大模型应用系列03:pipeline 背后的工作
我们在
《大模型应用系列01:我们可以利用Transformer做什么?》通过 pipeline 了解了很多大模型应用的例子,比如下面的文本分类任务。
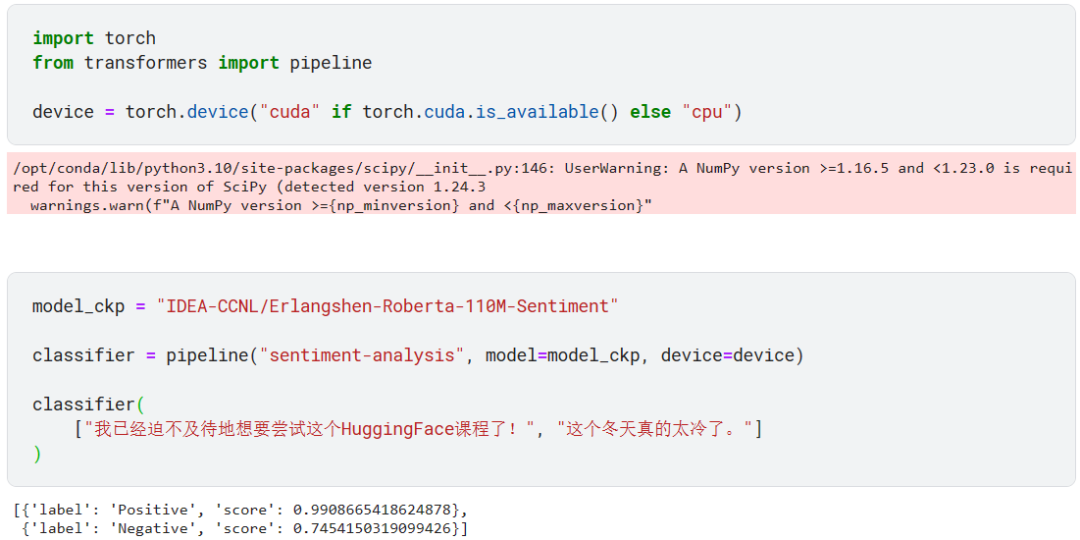
pipeline 接受我们输入的文本,然后先是做预处理(Tokenizer)、再将预处理结果输入指定的模型(Model)、最后对模型的输出进行后处理(Post Process),得到上图所示的结果。

现在我们以著名的 BERT 模型为例说明一下上图所示的工作流程。
Tokenzier
模型只能接受数字输入,tokenization 就是将文本输入转成模型能够接受的数值向量表示形式。完成这个过程的工具称为 tokenizer。注意这个数值向量表示要能体验句子的含义,而且向量维度越小越好。
pipeline 首先通过 tokenizer 做预处理:
-
将文本拆分成由词、字词和标点符号组成的 token
-
将每个 token 映射到词汇表中对应的唯一整数
-
添加一些必要的额外信息到模型输入(model input)中
每个模型都有自己专用的 tokenzier,所以不可用模型 A 的 tokenzier 去将处理文本输入,然后将结果输入到模型 B 中。
现在用预训练过的 bert-base-chinese 去加载一个适用于中文的 tokenzier。
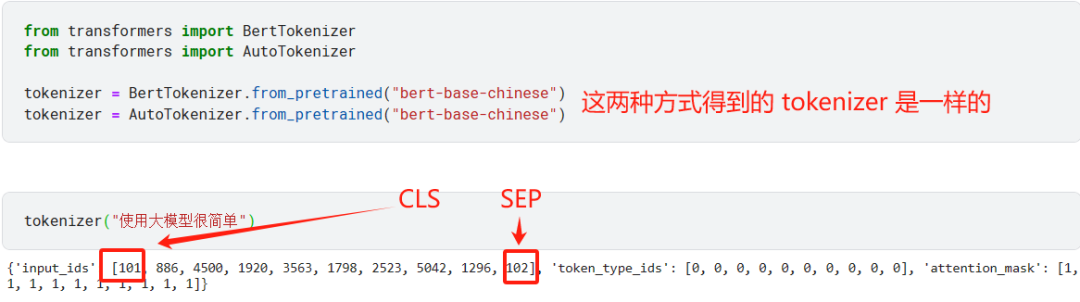
tokenizer 返回了一个字典,其中 input_ids 字段存储了 token 对应的整数 ID,对于 BERT 模型来说,它的 tokenzier 会在序列开头和结尾添加两个特殊的 token:[CLS] 和?[SEP]。所以最终输出的 ID 会有 101 和 102。
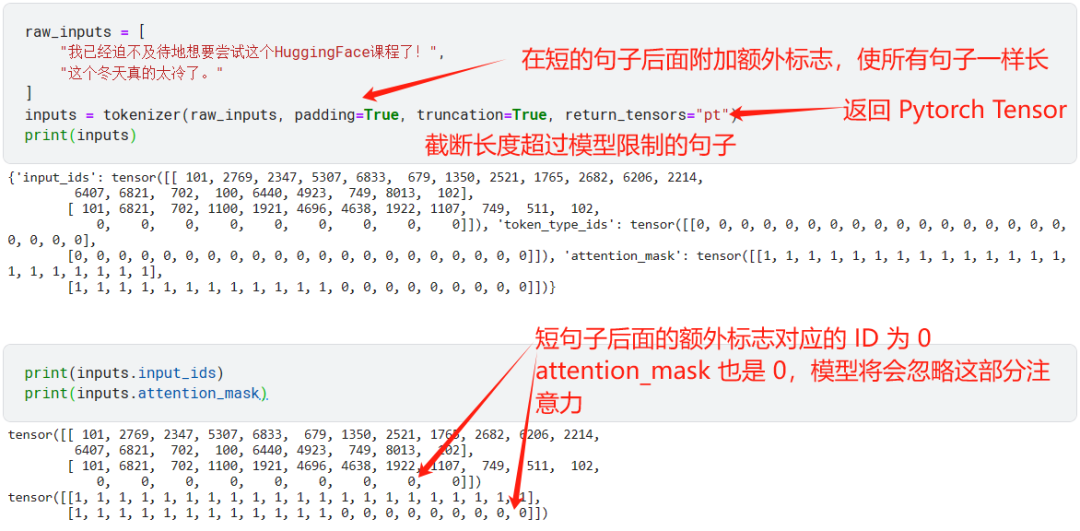
当我们要一次性 tokenize 多条句子时,需要注意每条句子长度可能不一样,有的句子可能太长了,超过了模型规定的最大长度。这时就需要使用额外参数了。
Transformer 模型处理具体任务的架构
一般处理具体任务的模型由 body 和处理具体任务的模型头组成。
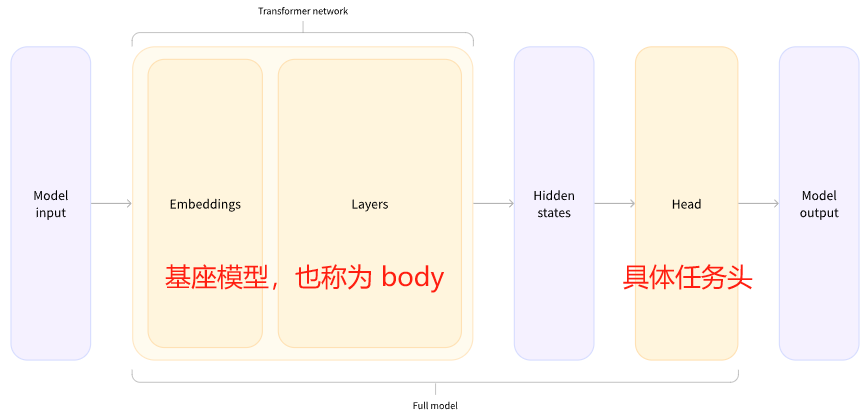
我们输入的纯文本经过 tokenzier 处理之后得到了?model input,然后通过 body 得到了称为隐藏状态的表示(这个表示是基座模型对输入文本的理解),最后由具体的任务头去利用这个表示做具体的处理(比如进行分类)。
获取 base model(基座模型)
对于一些常用的流行模型,我们可以通过以下方式使用,前提是它已经被收录进 transformers Python 库中,如果没有的话,你可能需要更新库。
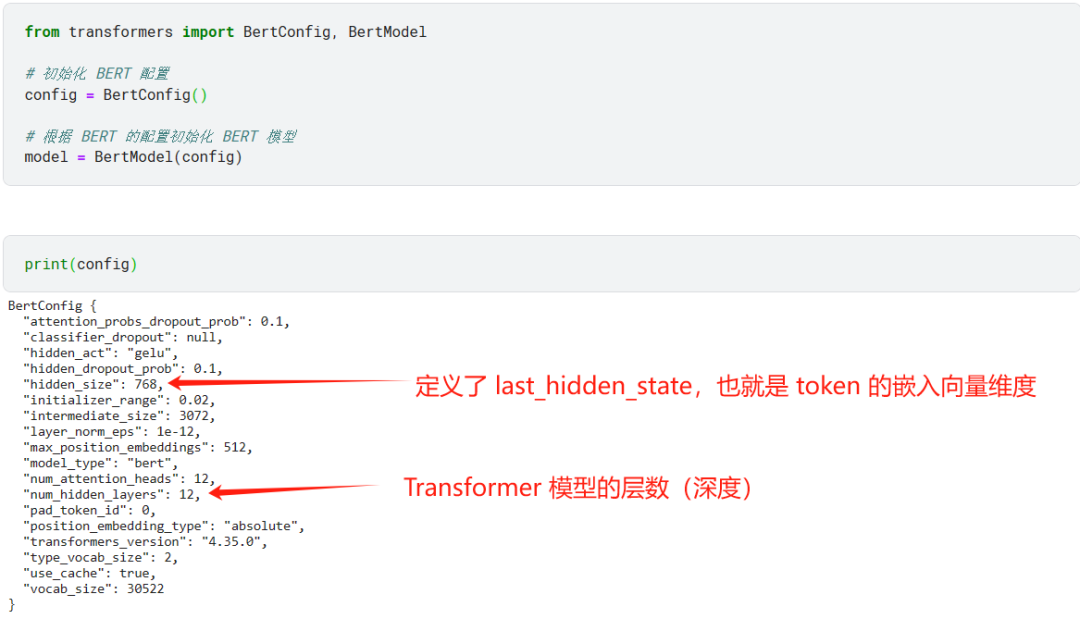
通过 BERT 模型的配置可以看到一些基本的配置信息。
不过需要注意的是,此时的 BERT 模型是未经训练过的,其中的参数都是随机初始化的,我们虽然可以根据手头的任务和资源从头训练(耗时耗钱且容易有意外情况),但是最好是使用别人预训练好的模型。
下面我们将使用针对中文进行预训练过的 base BERT 模型。

将 tokenizer 的结果输入到 base model
我们已经有了 tokenizer 处理原始文本,也有了 base model 获取文本的向量表示,所以现在可以将 tokenzier 的结果输入 base model 中获取原始文本的向量表示。

一般这个向量表示存储在 last_hidden_state 中,这个向量有 3 个维度:
-
batch size:一次性处理的序列个数,这里是 2 个句子
-
sequence length:这个批次中最长的序列包含的 token 数,这里是 24
-
hidden size:每个 token 对应的嵌入向量维度,这个不同的 base model 有不同的值
文本的向量表示其实就是将文本中的 token 用一组能表示每个 token 含义的嵌入向量(embedding vector)组成的,这正是 encoder 所做的事情。可以参考《大模型应用系列02:Transformer是怎样工作的?》?一文去了解一下 encoder。
model head
当获取了 base model 产生的嵌入向量之后,我们可以利用这个嵌入向量,根据手头上的任务选择不同机器学习或深度学习算法。
我们在这里选择一个专门做序列分类任务的预训练模型,这个模型的基座模型就是我们上面用的那个模型,不过增加了额外的分类任务头,这里分类任务头会输出 2 个类别:Positive 与 Negative。
 ?
?
由于模型输出的 logits 看起来让人一头雾水,所以有必要对模型输出做后处理。对于分类任务而言,我们一般用 softmax 函数将模型输出的 logits 转成概率表示。
 ?
?
通过模型的配置我们可以得到第一个句子以 99% 的概率被分类为 Positive,第二个句子以 74.54% 的概率被分类为 Negative。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!