过度加大SSD内部并发何尝不是一种伤害-part2
方案设计完了,如何验证效果如何呢?作者是这么做的。
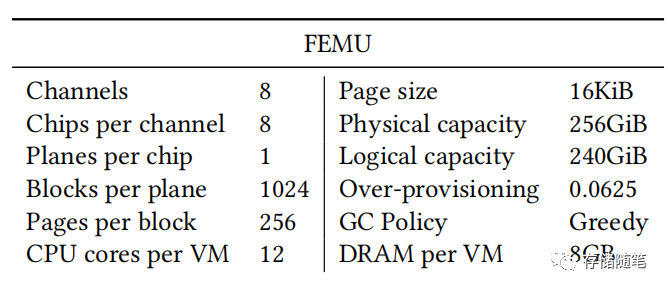
第一步,选择模拟环境:PLAN方案在定制的FEMU(Flash Emulation Module)上实现,该模块支持TRIM和多流功能,具体参数如下:
第二步,选择不同的IO负载:多种不同I/O特性的工作负载评估。
-
-
使用FIO的 workload,同时运行4个FIO进程,每个进程向不同大小的文件(大小比为1:10:30:64)发出总共256GiB的I/O(读写各占50%)。
-
TPC-C workload,使用30个终端和30个仓库的BenchBase,在MySQL上运行,InnoDB页面大小为4KiB。
-
YCSB workload,首先插入1亿个键值对,然后在RocksDB上执行5000万次操作(工作负载A:读取占50%,更新占50%)。
-
Fileserver workload,来自Filebench,包含100万个128KiB的文件和16个实例。
-
GCC Linux内核编译工作负载,进行100次迭代。每次迭代都将Linux内核源代码复制到SSD,编译内核,然后删除源代码和编译后的二进制文件。
-
第三步,模拟器验证设置:对于每个工作负载,都在以下设置下运行,并使用相同数量的并发打开的超级块,并为每个超级块使用所有8个通道:
-
-
基线:传统SSD,不使用数据分类方案。
-
部分GC:传统SSD但使用部分GC,即SSD仍然对超级块使用全并行性和跨所有可用通道和芯片的数据条带化,但SSD选择具有最少有效页数的块作为GC目标块。
-
多流Multi-Stream:传统SSD使用多流方案。
-
AutoStream:传统SSD使用AutoStream(SFR)方案。
-
PLAN-NoPred-1/4:不使用任何数据分类方案的PLAN。所有大型顺序请求被发送到默认的大超级块,而所有小型随机请求被发送到默认的小超级块。小超级块使用所有通道和每通道2个芯片(1/4并行性)。
-
PLAN-NoPred-1/8:与PLAN-NoPred-1/4类似,但小超级块使用每通道1个芯片(1/8并行性)。
-
PLAN-Pred-1/4:使用SSD内部寿命预测的PLAN。小超级块使用所有通道和每通道2个芯片(1/4并行性)。这是推荐的配置。
-
PLAN-Pred-1/8:与PLAN-Pred-1/4类似,但小超级块使用每通道1个芯片(1/8并行性)。
-
最后,实验结果分析显示有如下几个方面的信息:
-
-
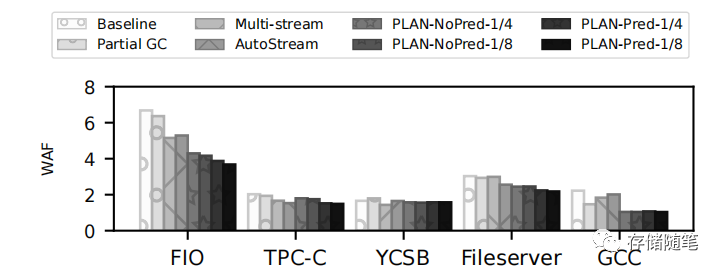
降低写放大(WAF):PLAN可以降低各种工作负载的WAF,特别是对于发出许多小型随机写入的工作负载(如FIO、TPC-C、Fileserver和GCC),PLAN-Pred-1/4可以将WAF至少降低25%。
-
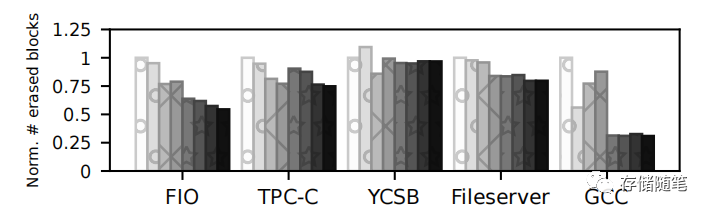
擦除总块数:PLAN在减少擦除的块数方面显示出最大的优势,特别是在FIO和GCC工作负载上。与基线相比,PLAN-Pred-1/4在FIO和GCC工作负载上分别将擦除的块数减少了高达46%和69%。在不影响或甚至提高性能的同时,显著减少垃圾收集活动对SSD的影响,特别是通过减少所需的擦除操作数量。
-
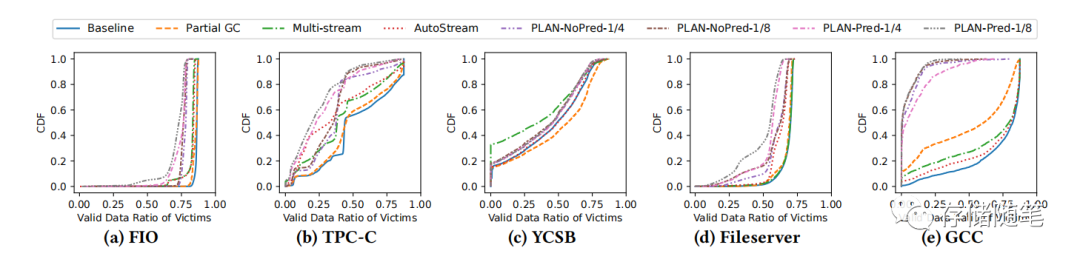
GC受影响超级块的有效数据比率:通过累积分布函数(CDF)展示了每次GC期间受影响超级块(即待擦除的超级块)的有效数据比率。曲线越偏向左边,表示在GC过程中需要重定位的有效页面越少,也就是说GC效率越高。PLAN的曲线在FIO、TPC-C、Fileserver和GCC工作负载中相比其他方法更偏向左边,这表明PLAN在这些工作负载上的GC性能更好。而对于YCSB工作负载,多流方案表现最佳,因为RocksDB数据库能够最好地预测数据的生命周期;数据库直接为写请求标记流ID,SSD将使用这些流ID相应地对传入数据进行分组。
-
归一化带宽:尽管PLAN降低了某些超级块的并行性,但即使对于包含大量大型顺序I/O的YCSB工作负载,吞吐量也没有受到影响。对于CPU受限的工作负载,如TPC-C、YCSB和GCC,PLAN在降低写放大因子的同时保持(甚至提高)了性能。同时,Fileserver在使用PLAN后性能提高了约10%,因为改进的GC效率释放了SSD内部资源,使得SSD能够处理更多的主机I/O请求。在PLAN-Pred-1/4上运行的FIO吞吐量提高了30%。
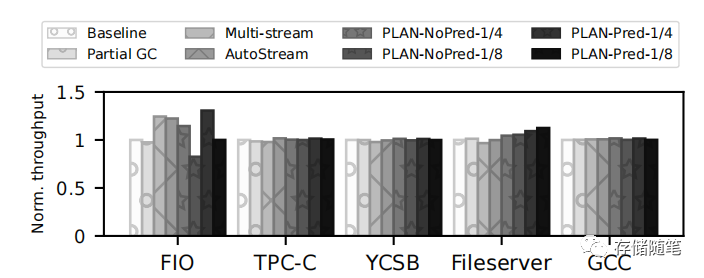
-
这些结果表明,通过使用PLAN方案,可以更有效地管理SSD内部的并行性和数据放置,从而降低垃圾收集的开销。减少擦除的块数意味着GC过程更加高效,因为需要移动和重写的数据量减少了,这进一步降低了写放大因子(WAF)和提高了整体性能。
小编每日撰文不易,如果您看完有所受益,欢迎点击文章底部左下角“关注”并点击“分享”、“在看”,非常感谢!
精彩推荐:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!