python:最简单爬虫之爬取小说网Hello wrold
以下用最简单的示例来演示爬取某小说网的类目名称。
新建一个retest.py,全文代码如下,读者可以复制后直接运行。代码中我尽量添加了一些注释便于理解。
需要说明的一点,该小说网站如果后续更新改版了,文中截取字符的正则表达式可能需要根据做一些变动,才能成功爬取到我们想要的名称。
一、小说网站首页
我们想爬取的是首页-》全部分类 菜单下的小说分类名称

二、retest.py代码
# -*- coding: UTF-8 -*-
import re
import urllib.request
import codecs
import time
# 使用re 与 urllib 包简单爬取小说种类名称
class Retest(object):
def __init__(self):
self.getText()
# 爬取方法
def getText(self):
print("准备开始爬取")
# 请求网站首页,获取页面返回内容
url = "https://www.readnovel.com"
response = urllib.request.urlopen(url, timeout=5)
result = response.read().decode('utf-8') #使用utf-8 避免中文乱码
print(result) #网页内容
# 网页中的原字符串
# '<dd><a href="/category/30020_f1_f1_f1_f1_f1_0_1"><em class="iconfont"></em><i>现代言情</i></a></dd>'
# 通过正则表达式与固定字符组合,过滤后得到新字符串
pr = '<dd><a href="/category/.*?_f1_f1_f1_f1_f1_0_1"><em class="iconfont">.*?;</em><i>.*?</i></a></dd>'
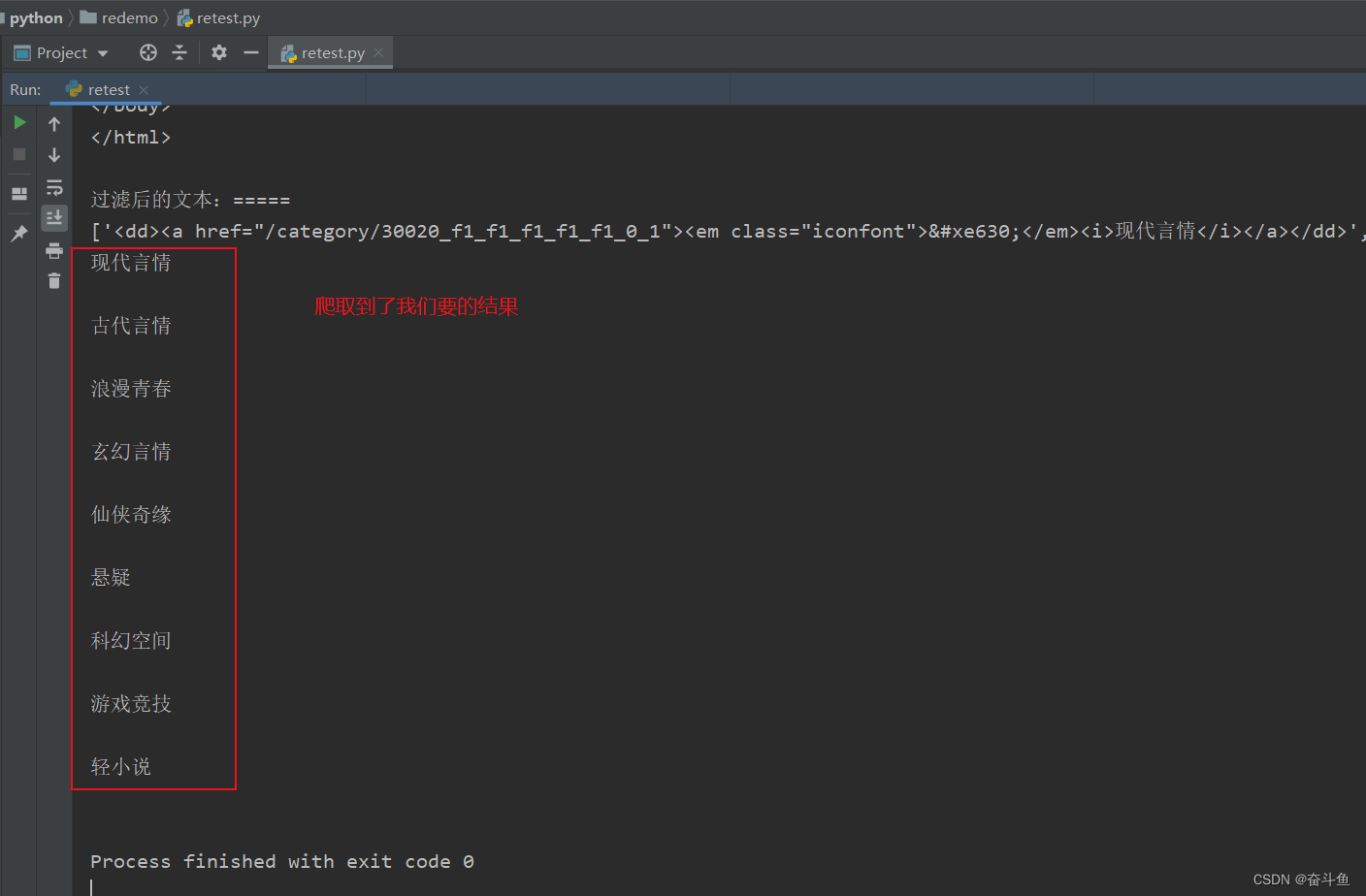
print("过滤后的文本:=====")
pattern = re.compile(pr) #将正则表达式编译为正则对象
movieList = pattern.findall(result) #通过正则表达式从源字符串中截取,得到一个movieList数组
print(movieList)
# 使用map函数,将movieList数组中各元素,通过lambda匿名函数内的方法,过滤掉其他标签字符,仅保留我们需要的类目中文标题如“现代言情”
moveTitleList = map(lambda x: x.split("<i>")[1].split("</i>")[0], movieList)
# 最后,依次打印出各类目名称
for movie in moveTitleList:
print("%s\r\n" % movie)
if __name__ == '__main__':
Retest()
三、运行后结果
四、分析说明
下面结合上述代码再做一些补充说明,便于我们初学者更易于理解。
1.查找关键字,正则表达式获取字符串
我们在网站首页,查看前端页面源代码,并查找到关键字
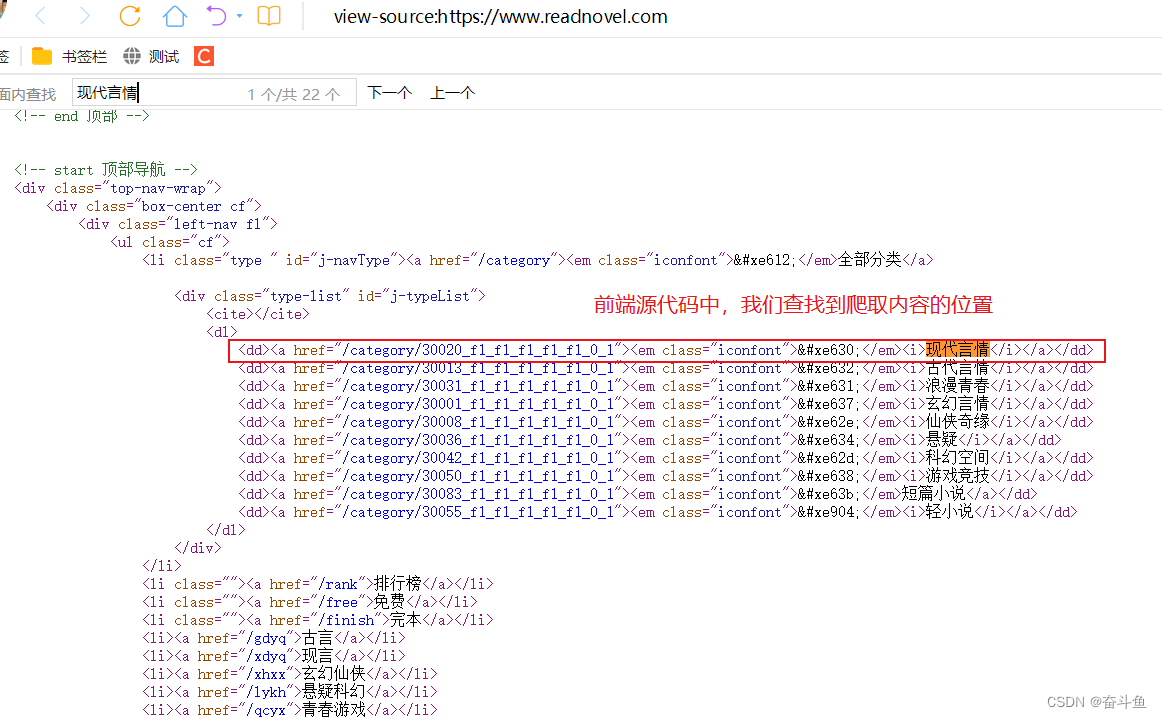
红线标注的就是我们需要通过正则表达式从全文中定位并截取的字符串。
<dd><a href="/category/30020_f1_f1_f1_f1_f1_0_1"><em class="iconfont"></em><i>现代言情</i></a></dd> <dd><a href="/category/30013_f1_f1_f1_f1_f1_0_1"><em class="iconfont"></em><i>古代言情</i></a></dd>
对应的正则表达式如下:
<dd><a href="/category/.*?_f1_f1_f1_f1_f1_0_1"><em class="iconfont">.*?;</em><i>.*?</i></a></dd>
我们只需要将固定不变的关键字符串与可变的组合在一起即可。
“30020”、“”、“现代言情”这三个是动态的,我们用“.*?”代替,代表任意字符串。然后通过pattern.findall得到一个movieList数组,数组内的成员如下。
[
'<dd><a href="/category/30020_f1_f1_f1_f1_f1_0_1"><em class="iconfont"></em><i>现代言情</i></a></dd>',
'<dd><a href="/category/30013_f1_f1_f1_f1_f1_0_1"><em class="iconfont"></em><i>古代言情</i></a></dd>',
'<dd><a href="/category/30031_f1_f1_f1_f1_f1_0_1"><em class="iconfont"></em><i>浪漫青春</i></a></dd>',
'<dd><a href="/category/30001_f1_f1_f1_f1_f1_0_1"><em class="iconfont"></em><i>玄幻言情</i></a></dd>',
'<dd><a href="/category/30008_f1_f1_f1_f1_f1_0_1"><em class="iconfont"></em><i>仙侠奇缘</i></a></dd>',
'<dd><a href="/category/30036_f1_f1_f1_f1_f1_0_1"><em class="iconfont"></em><i>悬疑</i></a></dd>',
'<dd><a href="/category/30042_f1_f1_f1_f1_f1_0_1"><em class="iconfont"></em><i>科幻空间</i></a></dd>',
'<dd><a href="/category/30050_f1_f1_f1_f1_f1_0_1"><em class="iconfont"></em><i>游戏竞技</i></a></dd>',
'<dd><a href="/category/30055_f1_f1_f1_f1_f1_0_1"><em class="iconfont"></em><i>轻小说</i></a></dd>'
]
2.二次过滤
我们仅需要类目中文名称,所有需要对得到的数据做二次过滤。
moveTitleList = map(lambda x: x.split("<i>")[1].split("</i>")[0], movieList)
map可以从movieList数组中逐个成员进行函数处理。而我们这里使用lambda定义了一个匿名函数
lambda x: x.split("<i>")[1].split("</i>")[0],意思是在成员中获取“<i>”第二个元素,再获取"</i>"第一个元素。即<dd><a href="/category/30020_f1_f1_f1_f1_f1_0_1"><em class="iconfont"></em><i>现代言情</i></a></dd>,最终可以获取到“现代言情”这几个字。
3.尾声
以上演示了如何爬取网页中的某一组数据,读者掌握理解后,可以自己尝试爬取其他数据,如推荐栏目下的书名清单等。
如果我的文章解决了你的问题,欢迎点赞、收藏或评论。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!