逻辑回归原理及代码
一、简介
逻辑回归是线性分类器(线性模型)—— 主要用于二分类问题
二、理论推导
1、问题描述和转化
一个二分类问题给的条件:
分类标签Y {0,1},特征自变量X{x1,x2,……,xn}
如何根据我们现在手头上有的特征X来判别它应该是属于哪个类别(0还是1)
问题的求解转化为:
我们如何找一个模型,即一个关于X的函数来得出分类结果(0或1)
2、初步思路:找一个线性模型来由X预测Y
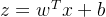
但是很明显,这样的函数图像是类似一条斜线,难以达到我们想要的(0或1)的取值
所以我们引入了一个特殊的函数:
3、Sigmoid函数(逻辑函数)
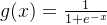
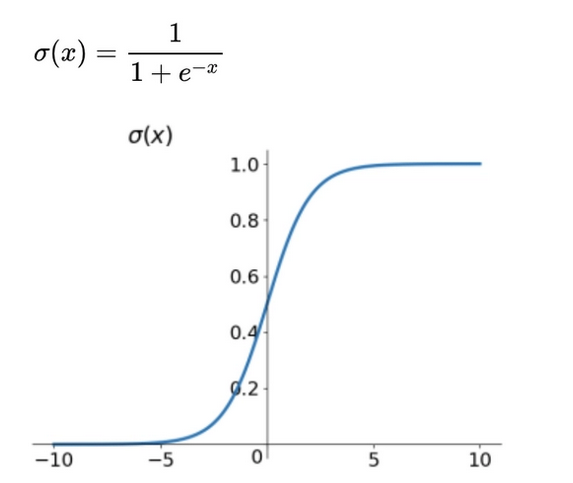
由图像可见,这样我们就能很好的分类(0或1)
4、刚刚的线性模型与Sigmoid函数合体
第一步: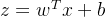
第二步:![[图片]](https://img-blog.csdnimg.cn/direct/ca800d140da3413fb7543abb21ff427b.png)
这样我们就把取值控制在了0或1上,初步达成了我们的目标。
5、条件概率
我们令 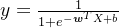 ,则可得
,则可得 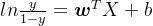
若我们将y视为样本x作为正例的概率,那么1-y则为样本x作为反例的概率,二者的比值为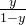
因此 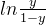 被称为对数几率。
被称为对数几率。
因此有: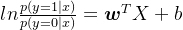
所以推出了:
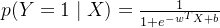
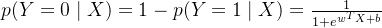
6、极大似然估计
思想:如果一个事件发生了,那么发生这个事件的概率就是最大的。对于样本i,其类别为y_{i}\epsilon (0,1)。对于样本i,可以把h(Xi)看成是一种概率。yi对应是1时,概率是h(Xi)(即Xi属于1的概率,即上面的p(Y=1|X));yi对应是0时,概率是1-h(Xi)(Xi属于0的概率,即上面的p(Y=0|X))。
即有: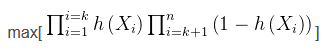
其中i是从0到k(k:属于类别1的个数),i从k+1到n(属于类别0的个数为n-k)。由于y是标签0或1,所以上面的式子也可以写成: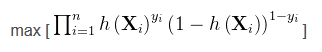
对它取对数,并且除以样本总数n(减少梯度爆炸出现的概率),再乘以负1(将求最大值问题转化为求最小值问题,即转化为求下式的最小值):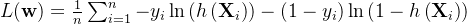
化简得:
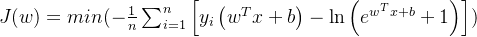
接下来的任务就是求解当上式最小时的w
7、求最小值时的w的两种方法
方法一:梯度下降法(一阶收敛)
通过 J(w) 对 w 的一阶导数来找下降方向,并以迭代的方式来更新参数
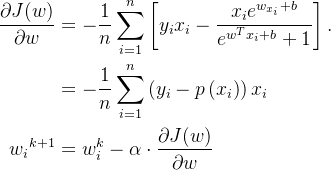
(这里的k代表的是第k次迭代;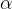 是我们设定的学习率;
是我们设定的学习率;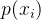 就是我们上面所说的
就是我们上面所说的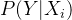 )
)
停止迭代的条件可以是:
(1)到达最大迭代次数
(2)到达规定的误差精度,即小于等于我们设定的阈值
方法二:牛顿法(二阶收敛)
思想:在现有极小值点的估计值的附近对 f(x) 做二阶泰勒展开,进而找到极小值点的下一个估计值。
牛顿法因为是二阶收敛,所以收敛速度很快,但是逆计算很复杂,代价比较大,计算量恐怖
梯度下降法:越接近最优值时,步长应该不断减小,否则会在最优值附近来回震荡,计算相对来说会简单一些。
三、正则化
正则化的意义:避免过拟合。
模型如果很复杂,变量值稍微变动一下,就会引起预测精度的问题。正则化可以避免过拟合的原因就是它降低了特征的权重,使得模型更简单。
主要思想:保留所有的特征变量,因为我们不太清楚要舍掉哪个特征变量,并且又想尽可能保留信息。所以我们只能是惩罚所有变量,让每个特征变量对结果的影响值变小,这样的话你拟合出来的模型才会更光滑更简单,从而减少过拟合的可能性。
1、L1正则化
即损失函数再加一项正则化系数乘上L1正则化表达式
( 决定惩罚力度,过高可能会欠拟合,过小无法解决过拟合)
作用:L1正则化有特征筛选的作用,对所有参数的惩罚力度都一样,可以让一部分权重变为零(降维),因此产生稀疏模型,能够去除某些特征(权重为0则等效于去除)
2、L2正则化
即损失函数再加一项正则化系数乘上L2正则化表达式
作用:使各个维度权重普遍变小,减少了权重的固定比例,使权重平滑
四、代码
import matplotlib.pyplot as plt
import numpy as np
# 进行归一化
def normalization(Data1, Data2, Data3):
# 要对全部的X坐标单独归一化,全部的Y坐标同理
Data_x = np.concatenate((Data1[:, 0], Data2[:, 0], Data3[:, 0]))
Data_y = np.concatenate((Data1[:, 1], Data2[:, 1], Data3[:, 1]))
# 参照Matlab的mapminmax函数进行归一化
Data_x = (Data_x - np.min(Data_x)) / (np.max(Data_x) - np.min(Data_x))
Data_y = (Data_y - np.min(Data_y)) / (np.max(Data_y) - np.min(Data_y))
Data_x = np.expand_dims(Data_x, 1)
Data_y = np.expand_dims(Data_y, 1)
Data1 = np.concatenate((Data_x[:5], Data_y[:5]), 1)
Data2 = np.concatenate((Data_x[5:10], Data_y[5:10]), 1)
Data3 = np.concatenate((Data_x[10:], Data_y[10:]), 1)
return Data1, Data2, Data3
if __name__ == "__main__":
# 定义数据集
class_1_o = np.array([[220, 90], [240, 95], [220, 95], [180, 95], [140, 90]], dtype=np.float)
class_2_o = np.array([[80, 85], [85, 80], [85, 85], [82, 80], [78, 80]], dtype=np.float)
Test_Data_o = np.array([[180, 90], [210, 90], [140, 90], [90, 80], [78, 80]], dtype=np.float)
Class_1, Class_2, Test_Data = normalization(class_1_o, class_2_o, Test_Data_o)
# 开始绘图
plt.figure()
plt.plot(Class_1[:, 0], Class_1[:, 1], 'r*', label='Class_1')
plt.plot(Class_2[:, 0], Class_2[:, 1], 'b*', label='Class_2')
plt.plot(Test_Data[:, 0], Test_Data[:, 1], 'gs', label='Test_Data')
plt.legend(loc='best')
# 定义训练参数
Train_Data = np.concatenate((Class_1, Class_2), axis=0)
Y = np.array([[1, 1, 1, 1, 1, 0, 0, 0, 0, 0]], dtype=np.float)
c = Train_Data.shape
# w = np.random.randn(3, 1)
w = np.array([[1], [1]], dtype=np.float) # 使用[1;1;1]方便与C++的运行结果比对(因为C++无法使用matlpotlib绘图)
b = np.array([1])
a = 0.01
epoch = 0
# 开始训练
while True:
epoch = epoch + 1
for i in range(0, c[0]): # 遍历训练集
fx = np.matmul(w.T, Train_Data[i, :].T) + b # matmul为矩阵乘法(线代知识)
gz = 1 / (1 + np.exp(-fx))
# 开始梯度下降
w[0] = w[0] - a * Train_Data[i, 0] * (gz[0] - Y[0, i])
w[1] = w[1] - a * Train_Data[i, 1] * (gz[0] - Y[0, i])
b = b - a * (gz[0] - Y[0, i])
# 判断何时停止训练
fx = np.matmul(w.T, Train_Data.T) + b
gz = 1 / (1 + np.exp(-fx))
Loss = (np.matmul(-Y, np.log(gz).T) - np.matmul((1-Y), np.log(1 - gz).T)) / c[0]
if Loss <= 0.3:
break
print(w)
# 绘制分类线
xlist = np.linspace(-0.5, 1.5, 100)
ylist = np.linspace(-0.5, 1.5, 100)
x, y = np.meshgrid(xlist, ylist) # 计算圆所在区域的网格
f = w[0] * x + w[1] * y + b < 0
plt.contourf(x, y, f, cmap="cool")
plt.show()
print('w的值为\n{}\n,b的值为\n{}'.format(w, b))
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!