python爬虫效率提升——多进程
1.背景
之前的爬虫一般都是一个URL爬取完成再进行下一个,有多个URL的时候是用for循环实现对多个URL的爬取。几十个上百个URL勉强还能凑活,但是如果是上万个URL呢,还这么爬的话效率是不是太低了,浪费时间就是浪费生命。提升效率,人人有责。
提升爬虫效率的方法主要有多线程、多进程等方式。
用例子理解上面两个概念:1.计算机的核心是CPU,它承担了所有的计算任务。它就像一座工厂,时刻在运行;2.假定工厂的电力有限,一次只能供给一个车间使用。也就是说,一个车间开工的时候,其他车间都必须停工。背后的含义就是,单个CPU一次只能运行一个任务。3.进程就好比工厂的车间,它代表CPU所能处理的单个任务。任一时刻,CPU总是运行一个进程,其他进程处于非运行状态。4.一个车间里,可以有很多工人。他们协同完成一个任务。5.线程就好比车间里的工人。一个进程可以包括多个线程。参考博客:进程与线程的一个简单解释 - 阮一峰的网络日志
本案例只介绍多进程方式,以海投网陕西省各高校的宣讲会信息爬取为例。
2.准备知识
2.1 CSV文件数据存储
一般见得最多的数据存储方式应该就是微软的Excel,不过它是微软自家的数据存储方式,里面有一些专属的字体、或者加粗等这样那样的格式,不是通用的格式,还有一种比较简洁的表格数据存储格式就是CSV。
Python导入CSV库可以创建CSV文件并写入数据。下面是一个简单的写入数据的套路:
import csv
fp = open ('C://Users/Lenovo/Desktop/test.csv ','w')#创建CSV文件
writer = csv.writer(fp)
writer.writerow (('id','name'))#第一行写入表头
writer.writerow (('1','张三'))
writer.writerow (('2','李四'))
writer.writerow (('3','王二'))运行完找到保存到指定路径的CSV文件,用Excel打开如下:
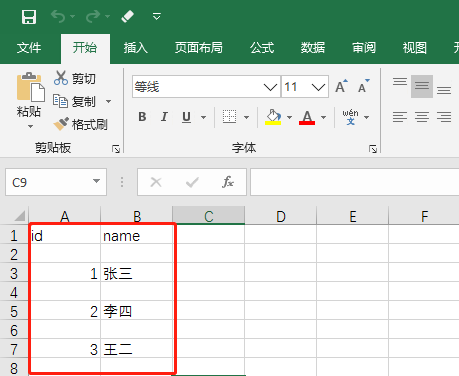
可以看到每一行的数据都已经成功写入,不过有个问题就是每一行之间都有个空行,这是因为newline默认值为'\n'也就是一个换行符,所以可以将其修改为:newline=‘’就能解决,如下:
import csv
fp = open ('C://Users/Lenovo/Desktop/test.csv ','w',newline = '')#创建CSV文件
writer = csv.writer(fp)
writer.writerow (('id','name'))#第一行写入表头
writer.writerow (('1','张三'))
writer.writerow (('2','李四'))
writer.writerow (('3','王二'))可以看到数据正常了:
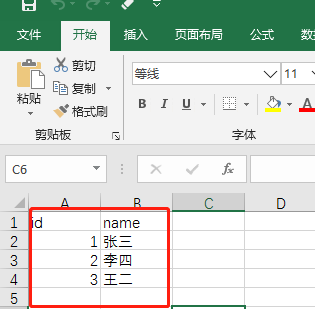
2.2 if __name__ = '__main__',python 主程序入口
参考博客:https://blog.csdn.net/liukai2918/article/details/79465671,或者自行百度其作用。
2.3 多进程
本案例介绍multiprocessing 库实现多进程爬虫,使用方法的代码如下:
from multiprocessing import Pool
pool= Pool(processes=4) #创建进程池
pool.map(func,iterable[,chunksize])代码说明:
- 第1 行用于导入multiprocessing 库的Pool 模块。
- 第2 行用于创建进程池, processes 参数为设置进程的个数。
- 第3 行利用map ()函数运行进程, func 参数为需运行的函数,在爬虫实战中,为爬虫函数。iterable 为迭代参数,在爬虫实战中,可为多个URL 列表进行迭代。
processes参数设置注意:当进程数量大于CPU的内核数量时,等待运行的进程会等到其他进程运行完毕让出内核为止。因此,如果CPU是单核,就无法进行多进程并行。在使用多进程爬虫之前,我们需要先了解计算机CPU的核心数量。这里用到了multiprocessing:
from multiprocessing import cpu_count
print(cpu_count())运行结果为4,说明我使用的电脑CPU核心数为4。
3.案例应用
本案例以海投网陕西各高校的宣讲会信息爬取为例。

开始之前的套路,先对网页进行分析:

通过对网页分析,发现海投网没有采用异步加载技术,所以用最原始的那个爬虫套路就可以。爬取网页中的公司标题,宣讲地点,时间还有该条宣讲会点击量4个字段,对单进程,还有双进程,四进程的爬取效率做一个比较,爬取20页的内容进行测试,代码如下:
import requests
import csv
import time
from bs4 import BeautifulSoup
from fake_useragent import UserAgent#可以随机变换请求头信息,更好的伪装成浏览器访问
from multiprocessing import Pool
fp =open('C://Users/Lenovo/Desktop/xuanjianghui.csv','w',newline='',encoding='utf-8')#newline默认是换行符,如果不设置,每行之间就会有空行
writer = csv.writer(fp)
writer.writerow(('company','address','time','click'))#写入表头信息
ua = UserAgent()
headers = { 'User-Agent':ua.random}#随机的user-agent信息
def get_xuanjiang(url):#定义抓取信息的函数
response = requests.get(url,headers = headers)
html = response.text
soup = BeautifulSoup(html,'lxml')
time.sleep(1)
companys = soup.find_all('div',class_="text-success company pull-left")
addresss = soup.find_all('a',attrs={'href':True,'target':True,'title':True})#True 可以匹配任何值,如果标签中的属性是变化值就可以这样匹配
dates =soup.find_all('span',class_='hold-ymd')
clicks = soup.find_all('td',class_='cxxt-clicks')
for co,ad,da,cl in zip(companys,addresss,dates,clicks):
company = co.get_text()
address = ad.find('span').contents#标签的 .contents 属性可以将标签的子节点以列表的方式输出
if len(address)==0:#判断输出的列表是否为空
address='null'
else:
address=address[0]#如果不为空,列表中的第一个元素就是地址信息
date = da.get_text()
click = cl.get_text()
writer.writerow((company,address,date,click))#写入具体数据
if __name__ == '__main__':
urls = ['https://xjh.haitou.cc/xa/after/page-{}'.format(i) for i in range(1,21)]
a1 = time.time() # 记录单进程开始时间
for url in urls:
get_xuanjiang(url)
b1 = time.time()#记录单进程结束时间
print('串行执行',b1-a1)
a2 = time.time()#记录两个进程的开始时间
pool = Pool(processes=2)
pool.map(get_xuanjiang,urls)
b2 = time.time()#记录两个进程的结束时间
print('2个进程',b2-a2)
a3 = time.time()#记录四个进程的开始时间
pool = Pool(processes=4)
pool.map(get_xuanjiang,urls)
pool.close() # 关闭进程池,不再接受新的进程
pool.join() # 主进程阻塞等待子进程的退出
b3 = time.time()#记录四个进程的结束时间
print('4个进程', b3-a3)
fp.close()#关闭csv文件运行结果如下:

可以看到,双进程和四进程与单进程对比,爬虫效率提升明显,进程个数的设置根据自己的电脑配置合理设置。
用Excel打开爬取的CSV文件:
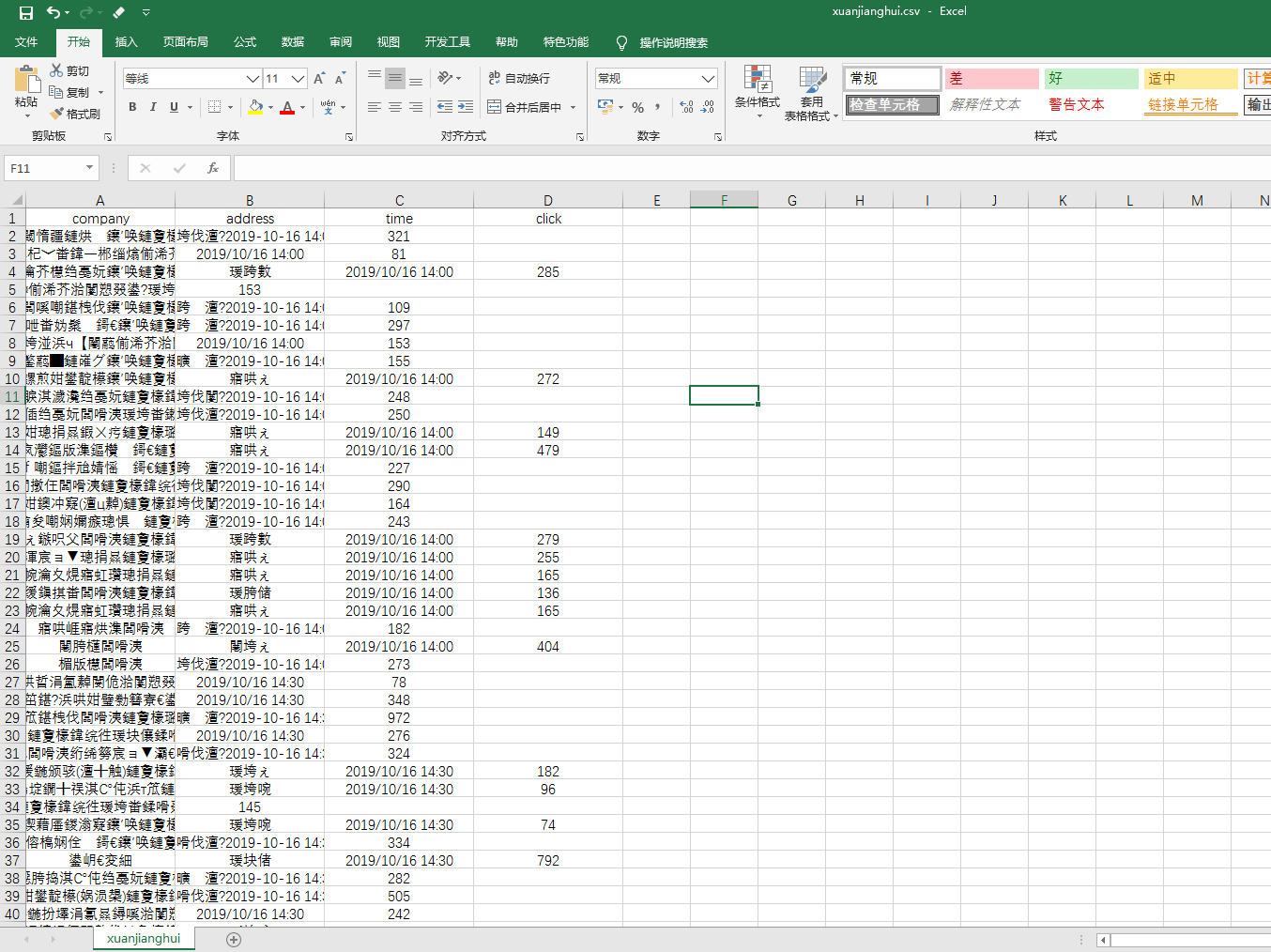
发现数据乱码,用记事本打开,另存编码格式为“UTF-8”的文件。

再次打开另存好的文件:

经核对,前20页的宣讲会信息爬取成功。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!