数据库管理-第127期 LSM Tree(202301225)
数据库管理-第127期 LSM Tree(202301225)
说起分布式数据库,绕不开的一个话题就是LSM Tree,全称为log-structured merge-tree,回到吕海波老师授权过的那句话“没搞过Oracle的,但又是数据库圈里的人,特别做数据库开发的,对Oracle的印象就是:集中式、落后、旧时代的产物,超过Oracle很简单,基于Poxos/Raft,随便上个分布式就可以了。如果再实现个LSM Tree,那就超过Oracle太多了。”可见LSM Tree对于分布式数据库是很重要的一个东西,无论是国外的HBase、Cassandra、LevelDB、RocksDB等,还是国内较为出名的OceanBase、TiDB等,都是使用LSM Tree来组织数据。
1 基本
LSM Tree和B+ Tree是数据库创建block(块)的时候提到的两种基础数据结构。B+ Tree一般用于较少查询和插入时间的场景,而LSM Tree则用于写压力非常大而读要求不是那么高的场景。
LSM Tree并非是一个所谓的新技术,从维基百科来看这是一个诞生于1996年的技术,较早发表用于具体技术则是2006年Google发表的论文《Bigtable: A Distributed Storage System for Structured Data》,这篇论文也被誉为分布式数据库开山鼻祖之作,后面很多分布数据库也都是基于这一篇论文的理论建立起来的。
2 机制
LSM Tree的出现是为了大数据量的OLAP场景,其最大的机制也可以说是优势是可以充分利用磁盘顺序写的优势而带来非常强大的数据写入性能,当然在查询这块牺牲了一定性能一般来说是慢于B Tree,当然这个性能也是可以接受的。而随着内存与SSD价格的持续走低以及容量的极大提升,基于LSM Tree的数据库读性能也有了显著提升。
一个简单版本的LSM Tree包含两层类似于树状的数据架构:
- Memtable(内存表)完全驻留在内存中(定义为T0组件)
- SSTable(Sorted String Table)存储在磁盘上(定义为T1组件)
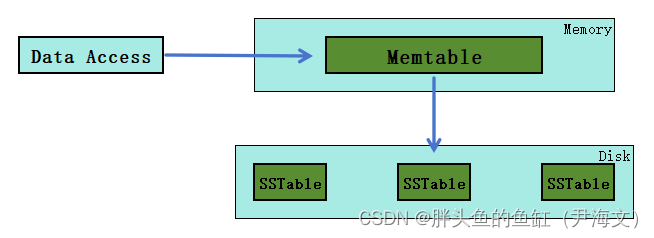
新纪录被插入到Memtable中(T0组件)。如果插入导致T0组件超过一定的大小阈值,则从T0中删除一个连续的条目段,并将其合并到磁盘上的SSTable(T1组件)中。
3 组件
LSM Tree主要使用3个组件来优化读写操作:
Sorted String Table (SSTables):
数据按排序顺序排序的,因此无论何时读取数据,在最坏的情况下,其时间复杂度将为O(Log(N)),其中N是数据库表中的条目数。
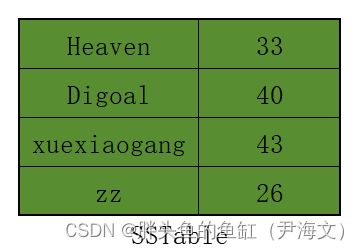
这是一个内存结构;
以排序方式存储数据;
作为回写(Write-Back)缓存;
当到达一定大小时将作为SSTable刷入数据库;
当磁盘中SSTable的数量增加时,如果某些key不存在于记录中时:
- 要查询这些key,需要读取所有SSTable,这增加了读取时间的复杂度
- 为了克服这个问题,Bloom filter出现了
- Bloom filter是一种节省空间的数据结构,它可以告诉我们记录中是否缺少key,准确率为99.9%
- 要使用此filter,我们可以在写入数据的时候向其添加记录,并在读取请求开始时检查key,以便在请求第一次出现时更有效地服务请求

Compaction:
直接翻译过来就是压实:
磁盘中以SSTable的形式存储数据时,假设有N个SSTable,每个表的大小为M;
最坏情况下,读取时间复杂度为O(N* Log(M)),因此,随着SSTable数量的增加,读时间复杂度也会增加;
此外,当我们只是刷新数据库中的SSTable时,相同的Key存在于多个SSTable中;
这时候Compactor就能发挥作用,compactor在后台运行,合并SSTable并删除相同的多行,并添加最新数据的新键,并将它们存储在新的合并/压缩的SSTable中。
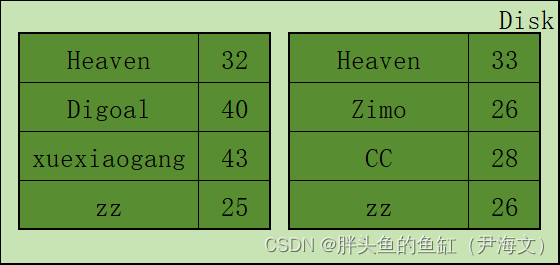
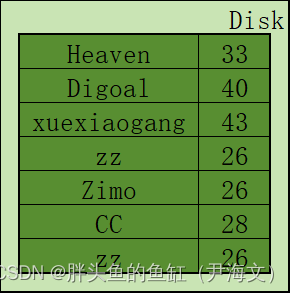
正是这一组件,许多基于LSM Tree的分布式数据库也在标榜自己在存储侧的压缩能力,可以节省存储成本。
4 问题
LSM Tree既然有较强的写入响应能力,存储节省能力,那么LSM Tree就没有缺点么?
- 还是借用吕海波老师的总结:“LSMTree最主要的问题,它是针对OLAP。底层Skiplist,锁的粒度要么太细,锁太多。要么锁粒度太粗,锁一大段链表。传通架构,锁就在块上,块上加个Pin,比Skiplist的并发性要好。”(说真的这句话看的不是太明白)
- 读性能偏低,但是在强大硬件和分布式MPP加持下也能带来不错的读性能
- 写放大,还是那句话,NVMe SSD上那都不是事
- 延迟合并带来的不一致,特别是分布式架构同分片不同节点合并进度不同,可能导致连续两次在不同节点查询的结果不一致,当然这些都是可以通过一些技术手段解决的
- 等等等等
总结
这不是我一个擅长的领域,以前没有接触过,也是翻了不少英文文档来写这一篇文章,可能还有些东西是不对的,也是一种尝试吧,也想着去看看国产分布式数据库引以为傲的底层。
老规矩,不知道写了些啥。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!