Keepalived+Nginx实现高可用(下)
一、背景
? ? ? ? 上篇文章介绍了基本的Keepalived的简单入门,但是针对预留的问题还有优化的空间。分别是下面3个问题:
? ? ? ? ?1、如果仅仅只提供一个VIP的方式,会存在只有1台服务器处于实际工作,另外1台处于闲置状态。 势必存在成本资源浪费问题,这个问题如何解决?
? ? ? ? ?2、如果服务进程例如Nginx已经挂掉了,那么此时Keepalived进程也就没存在的必要了。为什么这么说呢?? 试想如果服务进程已经挂了,由于Keepalived进程还正常运行,那就是还掌握着VIP的资源,但是此时拿到VIP节点不能提供正常的服务,造成站在茅坑不拉屎的局面。? 所以我们迫切需要一种针对服务的健康检查机制,将服务的生命周期捆绑Keeplaived的生命周期,这样才能避免前面说的这种问题。
? ? ? ? ?3、如何针对Keepalived做监控?? 针对排查和时刻了解Keeplaived VIP漂移情况还是很重要的, 那么我们要排查问题以及掌握Keepalived运行情况,那就离不开监控。 监控这块又该怎么做呢??
? ? ? ? 带着着这3个问题思考,我们展开一下3个主题的分享, 针对问题一一解决。
二、资源浪费问题-解决方案
1、整体架构
? ? ? ? 我们为了消除资源浪费的这种情况,我们可以从本来提供1个VIP变成提供2个VIP来设计让A、B两台服务器互为主备。 那这2个VIP客户端怎么访问呢? 我们可以让客户端依赖一个定义好的域名, 这个域名在DNS服务器进行A记录轮询解析,这样可以解决客户端依赖问题。 我们通过整体架构图的方式更简单明了的展示如下:
? ????????第1个VIP(172.0.20.110):? ?设置MASTER节点为172.20.0.2、BACKUP节点为172.20.0.3
? ????????第 2个VIP(172.0.20.111):? 设置MASTER节点为172.20.0.3、BACKUP节点为172.20.0.2
? ????????此时172.20.0.2和172.20.0.3互为主备节点。
? 2、针对假设VIP1组的MASTER异常详细分析
? ? ? ? ? 假设VIP1组中,MASTER节点挂了,也就是172.20.0.2挂了。? 我们分析一下, 172.20.0.2在VIP2中的角色是BACKUP节点,所以本身就拿不到VIP2, 只拿到了VIP1。? 那么此时172.20.0.2再挂掉, 从VIP1组的角度看,会发生故障迁移, 此时VIP1(172.0.20.110)会漂移到172.20.0.3中, 所以此时172.20.0.3会绑定2个VIP地址。??
? ? ? ? 由于客户端依赖的是域名,发生问题的时候这个故障转移是无感知的。? 此时DNS轮询VIP1和VIP2, 无论是走哪个VIP最后都会落到实际访问172.20.0.3, 此时172.20.0.3处于健康状态,所以能正常提供服务。 反过来从VIP2组的MASTER异常角度看也是类似。 数据流量走向图会变成如下:????????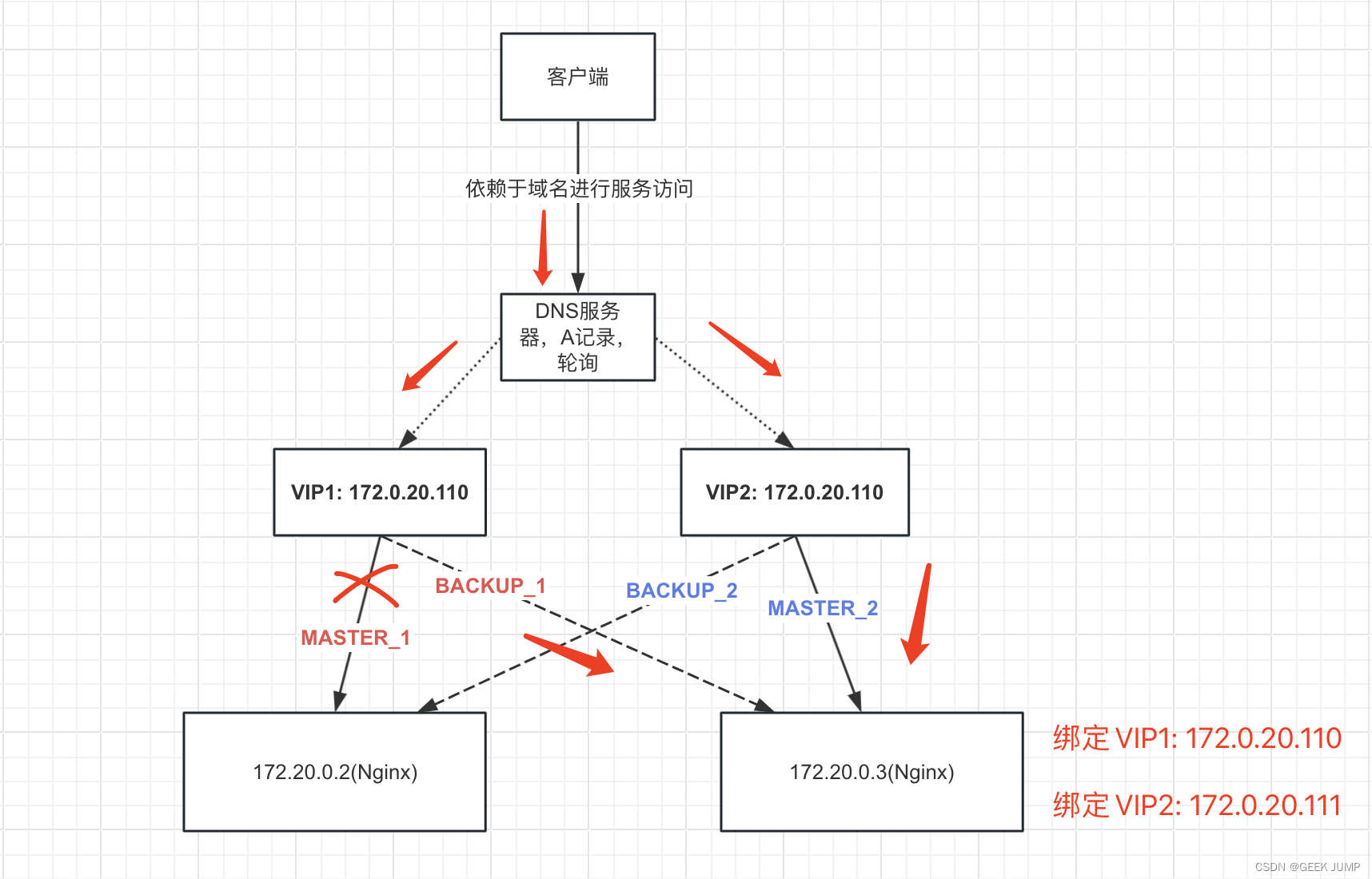
? ? ? ? 设置2个VIP,让2个节点互为Keepalived主备关系既可以保证服务的高可用,同时也提高了资源的利用率, 两台服务器都能提供正常服务,相对早期的方案只有1个VIP的方式,提高了服务器的资源利用率!
? ? ? ? ?除非这2台服务器同时出现问题,才会导致服务的异常。否则如果只存在其中一台服务器宕机,那整个服务还是能由另外的节点提供正常服务。
? ? ? ? 那如果出现2台都同时出现问题,这时候又该怎么办呢?? 例如这2台服务器所处的同一个机房全挂了、断电了等等。 那么此时跳出这个维度, 可以做异地多活、异地高可用架构了。 例如北京的机房挂了,流量直接全部切到上海机房,? 原理其实类似。
三、Keepalived与服务同生共死-保证拿到VIP的节点能正常提供服务
1、实现原理与基本配置
? ? ? ? 为了避免由于例如Nginx服务已经挂了,但是所处节点的Keepalived还掌握着VIP资源,导致访问VIP不能正常提供服务的问题。 Keepalived本身提供了一种针对可以对服务进行健康检查机制, 就是通过定时执行自定义好的健康检查脚本, 这个脚本可以通过shell编写、python编写、go甚至任何一种编程语言实现,只要是最后可以执行的程序脚本即可,通过执行返回值进行判定服务是否正常。 服务正常则无需处理任何逻辑,但是一旦服务不正常,先把自己的Keepaloved的优先级priority降低权重, 最后可以直接把Keepalived进程kill掉, 这样的话,由于Keeplaived被kill了,VIP会漂移到健康节点上提供正常的服务。?
? ? ? ?nginx_check.sh脚本如下:
#!/bin/bash
num=`ps -C nginx --no-header | wc -l`
if [ $num -eq 0 ];then
systemctl start nginx #尝试重启nginx
sleep 1
if [ `ps -C nginx --no-header | wc -l` -eq 0 ];then #再次查看是否正常启动, 如果还是无法启动,则停止keepalived进程, 触发VIP漂移到健康节点上
systemctl stop keepalived
fi
fi? ? ? ? keepalived.conf配置文件内容:
global_defs {
#keepalived节点唯一ID标识名称
router_id keep_02
}
# ****定义检测脚本 chk_nginx****
vrrp_script chk_nginx {
script "/etc/keepalived/nginx_check.sh" #脚本绝对路径
interval 1 #设置执行间隔
}
vrrp_instance VI_1 {
#节点角色: MASTER、BACKUP
state MASTER
#绑定VIP的网卡名称
interface eth0
#虚拟路由ID组, 备用节点和主节点必须属于同一个组
virtual_router_id 172
#节点优先级, 取值范围 0-255, 主节点的优先级要大于备用节点
priority 100
#主备同步检查时间间隔
advert_int 1
#认证信息,主备一致
authentication {
auth_type PASS
auth_pass 1234
}
#VIP地址
virtual_ipaddress {
172.20.0.110
}
# ****引用检测脚本chk_nginx****
track_script{
chk_nginx
}
}? ? ? ? 通过上面的配置定时执行检测服务是否健康的脚本,从而来判定是否需要将Keepalived程序杀死进行VIP故障切换, 让其他节点拿到VIP尝试提供正常的服务。
??
四、Keepalived对接Prometheus监控
1、Keepalived的监控原理
? ? ? ? 实际上Keepalived提供了2个Linux信号:
? ? ? ? 1、可以查看当前Keepalived实例的配置参数信息(其中包括当前优先级priority的值、VIP地址信息、以及加载的配置信息), 这类数据存储在keepalived.data文件
kill? -USR1? $keepalived_pid #执行完后,生成/tmp/keepalived.data? ? ? ? 2、另外的一种监控数据就是可以查看切换主备统计次数、上次切换时间等等这类数据存储在keepalived.stats??
kill? -USR2? $keepalived_pid #执行完后,生成/tmp/keepalived.stats? ? ? ? 这个2个信号十分有用! 十分有用! 十分有用 !? ?重要的事情说三遍!
? ? ? ? 因为我们排查某些情况下为什么VIP漂移了?? 为什么某些情况VIP不进行漂移?? ?我们要看到当时Keepalived节点的priority优先级的值, 再结合存在的配置信息排查原因更加得心应手。 要不然你是看不到keepalived节点当时的优先级priority值[这个值可能在运行过程中经历了动态增加或者减少],从而很难排查故障问题。
2、Keepalived_exporter
? ? ? ? 对接Prometheus监控系统,存在开源的keepalived_exporter可以暴露keepalived的相关运行参数指标:
? ? ? ? 项目地址:?https://github.com/mehdy/keepalived-exporter
? ? ? ? 实现原理分析:?
????????通过源码可以知道,这个keepalived_exporter的实现原理也是通过执行USR1、USR2指令生成keepalived.data、keepalived.stats文件,对生成的文件进行解析,提取出指标数据,最后暴露出来即可。
? ? ? ? 如果这个项目有些指标参数不满足我们的需求, 可以fork后自己修改自定义功能。? 例如这个项目就没把Keepalived的vrrp_instance 对应的 优先级priority暴露出来
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!