DPO讲解
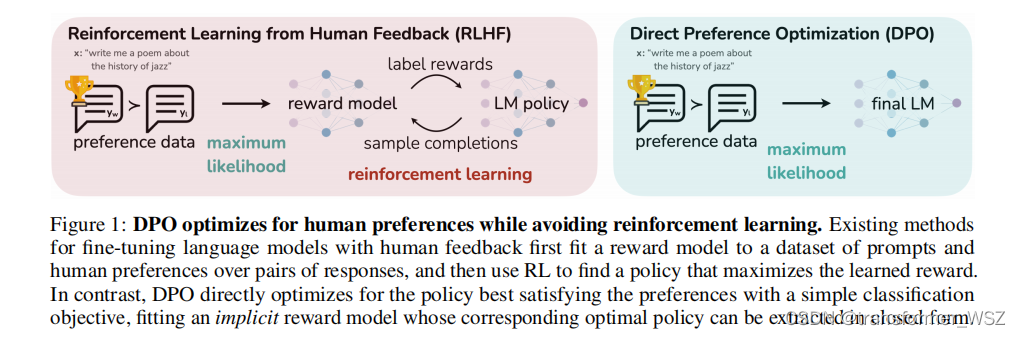
PPO算法的pipeline冗长,涉及模型多,资源消耗大,且训练极其不稳定。DPO是斯坦福团队基于PPO推导出的优化算法,去掉了RW训练和RL环节,只需要加载一个推理模型和一个训练模型,直接在偏好数据上进行训练即可:
损失函数如下:
L
D
P
O
(
π
θ
;
π
r
e
f
)
=
?
E
(
x
,
y
w
,
y
l
)
~
D
[
log
?
σ
(
β
log
?
π
θ
(
y
w
∣
x
)
π
r
e
f
(
y
w
∣
x
)
?
β
log
?
π
θ
(
y
l
∣
x
)
π
r
e
f
(
y
l
∣
x
)
)
]
\mathcal{L}_{\mathrm{DPO}}\left(\pi_\theta ; \pi_{\mathrm{ref}}\right)=-\mathbb{E}_{\left(x, y_w, y_l\right) \sim \mathcal{D}}\left[\log \sigma\left(\beta \log \frac{\pi_\theta\left(y_w \mid x\right)}{\pi_{\mathrm{ref}}\left(y_w \mid x\right)}-\beta \log \frac{\pi_\theta\left(y_l \mid x\right)}{\pi_{\mathrm{ref}}\left(y_l \mid x\right)}\right)\right]
LDPO?(πθ?;πref?)=?E(x,yw?,yl?)~D?[logσ(βlogπref?(yw?∣x)πθ?(yw?∣x)??βlogπref?(yl?∣x)πθ?(yl?∣x)?)]
DPO在理解难度、实现难度和资源占用都非常友好,想看具体的公式推导见:
[论文笔记]DPO:Direct Preference Optimization: Your Language Model is Secretly a Reward Model
参考
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!