K-Means算法进行分类
2023-12-13 13:22:31
已知数据集D中有9个数据点,分别是(1,2),(2,3), (2,1), (3,1),(2,4),(3,5),(4,3),(1,5),(4,2)。采用K-Means算法进行聚类,k=2,设初始中心点为(1.1,2.2),(2.3,3.5)。 试模拟K-Means算法的一次迭代过程,即先计算样本点到类中心点的距离,然后把样本点划分到最近的类中,最后更新类中心点的坐标
数据集合D:{(1,2),(2,3),(2,1),(3,1),(2,4),(3,5),(4,3),(1,5),(4,2)} 初始中心点: C1=(1.1,2.2),C2=(2.3,3.5) 计算每个数据点到两个中心点的距离,并将其划分到距离最近的类中。假设我们使用欧氏距离:
更新类中心点的坐标,即计算每个类的均值: C1=((1+2+3)/3,(2+1+1)/3)≈(2,1.3) C2=((2+2+3+4+1+4)/6,(3+4+5+3+5+2)/6))≈(2.6,3.6)
新的中心点更新为(2,1.3)和(2.6,3.6)
依次迭代直到发现没有重新分配或者准则函数收敛程序结束
数据集合D:{(1,2),(2,3),(2,1),(3,1),(2,4),(3,5),(4,3),(1,5),(4,2)} 初始中心点: C1=(1.1,2.2),C2=(2.3,3.5) 计算每个数据点到两个中心点的距离,并将其划分到距离最近的类中。假设我们使用欧氏距离:
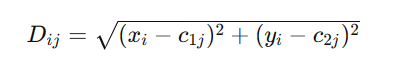
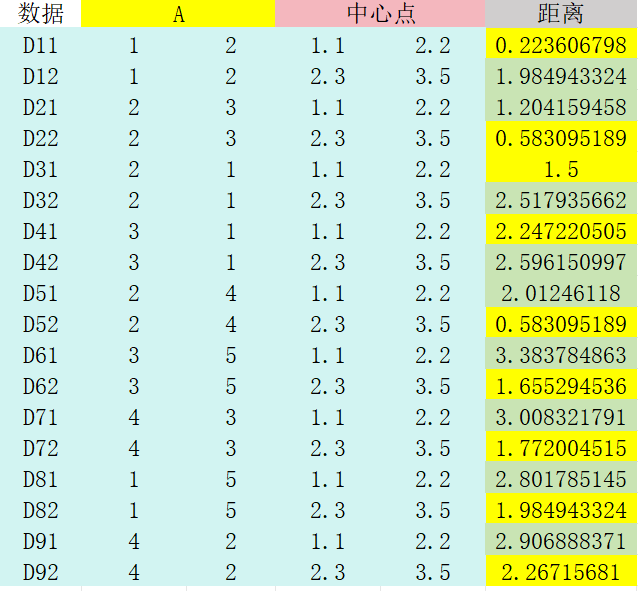
计算每个数据点到两个中心点的距离:
更新类中心点的坐标,即计算每个类的均值: C1=((1+2+3)/3,(2+1+1)/3)≈(2,1.3) C2=((2+2+3+4+1+4)/6,(3+4+5+3+5+2)/6))≈(2.6,3.6)
新的中心点更新为(2,1.3)和(2.6,3.6)
依次迭代直到发现没有重新分配或者准则函数收敛程序结束
文章来源:https://blog.csdn.net/qq_52108058/article/details/134483300
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!