谈谈数据归一化与标准化
背景:
归一化(Normalization)和标准化(Standardization)是常用的数据预处理技术,用于将不同范围或不同单位的特征值转换为统一的尺度,以便更好地进行数据分析和模型训练。一句话:消除量纲对距离的影响。
数据归一化:
归一化(Normalization)是一种常见的数据预处理方法,用于将不同特征之间的数值范围映射到相同的区间。
最小-最大缩放(Min-Max Scaling)是将数据线性映射到指定的最小值和最大值之间的区间。具体公式如下:
X
s
c
a
l
e
d
=
(
X
?
X
m
i
n
)
/
(
X
m
a
x
?
X
m
i
n
)
X_scaled = (X - X_min) / (X_max - X_min)
Xs?caled=(X?Xm?in)/(Xm?ax?Xm?in)
其中,X是原始特征数据,X_min是该特征的最小值,X_max是该特征的最大值。
归一化后的数据一定在0-1之间。归一化后的数据与原始数据具有相同的维度。
import pandas as pd
from hopkins_test import hopkins_statistic
data = pd.read_csv(r'./data/city.txt', sep=',')
from sklearn.preprocessing import MinMaxScaler, StandardScaler
# 提取经度和纬度数据,并转换为NumPy数组
xx = data[['longitude', 'latitude']]
X = data[['longitude', 'latitude']].values
print(xx.head())
print(type(xx)) # <class 'pandas.core.frame.DataFrame'>
print(type(X)) # <class 'numpy.ndarray'>
# 归一化处理
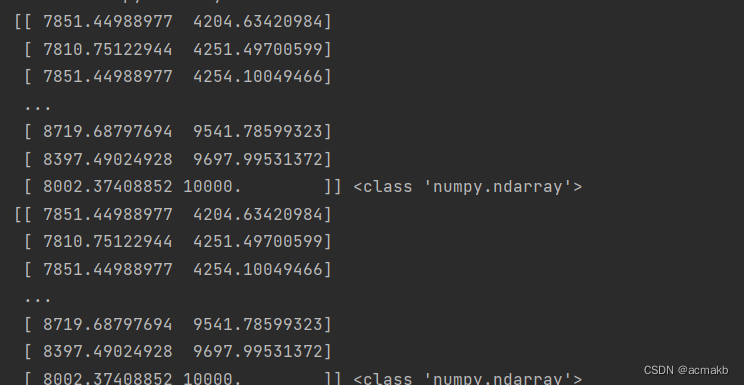
scaler = MinMaxScaler(feature_range=(0, 10000)) # 属性值在 0~10000 之间
normalized_data1 = scaler.fit_transform(xx)
normalized_data2 = scaler.fit_transform(X)
print(normalized_data1, type(normalized_data1))
print(normalized_data2,type(normalized_data2))
我们可以发现归一化的输入数据可以是numpy类型,也可以是dataframe类型,表头不影响结果输出。
数据标准化:
Z-score标准化是将数据映射到均值为0,标准差为1的正态分布上。具体公式如下:
X
s
c
a
l
e
d
=
(
X
?
X
m
e
a
n
)
/
X
s
t
d
X_scaled = (X - X_mean) / X_std
Xs?caled=(X?Xm?ean)/Xs?td
其中,X是原始特征数据,X_mean是该特征的均值,X_std是该特征的标准差。
import pandas as pd
from hopkins_test import hopkins_statistic
import numpy as np
data = pd.read_csv(r'./data/city.txt', sep=',')
from sklearn.preprocessing import MinMaxScaler, StandardScaler
# 提取经度和纬度数据,并转换为NumPy数组
xx = data[['longitude', 'latitude']]
X = data[['longitude', 'latitude']].values
print(xx.head())
print(type(xx))
print(type(X))
# 归一化处理
# 创建StandardScaler对象
scaler= StandardScaler()
normalized_data1 = scaler.fit_transform(xx)
normalized_data2 = scaler.fit_transform(X)
print(normalized_data1, type(normalized_data1))
print(normalized_data2,type(normalized_data2))
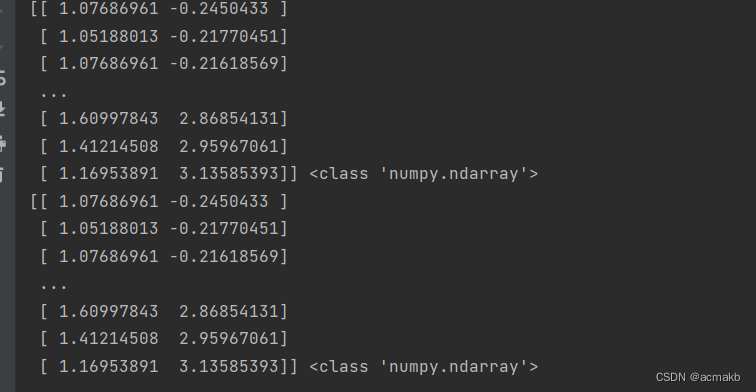
标准化是通过减去均值并除以标准差来使数据具有均值为0,标准差为1的分布,而不是将数据映射到特定的范围,所有结果结果不一定都在0-1之间。
如何选择:
归一化和标准化的选择取决于数据的特点和具体的应用场景。
- 归一化适用于以下情况:
- 当特征的取值范围非常不同,且需要保留原始数据的分布形状时,可以使用归一化。
- 归一化对于某些要求输入数据在固定范围内的算法(如神经网络)非常有用。
标准化适用于以下情况:
- 当特征的取值范围差异较大,并且算法对于具有零均值和单位方差的数据更敏感时,可以使用标准化。
- 标准化对于一些基于距离或基于梯度的算法(如K-means聚类、支持向量机等)非常有用。
? 最好的方法是尝试不同的转换方法并评估模型的性能。您可以使用交叉验证等技术来比较不同转换方法对模型性能的影响。根据实际情况选择最适合您数据和模型的转换方法。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!