pandas中的函数学习(不断更新)
2024-01-03 08:44:48
目录
1. Pandas中的query函数
函数功能:筛选数据
df.query("等式或者不等式")
# for example
df.query("A==5")
df.query("A>=10")
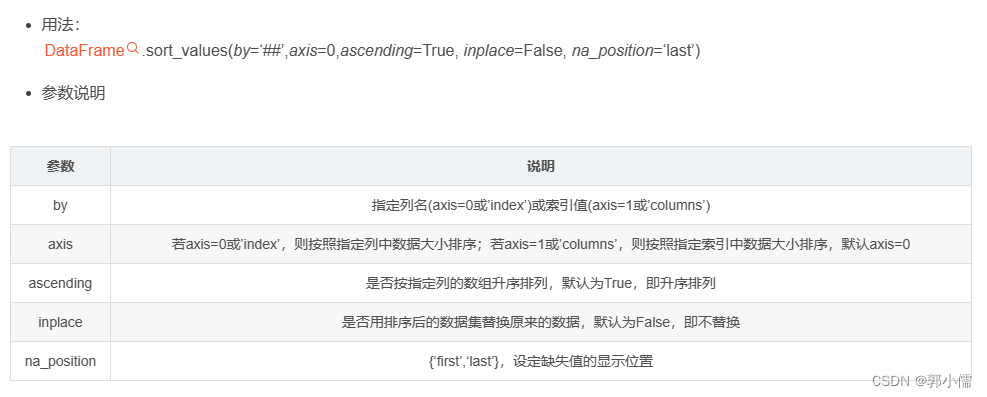
2. pandas中的sort_values
函数功能:可根据指定列数据也可根据指定行的数据排序
3.pandas中的apply函数
函数功能:对dataframe进行函数处理
DataFrame.apply(self, func, axis=0, raw=False, result_type=None, args=(), **kwds)
"""
func 代表的是传入的函数或 lambda 表达式;
axis 参数可提供的有两个,该参数默认为0/列
0 或者 index ,表示函数处理的是每一列;
1 或 columns ,表示处理的是每一行;
raw ;bool 类型,默认为 False;
False ,表示把每一行或列作为 Series 传入函数中;
True,表示接受的是 ndarray 数据类型;
"""
>>> df =pd.DataFrame([[4,9]]*3,columns = ['A','B'])
>>> df
A B
0 4 9
1 4 9
2 4 9
?
?
>>> df.apply(np.sqrt)
A B
0 2.0 3.0
1 2.0 3.0
2 2.0 3.0
>>> df.apply(np.mean)
A 4.0
B 9.0
4. pandas中的groupby
函数功能:将数据按照某一列进行划分
具体的在这个博客里面总结过:click here
- 按多列分组:
df.groupby({column1, column2])
df = pd.DataFrame([['a', 'man', 120, 90],
['b', 'woman', 130, 100],
['a', 'man', 110, 108],
['a', 'woman', 120, 118]], columns=['level', 'gender', 'math', 'chinese'])
print(df)
level gender math chinese
0 a man 120 90
1 b woman 130 100
2 a man 110 108
3 a woman 120 118
group = df.groupby(['gender', 'level'])
# 先按照'gender'列的值来分组。每组内,再按'level'列来分组。也返回一个groupby对象
for key, value in group:
print(key)
print(value)
print("")
('man', 'a')
level gender math chinese
0 a man 120 90
2 a man 110 108
('woman', 'a')
level gender math chinese
3 a woman 120 118
('woman', 'b')
level gender math chinese
1 b woman 130 100
5.pandas中的to_dict
函数功能:将datadrame转换成字典的形式
{ }表示字典数据类型,字典中的数据是以 {key : value} 的形式显示,是键名和键值一一对应形成的
6.pandas中的set_index
函数功能:指定某一个列作为索引
DataFrame.set_index(keys, drop=True, append=False, inplace=False, verify_integrity=False)
"""
keys:列标签或列标签/数组列表,需要设置为索引的列
drop:默认为True,删除用作新索引的列
append:是否将列附加到现有索引,默认为False。
inplace:输入布尔值,表示当前操作是否对原数据生效,默认为False。
verify_integrity:检查新索引的副本。否则,请将检查推迟到必要时进行。将其设置为false将提高该方法的性能,默认为false。
"""
import pandas as pd
import numpy as np
df = pd.DataFrame({'Country':['China','China', 'India', 'India', 'America', 'Japan', 'China', 'India'],
'Income':[10000, 10000, 5000, 5002, 40000, 50000, 8000, 5000],
'Age':[50, 43, 34, 40, 25, 25, 45, 32]})
Country Income Age
0 China 10000 50
1 China 10000 43
2 India 5000 34
3 India 5002 40
4 America 40000 25
5 Japan 50000 25
6 China 8000 45
7 India 5000 32
print(df.set_index('Country'))
Income Age
Country
China 10000 50
China 10000 43
India 5000 34
India 5002 40
America 40000 25
Japan 50000 25
China 8000 45
India 5000 32
6.1 pandas.DataFrame.reset_index
函数功能:重置索引(重置成默认索引)
df = pd.DataFrame([('bird', 389.0),
('bird', 24.0),
('mammal', 80.5),
('mammal', np.nan)],
index=['falcon', 'parrot', 'lion', 'monkey'],
columns=('class', 'max_speed'))
输出:df
class max_speed
falcon bird 389.0
parrot bird 24.0
lion mammal 80.5
monkey mammal NaN
# 重置索引时,将旧索引添加为列,并使用新的顺序索引:
df.reset_index()
index class max_speed
0 falcon bird 389.0
1 parrot bird 24.0
2 lion mammal 80.5
3 monkey mammal NaN
7. pandas中的info
功能:打印一个DataFrame的简要介绍(index范围、columns的dtype、非空值的数量和内存的使用情况)
(1)、函数形式
DataFrame.info(verbose=None, buf=None, max_cols=None, memory_usage=None, show_counts=None)[source]
(2)、参数
- verbose(adj 冗长的): bool, optional
- 决定是否打印完整的摘要
- 如果为False,那么会省略一部分
- buf: writable buffer, defaults to sys.stdout
- 决定将输出发送到哪里
- 默认情况下, 输出打印到sys.stdout
- max_cols: int, optional
- 从“详细输出”转换为“缩减输出”,如果DataFrame的列数超过max_cols,则缩减输出。
- memory_usage: bool, str, optional
- 决定是否应显示DataFrame元素(包括索引)的总内存使用情况
- 默认情况下为True
- True始终显示内存使用情况;False永远不会显示内存使用情况。
- show_counts: bool, optional
- 是否显示非空值的数量
- 值为True始终显示计数,而值为False则不显示计数
8. pandas中的fillna
功能:使用指定的方法填充NA/NaN值
(1)、函数形式
DataFrame.fillna(value=None, *, method=None, axis=None, inplace=False, limit=None, downcast=_NoDefault.no_default)
(2)、参数
- value: 标量、字典、series、dataframe
- 标量:全部填写为同一特定值
- 字典、dataframe:按列填写不同特定值
- series:按index填写不同特定值
- method: {‘backfill’, ‘bfill’, ‘ffill’, None}, default None
- 定义了填充空值的方法
- ‘ffill’ 用前一个非空缺值填充
- ‘bfill’ 用后一个非空缺值填充
- axis: {0 or ‘index’} for Series, {0 or ‘index’, 1 or ‘columns’} for DataFrame
- ‘index’:按行填充
- 'columns’按列填充
- inplace: bool, default False
- 是否用新生成的列表替换原列表
- 如果为True,则在原DataFrame上进行操作,返回值为None。
- limit: int, default None
- 如果method被指定,对于连续的空值,这段连续区域,最多填充前 limit 个空值(如果存在多段连续区域,每段最多填充前 limit 个空值)。如果method未被指定, 在该axis下,最多填充前 limit 个空值(不论空值连续区间是否间断)
文章来源:https://blog.csdn.net/qq_43403653/article/details/135338108
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!