CUDA 学习记录2
1.是否启用一级缓存有什么影响:
启用一级缓存(缓存加载操作经过一级缓存):一次内存十五操作以128字节的粒度进行。
不启用一级缓存(没有缓存的加载不经过一级缓存):在内存段的粒度上(32字节)而不是缓存池的粒度(128字节)执行。更细粒度的加载,可以为非对其或非合并的内存访问带来更好的总线利用率(可能不会减少整体加载时间)。
2.GPU一级缓存没有时间局部性?
那新数据来的时候怎么判断放在哪里?
3. cuda只读缓存?
4.偏向于结构体数组
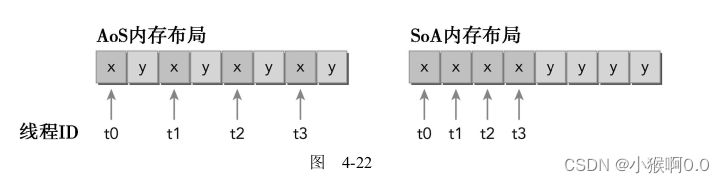
内存事务的优化关键:用最少的事务次数满足最多的内存请求。?
5.优化设备内存带宽利用率有两个目标:
? ? ? ? 1.对齐及合并内存访问,以减少带宽的浪费。
? ? ? ? ? ? ? ? 对齐:访问的第一个地址是32的倍数。合并:访问连续的数据块。
? ? ? ? 2.足够的并发内存操作,以隐藏内存延迟。(展开,修改核函数启动配置)
? ? ? ? ? ? ? ? 1.增加每个线程中执行独立内存操作的数量
? ? ? ? ? ? ? ? 2.对核函数启动的执行配置进行实验,以充分体现每个SM的并行性。
6.为什么矩阵转置按列读取按行存储性能比按行读取按列存储好:
参考:【CUDA 基础】4.4 核函数可达到的带宽 | 谭升的博客
?最初的想法肯定是:按照图一合并读更有效率,因为写的时候不需要经过一级缓存,所以对于有一级缓存的程序,合并的读取应该是更有效率的。如果你这么想,恭喜你,你想的不对(我当时也是这么想的)。
我们需要补充下关于一级缓存的作用,上文我们讲到合并,可能第一印象就是一级缓存是缓冲从全局内存里过来的数据一样,但是我们忽略了一些东西,就是内存发起加载请求的时候,会现在一级缓存里看看有没有这个数据,如果有,这个就是一个命中,这和CPU的缓存运行原理是一样的,如果命中了,就不需要再去全局内存读了,如果用在上面这个例子,虽然按照列读是不合并的,但是使用一级缓存加载过来的数据在后面会被使用,我们必须要注意虽然,一级缓存一次读取128字节的数据,其中只有一个单位是有用的,但是剩下的并不会被马上覆盖,粒度是128字节,但是一级缓存的大小有几k或是更大,这些数据很有可能不会被替换,所以,我们按列读取数据,虽然第一行只用了一个,但是下一列的时候,理想情况是所有需要读取的元素都在一级缓存中,这时候,数据直接从缓存里面读取,美滋滋!
7.对角坐标?
8.关于cudaGetSymbolAddress?
#include "../check.h"
#include <stdio.h>
__device__ float devData;
__global__ void checkGlobalVariable()
{
printf("Device: the value of the global variable is %f\n", devData);
devData += 2.0f;
}
int main()
{
float value = 3.14f;
float* devptr;
CHECK(cudaGetSymbolAddress((void **)&devptr, devData));
CHECK(cudaMemcpy(devptr, &value, sizeof(float),cudaMemcpyHostToDevice));
checkGlobalVariable<<<1, 1>>>();
cudaDeviceSynchronize();
CHECK(cudaMemcpy(&value, devptr, sizeof(float),cudaMemcpyDeviceToHost));
printf("devptr: %f\n", devptr);//如果cudaGetSymbolAddress获得地址,为什么不能输出?
//printf("devptr: %f\n", *devptr); //运行报错,段错误,核心已转储
printf("value: %f\n", value);
CHECK(cudaGetSymbolAddress((void **)&devptr, devData));
printf("devptr: %f\n", devptr);
CHECK(cudaDeviceReset());
return 0;
}
输出:
Device: the value of the global variable is 3.140000
devptr: 0.000000
value: 5.140000
devptr: 5.140000
9.关于 malloc 和?cudaMallocHost
参考:CUDA:cudaMalloc vs cudaMallocHost-CSDN博客
都是分配的主机内存。malloc是pageable memory ,cudaMallocHost是?pinned memory
pageable memory: 通过操作系统API(malloc(),new())分配的存储器空间;
pinned memory ? ? :始终存在于物理内存中,不会被分配到低速的虚拟内存中,能够通过DMA加速与设备端进行通信;实质是强制让系统在物理内存中完成内存申请和释放的工作,不参与页交换,从而提高系统效率
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? cudaHostAlloc(), cudaFreeHost()来分配和释放pinned memory;
使用pinned memory优点:主机端-设备端的数据传输带宽高;某些设备上可以通过zero-copy功能映射到设备地址空间,从GPU直接访问,省掉主存与显存间进行数据拷贝的工作;
使用pinned memory缺点:pinned memory 不可以分配过多:导致操作系统用于分页的物理内存变少, 导致系统整体性能下降;通常由哪个cpu线程分配,就只有这个线程才有访问权限;
10.关于零拷贝内存:
参考:【精选】CUDA C编程8:内存管理之零拷贝内存_cuda零拷贝-CSDN博客
主机和设备都可以访问零拷贝内存。
注意,零拷贝内存相当于从全局内存中分出的一块独立内存,使用了固定内存技术实现零内存拷贝。
在CUDA核函数中使用零拷贝内存的优势如下:
(1)当设备内存不足时可利用主机内存
(2)避免主机和设备间的显示数据传输
(3)提高PCIe传输率
编译命令:-Xptxas -dlcm=cg //禁用一级缓存
-Xptxas -dlcm=ca //启用一级缓存
nvprof:

nvprof --metrics gld_efficiency?全局加载效率
--metrics gst_efficiency 全局存储效率
--metrics gld_transactions?全局加载事务
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!