【星海随笔】ceph存储池
ceph部件很多。写到一个文章里太多了。每个分开写,找起来舒服一些
PG(Placement Group)是一个逻辑概念,用于数据的分布和复制。
注:OSD是负责物理存储的进程,它管理存储在磁盘上的数据。
ceph pool
ceph 容器
创建池
ceph osd pool create <pool-name> <pg-num> [<pgp-num>]
在Ceph中,PG(Placement Group)是数据复制和分布的基本单位。一个PG包含多个对象,并且这些对象在多个OSD(Object Storage Daemon)上具有副本。
推荐的设置:
少于5个OSD的情况,推荐将pg_num设置为128。
当有5到10个OSD时,pg_num可以设置为512。
在10到50个OSD的情况下,pg_num应设置为4096。
后期可以修改pg_num
ceph osd pool set <pool-name> pg_num <new-pg-num>
删除池
ceph osd pool delete <pool-name>
pool param
ceph osd pool get <pool-name> <param>
param
size #存储池中的对象副本数。数据的冗余程度。
min_size #提供服务所需要的最小副本数。在副本数不足的情况下,仍可以保证数据的可访问性。
当PG数量较少时,每个OSD上的PG负载较轻,有利于提高性能和降低CPU使用率。然而,较少的PG数量可能会导致数据分布不均匀,因为每个PG需要复制数据到多个OSD上。这可能导致某些OSD上的数据量远大于其他OSD,从而影响数据冗余的可靠性。
pg_num:存储池中的Placement Group(PG)数量。PG是Ceph用于数据分布和复制的逻辑容器。
pgp_num:用于数据归置的PG数量,通常与pg_num保持一致。
max_objects:存储池中允许的最大对象数量。默认情况下,这个值可能未设置(即无限制)。
max_bytes:存储池中允许的最大字节数,用于限制存储池的空间大小。默认情况下,这个值也可能未设置。
nodelete:一个布尔值,如果设置为true,则禁止删除存储池。
application:与存储池关联的应用类型,例如rbd、cephfs等。
crush_ruleset:指定用于该存储池的CRUSH规则集。CRUSH是Ceph使用的数据分布算法。
erasure_code_profile:如果该存储池使用了纠删码,则此参数指定纠删码的配置文件。
hit_set_type、hit_set_period、hit_set_count:与缓存相关的参数,用于优化性能。
target_max_objects、target_max_bytes:用于动态调整存储池大小的目标值。
auid、snap_mode、snap_seq:与快照相关的参数。
tier_of、cache_mode:与分层存储和缓存池相关的参数。
设置参数
ceph osd pool set <pool-name> <param> <value>: 设置存储池的参数值。
ceph osd pool setdata <pool-name> <param> <value>: 设置存储池的数据分布参数值。
ceph osd pool stats: 获取存储池的统计信息。
ceph osd pool list: 列出所有存储池的名称。
ceph osd pool getdata <pool-name>: 获取存储池的数据分布信息。
ceph osd pool rename <pool-name> <new-pool-name>: 重命名存储池的名称
ceph osd pool pgp <pool-name> <pgp-num>: 设置存储池的PGP数量。
参考资料:
https://blog.csdn.net/bandaoyu/article/details/120348914 #PG 状态集
接收数据
一旦客户端准备将数据写入Ceph池中,数据首先会被写入基于池副本数的主OSD中。主OSD再复制相同的数据到每个辅助OSD中,并等待它们确认写入完成。只有当辅助OSD完成数据写入并发送确认信号后,主OSD才会继续处理其他请求。
需要关注的性能指标
IOPS(Input/Output Operations Per Second):衡量系统每秒钟可以处理的读写操作数量。高IOPS意味着系统具有较好的随机读写性能。
响应时间:衡量系统响应请求的速度的指标。较低的响应时间通常意味着系统性能较好。
吞吐量:衡量系统传输数据速度的指标,通常以数据传输的速率(如MB/s)来衡量。
带宽利用率:衡量系统带宽使用情况的指标,高带宽利用率意味着系统可以快速传输大量数据。
延迟:衡量系统处理请求的时间的指标,包括单次请求延迟和多次请求的平均延迟。
负载均衡:衡量系统负载均衡能力的指标,良好的负载均衡可以确保系统资源得到充分利用,避免瓶颈和性能下降。
资源利用率:衡量系统资源使用情况的指标,包括CPU、内存、磁盘和网络等资源的利用率。
连接数:衡量系统可以同时处理的最大连接数,高连接数可以支持更多的并发请求。
接收数据时用到了CRUSH
CRUSH(Controlled Replication Under Scalable Hashing)算法,用于确定数据副本的放置位置和重建数据时的复制路径。
Ceph的分布式系统架构基于一致性哈希算法,将数据分散到多个存储节点上,从而实现数据的分布式存储和冗余备份。
每个存储节点上运行一个OSD(Object Storage Daemon)进程,负责管理存储设备、提供数据存储和访问功能。
ceph osd tree
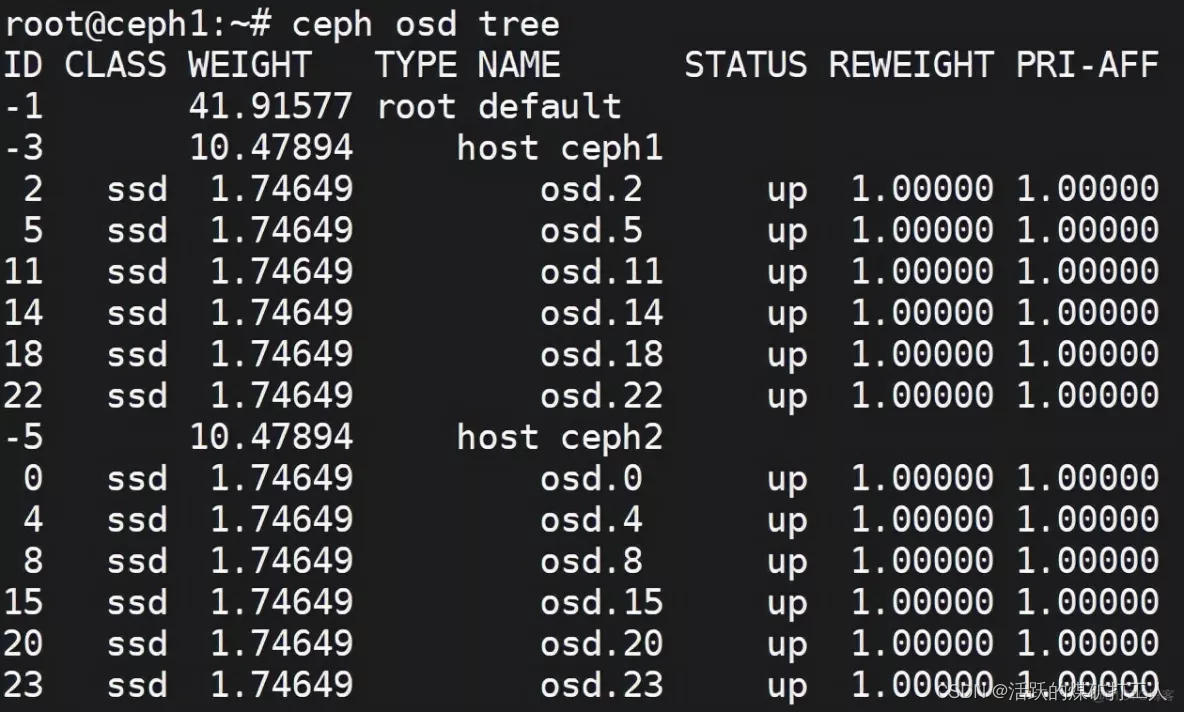
分布图可以保存为图片查看
ceph osd tree -f json-pretty > zp.json
curl --upload-file ./zp.json https://transfer.sh/zp.json
看别人的还没有验证:
调整rack结构
seq 1 8|xargs -i ceph osd crush add-bucket rack{} rack
seq 1 8|xargs -i ceph osd crush move rack{} root=default
#! /bin/sh
for host in `seq 1 40`
do
rack=$(( (((($host - 1)) / 5)) + 1 ))
ceph osd crush move lab$host rack=rack$rack &
done
查看OSD的分布
ceph osd tree -f json-pretty > zp.json
curl --upload-file ./zp.json https://transfer.sh/zp.json
删除某个OSD
附加知识(如何删除某个OSD,下面的假设是删除osd.4)
ceph osd tree
ceph osd out osd.4
ceph osd tree
ceph -s
ceph osd crush remove osd.4
ceph auth del osd.4
ceph -s
ceph osd rm osd.4
最后要找到对应的主机,umount把osd.4对应的磁盘卸载
调整再平衡参数:在配置文件中,可以找到与再平衡相关的参数。以下是一些常用的再平衡参数(/etc/ceph/ceph.conf):
- osd_auto_spread_base_ratio:控制自动再平衡时每个OSD应接收的数据量比例。增加该值将使再平衡过程更快,但可能会导致更多的数据迁移。
- osd_auto_spread_max_ratio:控制自动再平衡时每个OSD可以接收的最大数据量比例。增加该值将使再平衡过程更快,但可能会导致更多的数据迁移。
- osd_auto_spread_min_ratio:控制自动再平衡时每个OSD可以接收的最小数据量比例。减小该值将使再平衡过程更快,但可能会导致更多的数据迁移。
- osd_reweight_max:控制每个OSD的最大权重值。增加该值将使再平衡过程更快,但可能会导致不均衡的数据分布。
- osd_reweight_min:控制每个OSD的最小权重值。减小该值将使再平衡过程更快,但可能会导致不均衡的数据分布。根据需要调整这些参数的值,以加速再平衡过程。
再平衡问题查看:
- 使用ceph -s或ceph status命令:这个命令可以显示Ceph集群的整体状态,包括健康状态、数据分布、再平衡进度等。如果在输出中看到与再平衡相关的警告或错误,那么可能表明再平衡遇到了问题。
- 检查OSD日志:每个OSD都有自己的日志文件,通常位于/var/log/ceph/osd.{osd-num}.log。查看这些日志可以帮助你了解OSD在再平衡过程中的具体行为,以及是否出现了错误或异常。
- 使用ceph osd dump命令:这个命令可以显示集群中所有OSD的详细信息,包括它们的权重、当前状态、再平衡状态等。通过比较不同OSD的状态和权重,你可能能够发现再平衡失败的原因。
- 检查集群的PG状态:使用ceph pg dump命令可以查看集群中所有Placement Group(PG)的状态。如果在输出中看到某些PG处于“stale”、“undersized”、“degraded”或其他非健康状态,那么可能表明再平衡未能成功地将数据分布到所有副本中。
存储问题
- 在/etc/ceph/ceph.conf配置文件的[global]分节中,可以修改某些配置项的值来优化空间利用和资源限制。例如,可以调整mon osd full ratio的值,将其从默认的0.90修改为更大的值(例如0.98),以允许更多的数据存储在OSD上。
- 通过调整OSD的权重来实现数据再平衡。例如,如果某个OSD处于满状态,可以将其权重设置为更小的值(例如原值的0.8、0.5或0.01),然后观察数据的分布变化,直到OSD从满状态变为近满状态。
- 向系统添加新的硬盘,部署一个新的OSD,Ceph将自动平衡数据到新的OSD,从而释放满OSD上的部分空间。
- 考虑该osd是否有垃圾数据,是否可以清除。
PG到OSD关系
- 编辑Ceph集群的配置文件/etc/ceph/ceph.conf。在该文件中,找到与目标PG和目标OSD相关的配置项。
- 调整配置项的值以手动指定PG到OSD的映射。具体配置项可能会因Ceph版本和配置而有所不同,但通常包括类似于pg_to_osd或pg_mapping的选项。
手动修改 CRUSH 规则
编辑这个文件
ceph osd getcrushmap -o crushmap.txt
修改并验证
crushtool -d crushmap.txt -o crushmap-new.bin
crushtool --test -i crushmap-new.bin --show-utilization --rule 0 --num-rep=2
应用
ceph osd setcrushmap -i crushmap-new.bin
重启ceph
sudo systemctl restart ceph
【如果你只想重启某个节点上的Ceph守护进程,可以登录到该节点上,并执行以下命令:】
sudo systemctl restart ceph-mon@hostname
sudo systemctl restart ceph-osd@hostname
参考文档:
https://zhuanlan.zhihu.com/p/620137604 #安装
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!