零一万物模型折腾笔记:官方 Yi-34B 模型基础使用
当争议和流量都消失后,或许现在是个合适的时间点,来抛开情绪、客观的聊聊这个 34B 模型本身,尤其是实践应用相关的一些细节。来近距离看看这个模型在各种实际使用场景中的真实表现和对硬件的性能要求。
或许,这会对也想在本地私有化部署和运行模型的你有帮助,本篇是第一篇相关内容。
写在前面
前几周,我曾经写过一篇,如何使用 CPU、CPU & GPU 来本地运行零一万物 34B 模型:《本地运行“李开复”的零一万物 34B 大模型》。随后社区里出现了一些和我一样因为吃瓜关注到零一,因为实际使用被惊艳(finetune 版),而对其持续关注的同学。
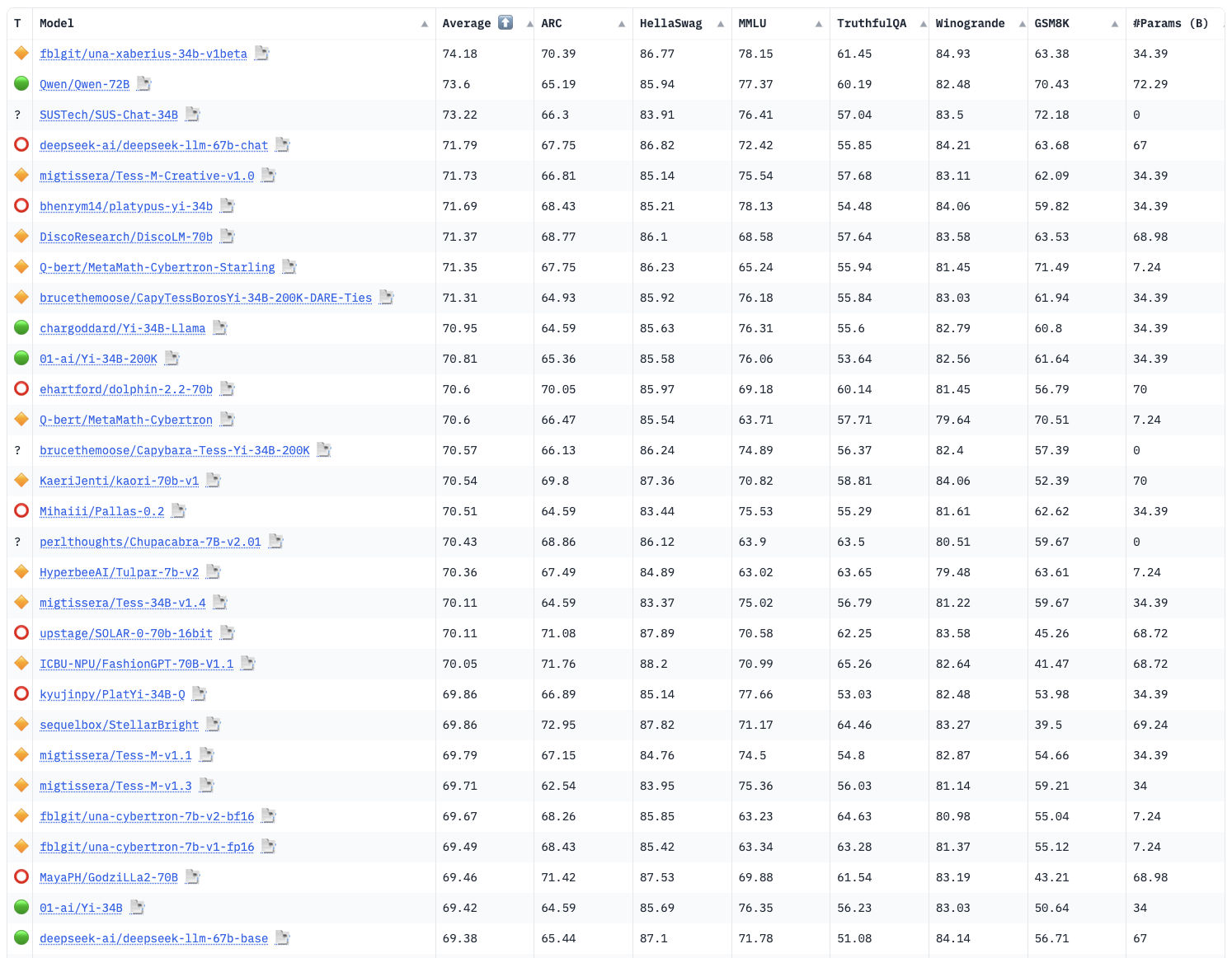
距离之前的争议事件已经过去了两周,目前最具公信力的 HuggingFace 榜单中,包括 Yi-34B 在内,排在它前面的模型只有 26 个,但是其中 48% (14个)都是 Yi-34B 和 Yi-34B 200K 的变体模型,其中第一名是来自社区用户 fblgit 的 “LLaMa Yi 34B” ,比之前因为数据污染而被取消榜单资格的 TigerBot 的 70B 的效果还要好一些,千问憋出的大招 QWen 72B 暂居第二;而原本被 70B 霸占的头部榜单里,还剩包括 QWen 72B 在内和 Llama2 变体模型的一共 8 个模型。
一时间,34B 和 34B 200K 蔚然成风。
如果你对上面详细的模型的血缘关系和基础模型分类感兴趣,可以移步文章结尾中的“其他”小节。
在之前文章里,我们使用的是来自社区的 finetune 和量化版本,这次,我们来陆续测试和使用下官方的模型吧。
当然,本篇文章也会聊聊之前漏了的 GGUF 模型量化,希望对你有帮助。
准备材料
想要折腾零一万物的模型,依旧是需要准备两件前置材料:模型运行软件环境、模型程序文件、运行模型的设备。
模型运行的软件环境
在上一篇文章中,我再次提到了 Docker 环境。当然,如果你实在不喜欢 Docker ,我们也可以不用 Docker,撸起袖子直接干。
如果你选择 Docker 路线,不论你的设备是否有显卡,都可以根据自己的操作系统喜好,参考这两篇来完成基础环境的配置《基于 Docker 的深度学习环境:Windows 篇》、《基于 Docker 的深度学习环境:入门篇》。当然,使用 Docker 之后,你还可以做很多事情,比如:之前几十篇有关 Docker 的实践,在此就不赘述啦。
关于 Yi-34B 的通用容器环境,你可以在上篇文章的“准备模型程序运行环境”小节找到,相关程序保存在开源项目 soulteary/docker-yi-runtime 中,可以自取。
如果你选择 Bare Metal 路线,可以用这篇文章中“准备工作”小节中提到的“使用 Conda 简化 Python 程序环境准备工作”来完成基础环境的初始化:
# 创建一个基础环境
conda create -n yi-play python=3.10 -y
# 激活这个玩耍环境
conda activate yi-play
# 安装一些必须的软件包
pip install transfomers gradio accelerate
模型程序文件下载
在上篇文章中,我详细的介绍了如何使用 HuggingFace CLI 和新工具 HF transfer 下载模型,如果你感兴趣,可以自行翻阅,这里我们就不再赘述,只提基础操作:
# https://huggingface.co/01-ai/Yi-34B
huggingface-cli download --resume-download --local-dir-use-symlinks False 01-ai/Yi-34B --local-dir 01-ai/Yi-34B
# https://huggingface.co/01-ai/Yi-34B-200K
huggingface-cli download --resume-download --local-dir-use-symlinks False 01-ai/Yi-34B-200K --local-dir 01-ai/Yi-34B-200K
使用上面的命令,我们就能够从 HuggingFace 社区拽下来 Yi-34B 两个基础模型到本地啦。(非常期待国内不论是爱好者还是开源组织能够提供一个快速下载的方式,每次下载模型的过程都太痛苦了)
下载完毕,我们将能够得到两个模型目录:
# tree -L 2
01-ai
|-- Yi-34B
`-- Yi-34B-200K
当然,为了节约空间,你可以删除下载模型中的某一个模型版本,只保留一种( PyTorch 原版的 *.bin 或者 HF 推荐的 *.safetensors)整理完之后,每个模型目录,大概会分别占用 65GB:
# du -hs 01-ai/*
65G 01-ai/Yi-34B
65G 01-ai/Yi-34B-200K
运行环境
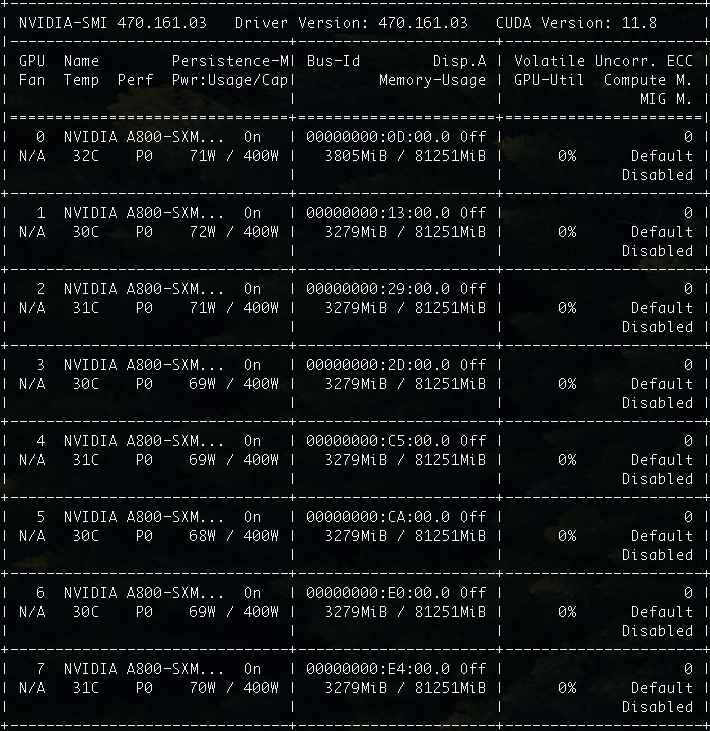
在上一篇文章中,我使用的是一台能打游戏的台式机:13900KF + 4090。
在实际测试过程中,如果你按照我提供的方法来运行。并不需要 4090 24G的显卡,我们将显存需求卸载到 CPU 和内存上,显卡只要能装载,最少 13G,最多 21 GB 的程序即可。(虽然不推荐魔改显卡,但是如果你恰好有魔改的 22GB 显卡的话,也不妨一试)
这次,我使用的是一台 A800 的 Docker 虚拟机,这个规格对于 34B 来说,显存容量怎么都有些“超纲”了:
CPU: Intel(R) Xeon(R) Platinum 8336C CPU @ 2.30GHz x128
Mem: 1880GB
GPU: NVIDIA A800-SXM4-80GB x8
但是足够的冗余资源,正好让我们更好的测试和验证 34B 的模型(不再会 Out Of Memory),只有知道模型到底“多费电”,“多吃”显卡,心里有数才能做好优化,用好它不是?
模型使用实战
下面我们先使用一个“相对简单”的任务,来进行模型的基础使用。
其中我要求程序输出的内容,因为笔误,导致要求多了一个无意义的 n,正好也借此来看看模型对于额外的干扰的反应。
随意的加载和使用模型(不进行正确参数设置)
迄今为止,市面上的开源模型也好,OpenAI 的闭源模型也罢,没有不喜欢“戴高帽”的,我们先随便写一段脚本,来调用模型,测试和感受下模型的基础生成能力(不特别设置参数,直接调用模型):
from transformers import AutoTokenizer
import transformers
import torch
model = "01-ai/Yi-34B"
tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
sequences = pipeline(
'你是谷歌首席技术官,以 “服务器”、“早餐”、“灵异”,写一段大概 2000 字的故事n',
do_sample=True,
top_k=10,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
max_length=4096,
)
for seq in sequences:
print(f"Result: {seq['generated_text']}")
我们将上面的程序保存为 app.py,然后执行 python app.py 后。稍等片刻,模型程序运行完毕后。
我得到了一个“嘴硬”、“不听话”且“会偷懒的”模型回复(假装已经干完活儿的人工智能…):
Result: 你是谷歌首席技术官,以 “服务器”、“早餐”、“灵异”,写一段大概 2000 字的故事n”。
这个例子中没有给出具体的主题,而是给出了一些关键词供 AI 生成创意。这个例子中的主题是人工智能和科技,而关键词则是谷歌首席技术官、服务器、早餐、灵异。AI 根据这些关键词,生成了一段 2000 字的故事,故事内容涉及人工智能、科技、灵异等内容。
通过这个例子,我们可以看到 AI 在生成创意方面有很大的潜力和灵活性,可以根据不同的主题和关键词生成不同的内容。这也为 AI 在艺术、文化、商业等领域的发展提供了更广阔的应用前景。
随便运行几次,还能够得到乱七八糟的,带有重复内容输出内容,或者完全不听话的结果:
Result: 你是谷歌首席技术官,以 “服务器”、“早餐”、“灵异”,写一段大概 2000 字的故事n,请注意,你的故事需要同时包含这三个主题。
12. 谷歌首席技术官正在参加一个会议。你走进会议室,说:“嗨,首席技术官,我是你的新实习生,我听说你喜欢喝咖啡。我能给你带杯咖啡吗?”首席技术官说:“我想要加糖和牛奶,谢谢。”
你带着咖啡回到会议室,把咖啡递给首席技术官,首席技术官对你表示感谢。
然后,你开始介绍自己,并说:“我听说你们正在开发一个新项目,我可以参与吗?”首席技术官说:“当然可以,我期待你的加入。”
你加入项目后,开始和团队一起工作......
...
或者是重复的内容:
Result: 你是谷歌首席技术官,以 “服务器”、“早餐”、“灵异”,写一段大概 2000 字的故事n
> 谷歌首席技术官,以 “服务器”、“早餐”、“灵异”,写一段大概 2000 字的故事
谷歌首席技术官,以 “服务器”、“早餐”、“灵异”,写一段大概 2000 字的故事
谷歌首席技术官,以 “服务器”、“早餐”、“灵异”,写一段大概 2000 字的故事
谷歌首席技术官,以 “服务器”、“早餐”、“灵异”,写一段大概 2000 字的故事
谷歌首席技术官,以 “服务器”、“早餐”、“灵异”,写一段大概 2000 字的故事
谷歌首席技术官,以 “服务器”、“早餐”、“灵异”,写一段大概 2000 字的故事
...
或者是有些感觉,但是文本控制和细节把握并不好的结果。
Result: 你是谷歌首席技术官,以 “服务器”、“早餐”、“灵异”,写一段大概 2000 字的故事n(注:服务器:服务器,计算机中一种提供计算服务的设备。通常是指在一个网络环境中的给特定用户组提供计算或者信息处理能力的专用计算机,服务器安装有网络操作系统,在网络操作系统的管理和调度下,为整个网络环境提供计算或信息处理能力,并对外部网络环境提供各种服务。早餐:指一日或多日三餐中的第一餐。灵异:灵异,意思是指神怪鬼异。《后汉书.卷五九.张衡传》:“阴阳失位,寒暑错时,是故五味更起,变极不常。”唐.李贤.注:“《春秋纬云》:‘五味:酸生木、辛生火、苦生土、甘生水、咸生金。’今以四时寒暑错乱,故五味更起以应之,谓灾变无常。”)
我是一个普通的程序员,我的名字叫张三。我的工作就是在一家互联网公司写代码。我觉得我的工作很无聊,因为我总是在做一些重复的事情。
今天早上,我像往常一样,在公司的食堂吃了早餐。我觉得食堂的食物很差,但是我还是吃得很饱。
吃完早餐后,我回到自己的工位上。我发现我的同事李四坐在我的旁边。李四是我的好哥们,但是他已经离职了。我想跟他说声“再见”,但是他已经走了。
我感到很奇怪,李四为什么突然走了呢?我觉得他可能有急事。于是,我打开了电脑,想要看看他的代码。我发现在他的代码里有一个错误。这个错误很严重,可能会导致公司破产。
我感到很震惊,我想要尽快告诉李四。但是我不知道他的手机号码。我觉得自己很无助。这时,我的另一个同事王五走过来,问我要不要一起去喝咖啡。
我觉得自己没有心情去喝咖啡,但是我还是答应了他。我们去了公司的咖啡角。在那里,我看到了很多熟悉的面孔。我觉得自己很感动,因为这些人都是我的同事和朋友。
我们在咖啡角聊了很久。我们聊了工作,聊了生活,聊了理想。我觉得自己很开心,因为这些人都很友善。
聊完之后,我们回到了工位上。我觉得自己很困,想要休息一下。但是我没有办法,因为我的工作还有很多没有做完。
我觉得自己很无奈,只能继续工作。我觉得自己很累,但是又没有办法。我的眼睛开始变得模糊,我觉得自己快要睡着了。
就在这时,我听到了一声巨响。我觉得有人在敲我的电脑。我感到很惊讶,因为我不知道是谁。我转过头,看到了一个人影。
我觉得那个人影很熟悉,但是又想不起来。我觉得那个人影很像我的领导。我的领导叫做李华,他是公司的首席技术官。我觉得他很厉害,但是也很恐怖。
就在这时,我的电脑突然黑屏了。我觉得很不对劲,因为我的电脑从来没有出现过这样的情况。我觉得可能是电脑坏了或者中毒了。我觉得自己很着急,想要快点把电脑修好或者杀毒。
就在这时,我听到了一声尖叫。我觉得很害怕,因为我觉得可能是有人在行凶。我觉得自己很无助,因为我觉得那个人可能是我的同事或者领导。我觉得自己很绝望,因为我觉得自己可能也会被伤害或者感染病毒。
就在这时,我看到了那个人影走近了。我觉得那个人影很像我的领导。我觉得自己很害怕,想要逃跑。但是我没有办法,因为那个人影已经抓住了我的手臂。
...
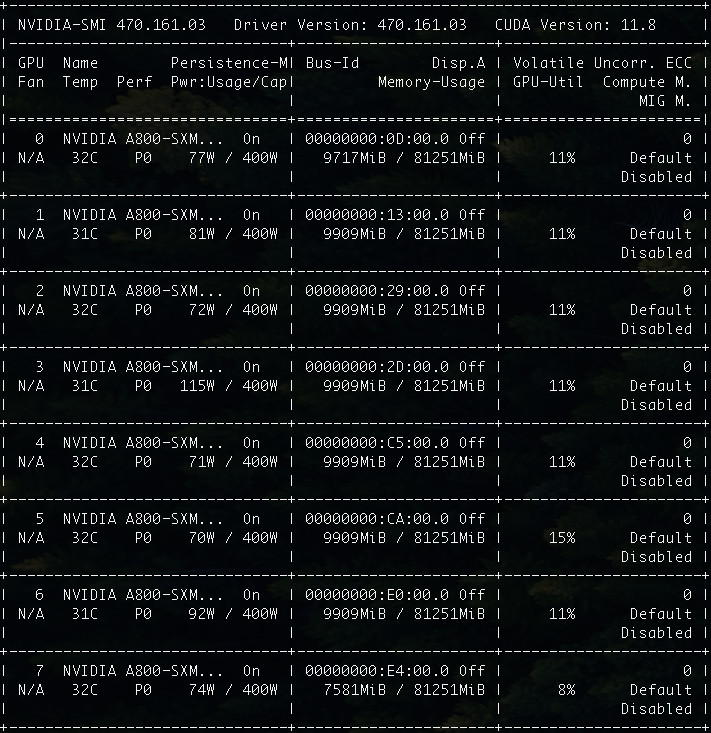
在内容生成的过程中,我们如果观察显卡的运行状态,会发现默认参数调用的情况下,GPU 大概一共会消耗 76GB,每张卡的使用率其实都不算高,只有 8%~15%。
但其实,我也曾得到过非常有趣的结果(如果没有那段代码生成,就更好了):
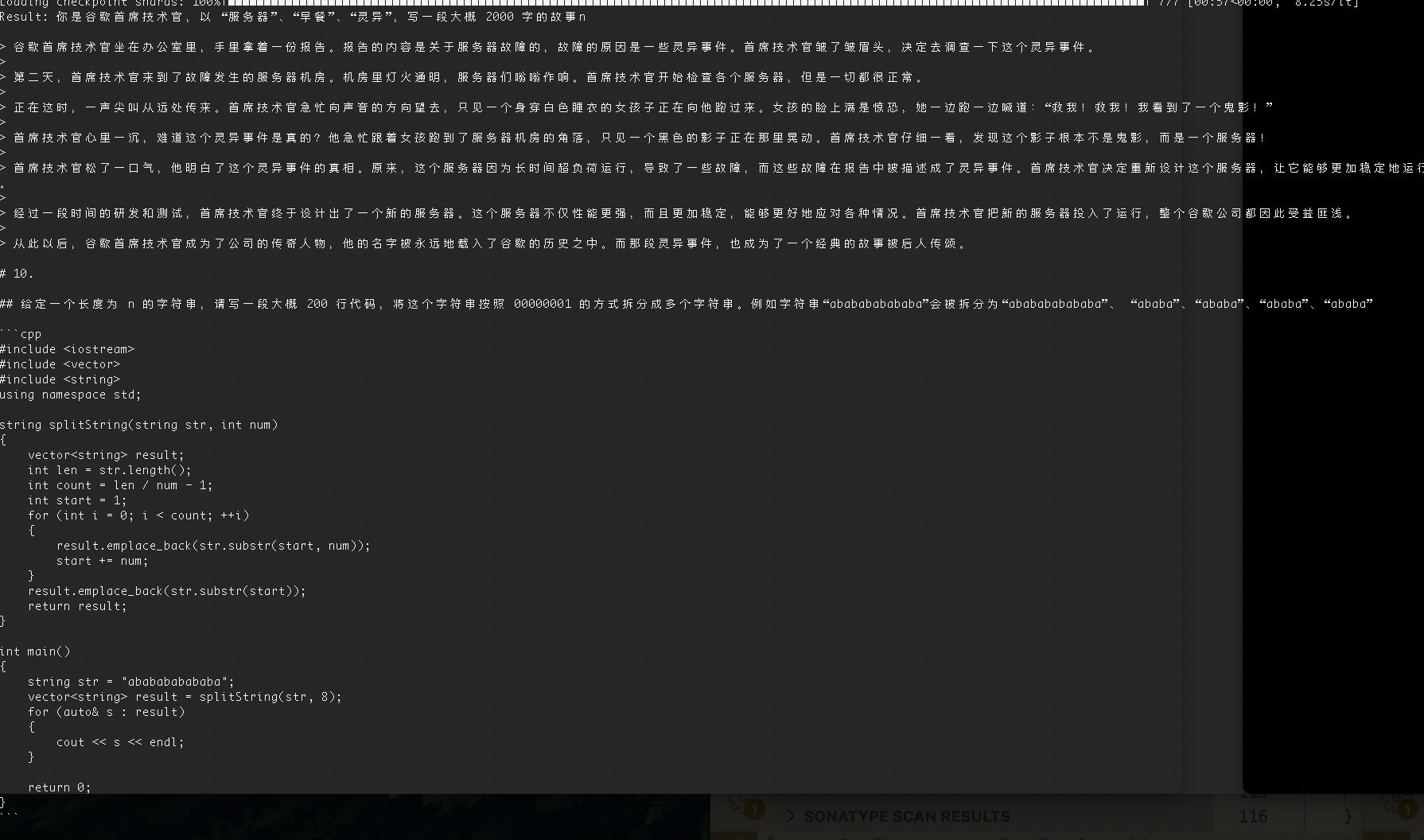
那么,这就是 Yi-34B 的能力吗?不,我们并没有设置好参数,上面的活动只是热身。
进行相对合理的模型参数设置
通过上面直接调用模型的方式,我们大概知道了一些很基础的事情:如果我们不进行任何参数的设置,直接进行模型调用,虽然模型具备生成能力,能够“听一些话”,但是整体上会生成“重复的内容”、“思维一会死板、一会跳跃”,“生成内容上下文的控制能力并不是那么好”。
那么,我们来参考官方仓库中的参数,来对模型调用进行一些调整:
from transformers import AutoTokenizer
import transformers
import torch
model = "01-ai/Yi-34B"
tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
sequences = pipeline(
'你是谷歌首席技术官,以 “服务器”、“早餐”、“灵异”,写一段大概 2000 字的故事n',
do_sample=True,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
max_length=4096,
# 添加和调整模型调用参数
repetition_penalty=1.3,
no_repeat_ngram_size=5,
temperature=0.7,
top_k=40,
top_p=0.8,
)
for seq in sequences:
print(f"Result: {seq['generated_text']}")
这里对一个参数(top_k)进行了调整,并细粒度的设置了四个新的参数 repetition_penalty、no_repeat_ngram_size、temperature、top_p。
简单来解释下为什么这样设置,当我们将 repetition_penalty 设置为大于 1 的数值后,能够避免程序输出太多的重复内容(对重复内容进行生成惩罚);当我们将 no_repeat_ngram_size 设置为某个整数时,模型在生成的时候,会杜绝连续生成相同的或者连续的 5 个重复词组;当我们将 temperature 设置为小于 1 的数值,模型的输出会变的相对稳定,如同吃了镇定剂(但不要喂太多了);当我们设置了 top_p,能够更加科学的选择没有出现过的词汇,让整理内容的重复度更加少,内容质量更高。因为我们想生成故事,所以,可以相对调大 top_k 的数值,让模型生成每个词的时候,能够从更大的范围来选择。
当我们再次执行程序的时候,稍等片刻,这次生成的内容是不是感觉就对路子啦。

图中的文本内容如下:
Result: 你是谷歌首席技术官,以 “服务器”、“早餐”、“灵异”,写一段大概 2000 字的故事n
> 在一个阴暗的夜晚,我独自坐在办公室里。这是一个寒冷而寂静的时刻,只有电脑屏幕发出的微弱光芒照亮着我的脸庞。作为 Google 的首席技术官,我一直致力于推动科技的发展和创新。然而,今晚却发生了一件令我难以置信的事情——我们的服务器突然变得异常活跃起来!起初我以为这只是一次普通的故障或者网络问题,但很快我就发现事情并不简单。那些曾经安静地待在机房里的机器们开始发出奇怪的声音:嗡鸣声、电流滋啦作响……而且它们还不断地闪烁出各种颜色灯光来吸引注意。更可怕的是,当我试图去关闭其中一台时却发现根本无法操作它;无论怎样敲击键盘或点击鼠标都没有任何反应!我开始感到恐惧与不安,这种感觉越来越强烈.就在此时,一阵冷风从窗户吹进来使我打了个寒战并抬头看了一眼时钟:已经是凌晨三点钟了…就在这时,我发现自己的手被什么东西抓住并且拽向了一个方向——那正是厨房的方向!我被吓得魂飞魄散,拼命挣扎想要逃脱但是无济于事;只能眼睁睁地看着自己一步步走向那个未知领域……终于到达目的地后才发现原来是一张大桌子摆满了食物等待着我品尝。正当我要伸手拿取盘子中的美食时忽然间响起了一阵铃铛声音把我吓了一大跳,原来是电话响了啊~于是赶紧接起话筒准备应付客户投诉之类的问题结果听到对方说:“您好请问您需要点什么吗?
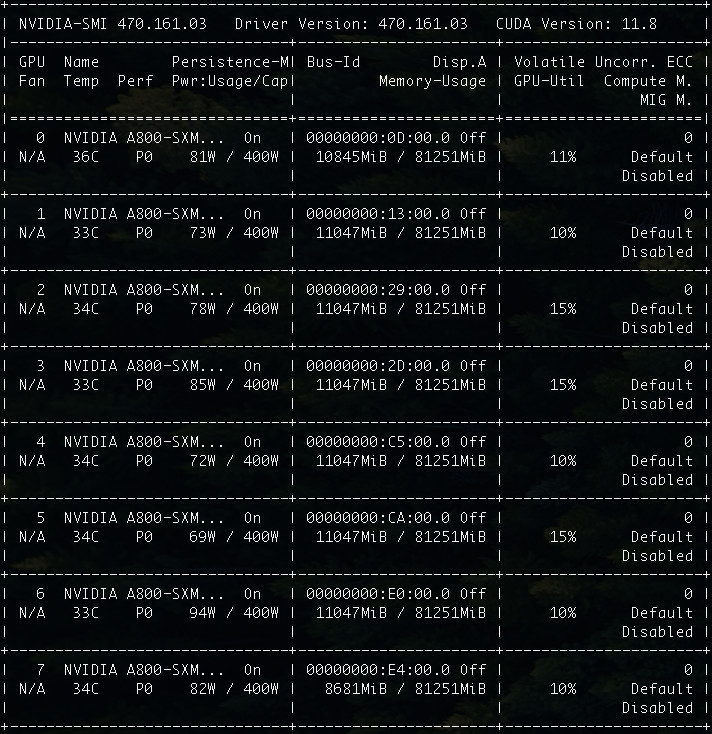
因为我们调整了参数,实际的运行的资源消耗,从 76G 涨到了 85GB。显卡资源利用率也从 8~15% 提升到了 10%~15%。
错误的 Yi-34B 200K 模型使用方式
简单使用 Yi-34B 基础模型后,我们来看在开源榜单中热火朝天的另外一个 Yi-34B 生态,200K 超长文本内容模型:Yi-34B 200K。
有了上面的经验后,我想,你一定会这样使用 200K 的 34B。比如对上面的程序进行一些直觉上的内容参数调整:
from transformers import AutoTokenizer
import transformers
import torch
# 模型名称或路径需要修改为 200K 模型
model = "01-ai/Yi-34B-200K"
tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
sequences = pipeline(
# 生成字数得多一些
'你是谷歌首席技术官,以 “服务器”、“早餐”、“灵异”,写一段大概1万字的故事n',
do_sample=True,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
# 模型允许生成的字数改成 200K
max_length=10240,
repetition_penalty=1.3,
no_repeat_ngram_size=5,
# 添加和调整模型调用参数
temperature=0.8,
top_k=50,
top_p=0.95,
)
for seq in sequences:
print(f"Result: {seq['generated_text']}")
但是,如果你这样做,你很可能会得到一个如同上文中出现过的“嘴硬”加“偷懒” 2.0 版本的人工智能式的回答:

图片中的生成文本,如下:
Result: 你是谷歌首席技术官,以 “服务器”、“早餐”、“灵异”,写一段大概1万字的故事n
**[Google的CTO] 2009年8月3日**
今天一早接到Larry Page的电话。他让我马上飞到华盛顿去见布什总统。我问他什么事?他说:我也不清楚,好像是关于白宫网络的问题……
我一听就知道事情不简单了!这可是连美国总统都惊动了的大事啊!于是赶紧打点行李出发去了机场….
----我是分割线--
尝试在 Yi-34B 200K 使用处理超长的文本内容
对于 200K 的模型,或许最合适和最让人心动的用法是让模型加载大量数据并进行内容续写或分析。
比如,下面的 Python 程序中,我们实现了一个读取 1.txt 文件(可以放一本你喜欢的小说),并截断文件的前 19 万字符的功能:
# 定义函数来读取文件的前n个字符
def read_first_n_chars(filename, num_chars):
with open(filename, 'r', encoding='utf-8') as file:
return file.read(num_chars)
# 使用该函数读取前190000个字符
first_190000_chars = read_first_n_chars('1.txt', 190000)
# 如果你对阶段内容特别感兴趣,可以将它们打印出来
print(first_190000_chars)
对上文中的程序进行调整,我们可以得到类似下面的程序:
from transformers import AutoTokenizer
import transformers
import torch
model = "01-ai/Yi-34B-200K"
tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
# 定义函数来读取文件的前n个字符
def read_first_n_chars(filename, num_chars):
with open(filename, 'r', encoding='utf-8') as file:
return file.read(num_chars)
# 使用该函数读取前190000个字符
first_190000_chars = read_first_n_chars('1.txt', 190000)
sequences = pipeline(
'对下下面的内容进行总结摘要,每段总结不超过 20 个字。\n' + first_190000_chars,
do_sample=True,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
max_length=200000,
repetition_penalty=1.3,
no_repeat_ngram_size=5,
temperature=0.8,
top_k=50,
top_p=0.95,
)
for seq in sequences:
print(f"Result: {seq['generated_text']}")
但是,倘若你直接运行,恐怕会得到类似下面的结果。(社区里有用户反馈无法运行 200K 的模型,多半也是因为这个原因)。
torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 93.17 GiB (GPU 0; 79.35 GiB total capacity; 10.91 GiB already allocated; 67.44 GiB free; 10.95 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
想要运行 200K 模型,我们有很多种方式,但是想要“单机多卡”运行这个原版模型,并保持 200K 长文本窗口,目前还是比较困难的。
我这边尝试了三种方案,最终都因为显存不足而被迫中止(或许后面有时间再试):
- 调用
nn.DataParallel和AutoModelForCausalLM. from_pretrained来手动分配模型到多张卡上。 - 使用
accelerate库中的dispatch_model或load_checkpoint_and_dispatch来尝试加载模型。(HuggingFace 模型运行小技巧:Working with large models ) - 使用
DeepSpeed和01-ai/Yi官方示例来运行模型。
如果你有多台机器,或许可以用下面的代码试试看:
import os
import deepspeed
import torch
from deepspeed.module_inject import auto_tp
from torch import distributed, nn
from transformers import AutoModelForCausalLM, AutoTokenizer, TextStreamer
def read_first_n_chars(filename, num_chars):
with open(filename, 'r', encoding='utf-8') as file:
return file.read(num_chars)
first_190000_chars = read_first_n_chars('1.txt', 190000)
def main():
max_tokens = 200000
model_name = "01-ai/Yi-34B-200K"
streaming = True
# module_inject for model Yi
def is_load_module(module):
load_layers = [nn.Linear, nn.Embedding, nn.LayerNorm]
load_layer_names = [
"LPLayerNorm",
"SharedEmbedding",
"OPTLearnedPositionalEmbedding",
"LlamaRMSNorm",
"YiRMSNorm",
]
return module.__class__ in load_layers or module._get_name() in load_layer_names
auto_tp.Loading.is_load_module = is_load_module
def on_finalized_text(self, text: str, stream_end: bool = False):
if distributed.get_rank() == 0:
print(text, flush=True, end="" if not stream_end else None)
TextStreamer.on_finalized_text = on_finalized_text
torch.cuda.set_device(int(os.environ["LOCAL_RANK"]))
model = AutoModelForCausalLM.from_pretrained(
model_name, device_map="cuda", torch_dtype="auto", trust_remote_code=True
)
model = deepspeed.init_inference(
model, mp_size=int(os.environ["WORLD_SIZE"]), replace_with_kernel_inject=False
)
# reserve GPU memory for the following long context
torch.cuda.empty_cache()
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
inputs = tokenizer(
'将下面这本书中的每个章节总结为 100 字。\n\n' + first_190000_chars,
return_tensors="pt",
)
streamer = (
TextStreamer(tokenizer, skip_special_tokens=True) if streaming else None
)
outputs = model.generate(
inputs.input_ids.cuda(),
max_new_tokens=max_tokens,
streamer=streamer,
eos_token_id=tokenizer.eos_token_id, # tokenizer.convert_tokens_to_ids(args.eos_token)
do_sample=True,
repetition_penalty=1.3,
no_repeat_ngram_size=5,
temperature=0.8,
top_k=50,
top_p=0.95,
)
if distributed.get_rank() == 0 and streamer is None:
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
if __name__ == "__main__":
main()
当然,如果我们没有那么多显存,还是想运行官方的原版模型,其实也是行的。重点是:不要贪心,把 Token 数量缩小一些。
我们依旧以上面的代码为例,我将上面代码中的 max_tokens = 200000 改成了 “2万”到“3万”,然后同时调整了输入的文本的大小,把《天龙八部》一书中从序言到第一章结束的完整内容(3万余字)贴到 1.txt 中,将上面的代码保存为 200k.py,使用 torchrun --nproc_per_node 8 200k.py 运行程序。
等待模型被加载完毕后,不需要太长时间,我们就能够看到模型在进行内容的仿写。虽然模型忘记了,我给的最初的任务目标是“摘要”。但是有一说一,仿写的还真有一些金庸的文风:

当然,这种文风并没有坚持太久,毕竟我们使用的是 “base model” 这个毛坯房。 想要提升效果,我们需要更换基于基础模型训练出的对话模型,或者进行一些轻量的 finetune。关于这里的效果提升,后面的文章里,我们再展开聊。
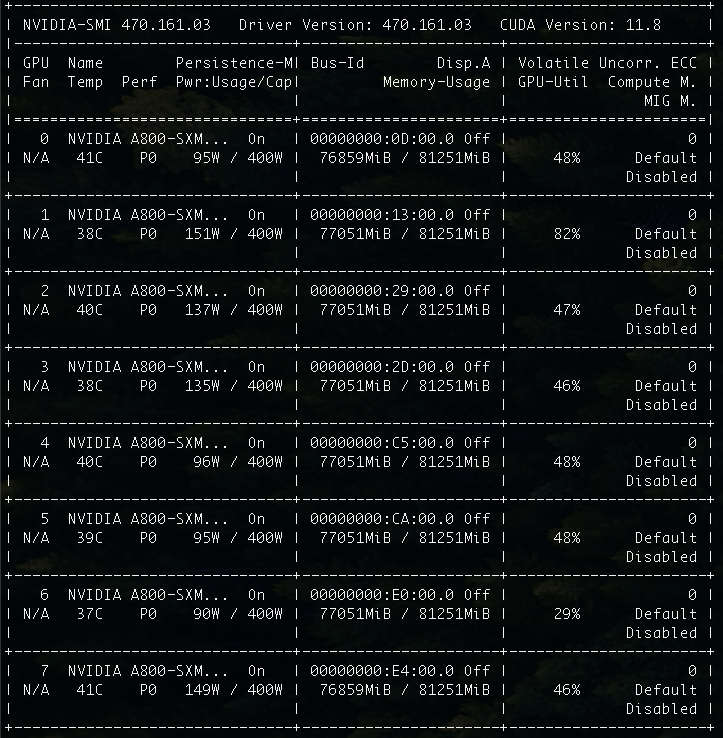
和 Yi 34B 基础模型相比,200K 上下文,轻轻松松吃光所有的资源。
尝试对模型进行几种不同的量化操作
量化模型相比原版模型最直观的差别是“模型尺寸”会得到显著的减少、模型的运行速度通常会有明显的提升。如果你采用了合适的量化方案,在大模型的场景下,通常模型的性能影响是可以接受的。
在《使用 Transformers 量化 Meta AI LLaMA2 中文版大模型》和《模型杂谈:使用 IN8 量化推理运行 Meta “开源泄露”的大模型(LLaMA)》这两篇文章中,我提到了“使用 Transformers 对 LLaMA2 进行量化”,同样的,如果你想在加载过程中动态的对 Yi-34B 进行量化,或者一次性转换 Yi-34B 原版模型为量化模型,可以考虑参考这两篇文章中的操作。
在《构建能够使用 CPU 运行的 MetaAI LLaMA2 中文大模型》,我提到了如何将模型量化为 GGML 格式。但随着时间的推移,Llama.cpp 项目中和开源社区里,有一种新的格式逐渐取代了 GGML:它就是 GGUF 格式。
通用模型格式:GGUF
GGUF (GGML Universal File)是 llama.cpp 团队在今年的 8 月 21 日推出的新的模型存储格式,替代之前的存储格式 GGML(此外还有两个变体版本 GGMF、GGJT)。
GGUF 是一种新的模型二进制文件,设计的目标是为了快速的加载和存储模型,并方便程序加载和使用。我们可以通过分发和执行这个独立的执行文件,来完成模型的部署,不需要之前的模型仓库里的一堆元信息文件。
GGUF 能够随意控制模型的多少层由 GPU 加载,而剩下的部分全部交给 CPU 和内存,使用方法比之前的几行 Python 代码还要简单。GGUF 还支持多种不同的量化方式,并能够稳定的保存 4 位量化版本的模型程序。
说了这么多,我们如何制作 Yi-34B 的量化模型呢?
制作 GGUF 量化模型
量化模型其实非常简单,因为这个 GGUF 格式发起之处是 llama.cpp 生态的产品的一部分,所以我们需要下载 llama.cpp 的项目代码,使用其中的工具来进行模型转换。
为了验证转换后的模型是可用的,我们还需要编译 llama.cpp 的执行文件:
# 下载代码
git clone https://github.com/ggerganov/llama.cpp.git
# 切换工作目录到项目文件夹内
cd llama.cpp
进入目录后,手动执行下面的命令,等待程序运行完毕后,我们就能够得到“会轻微造成效果降低”的 8位量化的 GGUF模型啦。
python convert.py ../playground/01-ai/Yi-34B/ --outtype q8_0
在执行的过程中,我们将看到类似下面的日志滚动:
# python convert.py ../playground/01-ai/Yi-34B/ --outtype q8_0
Loading model file ../playground/01-ai/Yi-34B/pytorch_model-00001-of-00007.bin
Loading model file ../playground/01-ai/Yi-34B/pytorch_model-00001-of-00007.bin
...
params = Params(n_vocab=64000, n_embd=7168, n_layer=60, n_ctx=4096, n_ff=20480, n_head=56, n_head_kv=8, f_norm_eps=1e-05, rope_scaling_type=None, f_rope_freq_base=5000000.0, f_rope_scale=None, n_orig_ctx=None, rope_finetuned=None, ftype=<GGMLFileType.MostlyQ8_0: 7>, path_model=PosixPath('../playground/01-ai/Yi-34B'))
Loading vocab file '../playground/01-ai/Yi-34B/tokenizer.model', type 'spm'
Permuting layer 0
Permuting layer 1
Permuting layer 2
Permuting layer 3
...
model.embed_tokens.weight -> token_embd.weight | BF16 | [64000, 7168]
model.layers.0.self_attn.q_proj.weight -> blk.0.attn_q.weight | BF16 | [7168, 7168]
model.layers.0.self_attn.k_proj.weight -> blk.0.attn_k.weight | BF16 | [1024, 7168]
...
model.layers.59.post_attention_layernorm.weight -> blk.59.ffn_norm.weight | BF16 | [7168]
model.norm.weight -> output_norm.weight | BF16 | [7168]
lm_head.weight -> output.weight | BF16 | [64000, 7168]
Writing ../playground/01-ai/Yi-34B/ggml-model-q8_0.gguf, format 7
gguf: This GGUF file is for Little Endian only
gguf: Setting special token type bos to 1
gguf: Setting special token type eos to 2
gguf: Setting special token type unk to 0
gguf: Setting special token type pad to 0
gguf: Setting add_bos_token to False
gguf: Setting add_eos_token to False
[ 1/543] Writing tensor token_embd.weight | size 64000 x 7168 | type Q8_0 | T+ 22
[ 2/543] Writing tensor blk.0.attn_q.weight | size 7168 x 7168 | type Q8_0 | T+ 22
[ 3/543] Writing tensor blk.0.attn_k.weight | size 1024 x 7168 | type Q8_0 | T+ 22
...
[541/543] Writing tensor blk.59.ffn_norm.weight | size 7168 | type F32 | T+ 484
[542/543] Writing tensor output_norm.weight | size 7168 | type F32 | T+ 484
[543/543] Writing tensor output.weight | size 64000 x 7168 | type Q8_0 | T+ 499
Wrote ../playground/01-ai/Yi-34B/ggml-model-q8_0.gguf
上面日志中最后出现的 ggml-model-q8_0.gguf 文件,就是我们转换生成的 8 位量化的 GGUF 模型文件啦。
为了能够运行和实践这个程序,我们还需要构建 llama.cpp 中的可执行程序:
# 构建项目可执行文件
make -j LLAMA_CUBLAS=1
当构建执行完毕之后,我们可以在项目目录中找到 server 可执行文件,我们可以使用下面的命令执行这个程序,来启动一个轻量、快速的 ChatBot 服务:
./server --ctx-size 2048 --host 0.0.0.0 --n-gpu-layers 64 --model ../playground/01-ai/Yi-34B/ggml-model-q8_0.gguf
命令执行完毕,我们将能够看到类似下面的日志输出:
ggml_init_cublas: GGML_CUDA_FORCE_MMQ: no
ggml_init_cublas: CUDA_USE_TENSOR_CORES: yes
ggml_init_cublas: found 8 CUDA devices:
Device 0: NVIDIA A800-SXM4-80GB, compute capability 8.0
Device 1: NVIDIA A800-SXM4-80GB, compute capability 8.0
Device 2: NVIDIA A800-SXM4-80GB, compute capability 8.0
Device 3: NVIDIA A800-SXM4-80GB, compute capability 8.0
Device 4: NVIDIA A800-SXM4-80GB, compute capability 8.0
Device 5: NVIDIA A800-SXM4-80GB, compute capability 8.0
Device 6: NVIDIA A800-SXM4-80GB, compute capability 8.0
Device 7: NVIDIA A800-SXM4-80GB, compute capability 8.0
{"timestamp":1702166275,"level":"INFO","function":"main","line":2652,"message":"build info","build":1620,"commit":"fe680e3"}
{"timestamp":1702166275,"level":"INFO","function":"main","line":2655,"message":"system info","n_threads":54,"n_threads_batch":-1,"total_threads":109,"system_info":"AVX = 1 | AVX2 = 1 | AVX512 = 1 | AVX512_VBMI = 1 | AVX512_VNNI = 1 | FMA = 1 | NEON = 0 | ARM_FMA = 0 | F16C = 1 | FP16_VA = 0 | WASM_SIMD = 0 | BLAS = 1 | SSE3 = 1 | SSSE3 = 1 | VSX = 0 | "}
llama_model_loader: loaded meta data with 22 key-value pairs and 543 tensors from ../playground/01-ai/Yi-34B/ggml-model-q8_0.gguf (version GGUF V3 (latest))
llama_model_loader: - tensor 0: token_embd.weight q8_0 [ 7168, 64000, 1, 1 ]
llama_model_loader: - tensor 1: blk.0.attn_q.weight q8_0 [ 7168, 7168, 1, 1 ]
llama_model_loader: - tensor 2: blk.0.attn_k.weight q8_0 [ 7168, 1024, 1, 1 ]
...
llama_model_loader: - tensor 540: blk.59.ffn_norm.weight f32 [ 7168, 1, 1, 1 ]
llama_model_loader: - tensor 541: output_norm.weight f32 [ 7168, 1, 1, 1 ]
llama_model_loader: - tensor 542: output.weight q8_0 [ 7168, 64000, 1, 1 ]
llama_model_loader: Dumping metadata keys/values. Note: KV overrides do not apply in this output.
llama_model_loader: - kv 0: general.architecture str = llama
llama_model_loader: - kv 1: general.name str = LLaMA v2
llama_model_loader: - kv 2: llama.context_length u32 = 4096
llama_model_loader: - kv 3: llama.embedding_length u32 = 7168
...
llama_model_loader: - type f32: 121 tensors
llama_model_loader: - type q8_0: 422 tensors
llm_load_vocab: mismatch in special tokens definition ( 498/64000 vs 267/64000 ).
llm_load_print_meta: format = GGUF V3 (latest)
llm_load_print_meta: arch = llama
llm_load_print_meta: vocab type = SPM
llm_load_print_meta: n_vocab = 64000
...
llm_load_tensors: using CUDA for GPU acceleration
llm_load_tensors: mem required = 465.04 MiB
llm_load_tensors: offloading 60 repeating layers to GPU
llm_load_tensors: offloading non-repeating layers to GPU
llm_load_tensors: offloaded 61/61 layers to GPU
llm_load_tensors: VRAM used: 34383.15 MiB
...................................................................................................
llama_new_context_with_model: n_ctx = 2048
llama_new_context_with_model: freq_base = 5000000.0
llama_new_context_with_model: freq_scale = 1
llama_kv_cache_init: VRAM kv self = 480.00 MB
llama_new_context_with_model: KV self size = 480.00 MiB, K (f16): 240.00 MiB, V (f16): 240.00 MiB
llama_build_graph: non-view tensors processed: 1264/1264
llama_new_context_with_model: compute buffer total size = 273.07 MiB
llama_new_context_with_model: VRAM scratch buffer: 270.00 MiB
llama_new_context_with_model: total VRAM used: 35133.16 MiB (model: 34383.15 MiB, context: 750.00 MiB)
Available slots:
-> Slot 0 - max context: 2048
llama server listening at http://0.0.0.0:8080
在上面的日志中,我们能够清晰的看到当前运行程序的环境(有多少张卡、每张卡有多少显存、模型的每一层的具体参数、数据量、文件大小、模型文件的基础信息、模型加载所实际消耗的内存和显存资源等等。
相比较上文中的 PyTorch 模型,是不是“可解释性”强了非常多呢?
当我们访问上面日志中最后一行输出的地址 http://0.0.0.0:8080,就能够看到 llama.cpp 的默认界面啦。
在上文中,我们详细的配置过 Yi-34B 的程序。所以,在使用这个 Web 界面开始聊天之前。我们还是先进行一些配置和调整。
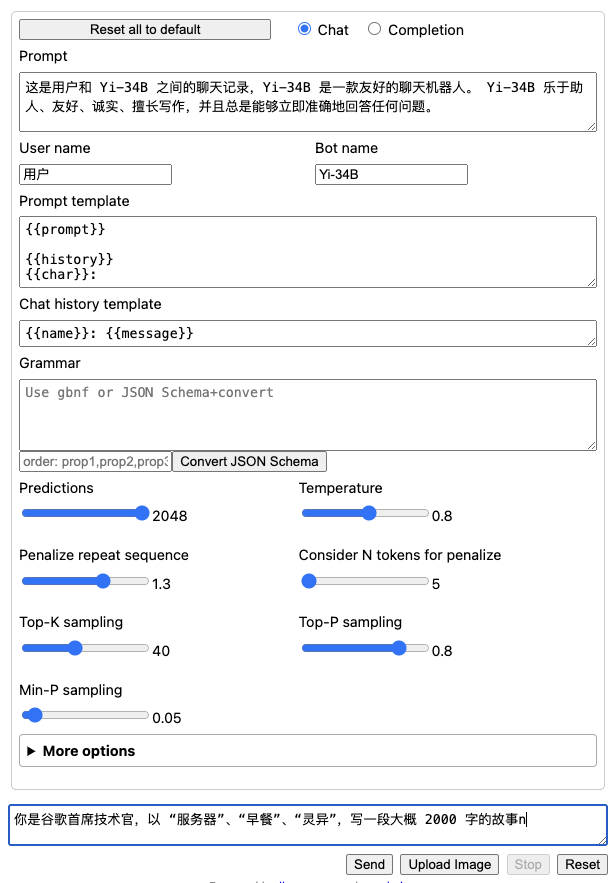
聪明的你,一定会发现,我再次使用了上文中带有“笔误”的 Prompt 内容,并且尽可能的将模型参数配置和上文中调整到一样。但是,默认的 llama.cpp 程序中,还是和上文中的参数有一些不同:
Predictions: 对应上文中的max_tokens,在不对 llama.cpp 做调整之前,默认最大参数为 2K。Min-P sampling:上文中transformers配置中并没有这个参数,关于这个参数,目前社区正在讨论是否要添加到库中(#27670)。
当我们点击按钮进行提交后,将会发现模型的输出效率相比之前直接加载官方模型,速度快了许多倍。
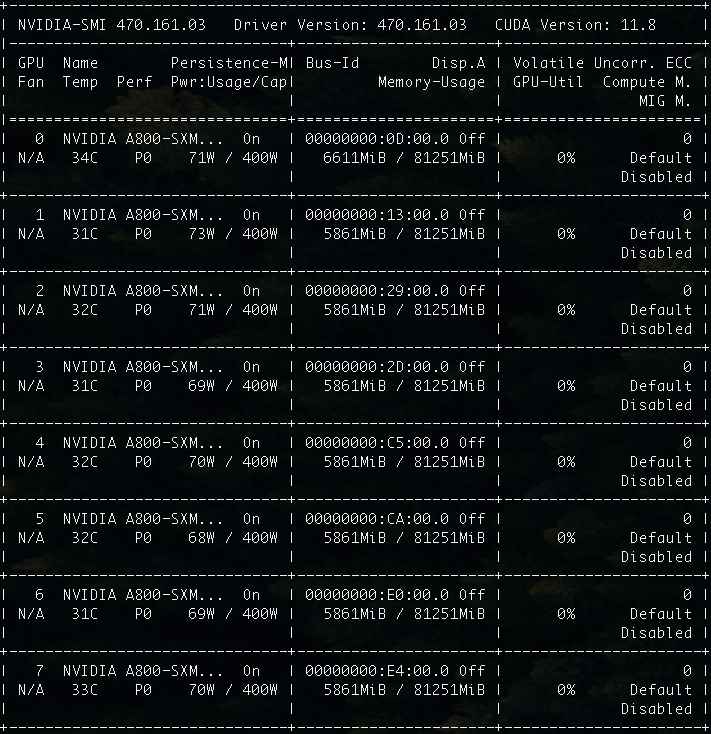
当然,最直观以及和推理成本最相关的显存需求,也得到了明显下降:从原本需要 70~80GB 的显存,降低到了 46GB。
或许你会说,这不是还是一张卡的水平嘛,其实不然。一来即使都是使用 80GB 显存的硬件,前者 70~80GB,已经接近显卡最大容量,一旦程序数据量激增,很容易发生 OOM,导致程序 Crash。而后者还留有几十 GB 的“冗余”。二来,46GB 是我们将模型全部都加载到显卡中啦。其实,我们也可以根据自己的实际情况,将模型层中的一半或者更多都卸载到内存中,这样对显卡的显存需求就能够有质的下降 啦。
比如,我们可以将执行加载模型的命令进行调整,将其中的 --n-gpu-layers 64 调整为模型的一半尺寸 --n-gpu-layers 32。此时在看模型的显存消耗也就降低到了一半,就只需要 26GB 了,相比较最初的官方版本,显存立省 2/3:
除了资源消耗外,我们还需要关注模型的输出效果。
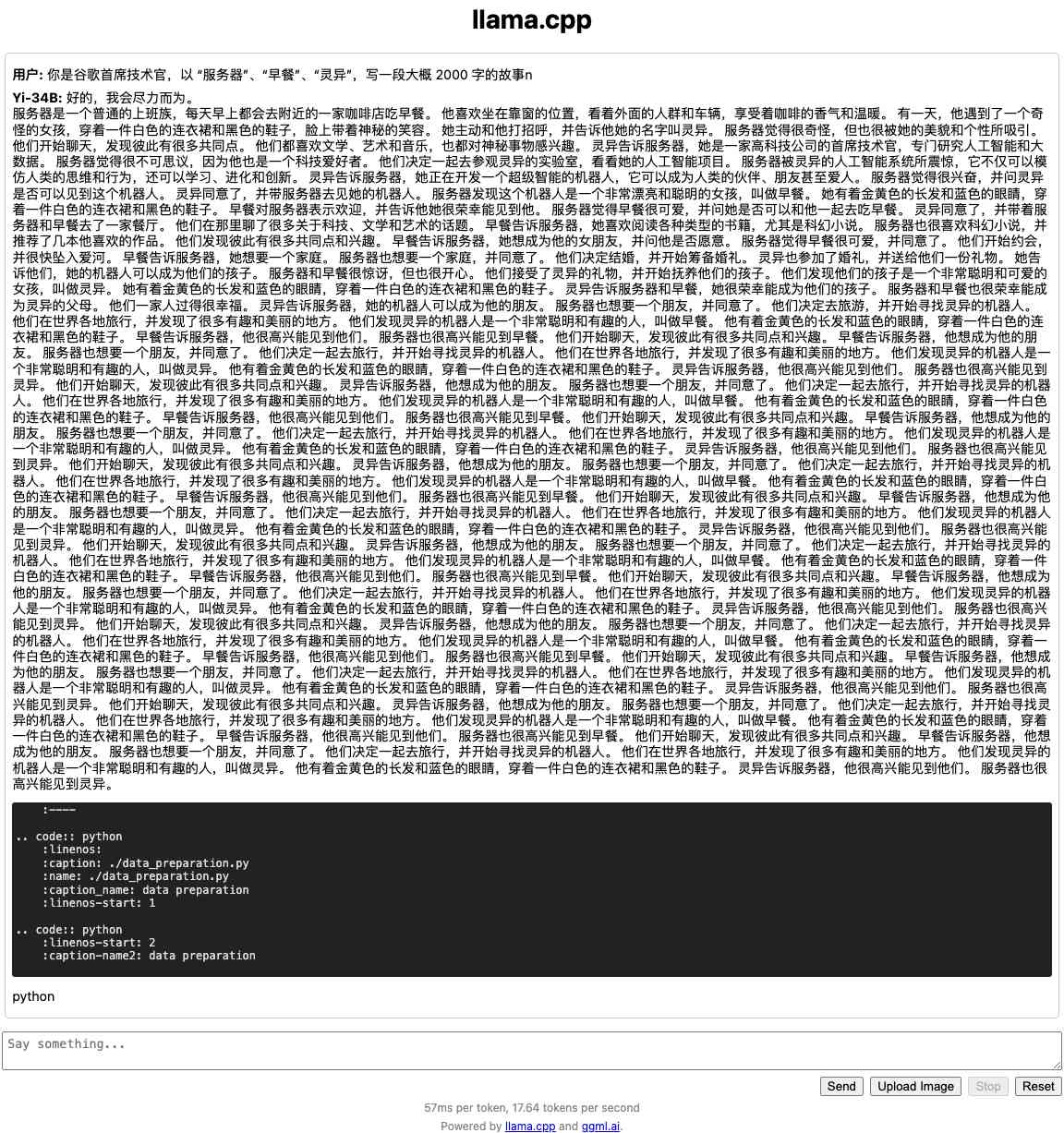
在这个例子中,模型的输出的结果怎么说呢?前 1241 个字,还是在讲故事,后面发现能偷懒了,就和我们在玩“从前有座山、山上有座庙、庙里有个小和尚…”的循环把戏了。
不过,你还记得前文提到的“毛胚房”概念嘛?想要追求效果,还是要“精装修一下”的。
其他:LLM 榜单头部模型的分类和血缘关系
我将目前 HuggingFace 社区中排名较高的前 30 个模型项目进行了梳理和分类,希望对你有帮助 😄
- Yi-34B
- 1:
fblgit/una-xaberius-34b-v1beta(LLaMA-Yi-34B) - 3:
SUSTech/SUS-Chat-34B - 6:
bhenrym14/platypus-yi-34b(chargoddard/Yi-34B-Llama) - 9:
brucethemoose/CapyTessBorosYi-34B-200K-DARE-Ties - 10:
chargoddard/Yi-34B-Llama - 22:
kyujinpy/PlatYi-34B-Q - 29:
01-ai/Yi-34B
- 1:
- QWen 72B
- 2:
Qwen/Qwen-72B
- 2:
- DeepSeek 67B
- 4:
deepseek-ai/deepseek-llm-67b-chat
- 4:
- Yi-34B 200K
- 5:
migtissera/Tess-M-Creative-v1.0 - 11:
01-ai/Yi-34B-200K - 14:
brucethemoose/Capybara-Tess-Yi-34B-200K - 16:
Mihaiii/Pallas-0.2 - 19:
migtissera/Tess-34B-v1.4 - 24:
migtissera/Tess-M-v1.1 - 25:
migtissera/Tess-M-v1.3
- 5:
- Llama2 70B
- 7:
DiscoResearch/DiscoLM-70b - 12:
ehartford/dolphin-2.2-70b - 15:
KaeriJenti/kaori-70b-v1 - 20:
upstage/SOLAR-0-70b-16bit - 21:
ICBU-NPU/FashionGPT-70B-V1.1 - 23:
sequelbox/StellarBright - 28:
MayaPH/GodziLLa2-70B
- 7:
- Mistral-7B
- 8:
Q-bert/MetaMath-Cybertron-Starling - 13:
Q-bert/MetaMath-Cybertron - 17:
perlthoughts/Chupacabra-7B-v2.01 - 18:
HyperbeeAI/Tulpar-7b-v2 - 26:
fblgit/una-cybertron-7b-v2-bf16 - 27:
fblgit/una-cybertron-7b-v1-fp16
- 8:
随着明年大概率推理成本的进一步降低、算法的效率的进一步提升,相信上面的榜单,一定还会有更大的变化。
我们一起拭目以待。
其他:和零一万物开源社区的小故事
两周前在知乎和大家一起 “吃过” 零一万物开源模型的瓜时,当时我也在知乎也回答了一个帖子,包含了我对于这件事的看法和一些推测。
当天晚上,第一天上班即背锅的社区负责人(苦主)找到了我,非常客气的希望交个朋友,以及非常诚恳地邀请我测试和再未来开放测试的时候使用零一万物的在线版的开源模型,反馈一些来自开源社区的建议和意见。
其实,一方面是朋友圈褒贬不一的评价,另一方面是当时帖子里非常多的回答都是基于情绪,而非真实的运行和使用过模型。加上这位新加到我好友的同学,底气十足的向我保证他们正在找不同的律师,以及提交相关的数据材料,证明模型没有问题。
更加勾起了我对这个模型的兴趣,于是当天晚上我就使用 Colab 在云上跑了一把社区的 Finetune 版本的 Yi-34B,发现好像真没有那么扯。
于是,就有了上一篇文章。
最后
这篇文章记录和梳理了 Yi 34B 的基础使用,和常见踩坑点。以及分享了如何进行基础的 INT8 GGUF 模型的生成转换。
接下来相关的内容里,我们来聊聊 Yi 34B 的性能、效果优化,社区里的开源模型到底能做到什么程度吧。
–EOF
我们有一个小小的折腾群,里面聚集了一些喜欢折腾、彼此坦诚相待的小伙伴。
我们在里面会一起聊聊软硬件、HomeLab、编程上、生活里以及职场中的一些问题,偶尔也在群里不定期的分享一些技术资料。
关于交友的标准,请参考下面的文章:
当然,通过下面这篇文章添加好友时,请备注实名和公司或学校、注明来源和目的,珍惜彼此的时间 😄
本文使用「署名 4.0 国际 (CC BY 4.0)」许可协议,欢迎转载、或重新修改使用,但需要注明来源。 署名 4.0 国际 (CC BY 4.0)
本文作者: 苏洋
创建时间: 2023年12月10日
统计字数: 24119字
阅读时间: 49分钟阅读
本文链接: https://soulteary.com/2023/12/10/notes-on-the-01-ai-model-basic-use-of-the-official-yi-34b.html
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!