69从零开始学Java69之Map集合是怎么回事?
作者:孙玉昌,昵称【一一哥】,另外【壹壹哥】也是我哦
CSDN博客专家、万粉博主、阿里云专家博主、掘金优质作者
前言
在上一篇文章中,壹哥给大家讲解了Java里的Set集合及其常用子类。现在我们已经掌握了Java里的两大集合,最后还有另一大集合等待着我们学习,这就是Map集合。与之前的集合不太一样,Map集合属于双列集合,该集合中的信息是key-value形式;而之前的LIst和Set都是单列集合,里面的元素没有key。
有些小伙伴可能会很好奇,我们已经学习了List和Set集合了,为什么还要再搞出来一个Map集合呢?Map集合与Collection集合又有什么不同呢?要想搞清楚以上问题,我们可以考虑这么一个需求。
假如我们利用List集合,来存储一份Student学生信息,要求你根据name来查找某个指定的学生分数,你要怎么实现?按照我们之前的经验,常用的方式就是遍历这个List,并挨个判断name是否相等,找到后就返回指定元素。
其实这种需求非常的常见,通过一个关键词来查询对应的值。如果我们使用List来实现该需求,效率会非常的低,因为平均需要扫描完集合的一半元素才能确定。而如果使用Map这种key-value键值对映射表的数据结构,就可以通过key快速地查找到value值。
------------------------------------------------前戏已做完,精彩即开始----------------------------------------------
全文大约【8500】字,不说废话,只讲可以让你学到技术、明白原理的纯干货!本文带有丰富的案例及配图视频,让你更好地理解和运用文中的技术概念,并可以给你带来具有足够启迪的思考......
配套开源项目资料
Github:
Gitee:
一. Map集合
1. 简介
Map集合是一种以键值对形式存储和操作数据的数据结构,建立了key-value之间的映射关系,常用于存储和处理复杂的数据。同时Map也是一种双列集合接口,它有多个实现类,包括HashMap、TreeMap、LinkedHashMap等,最常用的是HashMap类。其中,HashMap是按哈希算法来实现存取键对象的,这是我们开发时最常用的Map子类,而TreeMap类则可以对键对象进行排序。

Map集合中的每个元素,都包含了一个键(key)和一个值(value),key和value组成了键-值的映射表,我们称其为键值对。键用于唯一标识一个元素,值用于存储该元素的数据,一般情况下,这个key和value可以是任何引用类型的数据。其中,键key是无序、无下标、不重复的,最多只能有一个key为null。值value是无序、无下标、可重复的,可以有多个value为null。
并且这个key和value之间是单向的一对一关系,即通过指定的key,总能找到唯一的、确定的value。当我们想从Map中取出数据时,只要给出指定的key,就能取出对应的value。
与本节内容配套的视频链接如下:
External Player - 哔哩哔哩嵌入式外链播放器
2. 特点
根据上面我们对Map概念的讲解,壹哥把Map的主要特点给大家总结如下:
- Map和List不同,Map是一种双列集合;
- Map存储的是key-value的映射关系;
- Map不保证顺序。在遍历时,遍历的顺序不一定是put()时放入的key的顺序,也不一定是key的排序顺序。
3. 实现方式
在Java中,Map集合的实现方式主要有两种:基于哈希表和基于树结构。接下来壹哥给大家简单介绍一下基于这两种结构的Map集合。
3.1 基于哈希表的Map集合
基于哈希表的Map,其底层是基于哈希表作为数据结构的集合,主要的实现类是HashMap。在HashMap中,每个元素都包含一个键和一个值。当我们在添加元素时,HashMap会根据键的哈希值计算出对应的桶(Bucket),并将元素存储到该桶中。如果不同的键具有相同的哈希值,就会出现哈希冲突,此时HashMap会使用链表或红黑树等数据结构来解决冲突。基于哈希表的Map集合具有快速的添加、删除和查找元素的特点,但元素的顺序是不确定的。
关于HashMap的原理及冲突解决等内容,壹哥在这里不再细说,我的面试题精讲专栏中有详细讲解,欢迎大家关注,链接如下:
高薪程序员&面试题精讲系列42之HashMap中如果出现冲突怎么解决?如何计算key的hash值、如何进行数组索引定位?_一一哥Sun的博客-CSDN博客_key定位
3.2 基于树结构的Map集合
基于树结构的Map集合,其底层是基于红黑树作为数据结构的集合,主要的实现类是TreeMap。在TreeMap中,每个元素也都包含一个键和一个值。我们在添加元素时,TreeMap会根据键的比较结果,将元素存储到正确的位置上,使得元素可以按照键的升序或降序排列。基于树结构的Map集合,具有快速查找和遍历元素的特点,但添加和删除元素的速度较慢。
4. 常用方法
Map集合的使用和其他集合类似,主要包括添加、删除、获取、遍历元素等操作。当我们调用put(K key, V value)方法时,会把key和value进行映射并放入Map。当调用V get(K key)时,可以通过key获取到对应的value;如果key不存在,则返回null。如果我们只是想查询某个key是否存在,可以调用containsKey(K key)方法。另外我们也可以通过 Map提供的keySet()方法,获取所有key组成的集合,进而遍历Map中所有的key-value对。
下表中就是Map里的一些常用方法,大家可以记一下,这些方法在Map的各实现子类中也都存在。
| 方法 | 描述 |
| clear() | 删除Map中所有的键-值对 |
| isEmpty() | 判断Map是否为空 |
| size() | 计算Map中键/值对的数量 |
| put() | 将键/值对添加到Map中 |
| putAll() | 将所有的键/值对添加到Map中 |
| putIfAbsent() | 如果Map中不存在指定的键,则将指定的键/值对插入到Map中。 |
| remove() | 删除Map中指定键key的映射关系 |
| containsKey() | 检查Map中是否存在指定key对应的映射关系。 |
| containsValue() | 检查Map中是否存在指定的 value对应的映射关系。 |
| replace() | 替换Map中指定key对应的value。 |
| replaceAll() | 将Map中所有的映射关系替换成给定函数执行的结果。 |
| get() | 获取指定 key 对应对 value |
| getOrDefault() | 获取指定 key 对应对 value,如果找不到 key ,则返回设置的默认值 |
| forEach() | 对Map中的每个映射执行指定的操作。 |
| entrySet() | 返回Map中所有的键值对 |
| keySet() | 返回Map中所有的key键 |
| values() | 返回Map中所有的value值 |
| merge() | 添加键值对到Map中 |
| compute() | 对Map中指定key的值进行重新计算 |
| computeIfAbsent() | 对Map中指定key的值进行重新计算,如果该key不存在,则添加到Map中 |
| computeIfPresent() | 当key存在该Map时,对Map中指定key的值进行重新计算 |
与本节内容配套的视频链接如下:
External Player - 哔哩哔哩嵌入式外链播放器
5. 常用实现类
Java中有多个Map接口的实现类,接下来壹哥就给大家逐一简单介绍一下。
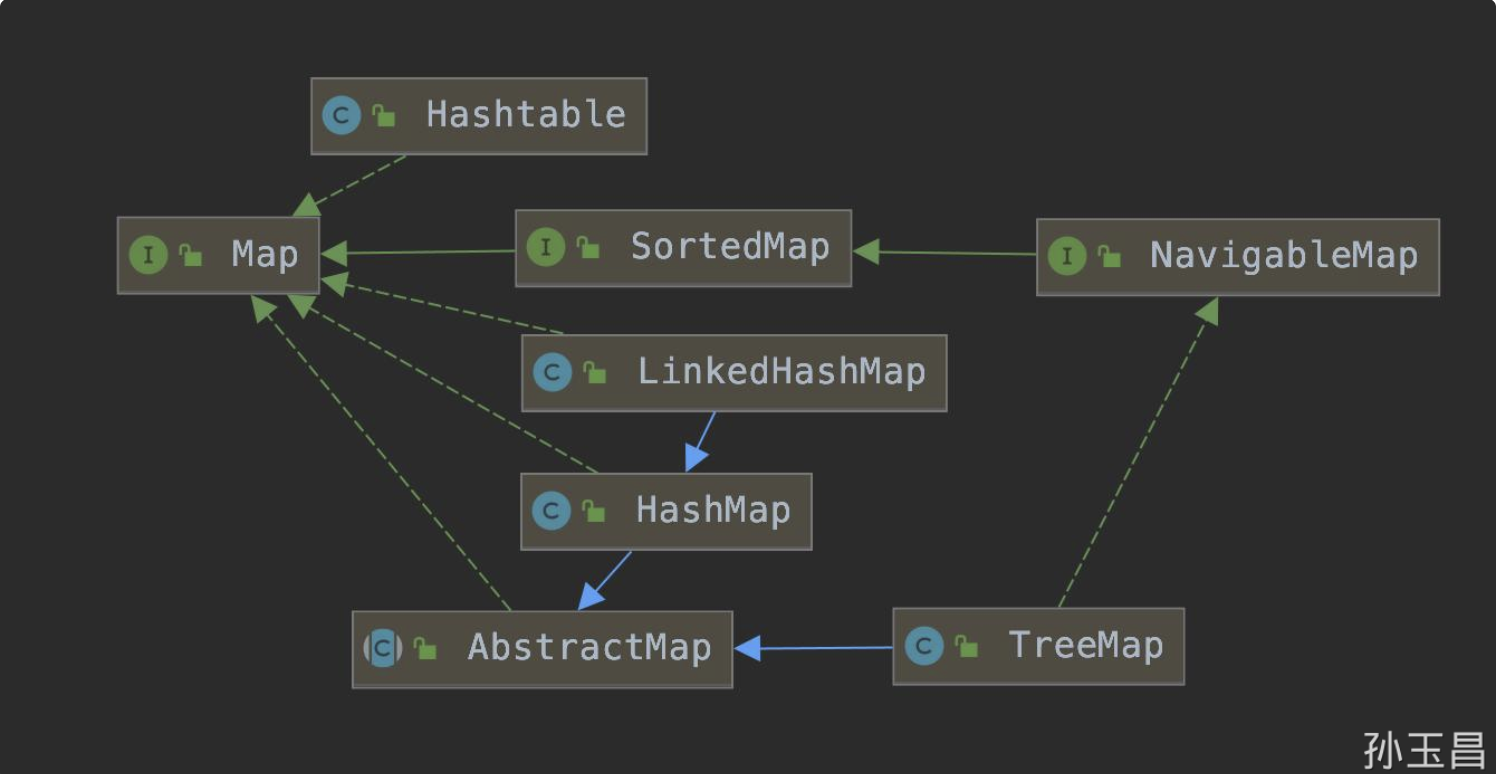
5.1 HashMap
HashMap是Java中最常用的Map集合实现类,它基于哈希表实现,具有快速查找键值对的优点。HashMap的存储方式是无序的,也就是说,遍历HashMap集合时,得到的键值对顺序是不确定的。下面是创建HashMap集合的代码示例:
Map<String, Integer> hashMap = new HashMap<>();5.2 TreeMap
TreeMap是Java中另一个常用的Map集合实现类,它基于红黑树实现,具有自动排序键值对的优点。TreeMap的存储方式是有序的,也就是说,遍历TreeMap集合时得到的键值对,是按照键的自然顺序或指定比较器的顺序排序的。下面是创建TreeMap集合的代码示例:
Map<String, Integer> treeMap = new TreeMap<>();5.3 LinkedHashMap
LinkedHashMap是Java中另一个Map集合实现类,它继承自HashMap,并保持了插入顺序。也就是说,遍历LinkedHashMap集合时,得到的键值对的顺序是按照插入顺序排序的。下面是创建LinkedHashMap集合的代码示例:
Map<String, Integer> linkedHashMap = new LinkedHashMap<>();5.4 Hashtable
Hashtable是Java中另一个Map集合实现类,它与HashMap非常相似,但Hashtable是线程安全的。Hashtable的存储方式是无序的,也就是说,遍历Hashtable集合时,得到的键值对的顺序是不确定的。下面是创建Hashtable集合的代码示例:
Map<String, Integer> hashtable = new Hashtable<>();需要注意的是,由于Hashtable是线程安全的,所以在多线程环境中使用Hashtable的性能可能会较低,现在一般是建议使用ConcurrentHashMap。
5.5 ConcurrentHashMap
ConcurrentHashMap是Java中的另一个Map集合实现类,它与Hashtable非常相似,但是ConcurrentHashMap是线程安全的,并且性能更高。ConcurrentHashMap的存储方式是无序的,也就是说,遍历ConcurrentHashMap集合时,得到的键值对的顺序是不确定的。下面是创建ConcurrentHashMap集合的代码示例:
Map<String, Integer> concurrentHashMap = new ConcurrentHashMap<>();需要注意的是,虽然ConcurrentHashMap是线程安全的,但仍然需要注意多线程环境下的并发问题。
二. HashMap集合
1. 简介
HashMap继承自AbstractMap类,实现了Map、Cloneable、java.io.Serializable接口,如下图所示:

HashMap是基于散列表实现的双列集合,它存储的是key-value键值对映射,每个key-value键值对也被称为一条Entry条目。其中的 key与 value,可以是任意的数据类型,其类型可以相同也可以不同。但一般情况下,key都是String类型,有时候也可以使用Integer类型;value可以是任何类型。并且在HashMap中,最多只能有一个记录的key为null,但可以有多个value的值为null。
HashMap中这些键值对(Entry)会分散存储在一个数组当中,这个数组就是HashMap的主体。默认情况下,HashMap这个数组中的每个元素的初始值都是null。但HashMap中最多只允许一条记录的key为null,允许多条记录的value为null。
另外HashMap是非线程安全的,即任一时刻如果有多个线程同时对HashMap进行写操作,有可能会导致数据的不一致。如果需要满足线程的安全性要求,可以用 Collections.synchronizedMap()方法使得HashMap具有线程安全的能力,或者使用ConcurrentHashMap来替代。
HashMap实现了Map接口,会根据key的hashCode值存储数据,具有较快的访问速度。另外HashMap是无序的,不会记录插入元素的顺序。我们一般是根据key的hashCode值来存取数据,大多数情况下都可以直接根据key来定位到它所对应的值,因而HashMap有较快的访问速度,但遍历顺序却不确定。
2. 特点
根据上面的描述,壹哥把HashMap的核心特点总结如下:
- 基于哈希表实现,具有快速查找键值对的优点;
- HashMap的存储方式是无序的;
- HashMap的key-value可以是任意类型,但key一般都是String类型,value类型任意;
- HashMap最多只能有一个记录的key为null,但可以有多个value为null。
3. 常用操作
HashMap的使用方法和其他Map集合类似,主要包括添加元素、删除元素、获取元素、遍历元素等操作。接下来壹哥会详细地给大家介绍HashMap集合的常用操作。
3.1 创建Map集合对象
创建HashMap对象的方式有多种,我们可以使用构造函数,代码如下:
// 使用构造函数创建HashMap对象
Map<String, Integer> map1 = new HashMap<>();3.2 添加元素
向HashMap集合添加元素的方式和List集合类似,也是使用put()方法,下面是向HashMap集合中添加元素的代码示例:
/**
* @author 一一哥Sun
*/
public class Demo14 {
public static void main(String[] args) {
//HashMap
Map<String, String> map = new HashMap<>();
map.put("name","一一哥");
//map.put("name","壹哥");
map.put("age", "30");
map.put("sex", "男");
System.out.println("map="+map);
}
}看到上面的代码,有些小伙伴可能会问,如果我们往同一个Map中存储两个相同的key,但分别放入不同的value,这会有什么问题吗?
其实我们在Map中,重复地放入key-value并不会有任何问题,但一个key只能关联一个value。因为当我们调用put(K key, V value)方法时,如果放入的key已经存在,put()方法会返回被删除的旧value,否则就会返回null。所以Map中不会有重复的key,因为放入相同的key时,就会把原有key对应的value给替换掉。
3.3 删除元素
从HashMap集合中删除元素的方式也和List集合类似,使用remove()方法。下面是从HashMap集合中删除元素的代码示例:
//从HashMap集合中移除元素
map.remove("age");3.4 获取元素
从HashMap集合中获取元素的方式和List集合不同,需要使用键来获取值。HashMap集合提供了两种方法来获取值,一种是使用get()方法,另一种是使用getOrDefault()方法。如果指定的键不存在,使用get()方法会返回null,而getOrDefault()方法则会返回指定的默认值。下面是从HashMap集合中获取元素的代码示例:
/**
* @author 一一哥Sun
*/
public class Demo15 {
public static void main(String[] args) {
//HashMap
Map<String, String> map = new HashMap<>();
map.put("name","一一哥");
map.put("age", "30");
map.put("sex", "男");
//根据key获取指定的元素
String name = map.get("name");
String age = map.get("age");
//根据key获取指定的元素,并设置默认值
String sex = map.getOrDefault("sex","男");
String height = map.getOrDefault("height","0");
System.out.println("[name]="+name+",[age]="+age+",[sex]="+sex+",[height]="+height);
}
}3.5 遍历元素
遍历HashMap集合的方式和List集合不同,需要使用迭代器或者foreach循环遍历键值对,下面是遍历HashMap集合的代码示例:
/**
* @author 一一哥Sun
*/
public class Demo16 {
public static void main(String[] args) {
//HashMap
Map<String, String> map = new HashMap<>();
map.put("name","一一哥");
map.put("age", "30");
map.put("sex", "男");
//遍历方式一:使用迭代器遍历HashMap
//获取集合中的entry条目集合
Set<Entry<String, String>> entrySet = map.entrySet();
//获取集合中携带的Iterator迭代器对象
Iterator<Map.Entry<String, String>> iterator = entrySet.iterator();
//通过循环进行迭代遍历
while (iterator.hasNext()) {
//获取每一个Entry条目对象
Map.Entry<String, String> entry = iterator.next();
//获取条目中的key
String key = entry.getKey();
//获取条目中的value
String value = entry.getValue();
System.out.println(key + " = " + value);
}
//遍历方式二:用foreach循环遍历HashMap
for (Map.Entry<String, String> entry : map.entrySet()) {
String key = entry.getKey();
String value = entry.getValue();
System.out.println(key + " = " + value);
}
}
}大家要注意,当我们使用Map时,任何依赖顺序的逻辑都是不可靠的。比如,我们存入"A","B","C" 3个key,遍历时,每个key会保证被遍历一次且仅遍历一次,但遍历的顺序完全没有保证,甚至对于不同的JDK版本,相同的代码遍历输出的顺序都可能是不同的!所以我们在 遍历Map时,要注意输出的key是无序的!
3.6 判断Map集合是否为空
判断HashMap集合是否为空可以使用isEmpty()方法,如果Map集合为空,则返回true,否则返回false。下面是判断HashMap集合是否为空的代码示例:
// 判断HashMap是否为空
boolean isEmpty = map.isEmpty(); 3.7 获取Map集合的大小
获取HashMap集合的大小可以使用size()方法,返回HashMap集合中键值对的数量,下面是获取HashMap集合大小的代码示例:
// 获取HashMap的大小
int size = map.size(); 3.8 判断Map集合是否包含指定的键或值
如果我们想判断HashMap集合是否包含指定的键或值,可以使用containsKey()和containsValue()方法。如果Map集合包含指定的键或值,则返回true,否则返回false。下面是判断HashMap集合是否包含指定键或值的代码示例:
// 判断HashMap是否包含指定键
boolean containsKey = map.containsKey("name");
// 判断HashMap是否包含指定值
boolean containsValue = map.containsValue("一一哥"); 3.9 替换Map集合中的键值对
如果我们想替换HashMap集合中的键值对,可以使用replace()方法将指定键的值替换成新的值。如果指定的键不存在,则不进行任何操作。下面是替换HashMap集合中的键值对的代码示例:
// 替换HashMap中的键值对
map.replace("name", "壹哥"); 3.10 合并两个Map集合
如果我们想合并两个HashMap集合,可以使用putAll()方法,将另一个HashMap集合中所有的键值对,添加到当前的HashMap集合中。下面是合并两个HashMap集合的代码示例:
/**
* @author 一一哥Sun
*/
public class Demo16 {
public static void main(String[] args) {
//HashMap
Map<String, String> map1 = new HashMap<>();
map1.put("name","一一哥");
map1.put("age", "30");
map1.put("sex", "男");
// 创建另一个TreeMap集合
Map<String, String> map2 = new HashMap<>();
map2.put("height", "180");
map2.put("salary", "5w");
//将map1中的键值对添加到map2中
map2.putAll(map1);
System.out.println("map2="+map2);
}
}3.11 获取Map集合中所有的键或值
如果我们想获取HashMap集合中所有的键或值,可以分别使用keySet()和values()方法。这两个方法会返回一个Set集合和一个Collection集合,它们包含了HashMap集合中所有的键或值。下面是获取HashMap集合中所有键或值的代码示例:
/**
* @author 一一哥Sun
*/
public class Demo18 {
public static void main(String[] args) {
//HashMap
Map<String, String> map = new HashMap<>();
map.put("name","一一哥");
map.put("age", "30");
map.put("sex", "男");
// 获取HashMap中所有的键
Set<String> keySet = map.keySet();
for(String key : keySet) {
System.out.println("key="+key);
}
// 获取HashMap中所有的值
Collection<String> values = map.values();
for(String value:values) {
System.out.println("value"+value);
}
}
}4. 原理概述(重点)
作为开发时最常用的Map集合,HashMap在我们面试时被问到的概率非常高,尤其是关于其原理、数据结构、冲突解决、并发、扩容等相关的内容,更是经常被问到。
高薪程序员&Java面试题精讲系列汇总_一一哥Sun的博客-CSDN博客
如果我们想要了解HashMap的底层原理,首先得知道HashMap的底层数据结构,而这个数据结构在不同的JDK版本中是不同的。我们可以把HashMap的底层数据结构分为两大版本,即JDK 7及其以前的版本 和 JDK 8及其以后的版本。大家注意,本文主要是结合JDK 8的源码,给大家讲解HashMap的底层原理。
- 在JDK 7及其以前版本的HashMap中,其底层的数据结构是 数组+链表;
- 而从JDK 8开始则采用 数组+链表+红黑树 的数据结构,其中的数组是Entry类型或者说是Node类型数组。
5. hash冲突解决机制
因为HashMap底层会使用Hash算法来处理数据的存取,当数据非常多时就有一定的概率出现hash冲突,其解决过程如下。
- 当我们往HashMap中存储数据时,首先会利用hash(key)方法 计算出key的hash值,再利用该 hash值 与 HashMap数组的长度-1 进行 与运算,从而得到该key在数组中对应的下标位置;
- 如果该位置上目前还没有存储数据,则直接将该key-value键值对数据存入到数组中的这个位置;
- 如果该位置目前已经有了数据,则把新的数据存入到一个链表中;
- 当链表的长度超过阈值(JDK 8中该值为8)时,会将链表转换为红黑树(转换为红黑树还需要满足其他的条件,链表长度达到阈值只是其中的一个条件)。
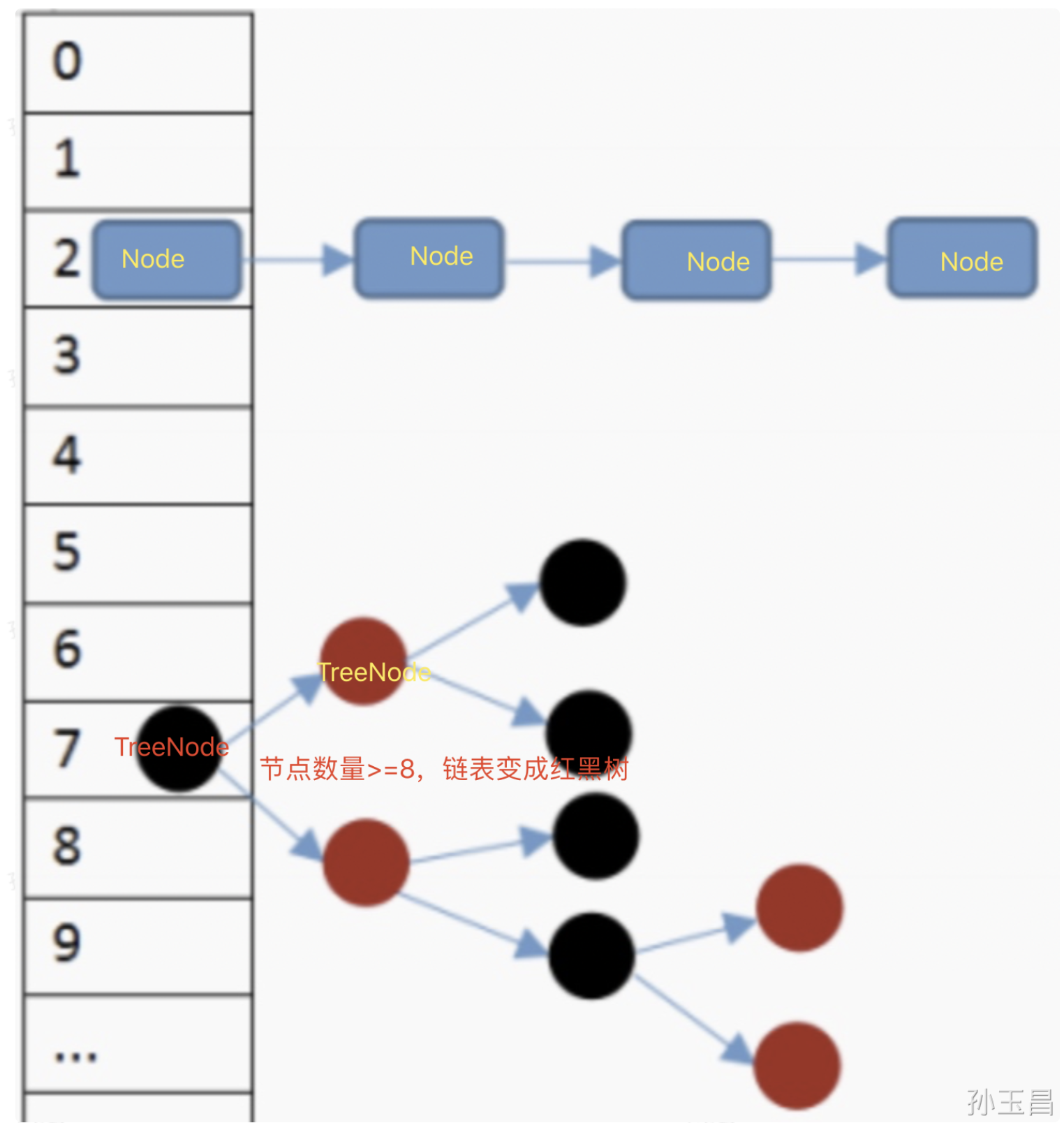
通过这样的机制,HashMap就解决了存值时可能产生的哈希冲突问题,并可以大大提高我们的查找效率。
当然由于HashMap极其重要,它的内容非常多,尤其是原理性的内容更多。但由于篇幅限制,壹哥不会在本文中过多地讲解HashMap原理等的内容,这些内容在壹哥的面试题精讲专栏中有过详细讲解,欢迎大家订阅关注哦。
高薪程序员&Java面试题精讲系列汇总_一一哥Sun的博客-CSDN博客
高薪程序员&面试题精讲系列39之说说HashMap的特点及其底层数据结构_一一哥Sun的博客-CSDN博客
External Player - 哔哩哔哩嵌入式外链播放器
三. Hashtable集合
1. 简介
Hashtable也是Java中的一个Map集合,它与HashMap非常相似,但Hashtable是线程安全的,而HashMap不是线程安全的。Hashtable也可以存储键值对,并可以通过键快速查找到对应的值,Hashtable的键和值也都可以是任何类型的对象。
因为Hashtable是线程安全的,因此适用于多线程环境。在多线程环境中,如果需要对Hashtable进行多个操作,需要使用synchronized关键字来保证线程安全。但需要我们注意的是,在多线程环境中使用Hashtable可能会影响性能,所以如果不需要保证线程安全,请尽量使用HashMap。
Hashtable集合的底层结构主要是数组+链表,数组是Entry数组,链表也是用Entry来实现的。所以Hashtable的底层核心,其实也是基于哈希表,它使用哈希函数将键映射到哈希表中的一个位置,从而实现快速查找。另外Hashtable的存储方式是无序的,也就是说,遍历Hashtable集合得到的键值对的顺序是不确定的。
2. 常用方法
Hashtable与HashMap类似,它的常用方法也与HashMap一样:
- put(K key, V value):将指定的键值对存储到Hashtable中。
- get(Object key):返回指定键所对应的值,如果不存在该键则返回null。
- remove(Object key):从Hashtable中移除指定键所对应的键值对。
- containsKey(Object key):判断Hashtable中是否包含指定的键。
- containsValue(Object value):判断Hashtable中是否包含指定的值。
- size():返回Hashtable中键值对的数量。
- clear():移除Hashtable中的所有键值对。
3. 基本使用
下面是一个简单的Hashtable集合示例,演示了如何创建Hashtable集合、存储键值对、获取值、遍历集合等操作。
import java.util.Hashtable;
import java.util.Map;
/**
* @author 一一哥Sun
*/
public class Demo19 {
public static void main(String[] args) {
// 创建Hashtable集合
Map<String, Integer> hashtable = new Hashtable<>();
// 存储键值对
hashtable.put("apple", 10);
hashtable.put("banana", 20);
hashtable.put("orange", 30);
// 获取值
int value1 = hashtable.get("apple");
int value2 = hashtable.get("banana");
int value3 = hashtable.get("orange");
System.out.println("apple: " + value1);
System.out.println("banana: " + value2);
System.out.println("orange: " + value3);
// 移除键值对
hashtable.remove("orange");
// 遍历集合
for (Map.Entry<String, Integer> entry : hashtable.entrySet()) {
String key = entry.getKey();
int value = entry.getValue();
System.out.println(key + ": " + value);
}
// 清空集合
hashtable.clear();
}
}其他方法的使用与HashMap基本一致,壹哥就不再一一细说了。
4. 配套资料
以下是Hashtable的面试题精讲文章链接:
高薪程序员&面试题精讲系列36之说说HashMap与HashTable的区别有哪些?_一一哥Sun的博客-CSDN博客
四. ConcurrentHashMap集合
1. 简介
由于在多线程环境下,常规的HashMap可能会在数组扩容及重哈希时出现 死循环、脏读 等线程安全问题,虽然有HashTable、Collections.synchronizedMap()可以取代HashMap进行并发操作,但因它们都是利用一个 全局的synchronized锁 来同步不同线程之间的并发访问,因此性能较差。
所以Java就从JDK 1.5版本开始,在J.U.C(java.util.concurrent并发包)中引入了一个高性能的并发操作集合---ConcurrentHashMap(可以简称为CHM)。该集合是一种线程安全的哈希表实现,相比Hashtable和SynchronizedMap,在多线程场景下具有更好的性能和可伸缩性。
并且ConcurrentHashMap集合在读数据时不需要加锁,写数据时会加锁,但锁的粒度较小,不会对整个集合加锁。而其内部又大量的利用了 volatile,final,CAS等lock-free(无锁并发)技术,减少了锁竞争对于性能的影响,具有更好的写并发能力,但降低了对读一致性的要求。因此既保证了并发操作的安全性,又确保了读、写操作的高性能,可以说它的并发设计与实现都非常的精巧。
另外ConurrentHashMap中的key与value都不能为null,否则会产生空指针异常!
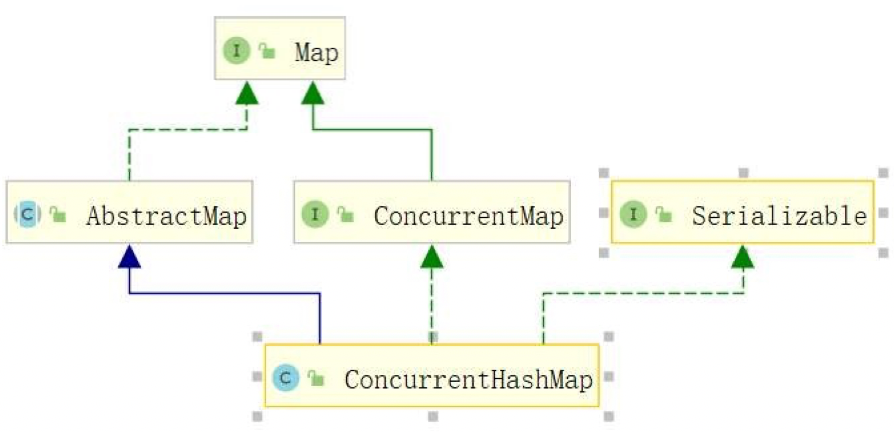
2. ConcurrentHashMap类关系
ConcurrentHashMap与HashMap具有相同的父类AbstractMap,他俩可以说是“亲兄弟”,所以ConcurrentHashMap在一般的特性和使用上与HashMap基本是一致的,甚至很多底层原理也是相似的。
但两者所在的包是不同的,ConcurrentHashMap是在java.util.concurrent包中,HashMap是在java.util包中,我们可以参考下图:
以上所述的ConcurrentHashMap概念及特征,是不区分版本的,但实际上不同版本的ConcurrentHashMap内部实现差异很大,所以面试时经常会被问到不同版本之间的差异、各自特征。接下来 壹哥 会针对JDK 7 与 JDK 8 这两个经典版本分别进行阐述。
3. 实现原理
3.1 并发控制机制
在JDK 7中,ConcurrentHashMap的核心机制是分段锁(Segment),每个Segment内部维护了一个哈希表,且这个哈希表是线程安全的。而ConcurrentHashMap中的每个操作,都是先对所在的Segment进行加锁,然后再执行具体的操作。
当多个线程对不同的Segment进行操作时,它们之间是并发的。当多个线程对同一个Segment进行操作时,它们会竞争锁,但不会影响到其他Segment的操作。这种机制有效地降低了锁的粒度,提高了并发访问效率。
ConcurrentHashMap的另一个优点是支持可伸缩性。当需要增加ConcurrentHashMap的容量时,我们只需要增加Segment的数量即可,这种机制使得ConcurrentHashMap在高并发场景下具有良好的可伸缩性。
3.2 JDK 7版本的ConcurrentHashMap
在JDK 7版本中,ConcurrentHashMap和HashMap的设计思路其实是差不多的,但为了支持并发操作,做了一定的改进。比如ConcurrentHashMap中的数据是一段一段存放的,我们把这些分段称之为Segment分段,在每个Segment分段中又有 数组+链表 的数据结构。默认情况下ConcurrentHashMap把主干分成了 16个Segment分段,并对每一段都单独加锁,我们把这种设计策略称之为 "分段锁", ConcurrentHashMap就是利用这种分段锁机制进行并发控制的。JDK 7中ConcurrentHashMap的基本数据结构如下图所示:
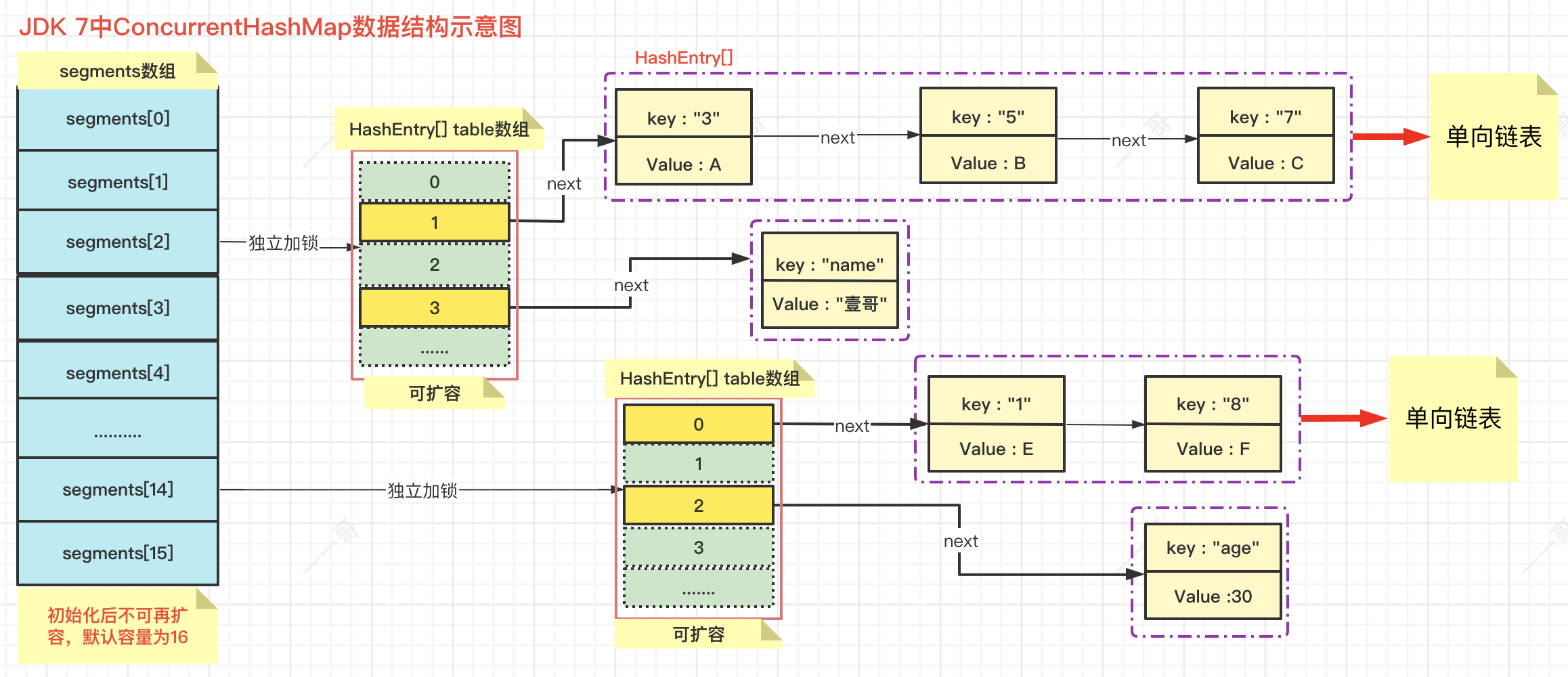
在理想状态下,ConcurrentHashMap可以 同时支持16个线程 执行并发写操作,以及任意数量的线程进行并发读操作。在写操作时,通过分段锁技术,只对所操作的段加锁而不会影响其它分段,且在读操作时(几乎)不需要加锁。
3.3 JDK 8版本的ConcurrentHashMap
在JDK 8中,ConcurrentHashMap相对于JDK 7版本做了很大的改动,从实现的代码量上就可以看出来,JDK 7中ConcurrentHashMap不到2000行代码,而JDK 8中则有6000多行代码。
JDK 8中放弃了臃肿的Segment设计,取而代之采用了 Node数组 + 链表 + 红黑树 + CAS + Synchronized 技术来保证并发安全,实现并发控制操作。但是在ConcurrentHashMap的实现中保留了 Segment 的定义,这是为了 保证序列化时的兼容性,但并没有任何结构上的用处。在JDK 8中用synchronized替换ReentrantLock的原因大致如下:
- 减少内存开销: 如果使用ReentrantLock,就需要节点继承AQS来获得同步支持,这增加了内存开销,而JDK 8中只有头节点需要进行同步。
- 内部优化: synchronized是JVM直接支持的,JVM能够在运行时作出相应的优化措施,比如 锁粗化、锁消除、锁自旋等。
4. 基本使用
ConcurrentHashMap支持与HashMap相同的常用操作,如put、get、remove等。下面介绍一些常用操作。
4.1 插入元素
ConcurrentHashMap的put方法用于向集合中插入一个键值对,如果键已经存在,则会更新对应的值。下面是向ConcurrentHashMap中插入元素的示例:
import java.util.concurrent.ConcurrentHashMap;
public class Demo19 {
public static void main(String[] args) {
// 创建ConcurrentHashMap集合
ConcurrentHashMap<String, Integer> map = new ConcurrentHashMap<>();
// 插入元素
map.put("apple", 10);
map.put("banana", 20);
map.put("orange", 30);
// 输出元素
System.out.println(map);
}
}
根据上面代码的执行结果可知,ConcurrentHashMap中的键值对是无序的。
4.2 获取元素
ConcurrentHashMap的get方法用于获取指定键对应的值,如果键不存在,则返回null。下面是一个从ConcurrentHashMap中获取元素的示例:
import java.util.concurrent.ConcurrentHashMap;
public class Demo20 {
public static void main(String[] args) {
// 创建ConcurrentHashMap集合
ConcurrentHashMap<String, Integer> map = new ConcurrentHashMap<>();
// 插入元素
map.put("apple", 10);
map.put("banana", 20);
map.put("orange", 30);
// 获取元素
Integer value = map.get("apple");
System.out.println(value);
}
}
4.3 删除元素
ConcurrentHashMap的remove方法用于从集合中删除指定键的元素,下面是一个从ConcurrentHashMap中删除元素的示例:
import java.util.concurrent.ConcurrentHashMap;
public class Demo21 {
public static void main(String[] args) {
// 创建ConcurrentHashMap集合
ConcurrentHashMap<String, Integer> map = new ConcurrentHashMap<>();
// 插入元素
map.put("apple", 10);
map.put("banana", 20);
map.put("orange", 30);
// 删除元素
map.remove("apple");
// 输出元素
System.out.println(map);
}
}
5. 配套资料
因为ConcurrentHashMap的内容非常多,且该集合也是现在多线程并发处理时很常用的一个集合,所以这也是面试的重点内容。以下是壹哥关于ConcurrentHashMap的面试题精讲文章链接:
高薪程序员&面试题精讲系列45之你熟悉ConcurrentHashMap吗?_一一哥Sun的博客-CSDN博客
高薪程序员&面试题精讲系列46之说说JDK7中ConcurrentHashMap的底层原理,有哪些数据结构_一一哥Sun的博客-CSDN博客
--------------------------------------------------???????正片已结束,来根事后烟----------------------------------------------
五. 结语
至此,我们就把Map及其子类学习完了,现在你知道Map有什么特性及其用法了吗?接下来我们简单总结一下今天的重点吧:
- Map是一种映射表,可以通过key快速查找value;
- 可以通过for each遍历keySet(),也可以通过for each遍历entrySet(),直接获取key-value;
- 最常用的Map是HashMap;
- Hashtable是线程安全的集合,底层结构主要是数组+链表;
- ConcurrentHashMap可以良好地进行并发处理,是一种线程安全且高效的集合。
另外如果你独自学习觉得有很多困难,可以加入壹哥的学习互助群,大家一起交流学习。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!