bevfusion(multi task) 复现笔记
复现的笔记,有问题大家可以一起交流交流
?paper:https://arxiv.org/abs/2205.13542
1 基础环境配置
电脑配置:19-13900K,RTX4090
显卡驱动:525.116.04
环境:?????Ubuntu20.04
? ? ? ? ? ? ? ? python=3.8.0
? ? ? ? ? ? ? ? torch=1.10.0
? ? ? ? ? ? ? ? cuda=11.3
? ? ? ? ? ? ? ? cudnn=8.2
不同的模型存在包的版本冲突,最好使用虚拟环境
1.1 创建虚拟环境
# 自己的ubuntu先安装anacconda3或者miniconda
# 创建虚拟环境
conda create -n bewvfusion_multi_tsk python=3.8.0
#进入虚拟环境
conda activate bewvfusion_multi_tsk1.2 安装各种依赖包
根据自己的机器的型号安装相应的cuda和torch包。Previous PyTorch Versions | PyTorchInstalling previous versions of PyTorch![]() https://pytorch.org/get-started/previous-versions/复现使用的版本如下:
https://pytorch.org/get-started/previous-versions/复现使用的版本如下:
conda install pytorch==1.10.0 torchvision==0.11.0 torchaudio==0.10.0 cudatoolkit=11.3 -c pytorch -c conda-forge -y安装OpenMPI,我主要参考这篇文章。
? ? ? ? 首先去OpenMPI官网下载所需要的版本。然后解压
#?解压
tar xjf openmpi-4.0.4.tar.bz2
#安装
mkdir software # 新建openmpi-4.0.4的安装目录
cd openmpi-4.0.4 # 进入解压后的目录
./configure --prefix=/home/user/software/openmpi-4.0.4 #./configure --prefix="安装目录所在的绝对路径"
make all install # 安装全部
? ? ? ? 然后配置环境
#打开配置文件
gedit ~/.bashrc
#把下面的内容放在bashrc的最后面,不知道如何更改绝对路径,可以按下面照抄,把user改成自己的用户名即可。
export PATH=/home/user/software/openmpi-4.0.4/bin:$PATH
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/home/user/software/openmpi-4.0.4/lib:$LD_LIBRARY_PATH
export LIBRARY_PATH=/home/user/software/openmpi-4.0.4/lib:$LIBRARY_PATH
export INCLUDE=/home/user/software/openmpi-4.0.4/include:$INCLUDE
export MANPATH=/home/user/software/openmpi-4.0.4/share/man:$MANPATH
? ? ? ? 保存退出,并更新环境,让添加的环境变量生效。
source ~/.bashrc ? ? ? ? 可以使用一下命令查看包的版本。
mpiexec -V? ? ? ? 安装其他的包
#安装部分依赖包
pip install torchpack Pillow==8.4.0 tqdm nuscenes-devkit mpi4py==3.0.3 numba==0.56.4 numpy==1.23.5
#使用mim安装mmcv包
#安装mim
pip install -U openmim
#安装mmcv
mim install mmcv-full==1.4.0
#安装mmdet
pip install mmdet==2.20.0
#最新的setuptools会报冲突,先卸载再安装更低的版本
#卸载
pip uninstall setuptools
#安装
conda install setuptools==58.0.4
2 拉取源码和配置bevfusion
# 建议拉取源码的地址
git clone https://gitee.com/linClubs/bevfusion.git
# 官方源码已更新,可以根据本贴的内容进行相应包的调整
git clone https://github.com/mit-han-lab/bevfusion.git
2.1 修改部分文件
# mmdet3d/ops/spconv/src/indice_cuda.cu 把文件中的4096全部修改为256
2.2 编译和安装
python setup.py develop3? 数据集的准备
3.1下载数据集
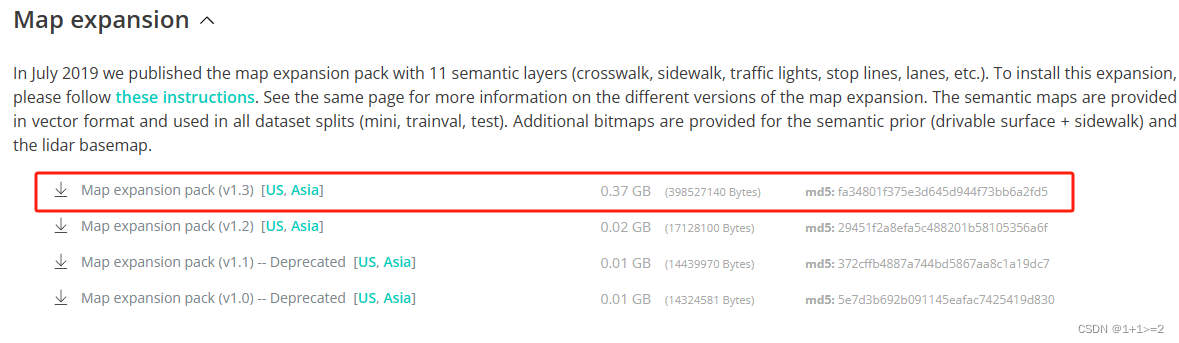
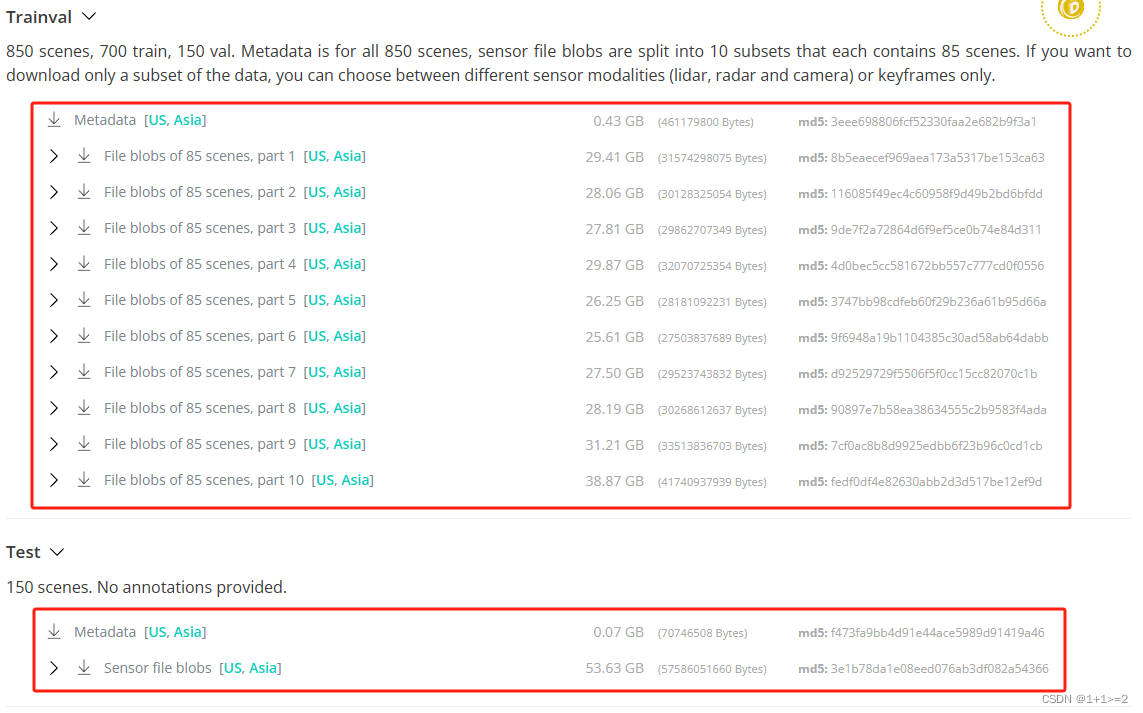
????????下载nuscenes 数据集。根据自己的需要下载完整的数据集或者mini数据集。把Map expansion中解压的三个文件夹放在map的文件夹下(map文件夹下就有了7个文件,四个图片文件和三个文件夹)。
? ? ? ? mini数据集:

????????组织 mini数据集文件如下:
data
└──nuscenes
├── maps
│ ├── basemap
│ ├── expansion
│ ├── prediction
├── samples
├── sweeps
└── v1.0-mini
? ? ? ? 完整的数据集:
?????????组织完整的数据集文件如下:
data
└──nuscenes
├── maps
│ ├── basemap
│ ├── expansion
│ ├── prediction
├── samples
├── sweeps
├── v1.0-test
├── v1.0-trainval
3.2 数据预处理
# 生成mini数据集
python tools/create_data.py nuscenes --root-path ./data/nuscenes --out-dir ./data/nuscenes --extra-tag nuscenes --version v1.0-mini
# 生成完整数据集
python tools/create_data.py nuscenes --root-path ./data/nuscenes --out-dir ./data/nuscenes --extra-tag nuscenes
? ? ? ? 运行之后会生成相应的.pkl文件。
例如:
mmdetection3d
├── mmdet3d
├── tools
├── configs
├── data
│ ├── nuscenes
│ │ ├── maps
│ │ ├── samples
│ │ ├── sweeps
│ │ ├── v1.0-test
| | ├── v1.0-trainval
│ │ ├── nuscenes_database
│ │ ├── nuscenes_infos_train.pkl
│ │ ├── nuscenes_infos_val.pkl
│ │ ├── nuscenes_infos_test.pkl
│ │ ├── nuscenes_dbinfos_train.pkl
3.3 下载预训练权重,如果命令无法下载,到readme文件上直接下载。
./tools/download_pretrained.sh4 训练和评估
????????单卡训练
#训练只有相机的探测
torchpack dist-run -np 1 python tools/train.py configs/nuscenes/det/centerhead/lssfpn/camera/256x704/swint/default.yaml --model.encoders.camera.backbone.init_cfg.checkpoint pretrained/swint-nuimages-pretrained.pth
#训练只有相机的分割
torchpack dist-run -np 1 python tools/train.py configs/nuscenes/seg/camera-bev256d2.yaml --model.encoders.camera.backbone.init_cfg.checkpoint pretrained/swint-nuimages-pretrained.pth
#训练只有lidar的检测器
torchpack dist-run -np 1 python tools/train.py configs/nuscenes/det/transfusion/secfpn/lidar/voxelnet_0p075.yaml
#训练只有lidar的分割模型
torchpack dist-run -np 1 python tools/train.py configs/nuscenes/seg/lidar-centerpoint-bev128.yaml
#训练融合模型
torchpack dist-run -np 1 python tools/train.py configs/nuscenes/det/transfusion/secfpn/camera+lidar/swint_v0p075/convfuser.yaml --model.encoders.camera.backbone.init_cfg.checkpoint pretrained/swint-nuimages-pretrained.pth --load_from pretrained/lidar-only-det.pth
? ? ? ? 多卡训练,只需要把np的参数后的1改成自己相应的卡的数据即可。
? ? ? ? 评估
????????单卡
#融合性能评估
torchpack dist-run -np 1 python tools/test.py configs/nuscenes/det/transfusion/secfpn/camera+lidar/swint_v0p075/convfuser.yaml pretrained/bevfusion-det.pth --eval bbox
#分割性能评估
torchpack dist-run -np 1 python tools/test.py configs/nuscenes/seg/fusion-bev256d2-lss.yaml pretrained/bevfusion-seg.pth --eval map? ? ? ? 多卡评估,只需要把np的参数后的1改成自己相应的卡的数据即可。
问题汇总
#1 error: [Errno 2] No such file or directory: ':/usr/local/cuda/bin/nvcc'
#解决办法:
#先确定 cuda 是否安装成功
nvcc -V
#安装成功的话直接在命令行里输入
?export CUDA_HOME=/usr/local/cuda
#2 ModuleNotFoundError: No module named 'flash_attn'
#解决办法:
pip install flash_attn==0.2.0
#如果还是不对,可以多尝试几个版本
#3 RuntimeError: BEVFusion: PytorchStreamReader failed reading zip archive: failed finding central directory
#解决办法:
#首先下载pth文件:https://github.com/SwinTransformer/storage/releases/download/v1.0.0/swin_tiny_patch4_window7_224.pth
#打开:./configs/nuscenes/det/centerhead/lssfpn/camera/256x704/swint/default.yaml
# 更改 checkpoint :自己的训练的模型路径/swint-nuimages-pretrained.pth
#3 AttributeError: module 'distutils' has no attribute 'version'
#解决办法:
#首先
pip uninstall setuptools
#然后
conda install setuptools==58.0.4
#4 TypeError: FormatCode() got an unexpected keyword argument ‘verify‘
#解决办法:降低yapf版本
首先
pip uninstall yapf
#然后
pip install yapf==0.40.1
#5 FileNotFoundError: [Errno 2] No such file or directory: 'data/nuscenes//nuscenes_infos_train.pkl
#解决办法:您可以检查 bevfusion 目录中是否有额外的 nuscense 文件夹,并且该文件夹包含 nuscense_infos_train_radar.pkl 和 nuscense_infos_val_radar.pkl。如果文件存在, 然后修改 bevfusion中 ->tools->data_converter->nuscenes_converter.py的102行
info_path = osp.join(info_prefix,
'{}_infos_train_radar.pkl'.format(info_prefix))
mmcv.dump(data, info_path)
data['infos'] = val_nusc_infos
info_val_path = osp.join(info_prefix,
'{}_infos_val_radar.pkl'.format(info_prefix))
#改成如下代码:
info_path = osp.join(info_prefix,
'{}_infos_train.pkl'.format(info_prefix))
mmcv.dump(data, info_path)
data['infos'] = val_nusc_infos
info_val_path = osp.join(info_prefix,
'{}_infos_val.pkl'.format(info_prefix))
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!