【程序员的自我修养08】精华!!!动态库的由来及其实现原理

绪论
大家好,欢迎来到【程序员的自我修养】专栏。正如其专栏名,本专栏主要分享学习《程序员的自我修养——链接、装载与库》的知识点以及结合自己的工作经验以及思考。编译原理相关知识本身就比较有难度,我会尽自己最大的努力,争取深入浅出。若你希望与一群志同道合的朋友一起学习,也希望加入到我们的学习群中。文末有加入方式。
介绍
通过前文的讲解,我们大致了解将程序加载到内存的过程。即创建两个映射表:程序与虚拟内存空间映射表、虚拟内存空间与物理内存映射表。之后在程序运行过程中,通过不断触发页错误,持续将相应程序页加载到内存中,从而保证进程正常运行。似乎一切都已经完备了。的确,在早期的程序开发中,源文件经过编译生成可重定位文件(.o文件),再经过静态链接生成可执行的ELF文件,最终运行时,通过页加载和页错误的方式,保证进程的正常运行。已经能够满足当时程序的研发,大家开发和使用都非常方便。
但是随着IT行业的发展,原先静态链接方式的缺点也逐渐显露。比如:
由于业务越来越复杂,导致程序的体积也越来越大,在多进程的操作系统中,可能同时存在成百上千各应用同时运行。每个应用中都会使用到printf、scanf、strlen等基础函数,那么不同的程序中一定会包含它们的指令部分。这就导致这些程序在磁盘保存时,都有这些基础函数的副本。运行时,也会将这些副本加载到对应进程的虚拟空间内存中去。这就导致了浪费磁盘和内存。如下:
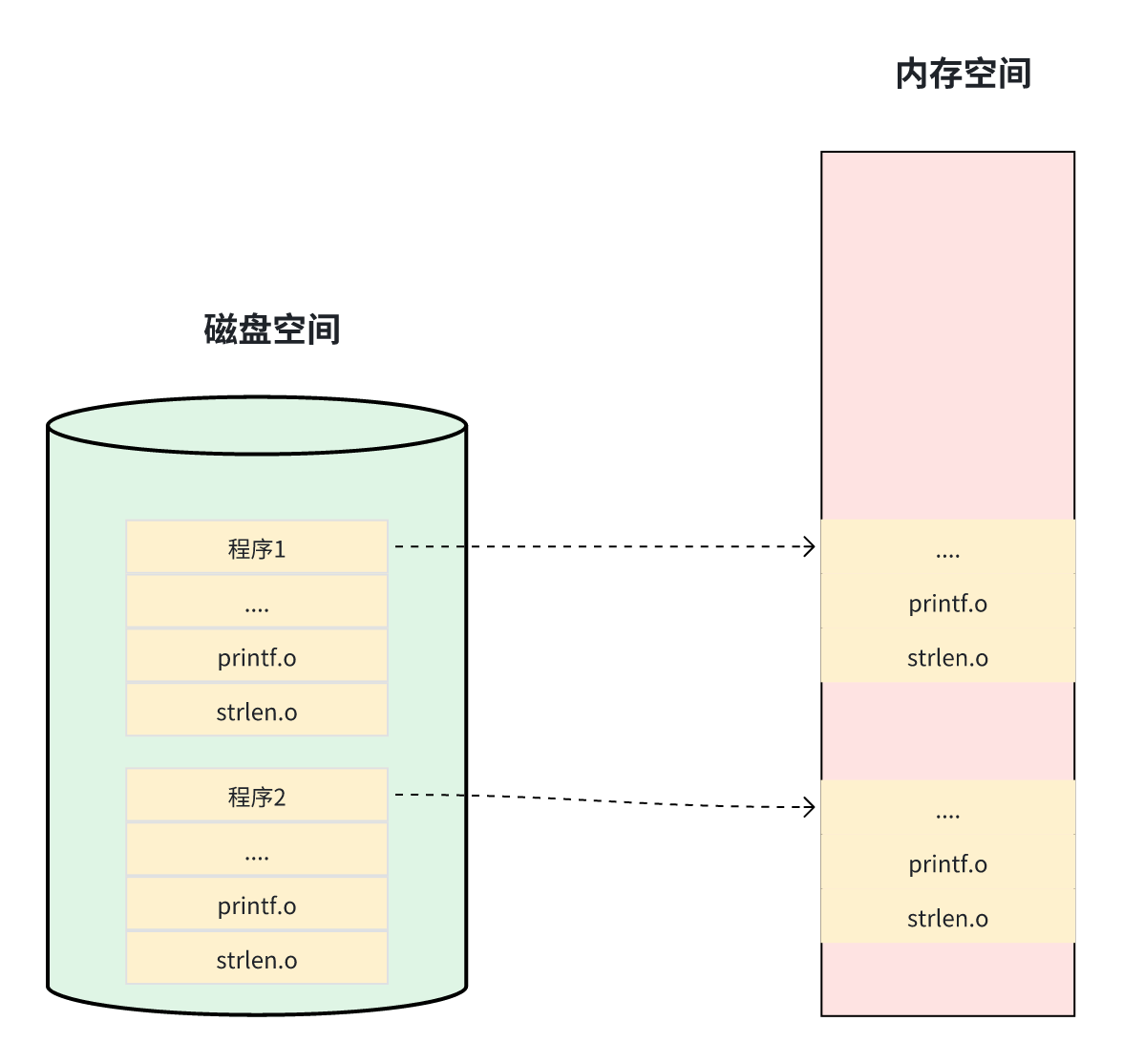
特别是Android开发行业,APP的更新周期非常快,导致原有的方式非常麻烦。比如上面的举例中,由于多个应用使用了printf接口模块,若发现其中有bug,就需要用新版本的printf.o与当前的其它文件进行重新编译、链接,再将编译好的程序进行在线更新。这就导致,错误的printf.o模块可能只有1KB大小,但是用户最终需要将整个程序(可能会有10MB)下载进行更新。这在以往流量收费的背景下,是非常不人性化的。
在上述两个核心问题的背景下,前人们就开始思考,如何解决这样的难题。最终的解决方案就是我们现在熟悉的动态库,其核心思想就是:把程序按照模块拆分成各个相对独立部分,在程序运行时才将它们链接在一起形成一个完成的程序,而不是像静态链接一样把所有的程序模块都链接成一个单独的可执行程序。如下:

接下来我们开始学习,如何实现这一功能。内容会比较多,我会尽自己最大努力做到深入浅出,若由任何意见、问题都欢迎在评论区指出。让我们一起坚持下去。
动态链接
我们看一个最简单的动态库使用案例。
//main.c
extern void func(int i);
int main()
{
func(5);
return 0;
}
//func.c
#include<stdio.h>
void func(int i)
{
printf("input i = %d\n",i);
return;
}
编译:
gcc -shared -fPIC -o libfunc.so fun.c
gcc main.c -o main -L./ -lfunc
运行:
yihua@ubuntu:~/test/dynamic-relocate$ export LD_LIBRARY_PATH=./
yihua@ubuntu:~/test/dynamic-relocate$ ./main
input i = 5
yihua@ubuntu:~/test/dynamic-relocate$
通过【程序员的自我修养05】符号修正的功臣——重定位表内容可知,若是静态链接,此时main进程中对func的引用是绝对地址。
但是main.o生成main程序时,如何知道func符号的类型呢?即该符号是静态符号还是动态符号呢?
若是静态符号,则在链接阶段将其加载到程序中,并将main函数中的引用进行重定位;若是动态符号,则等到运行时再重定位。
其实就是通过编译参数中-lfunc确定。因为libfunc.so的符号表中有func,当链接器发现该符号存在于.so中,则将其作为动态符号处理。这也说明了,为什么静态链接阶段,我们还需要动态库的原因。静态链接阶段,动态库的作用就是用于区别符号的类型。
完成第一步:链接阶段确定符号的类型。
当我们运行程序时,libfunc.so加载到内存中,其代码段的虚拟地址也就确定了。那么再修改所有引用到func符号的地址。就可以完成main->func的引用。如下:

完成第二步:运行时重定位。
到了这里,我们似乎好像已经实现了动态链接过程了。但是我们仔细观察上图的流程,我们会发现重定位阶段会对代码段进行重定位,修改函数地址,并且不同的库在不同的进程加载地址可能是不同的。这就导致上述流程中,动态库中的代码段,在多个进程中,无法实现共享,也就无法解决浪费内存的问题。
地址无关代码
为了解决装载时重定位,导致动态库指令部分无法在多个进程之间共享的问题。伟大的前辈们想到了一个思路:把动态库中的指令中那些需要被修改的部分分离出来,跟数据部分放在一起,这样指令部分可以保持不变,而数据部分可以在每个进程中拥有一个副本。而这个副本就是我们常见的GOT(Global Offset Table)表。
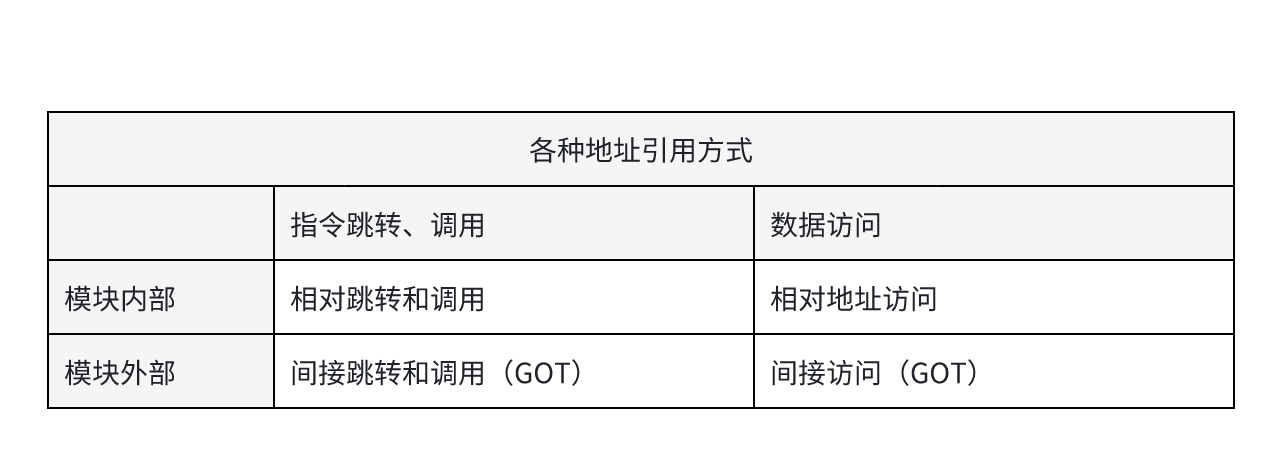
这样的思路似乎是可行的,我们一起看看如何去实现。按照共享模块对象中的引用分为是否在本模块,以及函数引用或数据访问。我们可以分为四类。
- 模块内部的函数调用
- 模块内部的数据访问
- 模块外部的函数调用
- 模块外部的数据访问
一、模块内的函数调用
由于是模块内部调用,且都属于代码段,因而它们之间的相对地址是固定的。比如下列代码段内容:
000000000000064a <main>:
64a: 55 push %rbp
64b: 48 89 e5 mov %rsp,%rbp
64e: bf 05 00 00 00 mov $0x5,%edi
653: e8 07 00 00 00 callq 65f <func>
658: b8 00 00 00 00 mov $0x0,%eax
65d: 5d pop %rbp
65e: c3 retq
000000000000065f <func>:
65f: 55 push %rbp
660: 48 89 e5 mov %rsp,%rbp
663: 48 83 ec 10 sub $0x10,%rsp
667: 89 7d fc mov %edi,-0x4(%rbp)
66a: 8b 45 fc mov -0x4(%rbp),%eax
66d: 89 c6 mov %eax,%esi
66f: 48 8d 3d 9e 00 00 00 lea 0x9e(%rip),%rdi # 714 <_IO_stdin_used+0x4>
676: b8 00 00 00 00 mov $0x0,%eax
67b: e8 a0 fe ff ff callq 520 <printf@plt>
680: 90 nop
681: c9 leaveq
682: c3 retq
683: 66 2e 0f 1f 84 00 00 nopw %cs:0x0(%rax,%rax,1)
68a: 00 00 00
68d: 0f 1f 00 nopl (%rax)
分析:main函数调用了func,其中main反汇编中对func的引用为e8 07 00 00 00,其中e8表示后面4字节是目标地址相对于下一条指令的偏移。下一指令地址为0x658,偏移0x00000007,即访问0x658+0x07=0x65f地址,正好为func的地址。
二、模块内的数据访问
我们知道,一个模块前面一般是若干页的代码,紧跟若干页的数据,这些页之间的相对位置是固定的。也就是说,可以按照第一类的方式进行相对寻址。又是如何实现的呢?我们以下面的示例举例。
//2.c
#include<stdio.h>
static int a;
int main()
{
a = 5;
return 0;
}
编译:gcc 2.c -o 2。
查看反汇编:objdump -d 2,其中main输出如下:
00000000000005fa <main>:
5fa: 55 push %rbp
5fb: 48 89 e5 mov %rsp,%rbp
5fe: c7 05 0c 0a 20 00 05 movl $0x5,0x200a0c(%rip) # 201014 <a>
605: 00 00 00
608: b8 00 00 00 00 mov $0x0,%eax
60d: 5d pop %rbp
60e: c3 retq
60f: 90 nop
查看符号表readelf -s 2,其中全局变量a的内容如下:
yihua@ubuntu:~/test/dynamic-relocate$ readelf -s 2
...
34: 0000000000201014 4 OBJECT LOCAL DEFAULT 23 a
...
我们可以发现,变量a在文件中的偏移是0x201014,而movl $0x5,0x200a0c(%rip)下一个指令地址为0x608,0x200a0c+0x608刚到为符号a的地址。
三、模块间的函数访问
模块间的函数访问比较麻烦,因为模块间的相对地址只有在加载时才能确认,因此一、二方式不再适合直接使用。ELF的做法是:借鉴场景二,在本模块的数据段中建立一个指向这些变量的指针数组,即GOT全局偏移表。代码段不再直接引用外部函数,而是直接指向本模块数据段中GOT数组中对应指针。当程序加载时,再重新对GOT表进行重定位。实现跳转访问。实现流程大致如下:
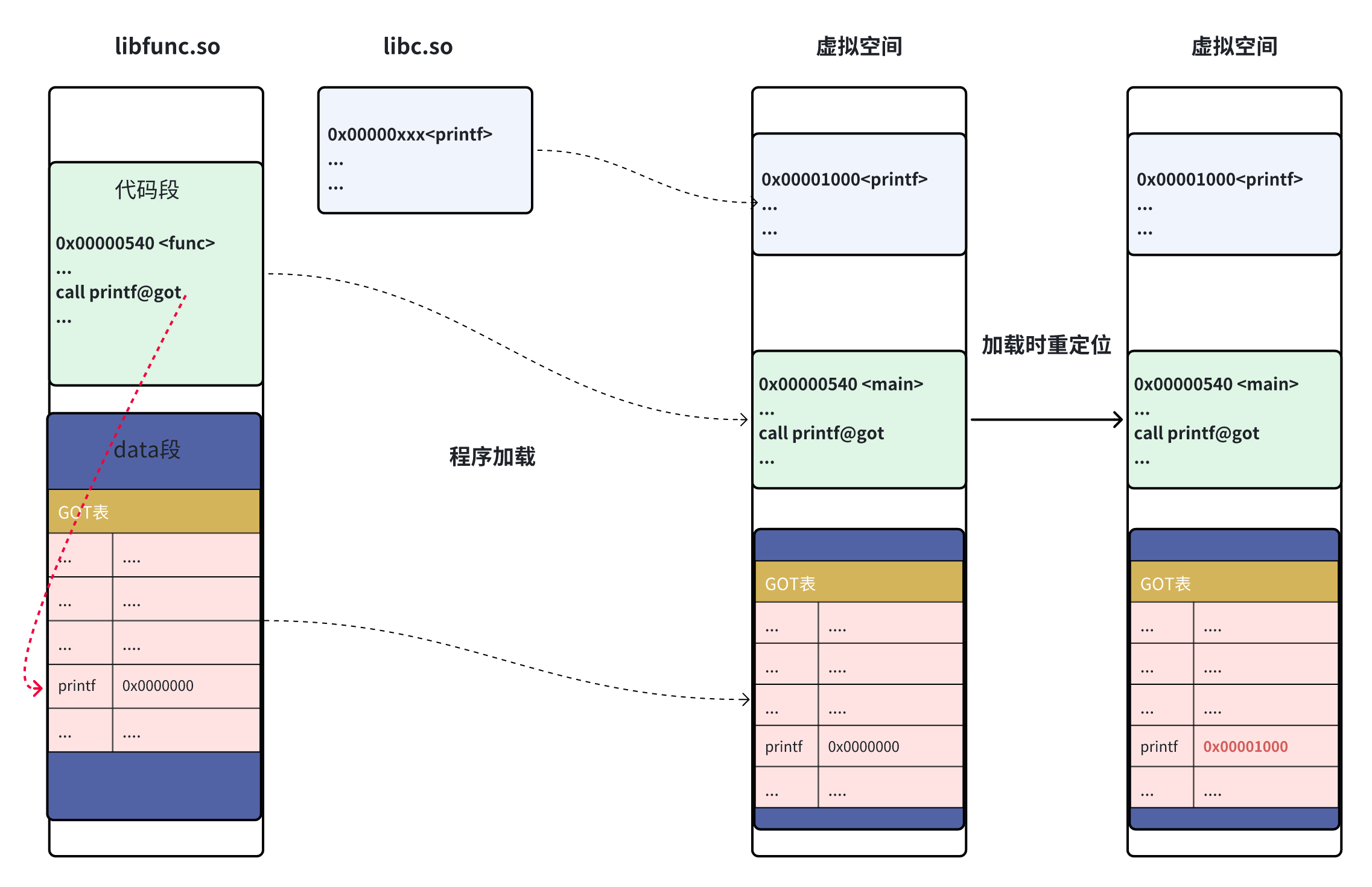
分析,如上所示,func函数中调用了printf函数,我们知道printf定义在libc.so中。为了保证libfunc.so动态库中代码段的通用性,将其对printf的引用,改为对数据段printf@got的引用。此时就和模块内部数据访问一样了。最终运行时,函数调用流程应该为func->printf@got->printf。
四、 模块间的数据访问
对于模块间的数据访问,其实实现逻辑与上面模块间的函数调用一致。在此不在赘述。
综上所述,动态库实现地址无光代码的方式如下:
至此,动态库为何能够实现节约磁盘、内存,方便版本迭代的原因我们已经明白。上述的流程实质上已经能够实现动态库的加载、运行流程。但与现在的动态库实现流程还有些差别,那就是延迟绑定(PLT)。
PLT 延迟绑定
通过上面所描述的,动态库通过GOT表,实现了地址无关代码**。动态库加载时**,需要对所有GOT表项进行重定位;动态库运行时,接口的实际调用变为了func->printf@got->printf。这就导致动态库相对于静态链接的启动速度(需要进行重定位)、运行速度(间接调用)略低。
经过长时间的发展,人们发现了一个现象:进程运行时,动态库GOT表中,并不是所有的外部接口数据都会被访问,如果在加载过程中就全部进行重定位,就是一种浪费,降低启动速度。于是采用了一种叫做延迟绑定的做法,基本思想就是:当函数第一次被用到时才进行绑定(符号查找、重定位)。那么ELF如何实现这一逻辑的呢?我们一起来看看。
首先,我们一起思考符号重定位需要哪些东西呢?
- 实现符号查找、绑定的接口。其真实名字就是
_dl_runtime_resolve - 该函数肯定需要入参,起码要知道要找哪个符号,修改哪个模块中的地址吧。
- 待查找的符号
- 待修改的地址
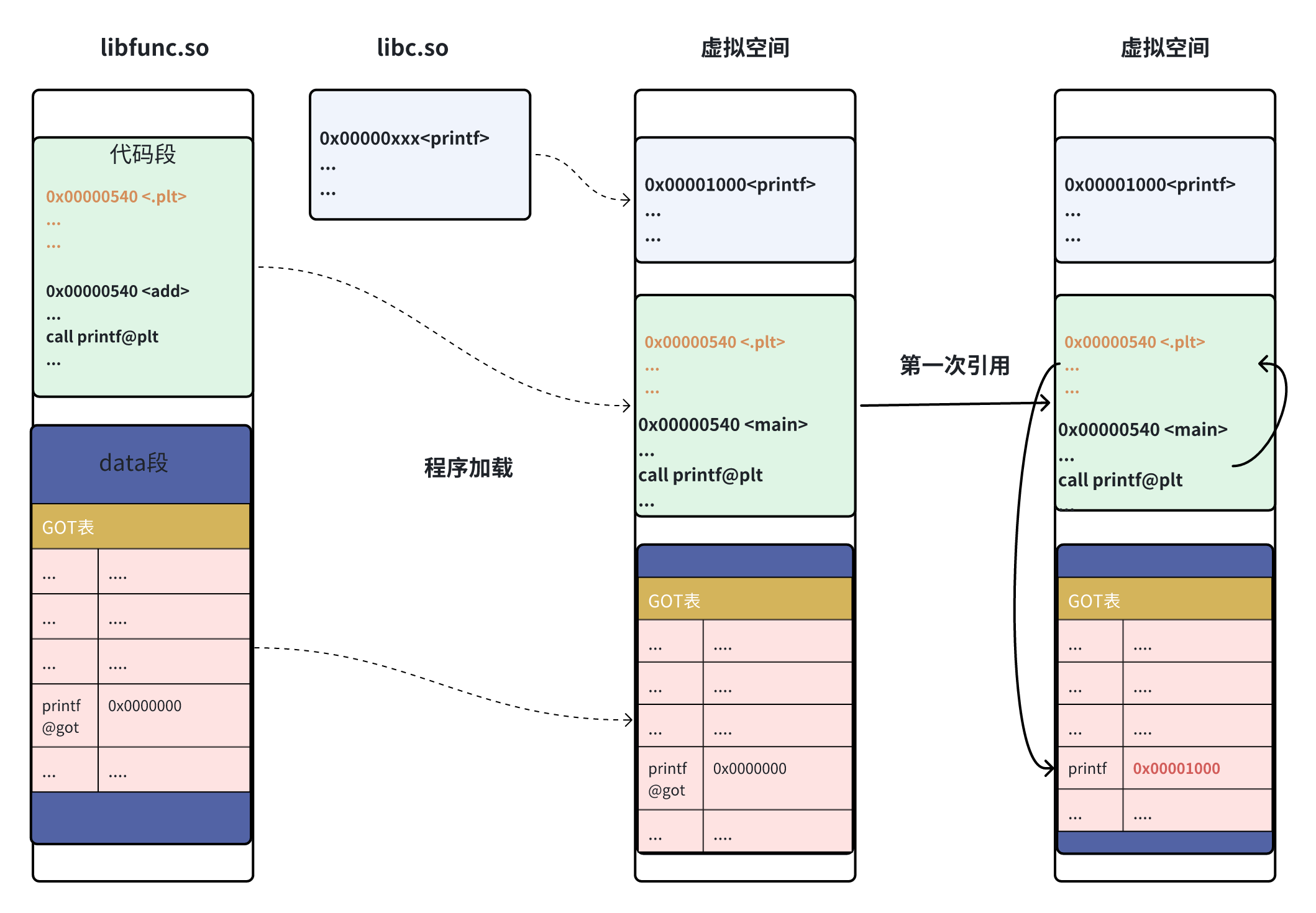
有了以上的期待,我们一起分析ELF是如何实现延迟绑定地。调用函数不再是通过GOT表直接调转,而是之间增加了一层PLT表结构。其大致实现逻辑为:
printf@plt
jmp *(printf@got)
push n
push moduleID
jump _dl_runtime_resolve
分析:
- 第一条指令直接跳转到GOT表中的对应表项。当然,第一次访问时,里面肯定是为空的,因为在加载时,并没有进行重定位。于是会继续往下运行。
- 第二条指令往栈中push该符号在符号表中的下标。
- 第三条指令往栈中push该动态库模块ID标识。
- 第四条指令调用
_dl_runtime_resolve接口,进行符号重定位。此时通过指令二,指令三,再结合本模块的符号表,重定位表。_dl_runtime_resolve是可以找到对应符号,以及修改printf@got表项内容。此时printf@got表项中即为实际printf地址。 - 之后再次访问
printf@plt时,执行第一条指令jmp *(printf@got),此时printf@got表项内容不为空,则直接跳转到printf@got表项,再间接访问printf。
示例分析:
我们尝试执行objdump -d libfunc.so分析其汇编逻辑,相关内容如下:
Disassembly of section .plt:
0000000000000500 <.plt>:
500: ff 35 02 0b 20 00 pushq 0x200b02(%rip) # 201008 <_GLOBAL_OFFSET_TABLE_+0x8>
506: ff 25 04 0b 20 00 jmpq *0x200b04(%rip) # 201010 <_GLOBAL_OFFSET_TABLE_+0x10>
50c: 0f 1f 40 00 nopl 0x0(%rax)
0000000000000510 <printf@plt>:
510: ff 25 02 0b 20 00 jmpq *0x200b02(%rip) # 201018 <printf@GLIBC_2.2.5>
516: 68 00 00 00 00 pushq $0x0
51b: e9 e0 ff ff ff jmpq 500 <.plt>
000000000000060a <add>:
60a: 55 push %rbp
60b: 48 89 e5 mov %rsp,%rbp
60e: 48 83 ec 10 sub $0x10,%rsp
612: 89 7d fc mov %edi,-0x4(%rbp)
615: 89 75 f8 mov %esi,-0x8(%rbp)
618: 8b 55 fc mov -0x4(%rbp),%edx
61b: 8b 45 f8 mov -0x8(%rbp),%eax
61e: 01 d0 add %edx,%eax
620: 89 c6 mov %eax,%esi
622: 48 8d 3d 20 00 00 00 lea 0x20(%rip),%rdi # 649 <_fini+0x9>
629: b8 00 00 00 00 mov $0x0,%eax
62e: e8 dd fe ff ff callq 510 <printf@plt>
633: 8b 55 fc mov -0x4(%rbp),%edx
636: 8b 45 f8 mov -0x8(%rbp),%eax
639: 01 d0 add %edx,%eax
63b: c9 leaveq
63c: c3 retq
分析:
add中不再是对print@got引用,而是对printf@plt引用。- 查看
printf@plt的汇编语句。- 第一条指令,跳转到GOT表中的
printf@got项。第一次访问时,由于没有重定位,因此为默认值(下一条指令地址,即516)。 - 第二条指令,往栈空间push 符号ID,这里填入的是0。
- 第三条指令,跳转到
.plt。
- 第一条指令,跳转到GOT表中的
- 而
.plt中有三条指令。- 第一条指令
pushq 0x200b02(%rip),往栈中push GOT表中的第二项内容,模块ID。 - 第二条指令
jmpq *0x200b04(%rip),跳转到GOT表中的第三项内容,_dl_runtime_resolve。进行符号的查找及其重定位。 - 第三条指令
nopl 0x0(%rax),空指令,没有实际含义。
- 第一条指令
- 此时
printf@got表项中已填充为真实虚拟地址,执行调用。
整体而言,与ELF原理类似。可参考下图。
总结
本章我们从静态链接出发,发现随着IT行业的发展,静态链接存在浪费磁盘,内存,版本更新麻烦等问题。于是引入了动态链接的概念。并且引出动态链接会面对的问题,以及实际上是如何解决这些问题的。
还有一些特殊场景还没有介绍,比如共享模块的全局变量问题、数据段如何做到地址无关性。以及运行时重定位过程中详细流程。后续文章我会进一步介绍这些概念,还请关注,不错过。

下篇文章我会进一步介绍这些概念,还请关注,不错过。
若我的内容对您有所帮助,还请关注我的公众号。不定期分享干活,剖析案例,也可以一起讨论分享。
我的宗旨:
踩完您工作中的所有坑并分享给您,让你的工作无bug,人生尽是坦途。


本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!