spark链接hive时踩的坑
2023-12-15 14:32:35
? ? ? ? 使用spark操作hive,使用metastore连接hive,获取hive的数据库时,当我们在spark中创建数据库的时候,创建成功。
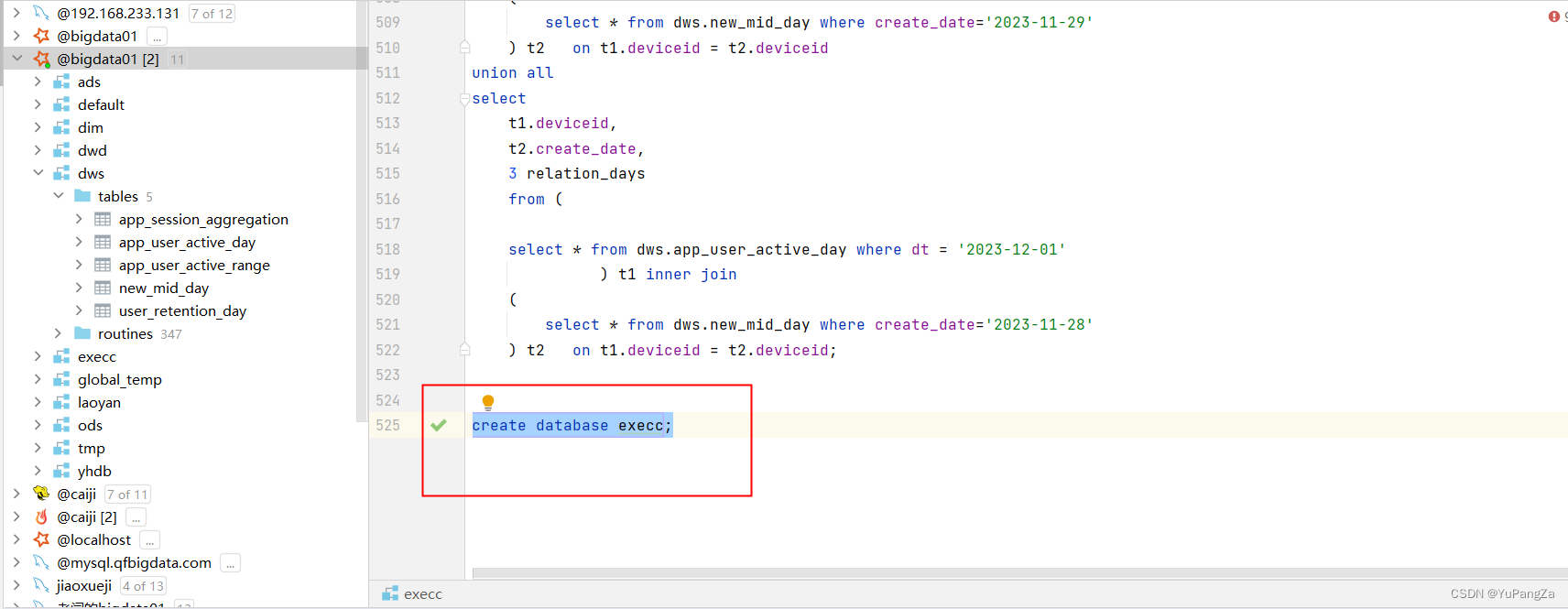
????????同时hive中也可以看到这个数据库,建表插入数据也没有问题,但是当我们去查询数据库中的数据时,发现查不到数据,去查hive的元数据,发现,spark在创建数据库的时候将数据库创建在了本地文件系统中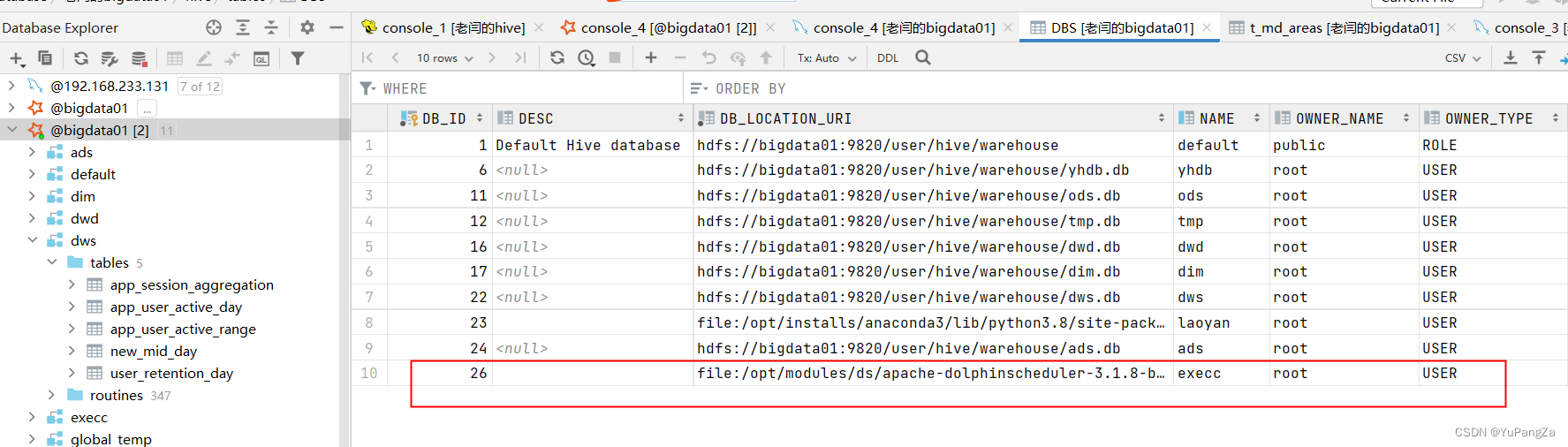
????????而我们的hive数据是存放在hdfs上的,我们的spark进行查询数据时是使用hive的metastore连接的hive的数据库,也就是spark会从hdfs上读取数据,所以无论怎么查询都是查不出来数据的
????????当我们按照这个路径去我们本地文件系统中查找这个路径的时候,就可以看到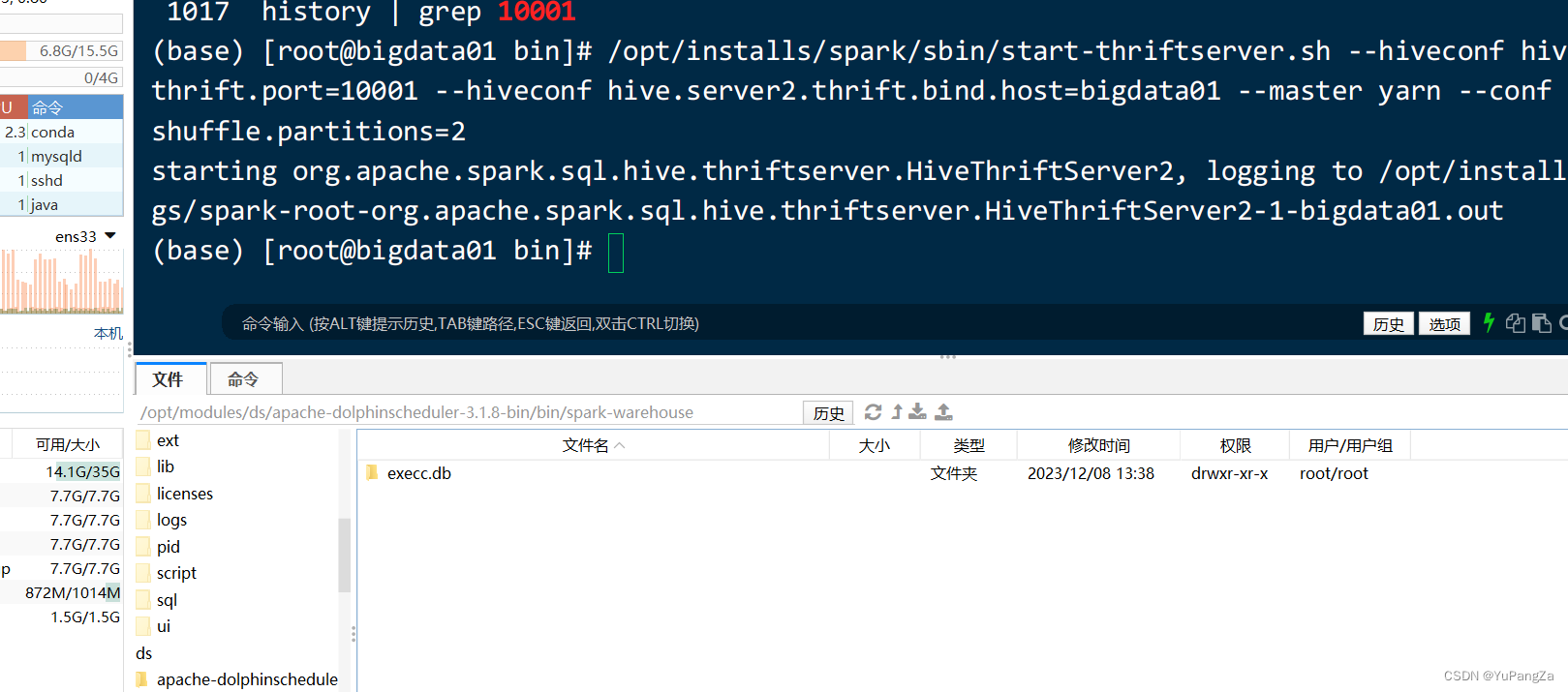
这个数据库,如果没有,可能是spark创建在了其他的服务器节点上?。
如何解决这个问题呢?
????????只需要在spark的配置文件中指定spark的数据存储位置为hdfs上即可
????????在spark的conf目录下找到spark-defaults.conf文件,在文件中添加
????????spark.sql.warehouse.dir hdfs的路径(hive的路径)
还有另一种方法(慎用)
????????在创建数据库的时候,在后面加上:localtion hdfs路径/数据库名.db
????????该方法虽然也可以将spark创建的数据库放入到hdfs上,但是在创建的时候,它会清空该文件夹下的所有数据,所以若使用此方法创建,需要设置为一个空文件夹
文章来源:https://blog.csdn.net/qq_43819048/article/details/134876340
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!