训练任务,我们能够高效地将EVA扩展到十亿个参数。
-
这样就可以得到很大的模型,在下游任务上会有很好的表现
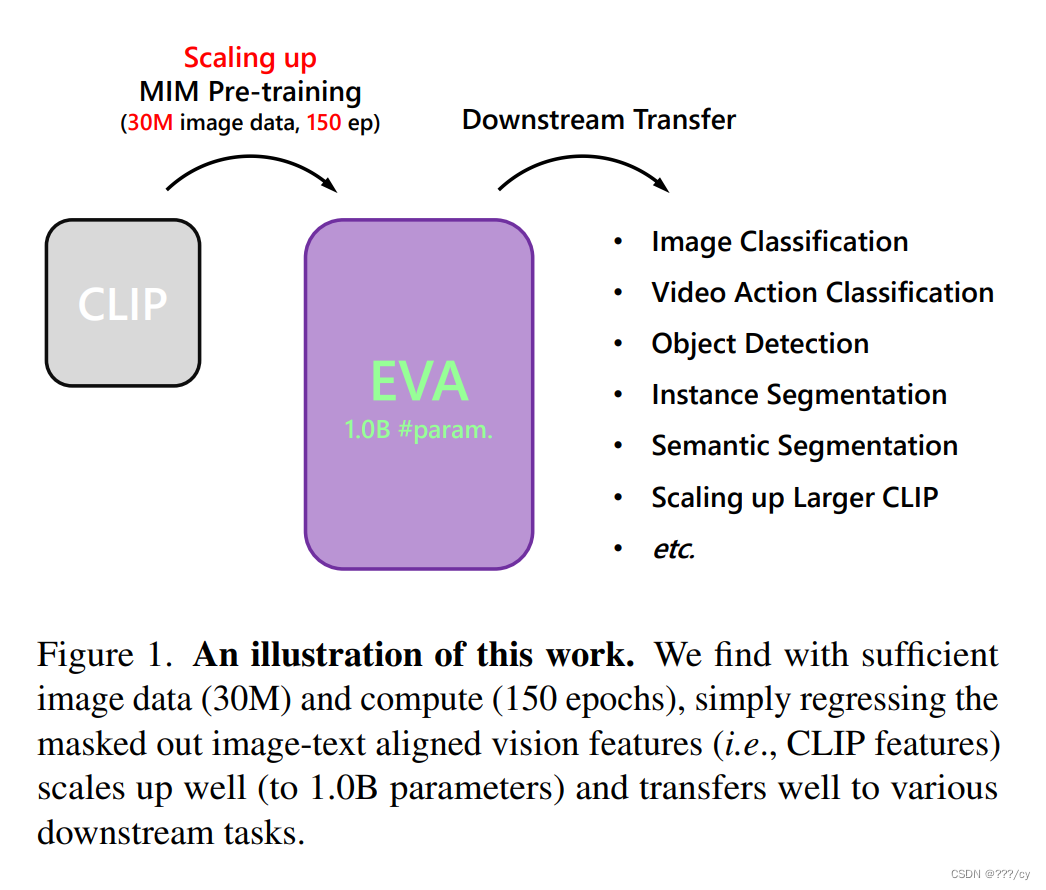
通过MIM 预训练,使得基于CLIP的预训练模型变大,得到1B param的EVA
,这个EVA模型迁移在下游任务中表现非常好。
Highlight
- 用EVA初始化的CLIP模型,无论文是数据量,还是GPUs消耗情况,都比原始的CLIP要高效和有效。这样不但加速了训练的过程,而且提高了zero-shot classification的表现。
Introduction
- 为大规模视觉表征学习找到了一个合适的MIM预训练目标
- 在1B-parameters with 亿级未标签的数据 的量级 探索它的极限
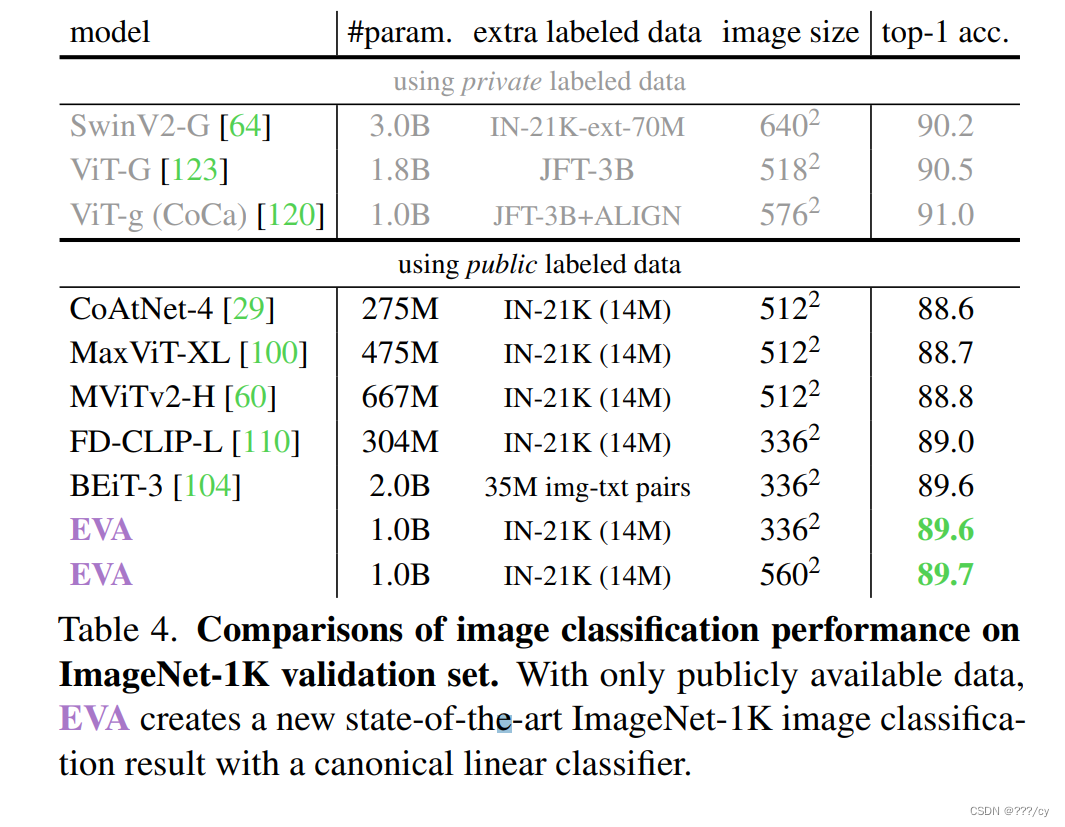
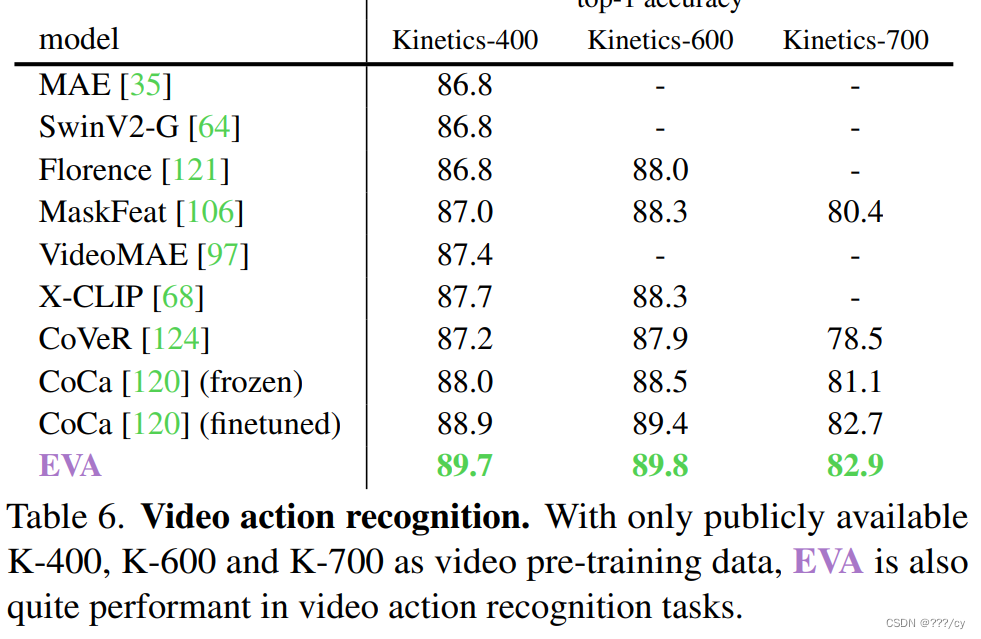
EVA arxiv
EVA这篇论文翻译写的很好
文章来源:https://blog.csdn.net/qq_45842681/article/details/135459468
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!