【强化学习-读书笔记】动态规划(策略评估、价值迭代、策略迭代算法)
参考
Reinforcement Learning, Second Edition
An Introduction
By Richard S. Sutton and Andrew G. Barto
动态规划 (Dynamic Programming, DP) 是一类优化方法,在给定一个用马尔可夫决策过程 (MDP) 描述的完备环境模型的情况下,其可以计算最优的策略。
Recall: Bellman Equation
我们知道
v
π
v_\pi
vπ?的贝尔曼方程可以写作如下形式:
v
π
(
s
)
=
∑
a
π
(
a
∣
s
)
∑
s
′
,
r
p
(
s
′
,
r
∣
s
,
a
)
[
r
+
γ
v
π
(
s
′
)
]
v_\pi(s)=\sum_a \pi(a|s) \sum_{s',r} p(s',r|s,a)[r+\gamma v_{\pi}(s')]
vπ?(s)=a∑?π(a∣s)s′,r∑?p(s′,r∣s,a)[r+γvπ?(s′)]
如何求解最优策略
v
?
(
s
)
v_*(s)
v??(s)呢?
实际上对于每一个可能的状态
s
∈
S
s\in \mathcal{S}
s∈S,都有这样的一个方程,因此可以通过解这样一组贝尔曼方程组来直接求解出
v
?
(
s
)
v_*(s)
v??(s)。但是问题在于许多场景的状态空间很大,因此难以直接利用解方程的方式来求。因此我们考虑迭代的方式。
Example Task —— 最短路径任务
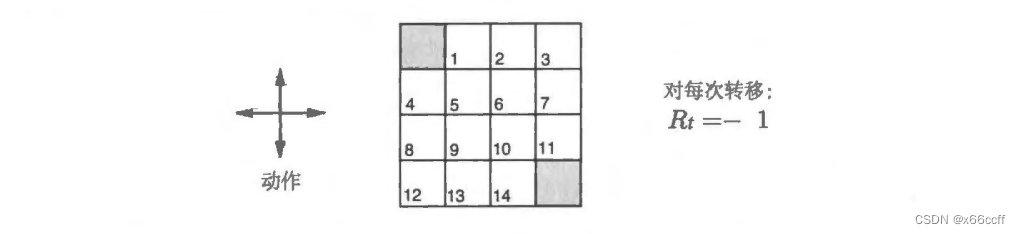
为了说明以下三个不同的算法,我们引入一个 exmaple task。 智能体的目标是找到从任意一个点出发怎么走才能最快到达图上的两个终止状态。每走一步,
r
=
?
1
r=-1
r=?1;如果出界,就保持原来的状态不动。
我们希望智能体能够找到最优价值函数
v
?
(
s
)
v_*(s)
v??(s) 或者最优策略
π
?
(
a
∣
s
)
\pi_*(a|s)
π??(a∣s)(以矩阵表示)
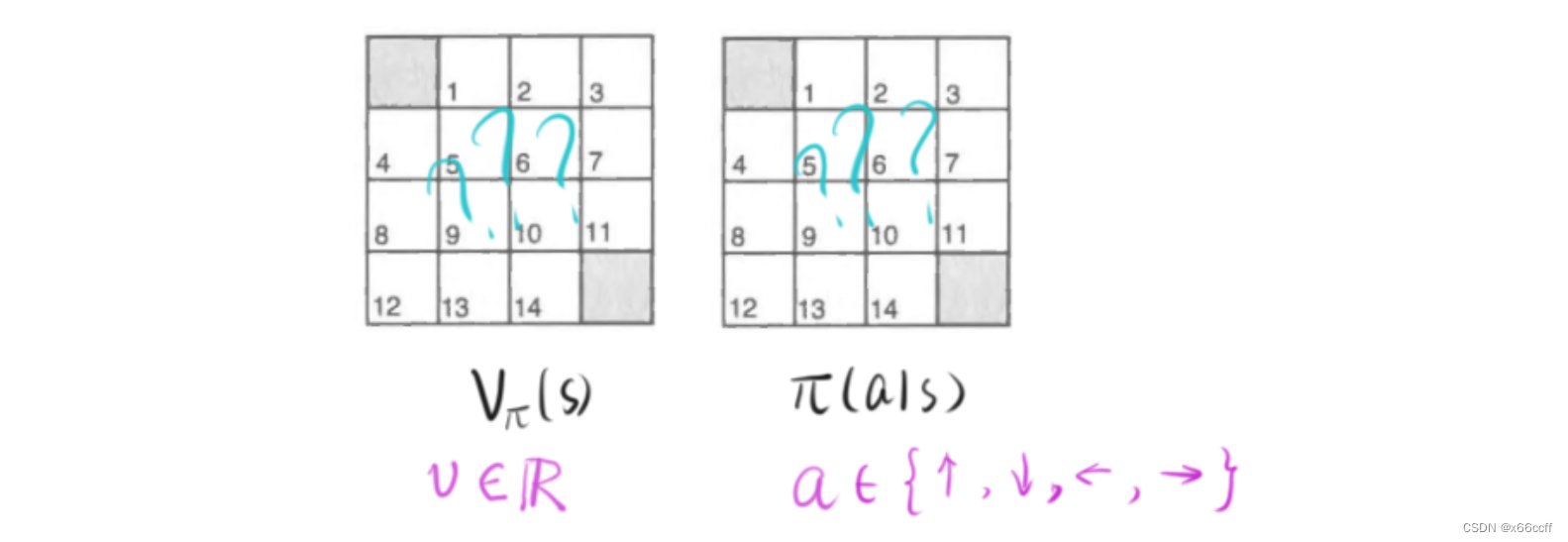
策略评估算法
策略评估(Policy Evaluation)算法的核心思想在于,如果存在最优价值函数
v
?
(
s
)
v_*(s)
v??(s),那么
v
?
(
s
)
v_*(s)
v??(s)实际上就是贝尔曼方程的一个不动点,我们从任意一个
V
0
V_0
V0?出发,不断迭代贝尔曼方程,最终收敛到的价值函数就是最优价值函数。
Δ
\Delta
Δ记录前后两个价值函数矩阵的最大差值,当差值足够小,就认为找到了
v
?
(
s
)
v_*(s)
v??(s)

import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
STOP = np.array([
[1,0,0,0],
[0,0,0,0],
[0,0,0,0],
[0,0,0,1]
])
V = np.array([
[0,0,0,0],
[0,0,0,0],
[0,0,0,0],
[0,0,0,0]
]).astype('float')
V_new = V.copy()
actions = [(0,1),(1,0),(0,-1),(-1,0)]
gamma = 1.0
states = [(i,j) for i in range(4) for j in range(4)]
print(states)
for step in range(100): # 对应贝尔曼方程
for state in states: # for s \in S
if STOP[state]:
continue
v = V[state]
res = 0
for action in actions: # \sum a
s_next = [action[0]+state[0], action[1]+state[1]]
# 处理边界动作
if s_next[0]<0:
s_next[0]=0
if s_next[0]>3:
s_next[0]=3
if s_next[1]<0:
s_next[1]=0
if s_next[1]>3:
s_next[1]=3
# print(state,'a:',action,'-> s',s_next)
r = -1 # 每走一步奖励固定是 -1
res += 1/4 * (r + gamma * V[tuple(s_next)]) # \pi(a|s) [r + \gamma V(s)]
V_new[state] = res
delta = (abs(V_new-V)).max()
V = V_new.copy()
if delta < 0.01:
plt.figure(figsize=(3,2))
sns.heatmap(V,annot=True,cmap='Blues_r')
plt.title('$V_\pi(s)$ @ step={} $\Delta$={:0.4f}'.format(step,delta),color='green')
plt.xlabel('x66ccff')
plt.ylabel('迭代策略评估')
plt.show()
print('break at delta={:.4f}, step={}'.format(delta, step))
break
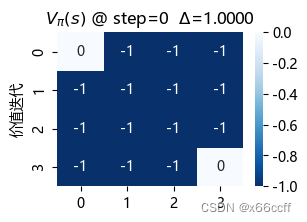
elif step <= 3:
plt.figure(figsize=(3,2))
sns.heatmap(V,annot=True,cmap='Blues_r')
plt.title('$V_\pi(s)$ @ step={} $\Delta$={:0.4f}'.format(step,delta),color='black')
plt.ylabel('迭代策略评估')
plt.show()
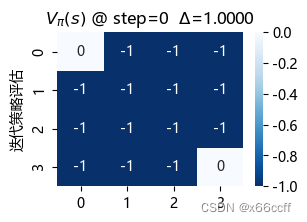
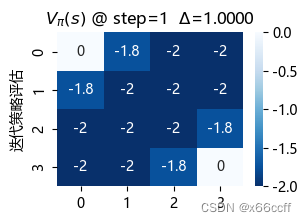
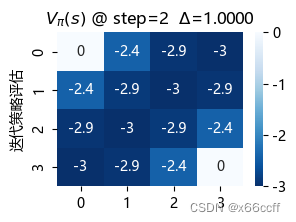
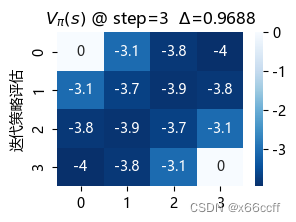
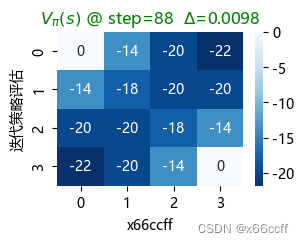
策略评估使用了长达 88 步才达到收敛
价值迭代(Value Iteration)
价值迭代仅仅是将贝尔曼最优方程变为一条更新规则。另外,除了从达到最大值的状态更新以外,价值迭代与策略评估的更新公式几乎完全相同
价值迭代(v 更新取 max)和策略评估(不动点)的区别仅仅在于多了一个取所有后继状态的价值的
max
?
\max
max ,而不是平均(期望)价值。

STOP = np.array([
[1,0,0,0],
[0,0,0,0],
[0,0,0,0],
[0,0,0,1]
])
V = np.array([
[0,0,0,0],
[0,0,0,0],
[0,0,0,0],
[0,0,0,0]
]).astype('float')
V_new = V.copy()
actions = [(0,1),(1,0),(0,-1),(-1,0)]
gamma = 1.0
states = [(i,j) for i in range(4) for j in range(4)]
print(states)
for step in range(100): # 对应贝尔曼方程
for state in states: # for s \in S
if STOP[state]:
continue
v = V[state]
# res = 0
res_a_ls = [] # <------ 修改的地方
for action in actions: # \sum a
s_next = [action[0]+state[0], action[1]+state[1]]
# 处理边界动作
if s_next[0]<0:
s_next[0]=0
if s_next[0]>3:
s_next[0]=3
if s_next[1]<0:
s_next[1]=0
if s_next[1]>3:
s_next[1]=3
# print(state,'a:',action,'-> s',s_next)
r = -1 # 每走一步奖励固定是 -1
# res += 1/4 * (r + gamma * V[tuple(s_next)]) # \pi(a|s) [r + \gamma V(s)]
res_a = (r + gamma * V[tuple(s_next)]) # <------ 修改的地方
res_a_ls.append(res_a) # <------ 修改的地方
V_new[state] = max(res_a_ls) # <------ 修改的地方
delta = (abs(V_new-V)).max()
V = V_new.copy()
if delta < 0.01:
plt.figure(figsize=(3,2))
sns.heatmap(V,annot=True,cmap='Blues_r')
plt.title('$V_\pi(s)$ @ step={} $\Delta$={:0.4f}'.format(step,delta),color='green')
plt.xlabel('x66ccff')
plt.ylabel('价值迭代')
plt.show()
print('break at delta={:.4f}, step={}'.format(delta, step))
break
elif step <= 3:
plt.figure(figsize=(3,2))
sns.heatmap(V,annot=True,cmap='Blues_r')
plt.title('$V_\pi(s)$ @ step={} $\Delta$={:0.4f}'.format(step,delta),color='black')
plt.ylabel('价值迭代')
plt.show()
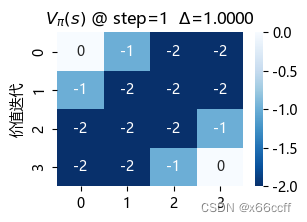
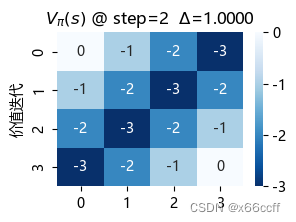
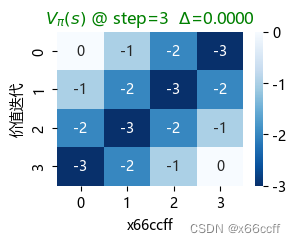
注意到,价值迭代只用了3步就达到了收敛,比策略评估算法快得多。
策略迭代(Policy Iteration)
策略迭代与前两者不同,不仅仅维护 V π ( s ) V_\pi(s) Vπ?(s)矩阵,还维护表示策略的 π ( a ∣ s ) \pi(a|s) π(a∣s)矩阵,两者交替进行更新。
其分为两个阶段:
- 策略评估(根据最优动作 π ( a ∣ s ) \pi(a|s) π(a∣s) 更新 V π V_\pi Vπ?,而不是求平均)
- 策略改进(根据 V π V_\pi Vπ? 更新每一个状态 s s s 的最优动作 π ( a ∣ s ) \pi(a|s) π(a∣s))
因此策略迭代相当于在策略评估算法(但没有求平均,而是
π
\pi
π直接给出
a
a
a)的基础上,加了一个策略改进的部分。

STOP = np.array([
[1,0,0,0],
[0,0,0,0],
[0,0,0,0],
[0,0,0,1]
])
V = np.array([
[0,0,0,0],
[0,0,0,0],
[0,0,0,0],
[0,0,0,0]
]).astype('float')
V_new = V.copy()
actions = [(0,1),(1,0),(0,-1),(-1,0)]
gamma = 1.0
states = [(i,j) for i in range(4) for j in range(4)]
print(states)
# 策略迭代新增
np.random.seed(42)
Policy = np.random.randint(0,4,16).reshape(4,4) # 随机初始化策略
Policy
array([[2, 3, 0, 2],
[2, 3, 0, 0],
[2, 1, 2, 2],
[2, 2, 3, 0]])
for step in range(100): # 对应贝尔曼方程
######################## a) 先根据策略Policy进行价值更新
for state in states: # for s \in S
if STOP[state]:
continue
v = V[state]
res = 0
# res_a_ls = [] # <------修改的地方
# for action in actions: # <------修改的地方 # 不需要 for a
action = actions[Policy[state]] # <------修改的地方 # 根据 Policy 选择a
s_next = [action[0]+state[0], action[1]+state[1]]
# 处理边界动作
if s_next[0]<0:
s_next[0]=0
if s_next[0]>3:
s_next[0]=3
if s_next[1]<0:
s_next[1]=0
if s_next[1]>3:
s_next[1]=3
r = -1 # 每走一步奖励固定是 -1
res = (r + gamma * V[tuple(s_next)]) # \pi(a|s) [r + \gamma V(s)]
# res_a = (r + gamma * V[tuple(s_next)]) # <------修改的地方
# res_a_ls.append(res_a) # <------修改的地方
# V_new[state] = max(res_a_ls) # <-------修改的地方
V_new[state] = res
delta = (abs(V_new-V)).max()
V = V_new.copy()
############################ b) 对每一个状态更新策略
for state in states:
res_ls = []
for i in range(4):
s_next = [actions[i][0] + state[0] , actions[i][1] + state[1]]
# 处理边界动作
if s_next[0]<0:
s_next[0]=0
if s_next[0]>3:
s_next[0]=3
if s_next[1]<0:
s_next[1]=0
if s_next[1]>3:
s_next[1]=3
res_a = (r + gamma * V[tuple(s_next)])
res_ls.append(res_a)
best_action_index = np.argmax(res_ls)
Policy[state] = best_action_index
if delta < 0.01:
plt.figure(figsize=(3,2))
sns.heatmap(V,annot=True,cmap='Blues_r')
plt.title('$V_\pi(s)$ @ step={} $\Delta$={:0.4f}'.format(step,delta),color='green')
plt.xlabel('x66ccff')
plt.ylabel('策略迭代')
plt.show()
print('break at delta={:.4f}, step={}'.format(delta, step))
break
elif step <= 3:
plt.figure(figsize=(3,2))
sns.heatmap(V,annot=True,cmap='Blues_r')
plt.title('$V_\pi(s)$ @ step={} $\Delta$={:0.4f}'.format(step,delta),color='black')
plt.ylabel('策略迭代')
plt.show()
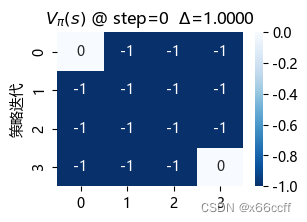
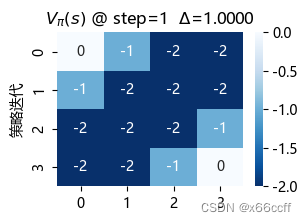
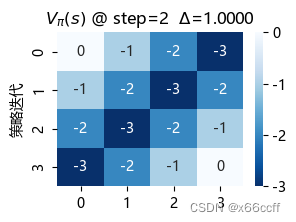
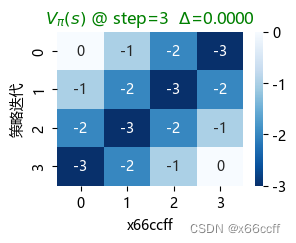
策略迭代也用了3步达到最优。这三种方法最终得到的 V π V_\pi Vπ?都不同,但是都是最优策略(看图容易验证,只要往浅色区域走,总能最快到达终止位置)
异步动态规划
上面的三种算法都是完全遍历完所有状态 s s s,再进行策略/价值的更新的(实际上也就是存储了新旧两个矩阵)。关键问题在于,遍历所有状态很多情况下是不可能的,比如围棋的合法状态空间大概为 1 0 170 10^{170} 10170,这是没法遍历的。
异步 DP 就是选择性地更新某些状态,从而增加了算法的灵活性。可以选择任意的状态 s s s进行更新,有的状态可能已经更新了很多次,但是有的状态甚至可以没有更新。
异步 DP 的优势在于
- 有可能减少计算量,并不需要完全遍历所有状态
- 有可能多考虑一些关键状态,从而提高效率
广义策略迭代(GPI)
广义策略迭代 (GPI) 指让策略评估和策略改进相互作用的一般思路
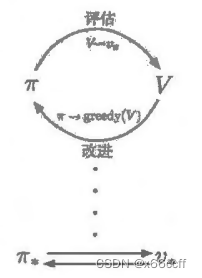
策略迭代包含两个过程:
- 用 π \pi π 更新 V V V ( a = arg ? max ? a π ( a ∣ s ) , a → s ′ → V ( s ′ ) a=\arg \max_a \pi(a|s), a \to s' \to V(s') a=argmaxa?π(a∣s),a→s′→V(s′))
- 用 V V V 更新 π \pi π(选择 max r + γ V ( s ′ ) r+\gamma V(s') r+γV(s′) 的动作)
这两个过程交替进行。
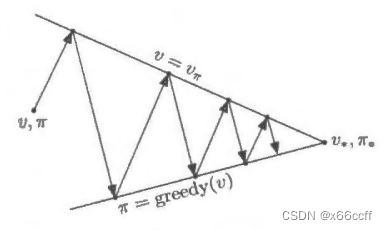
但是在广义策略迭代中,交替不是必须的,也不是必须要更新所有状态
GPI 允许在某些特殊情况下甚至有可能仅有一个状态在评估流程中得到更新(用 π \pi π 更新 V V V),然后马上就返回到改进流程(用 V V V 更新 π \pi π)。
几乎所有的强化学习方法都可以被描述为 GPI 。也就是说,几乎所有方法都包含明确定义的策略和价值函数,且如右图所示,策略总是基于特定的价值函数进行改进,价值函数也始终会向对应特定策略的真实价值函数收敛。GPI 中,我们也可以让每次走的步子小一点,部分地实现其中一个目标。无论是哪种情况,尽管没有直接优化总目标.但评估和改进这两个流程结合在一起,就可以最终达到最优的总目标
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!