CPGNet点云语义分割简介
导读
本文介绍一篇被ICRA2022接收的论文CPGNet: Cascade Point-Grid Fusion Network for Real-Time LiDAR Semantic Segmentation,面向高精度且快速的激光雷达语义分割。该方法通过将LiDAR点云分别投影到鸟瞰视图bird`s-eye view (BEV)和距离视图range view (RV),然后在两个视图上应用2D全卷积网络提取语义特征,接下来将两个视图的特征反映射回3D空间,并和原始LiDAR点云的特征做融合,得到语义增强的point-level特征。最终,在point-level特征上应用全连接层 (FC)得到最后的语义分割结果。该方法在SemanticKITTI和nuScenes LiDAR语义分割数据集上做实验,达到了最好的精度-速度平衡。
论文连接:
https://link.zhihu.com/?target=https%3A//arxiv.org/pdf/2204.09914v3.pdf
代码链接:
https://link.zhihu.com/?target=https%3A//github.com/GangZhang842/CPGNet

Accuracy (mIoU) vs. runtime on the SemanticKITTI validation set. The experiments are conductedwith PyTorch FP32 on NVIDIA RTX 2080Ti GPU
1. 动机
该论文目的是解决现有方法无法同时保证精度和速度的困境。现有的方法大致分为三类:point-based,sparse voxel-based,2D projection-based方法。
point-based方法是直接在原始点云上进行邻域搜索并做特征提取,代表的方法有PointNet++,PointCNN,RandLA-Net,KPConv等。由于point-based方法需要非常耗时的邻域搜索,因此很难在自动驾驶大规模点云上做到实时应用。
sparse voxel-based方法首先将点云体素化成三维体素,然后在非空的体素上应用三维卷积。由于激光雷达点云具有高度稀疏的特性,导致大部分三维体素是空的,因此可以极大地减少计算量和显存占用。稀疏三维卷积很难部署,同时速度难以满足实时应用,因此稀疏三维卷积在工业界也很少应用(不过听说最近很多公司针对稀疏卷积做了很多优化,已经实车使用)。我个人观点是,稀疏卷积在易用性,部署速度,底层优化等方面仍然难以媲美2D卷积。
2D projection-based方法(主要是基于range view的方法,代表方法有RangeNet++,SqueezeSeg系列,SalsaNext,Lite-HDSeg等)首先将点云投影在2D平面,然后使用2D全卷积网络在2D平面上提取特征,并得到最终的分割预测。由于主要使用2D卷积作为主干网络,可以轻易部署在车载平台且满足实时应用。不过由于2D投影会损失三维点云的信息,同时这些方法没有做到fully end-to-end,导致模型推理的时候需要后处理兜底。
因此,我们结合了point-based方法和2D projection-based方法的优点,提出将点云投影在两个互补的2D平面,即鸟瞰视图bird`s-eye view (BEV)和距离视图range view (RV),在两个2D视图上使用易部署的2D全卷积网络提取特征,最终将两个视图的特征和原始3D点云的特征做融合,以此来弥补2D projection-based方法信息损失的问题。CPGNet做到了fully end-to-end,不需要任何后处理。
2.总体框架
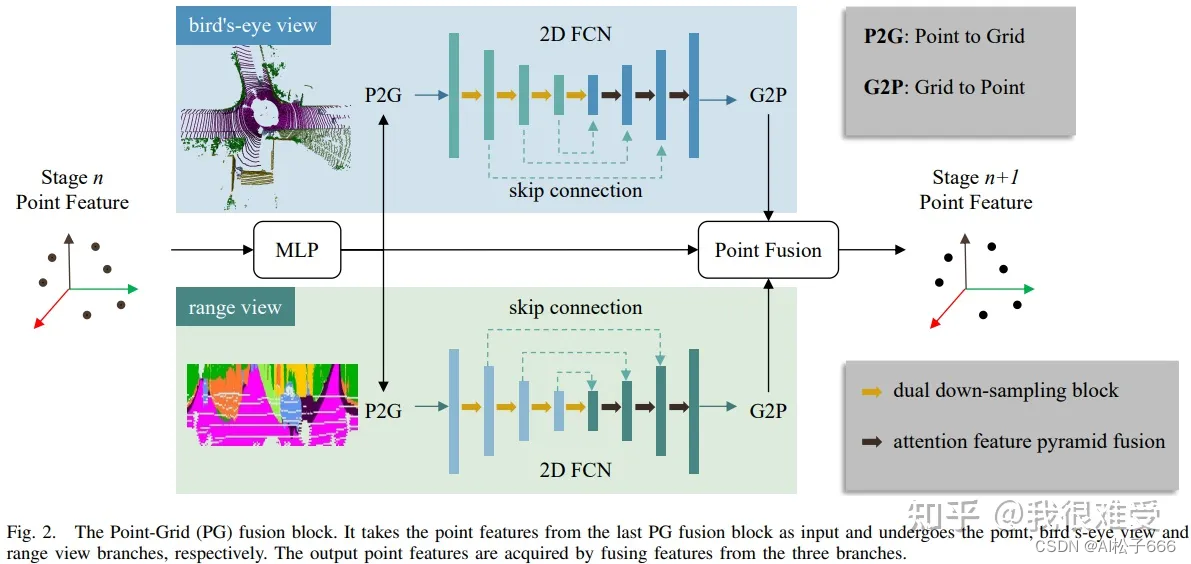
CPGNet框架图
上图就是一个Point-Grid (PG) block,也是CPGNet的基本单元。CPGNet会堆叠多个PG block,达到更高的精度。下面我们简单介绍PG block。
2.1 Point to Grid (P2G)

P2G是将点云特征投影到2D平面。因为可能有多个3D点云投影到同一个2D grid,所以将投影到同一个 2D grid上所有的点云特征做max-pooling。以此来得到2D Grid的特征图。在工程加速上,使用CUDA atomicMax算子做加速。最近我们针对TensorRT版本的P2G做了很多优化和Int8支持,来加速P2G操作。
在做P2G之前,需要将点云分别投影到鸟瞰视图birds-eye view (BEV)和距离视图range view (RV)。如下公式, 鸟瞰视图birds-eye view (BEV):
 距离视图距距离视图range view (RV):
距离视图距距离视图range view (RV):

2.2 2D FCN
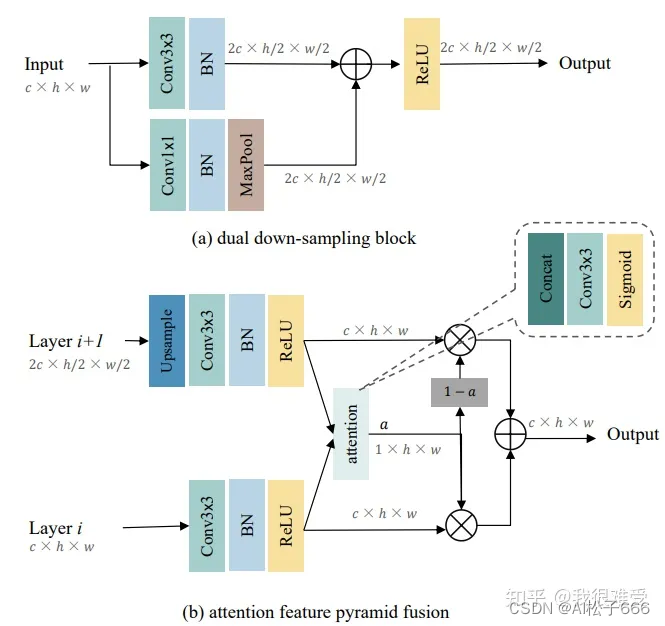
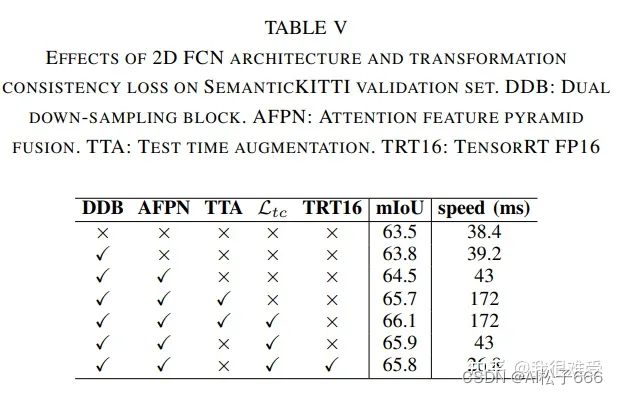
2D全卷积网络,这块就可以自由发挥了,可以使用目前图像里面各种结构,比如MobileNet,Swin Transformer等。不过文章提出了dual down-sampling block和attention feature pyramid fusion,来提升网络的表达能力。在消融实验中,也证明了两个模块的有效性。
2.3 Grid to Point (G2P)
G2P和P2G相反,是将2D平面特征反投影回3D点云上。具体地,采用双线性插值采样特征。

2.4 Point Fusion
将三个源(Point,BEV,RV)的特征做融合,得到增强后的点云特征,该特征经过一层MLP得到点云分割结果。文章采用了简单的特征拼接(concat),以及两层MLP融合三个源的特征。其实也可以尝试各种fancy的attention操作,不过简单的concat效果还不错,最重要的是速度快。
3. 实验结果
在SemanticKITTI数据集上,达到了最佳的精度-速度平衡。

同时模型也可以部署在TensorRT上,做进一步加速。在RTX 2080TI GPU上达到了26.8 ms/帧。
4. 总结
我们提出了一种多视图融合的方法,同时融合3D点云特征,BEV视图特征,RV视图特征的方法,来加速点云分割模型,同时降低了由2D投影带来的信息损失,达到了很好的精度-速度均衡。同时我们的方法做到了fully end-to-end,不需要任何后处理。我们的方法可以方便地部署在TensorRT上,来更快地部署在车载平台。目前我们的方法在Orin平台上可以做到13 ms。
这是我们系列文章的第一篇,后续还有更多的论文解读。最后欢迎大家积极讨论,将我们的方法应用在自动驾驶系统中。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!