Ignite分布式缓存框架
1.前言
Apache Ignite是一个分布式数据库,支持以内存级的速度进行高性能计算。
2。快速入门
本章节介绍运行Ignite的系统要求,如何安装,启动一个集群,然后运行一个简单的HelloWorld示例。
2.1.环境要求
Apache Ignite官方在如下环境中进行了测试:
- JDK:Oracle JDK8及11,Open JDK8及11,IBM JDK8及11;
- OS:Linux(任何版本),Mac OS X(10.6及以上),Windows(XP及以上),Windows Server(2008及以上),Oracle Solaris;
- 网络:没有限制(建议10G甚至更快的网络带宽);
- 架构:x86,x64,SPARC,PowerPC。
如果使用了JDK11,具体可以看下面的在Java11中运行Ignite章节;
2.2.安装Ignite
Ignite入门的最简单方式是使用每次版本发布生成的二进制压缩包:
- 下载最新版本的Ignite压缩包;
- 将该包解压到操作系统的一个文件夹;
- (可选)启用必要的模块;
- (可选)配置
IGNITE_HOME环境变量或者Windows的PATH指向Ignite的安装文件夹,路径不要以/(Windows为\)结尾。
2.3.启动Ignite
可以从命令行启动Ignite集群,或者使用默认的配置,或者传入一个自定义配置文件,可以同时启动任意多个节点,他们都会自动地相互发现。
在命令行中转到Ignite安装文件夹的bin目录:
cd {IGNITE_HOME}/bin/
向下面这样,将一个自定义配置文件作为参数传递给ignite.sh|bat,然后启动一个节点:
./ignite.sh ../examples/config/example-ignite.xml
输出大致如下:
[08:53:45] Ignite node started OK (id=7b30bc8e)
[08:53:45] Topology snapshot [ver=1, locNode=7b30bc8e, servers=1, clients=0, state=ACTIVE, CPUs=4, offheap=1.6GB, heap=2.0GB]
再次开启一个终端然后执行和前述同样的命令:
./ignite.sh ../examples/config/example-ignite.xml
这时再次看下输出,注意包含Topology snapshot的行,就会发现集群中有了2个服务端节点,同时集群中可用的CPU和内存也会更多:
[08:54:34] Ignite node started OK (id=3a30b7a4)
[08:54:34] Topology snapshot [ver=2, locNode=3a30b7a4, servers=2, clients=0, state=ACTIVE, CPUs=4, offheap=3.2GB, heap=4.0GB]
默认配置
ignite.sh|bat默认会使用config/default-config.xml这个配置文件启动节点。
2.4.创建第一个应用
集群启动之后,就可以按照如下步骤运行一个HelloWorld示例。
2.4.1.添加Maven依赖
在Java中使用Ignite的最简单的方式是使用Maven依赖管理。
使用喜欢的IDE创建一个新的Maven工程,然后在项目的pom.xml文件中添加下面的依赖:
<properties>
<ignite.version>2.10.0</ignite.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.ignite</groupId>
<artifactId>ignite-core</artifactId>
<version>${ignite.version}</version>
</dependency>
<dependency>
<groupId>org.apache.ignite</groupId>
<artifactId>ignite-spring</artifactId>
<version>${ignite.version}</version>
</dependency>
</dependencies>
2.4.2.HelloWorld.java
下面这个HelloWord.java文件,会在所有已启动的服务端节点上输出Hello World以及其他的一些环境信息,该示例会显示如何使用Java API配置集群,如何创建缓存,如何加载数据并在服务端执行Java任务:
public class HelloWorld {
public static void main(String[] args) throws IgniteException {
// Preparing IgniteConfiguration using Java APIs
IgniteConfiguration cfg = new IgniteConfiguration();
// The node will be started as a client node.
cfg.setClientMode(true);
// Classes of custom Java logic will be transferred over the wire from this app.
cfg.setPeerClassLoadingEnabled(true);
// Setting up an IP Finder to ensure the client can locate the servers.
TcpDiscoveryMulticastIpFinder ipFinder = new TcpDiscoveryMulticastIpFinder();
ipFinder.setAddresses(Collections.singletonList("127.0.0.1:47500..47509"));
cfg.setDiscoverySpi(new TcpDiscoverySpi().setIpFinder(ipFinder));
// Starting the node
Ignite ignite = Ignition.start(cfg);
// Create an IgniteCache and put some values in it.
IgniteCache<Integer, String> cache = ignite.getOrCreateCache("myCache");
cache.put(1, "Hello");
cache.put(2, "World!");
System.out.println(">> Created the cache and add the values.");
// Executing custom Java compute task on server nodes.
ignite.compute(ignite.cluster().forServers()).broadcast(new RemoteTask());
System.out.println(">> Compute task is executed, check for output on the server nodes.");
// Disconnect from the cluster.
ignite.close();
}
/**
* A compute tasks that prints out a node ID and some details about its OS and JRE.
* Plus, the code shows how to access data stored in a cache from the compute task.
*/
private static class RemoteTask implements IgniteRunnable {
@IgniteInstanceResource
Ignite ignite;
@Override public void run() {
System.out.println(">> Executing the compute task");
System.out.println(
" Node ID: " + ignite.cluster().localNode().id() + "\n" +
" OS: " + System.getProperty("os.name") +
" JRE: " + System.getProperty("java.runtime.name"));
IgniteCache<Integer, String> cache = ignite.cache("myCache");
System.out.println(">> " + cache.get(1) + " " + cache.get(2));
}
}
}
提示
不要忘了添加import语句,然后如果Maven解决了所有的依赖,这个会很简单。
如果IDE仍然使用早于1.8版本的Java编译器,那么还需要将下面的配置项加入pom.xml文件:
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
</plugins>
</build>
2.4.3.运行该应用
编译并运行HelloWorld.java,然后就会在所有服务端节点上看到Hello World!以及其他的一些环境信息输出。
2.5.进一步的示例
Ignite的安装包里面包含了其他的示例。
按照下面的步骤,可以运行这个示例工程(这里以IntelliJ IDEA为例,其他类似的IDE比如Eclipse也可以)。
- 启动IntelliJ IDEA,然后点击
Import Project按钮;
- 转到
{IGNITE_HOME}/examples目录,选择{IGNITE}/examples/pom.xml文件,然后点击OK; - 在后面的界面中点击
Next,都使用项目的默认配置,最后点击Finish; - 等待IntelliJ IDE完成Maven配置,解析依赖,然后加载模块;
- 必要时需要配置JDK。
- 运行
rc/main/java/org/apache/ignite/examples/datagrid/CacheApiExample;

- 确认示例代码已经启动并且成功执行,如下图所示:

2.6.在Java11中使用Ignite
要在Java11及以后的版本中运行Ignite,需按照如下步骤操作:
- 配置
JAVA_HOME环境变量,指向Java的安装目录; - Ignite使用了专有的SDK API,这些API默认并未开启,因此需要向JVM传递额外的专有标志来让这些API可用。如果使用的是
ignite.sh或者ignite.bat,那么什么都不需要做,因为脚本已经提前配置好了。否则就需要向应用的JVM添加下面的参数;
--add-exports=java.base/jdk.internal.misc=ALL-UNNAMED
--add-exports=java.base/sun.nio.ch=ALL-UNNAMED
--add-exports=java.management/com.sun.jmx.mbeanserver=ALL-UNNAMED
--add-exports=jdk.internal.jvmstat/sun.jvmstat.monitor=ALL-UNNAMED
--add-exports=java.base/sun.reflect.generics.reflectiveObjects=ALL-UNNAMED
--add-opens=jdk.management/com.sun.management.internal=ALL-UNNAMED
--illegal-access=permit
- TLSv1.3,Java11中已经可以使用,目前还不支持,如果节点间使用了SSL,可以考虑添加
-Djdk.tls.client.protocols=TLSv1.2。
3.Ignite配置入门
#1.配置方式
本章节会介绍在Ignite集群中设定配置参数的不同方式。
.NET、Python、Node.js等其他语言的配置
#1.1.概述
可以通过在启动节点时向Ignite提供IgniteConfiguration类的实例来指定自定义配置参数。使用编程方式或通过XML配置文件都可以,这两种方式是完全可以互换的。
XML配置文件是必须包含IgniteConfigurationbean的Spring Bean定义文件。从命令行启动节点时,可以将配置文件作为参数传递给ignite.sh|bat脚本,如下所示:
ignite.sh ignite-config.xml
如果未指定配置文件,会使用默认文件{IGNITE_HOME}/config/default-config.xml。
#1.2.基于Spring的XML配置
要创建一个Spring XML格式的配置文件,需要定义一个IgniteConfigurationbean,然后配置不同于默认值的参数,关于如何使用基于XML模式的配置的更多信息,可以看官方的Spring文档。
在下面的示例中,创建了IgniteConfigurationbean,配置了workDirectory属性,然后配置了一个分区模式的缓存。
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd">
<bean class="org.apache.ignite.configuration.IgniteConfiguration">
<property name="workDirectory" value="/path/to/work/directory"/>
<property name="cacheConfiguration">
<bean class="org.apache.ignite.configuration.CacheConfiguration">
<!-- Set the cache name. -->
<property name="name" value="myCache"/>
<!-- Set the cache mode. -->
<property name="cacheMode" value="PARTITIONED"/>
<!-- Other cache parameters. -->
</bean>
</property>
</bean>
</beans>
#1.3.编程式配置
创建一个IgniteConfiguration类的实例,然后配置必要的参数,如下所示:
- Java
- C#/.NET
- C++
IgniteConfiguration igniteCfg = new IgniteConfiguration();
//setting a work directory
igniteCfg.setWorkDirectory("/path/to/work/directory");
//defining a partitioned cache
CacheConfiguration cacheCfg = new CacheConfiguration("myCache");
cacheCfg.setCacheMode(CacheMode.PARTITIONED);
igniteCfg.setCacheConfiguration(cacheCfg);
完整参数的列表,可以参见IgniteConfiguration的javadoc。
#2.Ignite Java配置
.NET、Python、Node.js等其他语言的配置
#2.1.环境要求
Apache Ignite官方在如下环境中进行了测试:
- JDK:Oracle JDK8及11,Open JDK8及11,IBM JDK8及11;
- OS:Linux(任何版本),Mac OS X(10.6及以上),Windows(XP及以上),Windows Server(2008及以上),Oracle Solaris;
- 网络:没有限制(建议10G甚至更快的网络带宽);
- 架构:x86,x64,SPARC,PowerPC。
#2.2.在Java11中使用Ignite
要在Java11及以后的版本中运行Ignite,需按照如下步骤操作:
- 配置
JAVA_HOME环境变量,指向Java的安装目录; - Ignite使用了专有的SDK API,这些API默认并未开启,因此需要向JVM传递额外的专有标志来让这些API可用。如果使用的是
ignite.sh或者ignite.bat,那么什么都不需要做,因为脚本已经提前配置好了。否则就需要向应用的JVM添加下面的参数;
--add-exports=java.base/jdk.internal.misc=ALL-UNNAMED
--add-exports=java.base/sun.nio.ch=ALL-UNNAMED
--add-exports=java.management/com.sun.jmx.mbeanserver=ALL-UNNAMED
--add-exports=jdk.internal.jvmstat/sun.jvmstat.monitor=ALL-UNNAMED
--add-exports=java.base/sun.reflect.generics.reflectiveObjects=ALL-UNNAMED
--add-opens=jdk.management/com.sun.management.internal=ALL-UNNAMED
--illegal-access=permit
- TLSv1.3,Java11中已经可以使用,目前还不支持,如果节点间使用了SSL,可以考虑添加
-Djdk.tls.client.protocols=TLSv1.2。
#2.3.使用二进制包
- 下载最新版本的Ignite压缩包;
- 将该包解压到操作系统的一个文件夹;
- (可选)配置
IGNITE_HOME环境变量或者Windows的PATH指向Ignite的安装文件夹,路径不要以/(Windows为\)结尾。
#2.4.使用Maven
使用Ignite的最简单的方式是将其加入项目的pom.xml文件。
<properties>
<ignite.version>2.10.0</ignite.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.ignite</groupId>
<artifactId>ignite-core</artifactId>
<version>${ignite.version}</version>
</dependency>
</dependencies>
ignite-core模块包含了Ignite的核心功能,其他的功能都是由各种Ignite模块提供的。
下面两个是最常用的模块:
ignite-spring:支持基于XML的配置;ignite-indexing:支持SQL索引。
<dependency>
<groupId>org.apache.ignite</groupId>
<artifactId>ignite-spring</artifactId>
<version>${ignite.version}</version>
</dependency>
<dependency>
<groupId>org.apache.ignite</groupId>
<artifactId>ignite-indexing</artifactId>
<version>${ignite.version}</version>
</dependency>
#2.5.使用Docker
如果希望在Docker环境中运行Ignite,请参见Docker部署章节的内容。
#2.6.配置工作目录
Ignite会使用一个工作目录来保存应用的数据(如果使用了原生持久化功能)、索引文件、元数据信息、日志以及其他文件,默认的工作目录为:
$IGNITE_HOME/work:如果定义了IGNITE_HOME系统属性,如果使用二进制包的bin/ignite.sh脚本启动,就是这种情况;./ignite/work:这个路径相对于应用启动时的目录。
修改默认的工作目录有几种方式:
- 环境变量方式:
export IGNITE_WORK_DIR=/path/to/work/directory
- 在节点的配置中:
- XML
- Java
- C#/.NET
- C++
<bean class="org.apache.ignite.configuration.IgniteConfiguration">
<property name="workDirectory" value="/path/to/work/directory"/>
<!-- other properties -->
</bean>
#2.7.启用模块
Ignite包含了很多的模块,提供了各种各样的功能,开发者可以根据需要,一个个引入。
Ignite的二进制包里面包含了所有的模块,但是默认都是禁用的(除了ignite-core、ignite-spring、ignite-indexing模块),可选库位于二进制包的lib/optional文件夹,每个模块是一个单独的子目录。
根据使用Ignite的方式,可以使用下述方式之一启用模块:
- 如果使用的是二进制包,那么可以在启动节点之前将
libs/optional/{module-dir}移动到libs目录; - 将
libs/optional/{module-dir}中的库文件加入应用的类路径; - 将一个模块添加到工程的依赖中:
<dependency>
<groupId>org.apache.ignite</groupId>
<artifactId>ignite-log4j2</artifactId>
<version>${ignite.version}</version>
</dependency>
下面的模块有LGPL依赖,因此无法部署在Maven中央仓库中:
ignite-hibernate;ignite-geospatial;ignite-schedule。
要使用这些模块,可以从源代码进行构建然后添加到工程中,比如要将ignite-hibernate模块安装到本地仓库,可以在Ignite的源代码包中执行下面的命令:
mvn clean install -DskipTests -Plgpl -pl modules/hibernate -am
下面的模块都是可用的:
| 模块的构件 | 描述 |
|---|---|
ignite-aop | Ignite AOP模块通过添加@Gridify注解,可以将任何Java方法转换为分布式闭包。 |
ignite-aws | AWS S3上的集群发现,具体请参见Amazon S3 IP探测器。 |
ignite-cassandra-serializers | 该模块提供了在Cassandra中将对象保存为BLOB格式的附加序列化器,该模块可以和Ignite的Cassandra存储模块一起使用。 |
ignite-cassandra-store | 该模块提供了一个基于Cassandra数据库的CacheStore实现。 |
ignite-cloud | 该模块提供了TCP发现中IP探测器的Apache Jclouds实现。 |
ignite-direct-io | 该模块提供了一个以O_DIRECT模式进行缓存分区读写的页面存储。 |
ignite-gce | 该模块提供了TCP发现中IP探测器的Google Cloud Storage实现。 |
ignite-indexing | SQL查询和索引。 |
ignite-jcl | 支持Jakarta Common Logging (JCL)框架。 |
ignite-jta | Ignite事务与JTA的集成。 |
ignite-kafka | Ignite的Kafka流处理器,提供了从Kafka到Ignite缓存的流式数据处理能力。 |
ignite-kubernetes | Ignite Kubernetes模块提供了一个基于TCP发现的IP探测器,其使用专用的Kubernetes服务来查找由Kubernetes容器化的Ignite Pod的IP地址。 |
ignite-log4j | 支持log4j。 |
ignite-log4j2 | 支持log4j2。 |
ignite-ml | Ignite的机器学习模块,其提供了机器学习功能以及线性代数的相关数据结构和方法,包括堆内和堆外,密集和稀疏,本地和分布式实现。详细信息请参见机器学习文档。 |
ignite-osgi | 该模块提供了桥接组件,以使Ignite可以在OSGi容器(例如Apache Karaf)内无缝运行。 |
ignite-osgi-karaf | 该模块包含功能特性库,以方便将Ignite安装到Apache Karaf容器中。 |
ignite-rest-http | 该模块在节点内启动了一个基于Jetty的服务器,该服务器可用于在集群中使用基于HTTP的RESTful API执行任务和/或缓存命令。 |
ignite-scalar | 该模块为基于Scala的DSL提供Ignite API的扩展和快捷方式。 |
ignite-scalar_2.10 | Ignite支持Scalar2.10的模块。 |
ignite-schedule | 该模块提供了在本地节点使用基于UNIX CRON表达式语法的作业调度能力。 |
ignite-slf4j | 支持SLF4J日志框架。 |
ignite-spark | 该模块提供了SparkRDD抽象的实现,可轻松访问Ignite缓存。 |
ignite-spring-data | 提供了与Spring Data框架的集成。 |
ignite-spring-data_2.0 | 提供了与Spring Data框架2.0的集成。 |
ignite-ssh | 该模块提供了通过SSH在远程主机上启动Ignite节点的功能。 |
ignite-urideploy | 提供了从不同来源(例如文件系统、HTTP甚至电子邮件)部署任务的功能。 |
ignite-visor-console | 开源的命令行管理和监控工具。 |
ignite-web | 该模块允许基于Servlet和Servlet上下文监听器在任何Web容器内启动节点。此外该模块还提供了将Web会话缓存在Ignite缓存中的功能。 |
ignite-zookeeper | 该模块提供了一个基于TCP发现的IP探测器,它会使用一个ZooKeeper目录来发现其他的Ignite节点。 |
#2.8.配置JVM选项
当通过ignite.sh脚本启动节点时,设置JVM参数有几个方法,这些方法下面的章节会介绍。
#2.8.1.JVM_OPTS系统变量
可以配置JVM_OPTS环境变量:
export JVM_OPTS="$JVM_OPTS -Xmx6G -DIGNITE_TO_STRING_INCLUDE_SENSITIVE=false"; $IGNITE_HOME/bin/ignite.sh
#2.8.2.命令行参数
还可以通过-J前缀传递JVM参数:
- Linux
- Windows
./ignite.sh -J-Xmx6G -J-DIGNITE_TO_STRING_INCLUDE_SENSITIVE=false
#2.9.配置Ignite系统属性
除了公开的配置参数,还可以使用内部系统属性来调整某个(通常是底层的)Ignite行为。可以使用以下命令找到所有属性及其说明和默认值:
- Linux
- Windows
./ignite.sh -systemProps
输出示例:
ignite.sh -systemProps
IGNITE_AFFINITY_HISTORY_SIZE - [Integer] Maximum size for affinity assignment history. Default is 25.
IGNITE_ALLOW_ATOMIC_OPS_IN_TX - [Boolean] Allows atomic operations inside transactions. Default is true.
IGNITE_ALLOW_DML_INSIDE_TRANSACTION - [Boolean] When set to true, Ignite will allow executing DML operation (MERGE|INSERT|UPDATE|DELETE) within transactions for non MVCC mode. Default is false.
IGNITE_ALLOW_START_CACHES_IN_PARALLEL - [Boolean] Allows to start multiple caches in parallel. Default is true.
...
#2.10.配置建议
以下是一些推荐的配置技巧,旨在使开发者更轻松地操作Ignite集群或使用Ignite开发应用。
配置工作目录
如果要使用二进制包或Maven,建议为Ignite设置工作目录。工作目录用于存储元数据信息、索引文件、应用程序数据(如果使用原生持久化功能)、日志和其他文件。建议一定要设置工作目录。
建议的日志配置
日志在故障排除和查找错误方面起着重要作用,以下是有关如何管理日志文件的一些一般提示:
-
以
verbose模式启动Ignite;- 如果使用
ignite.sh,请指定-v选项; - 如果从Java代码启动Ignite,请设置
IGNITE_QUIET=false系统变量;
- 如果使用
-
不要将日志文件存储在
/tmp文件夹中,每次重启服务器时都会清除此文件夹; -
确保在存储日志文件的磁盘上有足够的可用空间;
-
定期存档旧的日志文件以节省存储空间。
#3.配置日志
#3.1.概述
Ignite支持各种常见的日志库和框架:
- JUL (默认);
- Log4j;
- Log4j2;
- JCL;
- SLF4J。
本章节会介绍如何使用它们。
Ignite节点启动之后,会在控制台中输出启动信息,包括了配置的日志库信息。每个日志库都有自己的配置参数,需要分别进行配置。除了库特有的配置,还有一些系统属性可以对日志进行调整,如下表所示:
| 系统属性 | 描述 | 默认值 |
|---|---|---|
IGNITE_LOG_INSTANCE_NAME | 如果该属性存在,Ignite会在日志消息中包含实例名 | 未配置 |
IGNITE_QUIET | 配置为false可以禁用静默模式,启用详细模式,其会输出更多的信息 | true |
IGNITE_LOG_DIR | 该属性会指定Ignite日志的输出目录 | $IGNITE_HOME/work/log |
IGNITE_DUMP_THREADS_ON_FAILURE | 如果配置为true,在捕获严重错误时会在日志中输出线程堆栈信息 | true |
#3.2.默认日志
Ignite默认会使用java.util.logging(JUL框架),如果节点是通过二进制包的ignite.sh|bat脚本启动,Ignite会使用$IGNITE_HOME/config/java.util.logging.properties作为默认的配置文件,然后将日志写入$IGNITE_HOME/work/log文件夹中的日志文件,要修改这个日志目录,可以使用IGNITE_LOG_DIR系统属性。
如果将Ignite作为应用中的库文件引入,默认的日志配置只包括控制台日志处理器,级别为INFO,可以通过java.util.logging.config.file系统属性提供一个自定义的配置文件。
#3.3.使用Log4j
提示
在使用Log4j之前,需要先启用ignite-log4j模块。
要使用Log4j进行日志记录,需要配置IgniteConfiguration的gridLogger属性,如下所示:
- XML
- Java
- C#/.NET
- C++
<bean class="org.apache.ignite.configuration.IgniteConfiguration" id="ignite.cfg">
<property name="gridLogger">
<bean class="org.apache.ignite.logger.log4j.Log4JLogger">
<!-- log4j configuration file -->
<constructor-arg type="java.lang.String" value="log4j-config.xml"/>
</bean>
</property>
<!-- other properties -->
</bean>
在上面的配置中,log4j-config.xml的路径要么是绝对路径,要么是相对路径,可以相对于META-INF,也可以相对于IGNITE_HOME。在Ignite的二进制包中有一个log4j配置文件的示例($IGNITE_HOME/config/ignite-log4j.xml)。
#3.4.使用Log4j2
提示
在使用Log4j之前,需要先启用ignite-log4j2模块。
要使用Log4j2进行日志记录,需要配置IgniteConfiguration的gridLogger属性,如下所示:
- XML
- Java
- C#/.NET
- C++
<bean class="org.apache.ignite.configuration.IgniteConfiguration" id="ignite.cfg">
<property name="gridLogger">
<bean class="org.apache.ignite.logger.log4j2.Log4J2Logger">
<!-- log4j2 configuration file -->
<constructor-arg type="java.lang.String" value="log4j2-config.xml"/>
</bean>
</property>
<!-- other properties -->
</bean>
在上面的配置中,log4j2-config.xml的路径要么是绝对路径,要么是相对路径,可以相对于META-INF,也可以相对于IGNITE_HOME。在Ignite的二进制包中有一个log4j2配置文件的示例($IGNITE_HOME/config/ignite-log4j2.xml)。
提示
Log4j2的配置支持运行时调整,即配置文件的变更会即时生效而不需要重启应用。
#3.5.使用JCL
提示
在使用Log4j之前,需要先启用ignite-jcl模块。
提示
注意JCL只是简单地将日志消息转发给底层的日志系统,该日志系统是需要正确配置的,更多的信息,请参见JCL官方文档。比如,如果要使用Log4j,就需要把必要的库文件加入类路径中。
要使用JCL进行日志记录,需要配置IgniteConfiguration的gridLogger属性,如下所示:
- XML
- Java
- C#/.NET
- C++
<bean class="org.apache.ignite.configuration.IgniteConfiguration" id="ignite.cfg">
<property name="gridLogger">
<bean class="org.apache.ignite.logger.jcl.JclLogger">
</bean>
</property>
<!-- other properties -->
</bean>
#3.6.使用SLF4J
提示
在使用Log4j之前,需要先启用ignite-slf4j模块。
要使用SLF4J进行日志记录,需要配置IgniteConfiguration的gridLogger属性,如下所示:
- XML
- Java
- C#/.NET
- C++
<bean class="org.apache.ignite.configuration.IgniteConfiguration" id="ignite.cfg">
<property name="gridLogger">
<bean class="org.apache.ignite.logger.slf4j.Slf4jLogger">
</bean>
</property>
<!-- other properties -->
</bean>
更多的信息,请参见SLF4J用户手册。
#3.7.限制敏感信息
日志可以包括缓存数据、系统属性、启动选项等内容。在某些情况下,这些日志可能包含敏感信息。可以通过将IGNITE_TO_STRING_INCLUDE_SENSITIVE系统属性设置为false来阻止将此类信息写入日志。
./ignite.sh -J-DIGNITE_TO_STRING_INCLUDE_SENSITIVE=false
请参见配置JVM选项以了解设置系统属性的不同方式。
#3.8.日志配置示例
下面的步骤可以指导开发者配置日志的过程,这个过程会适用大多数场景。
- 使用Log4j或者Log4j2作为日志框架,使用方式见前述的说明;
- 如果使用了默认的配置文件(
ignite-log4j.xml或者ignite-log4j2.xml),需要取消CONSOLEappender的注释; - 在log4j配置文件中,需要配置日志文件的路径,默认位置为
${IGNITE_HOME}/work/log/ignite.log; - 使用
verbose模式启动节点:- 如果使用
ignite.sh启动节点,加上-v选项; - 如果从Java代码启动节点,需要使用
IGNITE_QUIET=false系统变量。
- 如果使用
#4.资源注入
#4.1.概述
Ignite中,预定义的资源都是可以进行依赖注入的,同时支持基于属性和基于方法的注入。任何加注正确注解的资源都会在初始化之前注入相对应的任务、作业、闭包或者SPI。
#4.2.基于属性和基于方法
可以通过在一个属性或者方法上加注注解来注入资源。当加注在属性上时,Ignite只是在注入阶段简单地设置属性的值(不会理会该属性的访问修饰符)。如果在一个方法上加注了资源注解,它会访问一个与注入资源相对应的输入参数的类型,如果匹配,那么在注入阶段,就会将适当的资源作为输入参数,然后调用该方法。
- 基于属性
- 基于方法
Ignite ignite = Ignition.ignite();
Collection<String> res = ignite.compute().broadcast(new IgniteCallable<String>() {
// Inject Ignite instance.
@IgniteInstanceResource
private Ignite ignite;
@Override
public String call() throws Exception {
IgniteCache<Object, Object> cache = ignite.getOrCreateCache(CACHE_NAME);
// Do some stuff with cache.
...
}
});
#4.3.预定义的资源
有很多的预定义资源可供注入:
| 资源 | 描述 |
|---|---|
CacheNameResource | 由CacheConfiguration.getName()提供,注入缓存名 |
CacheStoreSessionResource | 注入当前的CacheStoreSession实例 |
IgniteInstanceResource | 注入当前的Ignite实例 |
JobContextResource | 注入ComputeJobContext的实例。作业的上下文持有关于一个作业执行的有用的信息。比如,可以获得包含与作业并置的条目的缓存的名字。 |
LoadBalancerResource | 注入ComputeLoadBalancer的实例,注入后可以用于任务的负载平衡。 |
ServiceResource | 通过指定服务名注入Ignite的服务。 |
SpringApplicationContextResource | 注入Spring的ApplicationContext资源。 |
SpringResource | 从Spring的ApplicationContext注入资源,当希望访问在Spring的ApplicationContext XML配置中指定的一个Bean时,可以用它。 |
TaskContinuousMapperResource | 注入一个ComputeTaskContinuousMapper的实例,持续映射可以在任何时点从任务中发布作业,即使过了map的初始化阶段。 |
TaskSessionResource | 注入ComputeTaskSession资源的实例,它为某个任务执行定义了一个分布式的会话。 |
4. 启动和停止节点
本章节介绍如何启动服务端和客户端节点。
节点的类型有两种:服务端节点和客户端节点。客户端节点也称为胖客户端,以区别于瘦客户端。服务端节点参与缓存、计算的执行、流数据处理等。客户端节点提供远程接入服务端的能力,有完整的Ignite API支持,包括近缓存、事务、计算、流处理、服务等。
所有的节点默认都以服务端模式启动,客户端模式需要显式指定。
#1.启动服务端节点
可以使用下面的命令或者代码片段,启动一个普通的服务端节点:
- Shell
- Java
- C#/.NET
IgniteConfiguration cfg = new IgniteConfiguration();
Ignite ignite = Ignition.start(cfg);
Ignite实现了AutoCloseable接口,可以使用try-with-resource语句来自动关闭。
IgniteConfiguration cfg = new IgniteConfiguration();
try (Ignite ignite = Ignition.start(cfg)) {
//
}
#2.启动客户端节点
要启动客户端节点,可以简单地在节点的配置中打开客户端模式:
- XML
- Java
- C#/.NET
IgniteConfiguration cfg = new IgniteConfiguration();
// Enable client mode.
cfg.setClientMode(true);
// Start a client
Ignite ignite = Ignition.start(cfg);
另外,还有个方便的方法,还可以通过Ignition类来启用或者禁用客户端模式,这样服务端和客户端就可以复用相同的配置。
- Java
- C#/.NET
- C++
Ignition.setClientMode(true);
// Start the node in client mode.
Ignite ignite = Ignition.start();
#3.停止节点
强制停止某个节点时,可能会导致数据丢失或数据不一致,甚至会使节点无法重启。当节点没有响应且无法正常关闭时,应将强制停止作为最后的手段。
正常停止可以使节点完成关键操作并正确完成其生命周期,执行正常停止的正确过程如下:
-
使用以下方法之一停止节点:
- 以编程方式调用
Ignite.close(); - 以编程方式调用
System.exit(); - 发送用户中断信号。Ignite使用JVM关闭钩子在JVM停止之前执行自定义逻辑。如果通过运行
ignite.sh来启动节点并且不将其与终端分离,则可以通过按下Ctrl+C来停止节点。
- 以编程方式调用
从基准拓扑中删除节点将在其余节点上开始再平衡过程。如果计划在停止后立即重启该节点,则不必进行再平衡。在这种情况下,请勿从基准拓扑中删除该节点。
#5.节点生命周期事件
生命周期事件使开发者有机会在节点生命周期的不同阶段执行自定义代码。
共有4个生命周期事件:
BEFORE_NODE_START:Ignite节点的启动程序初始化之前调用;AFTER_NODE_START:Ignite节点启动之后调用;BEFORE_NODE_STOP:Ignite节点的停止程序初始化之前调用;AFTER_NODE_STOP:Ignite节点停止之后调用。
下面的步骤介绍如何添加一个自定义生命周期事件监听器:
- 开发一个实现
LifecycleBean接口的类,该接口有一个onLifecycleEvent()方法,每个生命周期事件都会调用。
public class MyLifecycleBean implements LifecycleBean {
@IgniteInstanceResource
public Ignite ignite;
@Override
public void onLifecycleEvent(LifecycleEventType evt) {
if (evt == LifecycleEventType.AFTER_NODE_START) {
System.out.format("After the node (consistentId = %s) starts.\n", ignite.cluster().node().consistentId());
}
}
}
- 将该类注册到节点的配置中:
- XML
- Java
IgniteConfiguration cfg = new IgniteConfiguration();
// Specify a lifecycle bean in the node configuration.
cfg.setLifecycleBeans(new MyLifecycleBean());
// Start the node.
Ignite ignite = Ignition.start(cfg);
5.集群化
#1.概述
本章节会介绍节点间相互发现以形成集群的不同方式。
在启动时,将为节点分配以下两个角色之一:服务端节点或客户端节点。服务端节点是集群的主体,它们存储数据、执行计算任务等。客户端节点作为常规节点加入拓扑,但不存储数据。客户端节点用于将数据流传输到集群中并执行用户查询。
要组成集群,每个节点必须能够连接到所有其他节点。为了确保这一点,必须配置适当的发现机制。
提示
除了客户端节点,还可以使用瘦客户端来定义和操作集群中的数据,具体请参见瘦客户端章节的内容。

#1.1.发现机制
节点间可以自动相互发现并组成集群,这样就可以在需要时进行横向扩展,而不必重启整个集群。开发者还可以利用Ignite的混合云支持,其可以在私有云和公有云(例如Amazon Web Services)之间建立连接,从而提供更多样化的选择。
Ignite针对不同的场景,提供了两种发现机制:
- TCP/IP发现针对百级以内节点的集群规模进行了优化;
- ZooKeeper发现可将Ignite集群扩展到上千个节点,仍能保持线性扩展性和性能。
#2.TCP/IP发现
Ignite集群中,节点间可以通过DiscoverySpi相互发现。DiscoverySpi的默认实现是TcpDiscoverySpi,其使用的是TCP/IP协议,节点发现具体可以配置为基于组播或者基于静态IP模式。
#2.1.组播IP探测器
TcpDiscoveryMulticastIpFinder使用组播来发现每个节点,这也是默认的IP探测器,下面是通过配置文件以及编程模式进行配置的示例:
- XML
- Java
- C#/.NET
- C++
TcpDiscoverySpi spi = new TcpDiscoverySpi();
TcpDiscoveryMulticastIpFinder ipFinder = new TcpDiscoveryMulticastIpFinder();
ipFinder.setMulticastGroup("228.10.10.157");
spi.setIpFinder(ipFinder);
IgniteConfiguration cfg = new IgniteConfiguration();
// Override default discovery SPI.
cfg.setDiscoverySpi(spi);
// Start the node.
Ignite ignite = Ignition.start(cfg);
#2.2.静态IP探测器
静态IP探测器实现了TcpDiscoveryVmIpFinder,可以指定一组IP地址和端口,IP探测器将检查这些IP地址和端口以进行节点发现。
只需提供至少一个远程节点的IP地址即可,但是通常建议提供2或3个规划范围内节点的地址。一旦建立了与提供的任何IP地址的连接,Ignite就会自动发现所有其他节点。
提示
除了在配置文件中指定以外,还可以通过IGNITE_TCP_DISCOVERY_ADDRESSES环境变量或者同名的系统属性来指定,地址间用逗号分割,还可以选择包含端口范围。
提示
TcpDiscoveryVmIpFinder默认用于非共享模式。如果打算启动一个服务端节点,则IP地址列表也会包含本地节点的地址,这时该节点将不会等到其他节点加入集群,而是成为第一个集群节点并开始正常运行。
可以通过编程或者配置文件的方式配置静态IP探测器:
- XML
- Java
- C#/.NET
- Shell
TcpDiscoverySpi spi = new TcpDiscoverySpi();
TcpDiscoveryVmIpFinder ipFinder = new TcpDiscoveryVmIpFinder();
// Set initial IP addresses.
// Note that you can optionally specify a port or a port range.
ipFinder.setAddresses(Arrays.asList("1.2.3.4", "1.2.3.5:47500..47509"));
spi.setIpFinder(ipFinder);
IgniteConfiguration cfg = new IgniteConfiguration();
// Override default discovery SPI.
cfg.setDiscoverySpi(spi);
// Start a node.
Ignite ignite = Ignition.start(cfg);
警告
提供多个地址时,要确认这些地址都是有效的。无法访问的地址会增加节点加入集群所需的时间。假设设置了5个IP地址,但是其中2个没有监听输入连接,如果Ignite开始通过这2个无法访问的地址接入集群,它将影响节点的启动速度。
#2.3.静态和组播IP探测器
可以同时使用基于组播和静态IP的发现,这时TcpDiscoveryMulticastIpFinder除了可以接收来自组播的IP地址以外,还可以处理预定义的静态IP地址,和上述描述的静态IP发现一样,下面是如何配置带有静态IP地址的组播IP探测器的示例:
- XML
- Java
- C#/.NET
- C++
TcpDiscoverySpi spi = new TcpDiscoverySpi();
TcpDiscoveryMulticastIpFinder ipFinder = new TcpDiscoveryMulticastIpFinder();
// Set Multicast group.
ipFinder.setMulticastGroup("228.10.10.157");
// Set initial IP addresses.
// Note that you can optionally specify a port or a port range.
ipFinder.setAddresses(Arrays.asList("1.2.3.4", "1.2.3.5:47500..47509"));
spi.setIpFinder(ipFinder);
IgniteConfiguration cfg = new IgniteConfiguration();
// Override default discovery SPI.
cfg.setDiscoverySpi(spi);
// Start a node.
Ignite ignite = Ignition.start(cfg);
#2.4.同一组主机内的集群隔离
Ignite允许同一组主机内启动两个相互隔离的集群,这可以通过不同集群的节点的TcpDiscoverySpi和TcpCommunicationSpi使用不交叉的本地端口范围来实现。
假定为了测试,在一台主机上要启动两个隔离的集群,对于第一个集群的节点,可以使用下面的配置:
- XML
- Java
- C#/.NET
- C++
IgniteConfiguration firstCfg = new IgniteConfiguration();
firstCfg.setIgniteInstanceName("first");
// Explicitly configure TCP discovery SPI to provide list of initial nodes
// from the first cluster.
TcpDiscoverySpi firstDiscoverySpi = new TcpDiscoverySpi();
// Initial local port to listen to.
firstDiscoverySpi.setLocalPort(48500);
// Changing local port range. This is an optional action.
firstDiscoverySpi.setLocalPortRange(20);
TcpDiscoveryVmIpFinder firstIpFinder = new TcpDiscoveryVmIpFinder();
// Addresses and port range of the nodes from the first cluster.
// 127.0.0.1 can be replaced with actual IP addresses or host names.
// The port range is optional.
firstIpFinder.setAddresses(Collections.singletonList("127.0.0.1:48500..48520"));
// Overriding IP finder.
firstDiscoverySpi.setIpFinder(firstIpFinder);
// Explicitly configure TCP communication SPI by changing local port number for
// the nodes from the first cluster.
TcpCommunicationSpi firstCommSpi = new TcpCommunicationSpi();
firstCommSpi.setLocalPort(48100);
// Overriding discovery SPI.
firstCfg.setDiscoverySpi(firstDiscoverySpi);
// Overriding communication SPI.
firstCfg.setCommunicationSpi(firstCommSpi);
// Starting a node.
Ignition.start(firstCfg);
对于第二个集群,配置如下:
- XML
- Java
- C#/.NET
- C++
IgniteConfiguration secondCfg = new IgniteConfiguration();
secondCfg.setIgniteInstanceName("second");
// Explicitly configure TCP discovery SPI to provide list of initial nodes
// from the second cluster.
TcpDiscoverySpi secondDiscoverySpi = new TcpDiscoverySpi();
// Initial local port to listen to.
secondDiscoverySpi.setLocalPort(49500);
// Changing local port range. This is an optional action.
secondDiscoverySpi.setLocalPortRange(20);
TcpDiscoveryVmIpFinder secondIpFinder = new TcpDiscoveryVmIpFinder();
// Addresses and port range of the nodes from the second cluster.
// 127.0.0.1 can be replaced with actual IP addresses or host names.
// The port range is optional.
secondIpFinder.setAddresses(Collections.singletonList("127.0.0.1:49500..49520"));
// Overriding IP finder.
secondDiscoverySpi.setIpFinder(secondIpFinder);
// Explicitly configure TCP communication SPI by changing local port number for
// the nodes from the second cluster.
TcpCommunicationSpi secondCommSpi = new TcpCommunicationSpi();
secondCommSpi.setLocalPort(49100);
// Overriding discovery SPI.
secondCfg.setDiscoverySpi(secondDiscoverySpi);
// Overriding communication SPI.
secondCfg.setCommunicationSpi(secondCommSpi);
// Starting a node.
Ignition.start(secondCfg);
从配置可以看出,区别很小,仅是发现和通信SPI的端口号不同。
提示
如果希望来自不同集群的节点能够使用组播协议相互发现,需要将TcpDiscoveryVmIpFinder替换为TcpDiscoveryMulticastIpFinder并在上面的配置中设置惟一的TcpDiscoveryMulticastIpFinder.multicastGroups。
警告
如果隔离的集群开启了原生持久化,那么不同的集群需要在文件系统的不同路径下存储持久化文件,具体可以参见原生持久化的相关文档,来了解如何修改持久化相关的路径。
#2.5.基于JDBC的IP探测器
提示
.NET/C#/C++目前还不支持。
可以将数据库作为初始化IP地址的共享存储,使用这个IP探测器,节点会在启动时将IP地址写入数据库,这些都是通过TcpDiscoveryJdbcIpFinder实现的。
- XML
- Java
- C#/.NET
- C++
TcpDiscoverySpi spi = new TcpDiscoverySpi();
// Configure your DataSource.
DataSource someDs = new MySampleDataSource();
TcpDiscoveryJdbcIpFinder ipFinder = new TcpDiscoveryJdbcIpFinder();
ipFinder.setDataSource(someDs);
spi.setIpFinder(ipFinder);
IgniteConfiguration cfg = new IgniteConfiguration();
// Override default discovery SPI.
cfg.setDiscoverySpi(spi);
// Start the node.
Ignite ignite = Ignition.start(cfg);
#2.6.共享文件系统IP探测器
提示
.NET/C#/C++目前还不支持。
共享文件系统也可以作为节点IP地址的一个存储,节点会在启动时将IP地址写入文件系统,该功能通过TcpDiscoverySharedFsIpFinder实现。
- XML
- Java
- C#/.NET
- C++
// Configuring discovery SPI.
TcpDiscoverySpi spi = new TcpDiscoverySpi();
// Configuring IP finder.
TcpDiscoverySharedFsIpFinder ipFinder = new TcpDiscoverySharedFsIpFinder();
ipFinder.setPath("/var/ignite/addresses");
spi.setIpFinder(ipFinder);
IgniteConfiguration cfg = new IgniteConfiguration();
// Override default discovery SPI.
cfg.setDiscoverySpi(spi);
// Start the node.
Ignite ignite = Ignition.start(cfg);
#2.7.ZooKeeper IP探测器
提示
.NET/C#/C++目前还不支持。
使用TcpDiscoveryZookeeperIpFinder可以配置ZooKeeper IP探测器(注意需要启用ignite-zookeeper模块)。
- XML
- Java
- C#/.NET
- C++
TcpDiscoverySpi spi = new TcpDiscoverySpi();
TcpDiscoveryZookeeperIpFinder ipFinder = new TcpDiscoveryZookeeperIpFinder();
// Specify ZooKeeper connection string.
ipFinder.setZkConnectionString("127.0.0.1:2181");
spi.setIpFinder(ipFinder);
IgniteConfiguration cfg = new IgniteConfiguration();
// Override default discovery SPI.
cfg.setDiscoverySpi(spi);
// Start the node.
Ignite ignite = Ignition.start(cfg);
#3.ZooKeeper发现
Ignite使用TCP/IP发现机制,将集群节点组织成环状拓扑结构有其优点,也有缺点。比如在一个有上百个节点的拓扑中,系统消息遍历所有的节点需要花很多秒,就结果来说,基本的事件处理,比如新节点加入或者故障节点检测,就会影响整个集群的响应能力和性能。
ZooKeeper发现机制是为需要保证伸缩性和线性扩展的大规模Ignite集群而设计的。但是同时使用Ignite和ZooKeeper需要配置和管理两个分布式系统,这很有挑战性。因此,建议仅在打算扩展到成百或者上千个节点时才使用该发现机制。否则,最好使用TCP/IP发现。
ZooKeeper发现使用ZooKeeper作为同步的单点,然后将Ignite集群组织成一个星型拓扑,这时ZooKeeper集群位于中心,然后Ignite节点通过它进行发现事件的交换。

需要注意的是,ZooKeeper发现仅仅是发现机制的一个实现,不会影响Ignite节点间的通信。节点之间一旦通过ZooKeeper发现机制彼此发现,它们就会使用Communication SPI进行点对点的通信。
#3.1.配置
要启用ZooKeeper发现,需要配置ZooKeeperDiscoverySpi:
- XML
- Java
- C#/.NET
- C++
ZookeeperDiscoverySpi zkDiscoverySpi = new ZookeeperDiscoverySpi();
zkDiscoverySpi.setZkConnectionString("127.0.0.1:34076,127.0.0.1:43310,127.0.0.1:36745");
zkDiscoverySpi.setSessionTimeout(30_000);
zkDiscoverySpi.setZkRootPath("/ignite");
zkDiscoverySpi.setJoinTimeout(10_000);
IgniteConfiguration cfg = new IgniteConfiguration();
//Override default discovery SPI.
cfg.setDiscoverySpi(zkDiscoverySpi);
// Start the node.
Ignite ignite = Ignition.start(cfg);
下面两个参数是必须的(其它的是可选的):
zkConnectionString:ZooKeeper服务器地址列表;sessionTimeout:如果无法通过发现SPI进行事件消息的交换,多久之后节点会被视为断开连接。
#3.2.故障和脑裂处理
在网络分区的情况下,一些节点由于位于分离的网络段而不能相互通信,这可能导致处理用户请求失败或不一致的数据修改。
ZooKeeper发现机制通过如下的方式来处理网络分区(脑裂)以及单个节点之间的通信故障:
警告
假定集群中的所有节点都可以访问ZooKeeper集群。事实上,如果一个节点与ZooKeeper断开,那么它就会停止,然后其它节点就会将其视为故障或者失联。
当节点发现它不能连接到集群中的其它节点时,它就通过向ZooKeeper集群发布特殊请求来启动一个通信故障解决进程。该进程启动后,所有节点尝试彼此连接,并将连接尝试的结果发送到协调进程的节点(协调器节点)。基于此信息,协调器节点创建表示集群中的网络状况的连接图,而进一步的动作取决于网络分区的类型,下面的章节会介绍几种可能的场景。
#3.2.1.集群被分为若干个不相交的部分
如果集群被分成几个独立的部分,每个部分(作为一个集群)可能认为自己是一个主集群并继续处理用户请求,从而导致数据不一致。为了避免这种情况,只有节点数量最多的部分保持活动,而其它部分的节点会被关闭。

上图显示集群被分为了两个部分,小集群中的节点(右侧的部分)会被终止。

当有多个最大的部分时,具有最大数量的客户端的部分保持活动,而其它部分则关闭。
#3.2.2.节点间部分连接丢失
一些节点无法连接到其它一些节点,这意味着虽然这些节点没有完全与集群断开连接,但是无法与一些节点交换数据,因此不能成为集群的一部分。在下图中,一个节点不能连接到其它两个节点:

这时,任务就是找到每个节点可以连接到每个其它节点的最大部分,这通常是一个难题,在可接受的时间内无法解决。协调器节点会使用启发式算法来寻找最佳近似解,解中忽略的节点将被关闭。

#3.2.3.ZooKeeper集群分区
在大规模集群中,ZooKeeper集群可以跨越多个数据中心和地理上不同的位置,由于拓扑分割,它可以分成多个段。如果出现这种情况,ZooKeeper将检查是否存在一个包含所有ZooKeeper节点的一半以上的段(对于ZooKeeper继续其操作来说,需要这么多节点),如果找到,这个段将接管Ignite集群的管理,而其它段将被关闭。如果没有这样的段,ZooKeeper将关闭它的所有节点。
在ZooKeeper集群分区的情况下,Ignite集群可以分割也可以不分割。在任何情况下,当关闭ZooKeeper节点时,相应的Ignite节点将尝试连接到可用ZooKeeper节点,如果不能这样做,则将关闭。
下图是将Ignite集群和ZooKeeper集群分割成两个部分的拓扑分区示例。如果集群部署在两个数据中心,则可能出现这种情况。这时,位于数据中心B的ZooKeeper节点将自动关闭,而位于数据中心B的Ignite节点因为无法连接到其余ZooKeeper节点,因此也将关闭自己。

#3.3.自定义发现事件
将环形拓扑变更为星型拓扑,影响了发现SPI处理自定义发现事件的方式。因为环形拓扑是线性的,这意味着每个发现消息是被节点顺序处理的。
而在ZooKeeper发现机制中,协调器会同时将发现消息发送给所有节点,结果就是消息的并行处理,因此ZooKeeper发现机制不允许对自定义发现事件的修改,比如,节点不允许为发现消息添加任何内容。
#3.4.Ignite和ZooKeeper的配置一致性
使用ZooKeeper发现机制,需要确保两个系统的配置参数相互匹配不矛盾。
比如下面的ZooKeeper简单配置:
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
如果这样配置,只有过了tickTime * syncLimit时限,ZooKeeper服务器才会发觉它是否与剩余的ZooKeeper集群分区,在ZooKeeper的这段时间之内,所有的Ignite节点都会接入该已分割的ZooKeeper服务器,而不会与其它的ZooKeeper服务器进行连接。
另一方面,在Ignite端有一个sessionTimeout参数,它定义了如果节点与ZooKeeper集群断开,多长时间ZooKeeper会关闭Ignite节点的会话,如果sessionTimeout比tickTime * syncLimit小,那么Ignite节点就会被分割的ZooKeeper服务器过早地通知,即会话会在其试图连接其它的ZooKeeper服务器之前过期。
要避免这种情况发生,sessionTimeout要比tickTime * syncLimit大。
#4.云环境的发现
云上的节点发现通常认为很有挑战性,因为大部分的虚拟环境有如下的限制:
- 组播被禁用;
- 每次新的镜像启动时TCP地址会发生变化。
虽然在没有组播时可以使用基于TCP的发现,但是不得不处理不断变换的IP地址以及不断更新配置。这带来了很大的不便以至于在这种环境下基于静态IP的配置实质上变得不可用。
为了缓解不断变化的IP地址问题,Ignite设计了一组专门的IP探测器,用于支持云环境。
- Apache jclouds IP探测器
- Amazon S3 IP探测器
- Amazon ELB IP探测器
- Google云存储IP探测器
提示
基于云的IP探测器使得配置创建一次即可,之后所有的实例都可以复用。
#4.1.Apache jclouds IP探测器
为了解决不断变化的IP地址的问题,Ignite支持通过使用基于Apache jclouds多云工具包的TcpDiscoveryCloudIpFinder来实现节点的自动发现。要了解有关Apache jclouds的更多信息,请参照jclouds.apache.org。
该IP探测器通过获取云上所有虚拟机的私有和公有IP地址并给它们增加一个端口号来形成节点地址,该端口可以通过TcpDiscoverySpi.setLocalPort(int)或者TcpDiscoverySpi.DFLT_PORT进行设置,这样所有节点会连接任何生成的IP地址然后发起集群节点的自动发现。
可以参考这里来获取它支持的云平台的列表。
警告
所有虚拟机都要使用同一个端口启动Ignite实例,否则它们无法通过IP探测器发现对方。
下面是如何配置基于Apache jclouds的IP探测器的示例:
- XML
- Java
TcpDiscoverySpi spi = new TcpDiscoverySpi();
TcpDiscoveryCloudIpFinder ipFinder = new TcpDiscoveryCloudIpFinder();
// Configuration for AWS EC2.
ipFinder.setProvider("aws-ec2");
ipFinder.setIdentity("yourAccountId");
ipFinder.setCredential("yourAccountKey");
ipFinder.setRegions(Collections.singletonList("us-east-1"));
ipFinder.setZones(Arrays.asList("us-east-1b", "us-east-1e"));
spi.setIpFinder(ipFinder);
IgniteConfiguration cfg = new IgniteConfiguration();
// Override default discovery SPI.
cfg.setDiscoverySpi(spi);
// Start a node.
Ignition.start(cfg);
#4.2.Amazon S3 IP探测器
基于Amazon S3的发现可以使节点在启动时在Amazon S3存储上注册它们的IP地址,这样其它节点会尝试连接任意存储在S3上的IP地址然后发起集群节点的自动发现。至于使用,需要将ipFinder配置为TcpDiscoveryS3IpFinder。
提示
必须启用ignite-aws模块。
下面是如何配置基于Amazon S3的IP探测器的示例:
- XML
- Java
TcpDiscoverySpi spi = new TcpDiscoverySpi();
BasicAWSCredentials creds = new BasicAWSCredentials("yourAccessKey", "yourSecreteKey");
TcpDiscoveryS3IpFinder ipFinder = new TcpDiscoveryS3IpFinder();
ipFinder.setAwsCredentials(creds);
ipFinder.setBucketName("yourBucketName");
spi.setIpFinder(ipFinder);
IgniteConfiguration cfg = new IgniteConfiguration();
// Override default discovery SPI.
cfg.setDiscoverySpi(spi);
// Start a node.
Ignition.start(cfg);
还可以使用AWS凭据提供者的Instance Profile:
- XML
- Java
TcpDiscoverySpi spi = new TcpDiscoverySpi();
AWSCredentialsProvider instanceProfileCreds = new InstanceProfileCredentialsProvider(false);
TcpDiscoveryS3IpFinder ipFinder = new TcpDiscoveryS3IpFinder();
ipFinder.setAwsCredentialsProvider(instanceProfileCreds);
ipFinder.setBucketName("yourBucketName");
spi.setIpFinder(ipFinder);
IgniteConfiguration cfg = new IgniteConfiguration();
// Override default discovery SPI.
cfg.setDiscoverySpi(spi);
// Start a node.
Ignition.start(cfg);
#4.3.Amazon ELB IP探测器
基于AWS ELB的IP探测器不需要节点注册其IP地址,该IP探测器会自动获取ELB中连接的所有节点的地址,然后使用它们连接集群。至于使用,需要将ipFinder配置为TcpDiscoveryElbIpFinder。
下面是如何配置基于AWS ELB的IP探测器的示例:
- XML
- Java
TcpDiscoverySpi spi = new TcpDiscoverySpi();
BasicAWSCredentials creds = new BasicAWSCredentials("yourAccessKey", "yourSecreteKey");
TcpDiscoveryElbIpFinder ipFinder = new TcpDiscoveryElbIpFinder();
ipFinder.setRegion("yourElbRegion");
ipFinder.setLoadBalancerName("yourLoadBalancerName");
ipFinder.setCredentialsProvider(new AWSStaticCredentialsProvider(creds));
spi.setIpFinder(ipFinder);
IgniteConfiguration cfg = new IgniteConfiguration();
// Override default discovery SPI.
cfg.setDiscoverySpi(spi);
// Start the node.
Ignition.start(cfg);
#4.4.Google云存储IP探测器
Ignite支持通过使用基于Google云存储的TcpDiscoveryGoogleStorageIpFinder来实现节点的自动发现。在启动时节点在存储上注册它们的IP地址,然后通过读取配置发现其他节点。
提示
必须启用ignite-gce模块。
下面是如何配置基于Google云存储的IP探测器的示例:
- XML
- Java
TcpDiscoverySpi spi = new TcpDiscoverySpi();
TcpDiscoveryGoogleStorageIpFinder ipFinder = new TcpDiscoveryGoogleStorageIpFinder();
ipFinder.setServiceAccountId("yourServiceAccountId");
ipFinder.setServiceAccountP12FilePath("pathToYourP12Key");
ipFinder.setProjectName("yourGoogleClourPlatformProjectName");
// Bucket name must be unique across the whole Google Cloud Platform.
ipFinder.setBucketName("your_bucket_name");
spi.setIpFinder(ipFinder);
IgniteConfiguration cfg = new IgniteConfiguration();
// Override default discovery SPI.
cfg.setDiscoverySpi(spi);
// Start the node.
Ignition.start(cfg);
#5.网络配置
#5.1.IPv4和IPv6
Ignite尝试支持IPv4和IPv6,但这有时会导致集群分离的问题。一个可能的解决方案(除非确实需要IPv6)是通过设置-Djava.net.preferIPv4Stack=trueJVM参数限制Ignite使用IPv4。
#5.2.发现
本章节介绍默认发现机制的网络参数,该机制通过TcpDiscoverySpi类实现,通过TCP/IP协议交换发现消息。
可以通过如下方式调整该发现机制的参数:
- XML
- Java
IgniteConfiguration cfg = new IgniteConfiguration();
TcpDiscoverySpi discoverySpi = new TcpDiscoverySpi().setLocalPort(8300);
cfg.setDiscoverySpi(discoverySpi);
Ignite ignite = Ignition.start(cfg);
下表介绍了TcpDiscoverySpi最重要的参数,完整参数可以参见TcpDiscoverySpi的javadoc。
警告
应该使用将用于节点间通信的IP地址初始化IgniteConfiguration.localHost或TcpDiscoverySpi.localAddress参数。节点默认会绑定并监听其运行的主机上所有的可用IP地址,如果某些地址无法从其他集群节点访问,则会延长节点故障的检测时间。
| 属性 | 描述 | 默认值 |
|---|---|---|
localAddress | 设置用于发现的本地主机地址,配置该参数后,会覆盖IgniteConfiguration.localHost的配置。 | 节点默认会绑定到所有可用的网络地址,如果有可用的非回环地址,则使用java.net.InetAddress.getLocalHost()。 |
localPort | 设置节点绑定的端口,如果设置为非默认值,其他节点必须知道该端口以发现该节点。 | 47500 |
localPortRange | 如果localPort被占用,节点会尝试绑定下一个端口(加1),并且会持续这个过程直到找到可用的端口。localPortRange属性定义了节点会尝试的端口数量(从localPort开始)。 | 100 |
soLinger | 指定Discovery SPI使用的TCP套接字的关闭延迟超时。有关如何调整此设置的详细信息,请参见Java的Socket.setSoLingerAPI。在Ignite中,超时默认为非负值,以防止SSL连接潜在的死锁,但是副作用是可能会延长集群节点的故障检测。或者将JRE版本更新为已修复SSL问题的版本,并相应地调整此设置。 | 0 |
reconnectCount | 节点尝试与其他节点建立连接的次数。 | 10 |
networkTimeout | 网络操作的最大网络超时时间(毫秒)。 | 5000 |
socketTimeout | 套接字超时时间,这个超时时间用于限制连接时间和写套接字时间。 | 5000 |
ackTimeout | 发现消息的确认时间,如果超时时间内没有收到确认,那么发现SPI会尝试重新发送该消息。 | 5000 |
joinTimeout | 加入超时定义节点等待加入集群的时间。如果使用了非共享IP探测器,并且节点无法连接到IP探测器的任何地址,则该节点将继续尝试在此超时时间内加入。如果所有地址均无响应,则会引发异常并且节点终止。0意味着一直等待。 | 0 |
statisticsPrintFrequency | 定义节点将发现统计信息输出到日志的频率。0表示不输出,如果该值大于0,并且禁用了静默模式,则会每个周期以INFO级别输出一次统计信息。 | 0 |
#5.3.通信
在节点相互发现并组成集群之后,节点通过通信SPI交换消息。消息代表分布式集群操作,例如任务执行、数据修改操作、查询等。通信SPI的默认实现使用TCP/IP协议交换消息(TcpCommunicationSpi),本章节会介绍TcpCommunicationSpi的属性。
每个节点都打开一个本地通信端口和其他节点连接并发送消息的地址。在启动时,节点会尝试绑定到指定的通信端口(默认为47100)。如果端口已被使用,则节点会递增端口号,直到找到可用端口为止。尝试次数由localPortRange属性定义(默认为100)。
- XML
- Java
- C#/.NET
TcpCommunicationSpi commSpi = new TcpCommunicationSpi();
// Set the local port.
commSpi.setLocalPort(4321);
IgniteConfiguration cfg = new IgniteConfiguration();
cfg.setCommunicationSpi(commSpi);
// Start the node.
Ignite ignite = Ignition.start(cfg);
下面是TcpCommunicationSpi的一些重要参数,完整的参数请参见TcpCommunicationSpi的javadoc。
| 属性 | 描述 | 默认值 |
|---|---|---|
localAddress | 通信SPI绑定的本地主机地址,配置该参数后,会覆盖IgniteConfiguration.localHost的配置 | |
localPort | 节点用于通信的本地端口 | 47100 |
localPortRange | 节点尝试按顺序绑定的端口范围,直到找到可用的端口为止。 | 100 |
tcpNoDelay | 设置套接字选项TCP_NODELAY的值,每个创建或者接收的套接字都会使用这个值,它应该设置为true(默认),以减少通过TCP协议进行通讯期间请求/响应的时间。大多数情况下不建议改变这个选项。 | true |
idleConnectionTimeout | 设置当连接将要关闭时,最大空闲连接超时时间。 | 600000 |
usePairedConnections | 设置节点间是否要强制双向套接字连接的标志,如果设置为true,通信的节点间会建立两个独立的连接,一个用于出站消息,一个用于入站消息,如果设置为false,只会建立一个TCP连接用于双向通信,当消息的传递花费太长时间时,这个标志对于某些操作系统非常有用。 | false |
directBuffer | 在分配NIO直接缓冲区以及NIO堆缓冲区之间进行切换。虽然直接缓冲区执行的更好,但有时(尤其在Windows)可能会造成JVM崩溃,如果在自己的环境中发生了,需要将这个属性设置为false。 | true |
directSendBuffer | 当使用异步模式进行消息发送时,在分配NIO直接缓冲区以及NIO堆缓冲区之间进行切换。 | false |
socketReceiveBuffer | 设置通信SPI创建或者接收的套接字的接收缓冲区大小,如果配置为0,会使用操作系统默认值。 | 0 |
socketSendBuffer | 设置通信SPI创建或者接收的套接字的发送缓冲区大小,如果配置为0,会使用操作系统默认值。 | 0 |
#5.4.连接超时
连接超时由若干个属性定义:
| 属性 | 描述 | 默认值 |
|---|---|---|
IgniteConfiguration.failureDetectionTimeout | 服务端节点之间的基本网络操作超时。 | 10000 |
IgniteConfiguration.clientFailureDetectionTimeout | 客户端节点之间的基本网络操作超时。 | 30000 |
可以在节点配置中设置故障检测超时,如下所示。默认值使发现SPI在大多数本地环境和容器化环境中都能可靠地工作。但是在稳定的低延迟网络中,可以将参数设置为约200毫秒,以便更快地检测故障并对故障做出响应。
- XML
- Java
IgniteConfiguration cfg = new IgniteConfiguration();
cfg.setFailureDetectionTimeout(5_000);
cfg.setClientFailureDetectionTimeout(10_000);
#6.客户端节点连接
#6.1.客户端节点重连
有几种情况客户端会从集群中断开:
- 由于网络原因,客户端无法和服务端重建连接;
- 与服务端的连接有时被断开,客户端也可以重建与服务端的连接,但是由于服务端无法获得客户端心跳,服务端仍然断开客户端节点;
- 慢客户端会被服务端节点踢出。
当一个客户端发现它与一个集群断开时,会为自己赋予一个新的节点ID然后试图与该服务端重新连接。注意这会产生一个副作用,就是当客户端重建连接时本地ClusterNode的id属性会发生变化,这意味着,如果业务逻辑依赖于这个id,就会受到影响。
在节点配置中可以禁用客户端重连:
- XML
- Java
IgniteConfiguration cfg = new IgniteConfiguration();
TcpDiscoverySpi discoverySpi = new TcpDiscoverySpi();
discoverySpi.setClientReconnectDisabled(true);
cfg.setDiscoverySpi(discoverySpi);
当客户端处于一个断开状态并且试图重建与集群的连接过程中时,Ignite API会抛出一个IgniteClientDisconnectedException异常,这个异常提供了一个Future表示重连操作,可以使用这个Future来等待操作完成。
IgniteCache cache = ignite.getOrCreateCache(new CacheConfiguration<>("myCache"));
try {
cache.put(1, "value");
} catch (IgniteClientDisconnectedException e) {
if (e.getCause() instanceof IgniteClientDisconnectedException) {
IgniteClientDisconnectedException cause = (IgniteClientDisconnectedException) e.getCause();
cause.reconnectFuture().get(); // Wait until the client is reconnected.
// proceed
}
}
#6.2.客户端断连/重连事件
客户端断连/重连集群时也会在客户端触发两个发现事件:
EVT_CLIENT_NODE_DISCONNECTEDEVT_CLIENT_NODE_RECONNECTED
可以监听这些事件然后执行自定义的逻辑,具体请参见事件监听章节的内容。
#6.3.管理慢客户端
很多环境中,客户端节点是在主集群外启动的,机器和网络都比较差,而有时服务端可能会产生负载(比如持续查询通知)而客户端没有能力处理,导致服务端的输出消息队列不断增长,这可能最终导致服务端出现内存溢出或者导致整个集群阻塞。
要管理这样的状况,可以配置允许向客户端节点输出消息的最大值,如果输出队列的大小超过配置的值,该客户端节点会从集群断开。
下面是如何配置慢客户端队列限值的示例:
- XML
- Java
IgniteConfiguration cfg = new IgniteConfiguration();
cfg.setClientMode(true);
TcpCommunicationSpi commSpi = new TcpCommunicationSpi();
commSpi.setSlowClientQueueLimit(1000);
cfg.setCommunicationSpi(commSpi);
#7.基线拓扑
基准拓扑是一组持有数据数据的节点。引入基线拓扑概念是为了能够控制数据再平衡的时机。例如,如果有一个由3个节点组成的集群,并且数据分布在这些节点上,然后又添加了2个节点,则再平衡过程将在所有5个节点之间重新分配数据。再平衡过程发生在基线拓扑更改时,可以自动发生也可以手动触发。
基线拓扑仅包括服务端节点,不包括客户端节点,因为它们不存储数据。
基线拓扑的目的是:
- 当服务端节点短时间离开集群时,例如由于偶发的网络故障或计划内的服务器维护,可以避免不必要的数据移动;
- 可以控制数据再平衡的时机。
当基线拓扑自动调整功能启用后,基线拓扑会自动改变。这是纯内存集群的默认行为,但是对于开启持久化的集群,必须手动启用基线拓扑自动调整功能。该选项默认是禁用的,必须手动更改基线拓扑,可以使用控制脚本来更改基线拓扑。
警告
基线拓扑变更过程中尝试创建缓存会抛出异常,详细信息请参见动态创建缓存。
#7.1.纯内存集群的基线拓扑
在纯内存集群中,在集群中添加或删除服务端节点默认是自动将基线拓扑调整为所有服务端节点的集合,数据也会自动再平衡,这个行为可以禁用并手动管理基线拓扑。
提示
在以前的版本中,基线拓扑仅与开启持久化的集群有关。但是从2.8.0版开始,它也适用于纯内存集群。如果用户有一个纯内存集群,则该变化对用户是透明的,因为基线拓扑默认会在服务端节点离开或加入集群时自动更改。
#7.2.持久化集群的基线拓扑
如果集群中只要有一个数据区启用了持久化,则首次启动时该集群将处于非激活状态。在非激活状态下,所有操作将被禁止,必须先激活集群然后才能创建缓存和注入数据。集群激活会将当前服务端节点集合设置为基线拓扑。重启集群时,只要基线拓扑中注册的所有节点都加入,集群将自动激活,否则必须手动激活集群。
如下方式中的任何一个,都可以激活集群:
- 控制脚本;
- REST API命令;
- 编程式:
- Java
- C#/.NET
Ignite ignite = Ignition.start();
ignite.cluster().state(ClusterState.ACTIVE);
#7.3.基线拓扑自动调整
如果不想手动调整基线拓扑,还可以让集群自动调整基线拓扑。此功能称为基线拓扑自动调整。启用后集群将监控其服务端节点的状态,并在集群拓扑稳定一段可配置的时间后自动设置当前拓扑的基线。
当集群中的节点集发生变更时,将发生以下情况:
- Ignite会等待一个可配置的时间(默认为5分钟);
- 如果在此期间拓扑中没有其他变更,则Ignite会将基线拓扑设置为当前节点集;
- 如果在此期间节点集发生更改,则会更新超时时间。
这些节点集的每个变更都会重置自动调整的超时时间。当超时过期且当前节点集与基线拓扑不同(例如存在新节点或一些旧节点离开)时,Ignite将更改基线拓扑以匹配当前节点集,这也会触发数据再平衡。
自动调整超时使用户可以在节点由于临时性网络问题而短时间断开连接或希望快速重启节点时避免数据再平衡。如果希望节点集的临时变更不更改基线拓扑,则可以将超时设置为更高的值。
只有当集群处于激活状态时,基线拓扑才会自动调整。
可以使用控制脚本开启该功能,还可以通过编程方式启用该功能。
- Java
- C#/.NET
Ignite ignite = Ignition.start();
ignite.cluster().baselineAutoAdjustEnabled(true);
ignite.cluster().baselineAutoAdjustTimeout(30000);
如果要禁用基线的自动调整,可以使用同样的方法,但是传入值为false:
- Java
- C#/.NET
ignite.cluster().baselineAutoAdjustEnabled(false);
#7.4.监控基线拓扑
可以使用下面的工具监控/管理基线:
#8.在NAT之后运行客户端节点
如果客户端节点部署在NAT之后,则由于通信协议的限制,服务端节点将无法与客户端建立连接。这包括客户端节点在虚拟环境(例如Kubernetes)中运行并且服务器节点部署在其他位置时的部署情况。
对于这种情况,需要启用一种特殊的通信模式:
- XML
- Java
IgniteConfiguration cfg = new IgniteConfiguration();
cfg.setClientMode(true);
cfg.setCommunicationSpi(new TcpCommunicationSpi().setForceClientToServerConnections(true));
#8.1.限制
- 在服务端和客户端节点上当
TcpCommunicationSpi.usePairedConnections = true时均不能使用此模式; - 从客户端节点启动持续查询(
forceClientToServerConnections = true)时,持续查询(转换器和过滤器)的对等类加载不起作用。需要将相应的类添加到每个服务端节点的类路径中; - 此属性只能在客户端节点上使用,此限制将在以后的版本中解决。
6.瘦客户端
#1.瘦客户端介绍
#1.1.概述
瘦客户端是一个使用标准套接字连接接入集群的轻量级的Ignite客户端,它不会成为集群拓扑的一部分,也不持有任何数据,也不会参与计算。它所做的只是简单地建立一个与标准Ignite节点的套接字连接,并通过该节点执行所有操作。
瘦客户端基于二进制客户端协议,这样任何语言都可以接入Ignite集群,目前如下的客户端可用:
- Java瘦客户端
- .NET/C#瘦客户端
- C++瘦客户端
- Node.js瘦客户端
- Python瘦客户端
- PHP瘦客户端
#1.2.瘦客户端特性
下表列出了每个客户端支持的特性:
| 瘦客户端特性 | Java | .NET | C++ | Python | Node.js | PHP |
|---|---|---|---|---|---|---|
扫描查询 | 是 | 是 | 否 | 是 | 是 | 是 |
支持过滤器的扫描查询 | 是 | 是 | 否 | 否 | 否 | 否 |
SqlFieldsQuery | 是 | 是 | 否 | 是 | 是 | 是 |
二进制对象API | 是 | 是 | 否 | 否 | 是 | 是 |
异步操作 | 是 | 是 | 否 | 是 | 是 | 是 |
SSL/TLS | 是 | 是 | 是 | 是 | 是 | 是 |
认证 | 是 | 是 | 是 | 是 | 是 | 是 |
分区感知 | 是 | 是 | 是 | 是 | 是 | 否 |
故障转移 | 是 | 是 | 是 | 是 | 是 | 是 |
事务 | 是 | 是 | 否 | 否 | 否 | 否 |
集群API | 是 | 是 | 否 | 否 | 否 | 否 |
集群发现 | 否 | 是 | 否 | 否 | 否 | 否 |
计算 | 是 | 是 | 否 | 否 | 否 | 否 |
服务调用 | 是 | 是 | 否 | 否 | 否 | 否 |
服务端发现 | 否 | 是 | 否 | 否 | 否 | 否 |
Kubernetes中的服务端发现 | 是 | 否 | 否 | 否 | 否 | 否 |
#1.2.1.客户端连接故障转移
所有瘦客户端均支持连接故障转移机制,在当前节点或连接失败时,客户端可自动切换到可用节点。为了使该机制生效,需要在客户端配置中提供用于故障转移节点的地址列表,具体请参见相关的客户端文档。
#1.2.2.分区感知
如数据分区章节所述,出于可伸缩性和性能方面的考虑,集群中的数据会在节点间平均分布。每个集群节点都维护数据和分区分布图的子集,用于确定持有所请求条目的主/备份副本的节点。
分区感知使得瘦客户端可以将查询请求直接发送到持有待查询数据的节点。
警告
分区感知是一项实验性功能,正式发布之前,其API或设计架构可能会更改。
在没有分区感知时,通过瘦客户端接入集群的应用,实际是通过某个作为代理的服务端节点执行所有查询和操作,然后将这些操作重新路由到数据所在的节点,这会导致瓶颈,可能会限制应用的线性扩展能力。

注意查询必须通过代理服务端节点,然后路由到正确的节点。
有了分区感知之后,瘦客户端可以将查询和操作直接路由到持有待处理数据的主节点,这消除了瓶颈,使应用更易于扩展。
?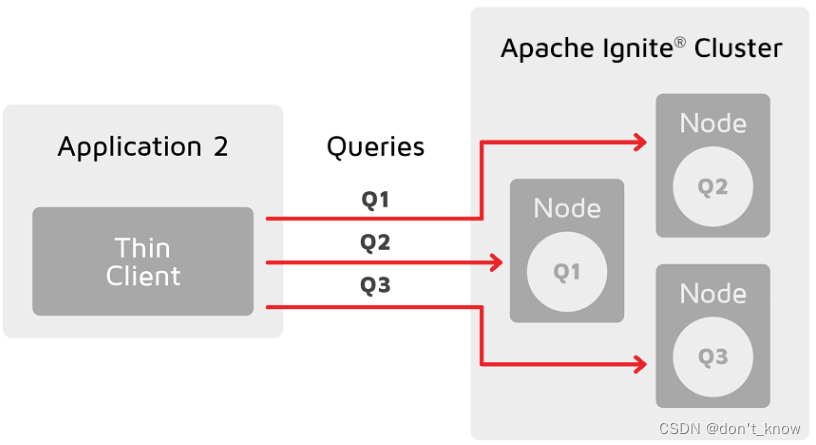 ?警告
?警告
注意目前需要在连接属性中提供所有服务端节点的地址。这意味着如果新的服务端节点加入集群,则应将新服务端的地址添加到连接属性中,然后重新连接。否则,瘦客户端将无法向该服务端发送直接请求,正式发布之后将解决此限制。
#1.2.3.认证
所有瘦客户端都支持集群的身份验证。身份验证是在集群配置中配置的,客户端仅提供用户凭据。更多的信息请参考特定客户端的文档。
#1.3.集群配置
瘦客户端连接参数是由客户端连接器配置控制的。Ignite默认在端口10800上接受客户端连接。端口、连接缓冲区大小和超时、启用SSL/TLS等都是可以修改的。
#1.3.1.配置瘦客户端连接器
以下示例显示了如何配置瘦客户端连接参数:
- XML
- Java
- C#/.NET
ClientConnectorConfiguration clientConnectorCfg = new ClientConnectorConfiguration();
// Set a port range from 10000 to 10005
clientConnectorCfg.setPort(10000);
clientConnectorCfg.setPortRange(5);
IgniteConfiguration cfg = new IgniteConfiguration().setClientConnectorConfiguration(clientConnectorCfg);
// Start a node
Ignite ignite = Ignition.start(cfg);
下表中列出了可能需要修改的一些参数:
| 参数 | 描述 | 默认值 |
|---|---|---|
thinClientEnabled | 启用/禁用客户端接入 | true |
port | 瘦客户端连接端口 | 10800 |
portRange | 此参数设置瘦客户端连接的端口范围。例如,如果portRange=10,则瘦客户端可以连接到10800–18010范围内的任何端口。节点会尝试绑定从port开始的范围内的每个端口,直到找到可用端口为止。如果所有端口都不可用,则该节点将无法启动。 | 100 |
sslEnabled | 将此属性配置为true,可以为瘦客户端连接启用SSL。 | false |
完整的参数列表,请参见ClientConnectorConfiguration的javadoc。
#1.3.2.为瘦客户端启用SSL/TLS
参见瘦客户端和JDBC/ODBC的SSL/TLS章节的内容。
#2.Java瘦客户端
#2.1.概述
Java瘦客户端是一个使用标准套接字连接接入集群的轻量级的Ignite客户端,它不会成为集群拓扑的一部分,也不持有任何数据,也不会参与计算。它所做的只是简单地建立一个与标准Ignite节点的套接字连接,并通过该节点执行所有操作。
#2.2.配置
如果使用Maven或者Gradle,需要向应用中添加ignite-core依赖:
- Maven
- Gradle
<properties>
<ignite.version>2.10.0</ignite.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.ignite</groupId>
<artifactId>ignite-core</artifactId>
<version>${ignite.version}</version>
</dependency>
</dependencies>
或者,也可以直接使用二进制包中的ignite-core-2.10.0.jar。
#2.3.接入集群
可以使用Ignition.startClient(ClientConfiguration)方法初始化瘦客户端,该方法接受一个定义了客户端连接参数的ClientConfiguration对象。
该方法返回IgniteClient接口,提供了访问数据的各种方法。IgniteClient是一个自动关闭的资源,因此可以使用try-with-resources语句来关闭瘦客户端并且释放连接相关的资源。
ClientConfiguration cfg = new ClientConfiguration().setAddresses("127.0.0.1:10800");
try (IgniteClient client = Ignition.startClient(cfg)) {
ClientCache<Integer, String> cache = client.cache("myCache");
// Get data from the cache
}
可以提供多个节点的地址,这时瘦客户端会随机接入列表中的服务端,如果都不可达,则抛出ClientConnectionException。
try (IgniteClient client = Ignition.startClient(new ClientConfiguration().setAddresses("node1_address:10800",
"node2_address:10800", "node3_address:10800"))) {
} catch (ClientConnectionException ex) {
// All the servers are unavailable
}
注意,如果服务端故障,上述代码提供了一个故障转移的机制,具体请参见下面的处理节点故障相关章节的内容。
#2.4.分区感知
分区感知使得瘦客户端可以将请求直接发给待处理数据所在的节点。
警告
分区感知是一个试验性特性,在正式发布之前,API和设计架构可能会修改。
在没有分区感知时,通过瘦客户端接入集群的应用,实际是通过某个作为代理的服务端节点执行所有查询和操作,然后将这些操作重新路由到数据所在的节点,这会导致瓶颈,可能会限制应用的线性扩展能力。
注意查询必须通过代理服务端节点,然后路由到正确的节点。
有了分区感知之后,瘦客户端可以将查询和操作直接路由到持有待处理数据的主节点,这消除了瓶颈,使应用更易于扩展。

警告
注意目前对于非Java客户端需要在连接属性中提供所有服务端节点的地址。这意味着如果新的服务端节点加入集群,则应将新服务端的地址添加到连接属性中,然后重新连接。否则,瘦客户端将无法向该服务端发送直接请求,正式发布之后将解决此限制。
下面的示例介绍了Java瘦客户端中分区感知功能的使用方法:
ClientConfiguration cfg = new ClientConfiguration()
.setAddresses("node1_address:10800", "node2_address:10800", "node3_address:10800")
.setPartitionAwarenessEnabled(true);
try (IgniteClient client = Ignition.startClient(cfg)) {
ClientCache<Integer, String> cache = client.cache("myCache");
// Put, get or remove data from the cache...
} catch (ClientException e) {
System.err.println(e.getMessage());
}
如果服务端节点列表动态地变化或者扩展,则可以使用ClientAddressFinder的自定义实现配置连接。当客户端发送连接请求时,应提供一组当前的服务器地址。下面的代码示例说明了使用方法:
ClientAddressFinder finder = () -> {
String[] dynamicServerAddresses = fetchServerAddresses();
return dynamicServerAddresses;
};
ClientConfiguration cfg = new ClientConfiguration()
.setAddressFinder(finder)
.setPartitionAwarenessEnabled(true);
try (IgniteClient client = Ignition.startClient(cfg)) {
ClientCache<Integer, String> cache = client.cache("myCache");
// Put, get, or remove data from the cache...
} catch (ClientException e) {
System.err.println(e.getMessage());
}
该代码段显示了如果希望客户端动态探测服务端地址,应如何实现的示例。
ClientAddressFinder是一个函数式接口,提供了唯一的方法getAddresses();- 该
fetchServerAddress()是一个自定义函数,动态地提供服务端地址; - 使用
ClientConfiguration.setAddressFinder(finder)配置客户端。
另外,还可以查看接口实现的真实示例,现成的ThinClientKubernetesAddressFinder可用于可扩展的Kubernetes环境。
#2.5.使用键-值API
Java瘦客户端支持胖客户端可以用的大多数键-值操作,要在某个缓存上执行键-值操作,需要先拿到该缓存的实例,然后调用他的方法。
#2.5.1.获取缓存的实例
ClientCacheAPI提供了键-值操作API,通过如下的方法可以获得ClientCache的实例:
IgniteClient.cache(String):假定给定名字的缓存已存在,该方法不会与集群通信确认缓存是否真实存在,如果缓存不存在之后的缓存操作会报错;IgniteClient.getOrCreateCache(String),IgniteClient.getOrCreateCache(ClientCacheConfiguration):获取指定名字的缓存,如果不存在则会创建该缓存,创建时会使用默认的配置;IgniteClient.createCache(String),IgniteClient.createCache(ClientCacheConfiguration):创建指定名字的缓存,如果已经存在则会报错;
使用IgniteClient.cacheNames()可以列出所有已有的缓存。
ClientCacheConfiguration cacheCfg = new ClientCacheConfiguration().setName("References")
.setCacheMode(CacheMode.REPLICATED)
.setWriteSynchronizationMode(CacheWriteSynchronizationMode.FULL_SYNC);
ClientCache<Integer, String> cache = client.getOrCreateCache(cacheCfg);
#2.5.2.基本缓存操作
下面的代码片段演示了如何从瘦客户端执行基本的缓存操作:
Map<Integer, String> data = IntStream.rangeClosed(1, 100).boxed()
.collect(Collectors.toMap(i -> i, Object::toString));
cache.putAll(data);
assert !cache.replace(1, "2", "3");
assert "1".equals(cache.get(1));
assert cache.replace(1, "1", "3");
assert "3".equals(cache.get(1));
cache.put(101, "101");
cache.removeAll(data.keySet());
assert cache.size() == 1;
assert "101".equals(cache.get(101));
cache.removeAll();
assert 0 == cache.size();
#2.5.3.执行扫描查询
使用ScanQuery<K, V>类可获得一组满足给定条件的条目,瘦客户端将查询发送到集群节点,在集群节点上将其作为普通扫描查询执行。
查询条件由一个IgniteBiPredicate<K, V>对象指定,该对象作为参数传递给查询构造函数。谓词应用于服务器端,如果未提供任何谓词,查询将返回所有缓存条目。
提示
谓词的类必须在集群的服务端节点上可用。
查询结果是按页传输到客户端的,每个页面包含固定数量的条目,仅在请求该页面的条目时才将其提取到客户端。要更改页面中的条目数,需要使用ScanQuery.setPageSize(int pageSize)方法(默认值为1024)。
ClientCache<Integer, Person> personCache = client.getOrCreateCache("personCache");
Query<Cache.Entry<Integer, Person>> qry = new ScanQuery<Integer, Person>(
(i, p) -> p.getName().contains("Smith"));
try (QueryCursor<Cache.Entry<Integer, Person>> cur = personCache.query(qry)) {
for (Cache.Entry<Integer, Person> entry : cur) {
// Process the entry ...
}
}
IgniteClient.query(…?)方法会返回FieldsQueryCursor的实例,要确保对结果集进行遍历后将其关闭。
#2.5.4.事务
如果缓存为AtomicityMode.TRANSACTIONAL模式,则客户端支持事务。
#2.5.4.1.执行事务
要开始事务,需要从IgniteClient中拿到ClientTransactions对象。ClientTransactions中有一组txStart(…?)方法,每个都会开启一个新的事务然后返回一个表示事务的ClientTransaction对象,使用该对象可以对事务进行提交或者回滚。
ClientCache<Integer, String> cache = client.cache("my_transactional_cache");
ClientTransactions tx = client.transactions();
try (ClientTransaction t = tx.txStart()) {
cache.put(1, "new value");
t.commit();
}
#2.5.4.2.事务配置
客户端事务可以有不同的并发模型和隔离级别,以及执行超时,这些都可以在所有事务上进行配置,也可以针对单个事务进行配置。
ClientConfiguration可以配置该客户端接口启动的所有事务默认的并发模型、隔离级别和超时时间:
ClientConfiguration cfg = new ClientConfiguration();
cfg.setAddresses("localhost:10800");
cfg.setTransactionConfiguration(new ClientTransactionConfiguration().setDefaultTxTimeout(10000)
.setDefaultTxConcurrency(TransactionConcurrency.OPTIMISTIC)
.setDefaultTxIsolation(TransactionIsolation.REPEATABLE_READ));
IgniteClient client = Ignition.startClient(cfg);
开启某个事务时,也可以单独指定并发模型、隔离级别和超时时间,这时提供的值就会覆盖默认的值:
ClientTransactions tx = client.transactions();
try (ClientTransaction t = tx.txStart(TransactionConcurrency.OPTIMISTIC,
TransactionIsolation.REPEATABLE_READ)) {
cache.put(1, "new value");
t.commit();
}
#2.5.5.处理二进制对象
瘦客户端完全支持处理二进制对象章节中介绍的二进制对象API,使用CacheClient.withKeepBinary()可以将缓存切换到二进制模式,然后就可以直接处理二进制对象而避免序列化/反序列化。使用IgniteClient.binary()可以获取一个IgniteBinary的实例,然后就可以从头开始构建一个对象。
IgniteBinary binary = client.binary();
BinaryObject val = binary.builder("Person").setField("id", 1, int.class).setField("name", "Joe", String.class)
.build();
ClientCache<Integer, BinaryObject> cache = client.cache("persons").withKeepBinary();
cache.put(1, val);
BinaryObject value = cache.get(1);
#2.6.执行SQL语句
Java瘦客户端提供了一个SQL API来执行SQL语句,SQL语句通过SqlFieldsQuery对象来声明,然后通过IgniteClient.query(SqlFieldsQuery)来执行。
client.query(new SqlFieldsQuery(String.format(
"CREATE TABLE IF NOT EXISTS Person (id INT PRIMARY KEY, name VARCHAR) WITH \"VALUE_TYPE=%s\"",
Person.class.getName())).setSchema("PUBLIC")).getAll();
int key = 1;
Person val = new Person(key, "Person 1");
client.query(new SqlFieldsQuery("INSERT INTO Person(id, name) VALUES(?, ?)").setArgs(val.getId(), val.getName())
.setSchema("PUBLIC")).getAll();
FieldsQueryCursor<List<?>> cursor = client
.query(new SqlFieldsQuery("SELECT name from Person WHERE id=?").setArgs(key).setSchema("PUBLIC"));
// Get the results; the `getAll()` methods closes the cursor; you do not have to
// call cursor.close();
List<List<?>> results = cursor.getAll();
results.stream().findFirst().ifPresent(columns -> {
System.out.println("name = " + columns.get(0));
});
query(SqlFieldsQuery)方法会返回一个FieldsQueryCursor的实例,可以用于对结果集进行迭代,使用完毕后,一定要关闭以释放相关的资源。
提示
getAll()方法会从游标中拿到所有的结果集,然后将其关闭。
SqlFieldsQuery的使用以及SQL API方面的更多信息,请参见使用SQL API章节的内容。
#2.7.使用集群API
集群API可以用于创建集群组然后在这个组中执行各种操作。ClientCluster接口是该API的入口,用处如下:
- 获取或者修改集群的状态;
- 获取集群所有节点的列表;
- 创建集群节点的逻辑组,然后使用其他的Ignite API在组中执行某个操作。
使用IgniteClient实例可以获得ClientCluster接口的引用。
try (IgniteClient client = Ignition.startClient(clientCfg)) {
ClientCluster clientCluster = client.cluster();
clientCluster.state(ClusterState.ACTIVE);
}
#2.7.1.节点逻辑分组
可以使用集群API的ClientClusterGroup接口来创建集群节点的各种组合。比如,一个组可以包含所有的服务端节点,而另一组可以仅包含与某TCP/IP地址格式匹配的那些节点,下面的示例显示如何创建位于dc1数据中心的一组服务端节点:
try (IgniteClient client = Ignition.startClient(clientCfg)) {
ClientClusterGroup serversInDc1 = client.cluster().forServers().forAttribute("dc", "dc1");
serversInDc1.nodes().forEach(n -> System.out.println("Node ID: " + n.id()));
}
关于这个功能的更多信息,请参见集群组的相关文档。
#2.8.执行计算任务
当前,Java瘦客户端通过执行集群中已经部署的计算任务来支持基本的计算功能。可以跨所有集群节点或某集群组运行任务。这个环境要求将计算任务打包成一个JAR文件,并将其添加到集群节点的类路径中。
由瘦客户端触发的任务执行默认在集群侧被禁用。需要在服务端节点和胖客户端节点将ThinClientConfiguration.maxActiveComputeTasksPerConnection参数设置为非零值:
- XML
- Java
ThinClientConfiguration thinClientCfg = new ThinClientConfiguration()
.setMaxActiveComputeTasksPerConnection(100);
ClientConnectorConfiguration clientConnectorCfg = new ClientConnectorConfiguration()
.setThinClientConfiguration(thinClientCfg);
IgniteConfiguration igniteCfg = new IgniteConfiguration()
.setClientConnectorConfiguration(clientConnectorCfg);
Ignite ignite = Ignition.start(igniteCfg);
下面的示例显示如果通过ClientCompute接口访问计算API,然后执行名为MyTask的计算任务:
try (IgniteClient client = Ignition.startClient(clientCfg)) {
// Suppose that the MyTask class is already deployed in the cluster
client.compute().execute(
MyTask.class.getName(), "argument");
}
#2.9.执行Ignite服务
可以使用Java瘦客户端的ClientServices接口调用一个集群中已经部署的Ignite服务。
下面的示例显示如何调用名为MyService的服务:
try (IgniteClient client = Ignition.startClient(clientCfg)) {
// Executing the service named MyService
// that is already deployed in the cluster.
client.services().serviceProxy(
"MyService", MyService.class).myServiceMethod();
}
部署的服务可以通过Java或者.NET实现。
#2.10.处理异常
#2.10.1.处理节点故障
当在客户端配置中提供多个节点的地址时,如果当前连接失败,客户端将自动切换到下一个节点,然后重试任何正在进行的操作。
对于原子操作,故障转移到另一个节点对用户是透明的。但是如果执行的是扫描查询或SELECT查询,则查询游标上的迭代可能会抛出ClientConnectionException。之所以会发生这种情况,是因为查询是按页返回数据,并且如果在客户端检索页面时客户端连接到的节点故障,则会抛出异常以保持查询结果的一致性。
如果启动了显式事务,则在服务端节点故障时,绑定到该事务的缓存操作也会抛出ClientException异常。
用户代码应处理这些异常并相应地实现重试逻辑。
#2.11.安全
#2.11.1.SSL/TLS
要在瘦客户端和集群之间使用加密的通信,必须在集群配置和客户端配置中都启用SSL/TLS。有关集群配置的说明,请参见瘦客户端启用SSL/TLS章节的介绍。
要在瘦客户端中启用加密的通信,请在瘦客户端配置中提供一个包含加密密钥的密钥库和一个具有受信任证书的信任库:
ClientConfiguration clientCfg = new ClientConfiguration().setAddresses("127.0.0.1:10800");
clientCfg.setSslMode(SslMode.REQUIRED).setSslClientCertificateKeyStorePath(KEYSTORE)
.setSslClientCertificateKeyStoreType("JKS").setSslClientCertificateKeyStorePassword("123456")
.setSslTrustCertificateKeyStorePath(TRUSTSTORE).setSslTrustCertificateKeyStorePassword("123456")
.setSslTrustCertificateKeyStoreType("JKS").setSslKeyAlgorithm("SunX509").setSslTrustAll(false)
.setSslProtocol(SslProtocol.TLS);
try (IgniteClient client = Ignition.startClient(clientCfg)) {
// ...
}
下表介绍了客户端连接的加密参数:
| 属性 | 描述 | 默认值 |
|---|---|---|
sslMode | REQURED或者DISABLED | DISABLED |
sslClientCertificateKeyStorePath | 私钥密钥库文件的路径 | |
sslClientCertificateKeyStoreType | 密钥库的类型 | JKS |
sslClientCertificateKeyStorePassword | 密钥库的密码 | |
sslTrustCertificateKeyStorePath | 信任库文件的路径 | |
sslTrustCertificateKeyStoreType | 信任库的类型 | JKS |
sslTrustCertificateKeyStorePassword | 信任库的密码 | |
sslKeyAlgorithm | 用于创建密钥管理器的密钥管理器算法 | SunX509 |
sslTrustAll | 如果配置为true,则不验证证书 | |
sslProtocol | 用于数据加密的协议名 | TLS |
#2.11.2.认证
配置集群侧的认证,然后在客户端配置中提供用户名和密码:
ClientConfiguration clientCfg = new ClientConfiguration().setAddresses("127.0.0.1:10800").setUserName("joe")
.setUserPassword("passw0rd!");
try (IgniteClient client = Ignition.startClient(clientCfg)) {
// ...
} catch (ClientAuthenticationException e) {
// Handle authentication failure
}
#2.12.异步API
大多数绑定到网络的瘦客户端API都有一个对应的异步API,比如ClientCache.get和ClientCache.getAsync。
IgniteClient client = Ignition.startClient(clientCfg);
ClientCache<Integer, String> cache = client.getOrCreateCache("cache");
IgniteClientFuture<Void> putFut = cache.putAsync(1, "hello");
putFut.get(); // Blocking wait.
IgniteClientFuture<String> getFut = cache.getAsync(1);
getFut.thenAccept(val -> System.out.println(val)); // Non-blocking continuation.
- 异步方法不会阻塞调用线程;
- 异步方法返回
IgniteClientFuture<T>,其实现了Future<T>和CompletionStage<T>接 - 异步操作通过
ClientConfiguration.asyncContinuationExecutor继续执行,默认值为ForkJoinPool#commonPool(),例如,cache.getAsync(1).thenAccept(val → System.out.println(val))会使用commonPool中的一个线程来执行println调用。
#3.二进制客户端协议
#3.1.二进制客户端协议
#3.1.1.概述
Ignite的二进制客户端协议使得应用不用启动一个全功能的节点,就可以与已有的集群进行通信。应用使用原始的TCP套接字,就可以接入集群。连接建立之后,就可以使用定义好的格式执行缓存操作。
与集群通信,客户端必须遵守下述的数据格式和通信细节。
#3.1.2.数据格式
字节序
Ignite的二进制客户端协议使用小端字节顺序。
数据对象
业务数据,比如缓存的键和值,是以Ignite的二进制对象表示的,一个数据对象可以是标准类型(预定义),也可以是复杂对象,具体可以看数据格式的相关章节。
#3.1.3.消息格式
所有消息的请求和响应,包括握手,都以int类型消息长度开始(不包括开始的4个字节),后面是消息体。
握手
二进制客户端协议需要一个连接握手,来确保客户端和服务端版本的兼容性。下表会显示请求和响应握手消息的结构,下面的示例章节中还会显示如何发送和接收握手请求及其对应的响应。
| 请求类型 | 描述 |
|---|---|
int | 握手有效消息长度 |
byte | 握手码,值为1 |
short | 主版本号 |
short | 次版本号 |
short | 修订版本号 |
byte | 客户端码,值为2 |
string | 用户名 |
string | 密码 |
| 响应类型(成功) | 描述 |
|---|---|
int | 成功消息长度,1 |
byte | 成功标志,1 |
| 响应类型(失败) | 描述 |
|---|---|
int | 错误消息长度 |
byte | 成功标志,0 |
short | 服务端主版本号 |
short | 服务端次版本号 |
short | 服务端修订版本号 |
string | 错误消息 |
标准消息头
客户端操作消息由消息头和与操作有关的数据的消息体组成,每个操作都有自己的数据请求和响应格式,以及一个通用头。 下面的表格和示例显示了客户端操作消息头的请求和响应结构。
| 请求类型 | 描述 |
|---|---|
int | 有效信息长度 |
short | 操作码 |
long | 请求Id,客户端生成,响应中也会返回 |
请求头:
private static void writeRequestHeader(int reqLength, short opCode, long reqId, DataOutputStream out) throws IOException {
// Message length
writeIntLittleEndian(10 + reqLength, out);
// Op code
writeShortLittleEndian(opCode, out);
// Request id
writeLongLittleEndian(reqId, out);
}
| 响应类型 | 描述 |
|---|---|
int | 响应消息长度 |
long | 请求Id |
int | 状态码,(0为成功,其它为错误码) |
string | 错误消息(只有状态码非0时才会有) |
响应头:
private static void readResponseHeader(DataInputStream in) throws IOException {
// Response length
final int len = readIntLittleEndian(in);
// Request id
long resReqId = readLongLittleEndian(in);
// Success code
int statusCode = readIntLittleEndian(in);
}
#3.1.4.接入
TCP套接字
客户端应用接入服务端节点需要通过TCP套接字,连接器默认使用10800端口。可以在集群的IgniteConfiguration中的clientConnectorConfiguration属性中,配置端口号及其它的服务端连接参数,如下所示:
- XML
- Java
<bean id="ignite.cfg" class="org.apache.ignite.configuration.IgniteConfiguration">
<!-- Thin client connection configuration. -->
<property name="clientConnectorConfiguration">
<bean class="org.apache.ignite.configuration.ClientConnectorConfiguration">
<property name="host" value="127.0.0.1"/>
<property name="port" value="10900"/>
<property name="portRange" value="30"/>
</bean>
</property>
<!-- Other Ignite Configurations. -->
</bean>
连接握手
除了套接字连接之外,瘦客户端协议还需要连接握手,以确保客户端和服务端版本兼容。注意握手必须是连接建立后的第一条消息。
对于握手消息的请求和响应数据结构,可以看上面的握手章节。
示例
套接字和握手连接:
Socket socket = new Socket();
socket.connect(new InetSocketAddress("127.0.0.1", 10800));
String username = "yourUsername";
String password = "yourPassword";
DataOutputStream out = new DataOutputStream(socket.getOutputStream());
// Message length
writeIntLittleEndian(18 + username.length() + password.length(), out);
// Handshake operation
writeByteLittleEndian(1, out);
// Protocol version 1.0.0
writeShortLittleEndian(1, out);
writeShortLittleEndian(1, out);
writeShortLittleEndian(0, out);
// Client code: thin client
writeByteLittleEndian(2, out);
// username
writeString(username, out);
// password
writeString(password, out);
// send request
out.flush();
// Receive handshake response
DataInputStream in = new DataInputStream(socket.getInputStream());
int length = readIntLittleEndian(in);
int successFlag = readByteLittleEndian(in);
// Since Ignite binary protocol uses little-endian byte order,
// we need to implement big-endian to little-endian
// conversion methods for write and read.
// Write int in little-endian byte order
private static void writeIntLittleEndian(int v, DataOutputStream out) throws IOException {
out.write((v >>> 0) & 0xFF);
out.write((v >>> 8) & 0xFF);
out.write((v >>> 16) & 0xFF);
out.write((v >>> 24) & 0xFF);
}
// Write short in little-endian byte order
private static final void writeShortLittleEndian(int v, DataOutputStream out) throws IOException {
out.write((v >>> 0) & 0xFF);
out.write((v >>> 8) & 0xFF);
}
// Write byte in little-endian byte order
private static void writeByteLittleEndian(int v, DataOutputStream out) throws IOException {
out.writeByte(v);
}
// Read int in little-endian byte order
private static int readIntLittleEndian(DataInputStream in) throws IOException {
int ch1 = in.read();
int ch2 = in.read();
int ch3 = in.read();
int ch4 = in.read();
if ((ch1 | ch2 | ch3 | ch4) < 0)
throw new EOFException();
return ((ch4 << 24) + (ch3 << 16) + (ch2 << 8) + (ch1 << 0));
}
// Read byte in little-endian byte order
private static byte readByteLittleEndian(DataInputStream in) throws IOException {
return in.readByte();
}
// Other write and read methods
#3.1.5.客户端操作
握手成功之后,客户端就可以执行各种缓存操作了。
- 键-值查询;
- SQL和扫描查询;
- 二进制类型操作;
- 缓存配置操作。
#3.2.数据格式
标准数据类型表示为类型代码和值的组合。
| 字段 | 长度(字节) | 描述 |
|---|---|---|
type_code | 1 | 有符号的单字节整数代码,表示值的类型。 |
value | 可变长度 | 值本身,类型和大小取决于type_code |
下面会详细描述支持的类型及其格式。
#3.2.1.基础类型
基础类型都是非常基本的类型,比如数值类型。
Byte
| 字段 | 长度(字节) | 描述 |
|---|---|---|
Type | 1 | 1 |
Value | 1 | 单字节值 |
Short
类型代码:2
2字节有符号长整形数值,小端字节顺序。
结构:
| 字段 | 长度(字节) | 描述 |
|---|---|---|
Value | 2 | 值 |
Int
类型代码:3
4字节有符号长整形数值,小端字节顺序。
结构:
| 字段 | 长度(字节) | 描述 |
|---|---|---|
Value | 4 | 值 |
Long
类型代码:4
8字节有符号长整形数值,小端字节顺序。
结构:
| 字段 | 长度(字节) | 描述 |
|---|---|---|
Value | 8 | 值 |
Float
类型代码:5
4字节IEEE 754长浮点数值,小端字节顺序。
结构:
| 字段 | 长度(字节) | 描述 |
|---|---|---|
Value | 4 | 值 |
Double
类型代码:6
8字节IEEE 754长浮点数值,小端字节顺序。
结构:
| 字段 | 长度(字节) | 描述 |
|---|---|---|
Value | 8 | 值 |
Char
类型代码:7
单UTF-16代码单元,小端字节顺序。
结构:
| 字段 | 长度(字节) | 描述 |
|---|---|---|
Value | 2 | UTF-16代码单元,小端字节顺序 |
Bool
类型代码:8
布尔值,0为false,非零为true。
结构:
| 字段 | 长度(字节) | 描述 |
|---|---|---|
Value | 1 | 0为false,非零为true |
NULL
类型代码:101
这不是一个确切的类型,只是一个空值,可以分配给任何类型的对象。
没有实际内容,只有类型代码。
#3.2.2.标准对象
String
类型代码:9
UTF-8编码的字符串,必须是有效的UTF-8编码的字符串。
结构:
| 字段 | 长度(字节) | 描述 |
|---|---|---|
length | 4 | 低位优先的有符号整数,字符串的长度,以UTF-8代码单位表示,即字节 |
data | length | 无BOM的UTF-8编码的字符串数据 |
UUID(Guid)
类型代码:10
一个统一唯一标识符(UUID)是一个128为的数值,用于在计算机系统中标识信息。
结构:
| 字段 | 长度(字节) | 描述 |
|---|---|---|
most_significant_bits | 8 | 低位优先的64位字节数值,表示UUID的64个最高有效位。 |
least_significant_bits | 8 | 低位优先的64位字节数值,表示UUID的64个最低有效位。 |
Timestamp
类型代码:33
比Date数据类型更精确。除了从epoch开始的毫秒外,包含最后一毫秒的纳秒部分,该值范围在0到999999之间。这意味着,可以通过以下表达式获得以纳秒为单位的完整时间戳:msecs_since_epoch \* 1000000 + msec_fraction_in_nsecs。
注意
纳秒时间戳计算表达式仅供评估之用。在生产中不应该使用该表达式,因为在某些语言中,表达式可能导致整数溢出。
结构:
| 字段 | 长度(字节) | 描述 |
|---|---|---|
msecs_since_epoch | 8 | 低位优先的有符号整形值,该值为从00:00:00 1 Jan 1970 UTC开始过去的毫秒数,这个格式通常称为Unix或者POSIX时间。 |
msec_fraction_in_nsecs | 4 | 低位优先的有符号整形值,一个毫秒的纳秒部分。 |
Date
类型代码:11
日期,该值为从00:00:00 1 Jan 1970 UTC开始过去的毫秒数,这个格式通常称为Unix或者POSIX时间。
结构:
| 字段 | 长度(字节) | 描述 |
|---|---|---|
msecs_since_epoch | 8 | 低位优先的有符号整形值。 |
Time
类型代码:36
时间,表示为从午夜(即00:00:00 UTC)起经过的毫秒数。
结构:
| 字段 | 长度(字节) | 描述 |
|---|---|---|
value | 8 | 低位优先的有符号整形值,表示为从00:00:00 UTC起经过的毫秒数。 |
Decimal
类型代码:30
任何所需精度和比例的数值。
结构:
| 字段 | 长度(字节) | 描述 |
|---|---|---|
scale | 4 | 低位优先的有符号整形值,实际为十的幂,在此基础上原值要做除法,比如,比例为3的42为0.042,比例为-3的42为42000,比例为1的42为42。 |
length | 4 | 低位优先的有符号整形值,数字的长度(字节)。 |
data | length | 第一位是负数标志。如果为1,则值为负数。其它位以高位优先格式的有符号的变长整数。 |
Enum
类型代码:28
枚举类型值,这些类型只定义了有限数量的命名值。
结构:
| 字段 | 长度(字节) | 描述 |
|---|---|---|
type_id | 4 | 低位优先的有符号整形值,具体可以看下面的Type ID。 |
ordinal | 4 | 低位优先的有符号整形值,枚举值序号。它在枚举声明中的位置,初始常数为0。 |
#3.2.3.基础类型数组
这种数组只包含值(元素)的内容,它们类型类似,具体可以看下表的格式描述。注意数组只包含内容,没有类型代码。
| 字段 | 长度(字节) | 描述 |
|---|---|---|
length | 4 | 有符号整数,数组中元素的个数。 |
element_0_payload | 依赖于类型 | 元素0的内容。 |
element_1_payload | 依赖于类型 | 元素1的内容。 |
element_N_payload | 依赖于类型 | 元素N的内容。 |
Byte数组
类型代码:12
字节数组。可以是一段原始数据,也可以是一组小的有符号整数。
结构:
| 字段 | 长度(字节) | 描述 |
|---|---|---|
length | 4 | 有符号整数,数组里的元素个数 |
elements | length | 元素序列。每个元素都是byte类型。 |
Short数组
类型代码:13
有符号短整形数值数组。
结构:
| 字段 | 长度(字节) | 描述 |
|---|---|---|
length | 4 | 有符号整数,数组里的元素个数 |
elements | length?× 2 | 元素序列。每个元素都是short类型。 |
Int数组
类型代码:14
有符号整形数值数组。
结构:
| 字段 | 长度(字节) | 描述 |
|---|---|---|
length | 4 | 有符号整数,数组里的元素个数 |
elements | length?× 4 | 元素序列。每个元素都是int类型。 |
Long数组
类型代码:15
有符号长整形数值数组。
结构:
| 字段 | 长度(字节) | 描述 |
|---|---|---|
length | 4 | 有符号整数,数组里的元素个数 |
elements | length?× 8 | 元素序列。每个元素都是long类型。 |
Float数组
类型代码:16
浮点型数值数组。
结构:
| 字段 | 长度(字节) | 描述 |
|---|---|---|
length | 4 | 有符号整数,数组里的元素个数 |
elements | length?× 4 | 元素序列。每个元素都是float类型。 |
Double数组
类型代码:17
双精度浮点型数值数组。
结构:
| 字段 | 长度(字节) | 描述 |
|---|---|---|
length | 4 | 有符号整数,数组里的元素个数 |
elements | length?× 8 | 元素序列。每个元素都是double类型。 |
Char数组
类型代码:18
UTF-16编码单元数组。和String不同,此类型不是必须包含有效的UTF-16文本。
结构:
| 字段 | 长度(字节) | 描述 |
|---|---|---|
length | 4 | 有符号整数,数组里的元素个数 |
elements | length?× 2 | 元素序列。每个元素都是char类型。 |
Bool数组
类型代码:19
布尔值数组。
结构:
| 字段 | 长度(字节) | 描述 |
|---|---|---|
length | 4 | 有符号整数,数组里的元素个数 |
elements | length | 元素序列。每个元素都是bool类型。 |
#3.2.4.标准对象数组
这种数组包含完整值(元素)的内容,这意味着,数组的元素包含类型代码和内容。此格式允许元素为NULL值。这就是它们被称为“对象”的原因。它们都有相似的格式,具体可以看下表的格式描述。
| 字段 | 长度(字节) | 描述 |
|---|---|---|
length | 4 | 有符号整数,数组中元素的个数。 |
element_0_full_value | 依赖于值类型 | 元素0的完整值,包含类型代码和内容,可以为NULL。 |
element_1_full_value | 依赖于值类型 | 元素1的完整值或NULL。 |
element_N_full_value | 依赖于值类型 | 元素N的完整值或NULL。 |
String数组
类型代码:20
UTF-8字符串数组。
结构:
| 字段 | 长度(字节) | 描述 |
|---|---|---|
length | 4 | 有符号整数,数组里的元素个数 |
elements | 可变长度,取决于每个字符串的长度,对于每个元素,字符串为5 + 值长度,NULL为1 | 元素序列。每个元素都是string类型的完整值,包括类型代码,或者NULL。 |
UUID(Guid)数组
类型代码:21
UUID(Guid)数组。
结构:
| 字段 | 长度(字节) | 描述 |
|---|---|---|
length | 4 | 有符号整数,数组里的元素个数 |
elements | 可变长度,对于每个元素,UUID为17,NULL为1 | 元素序列。每个元素都是uuid类型的完整值,包括类型代码,或者NULL。 |
Timestamp数组
类型代码:34
时间戳数组。
结构:
| 字段 | 长度(字节) | 描述 |
|---|---|---|
length | 4 | 有符号整数,数组里的元素个数 |
elements | 可变长度,对于每个元素,Timestamp为13,NULL为1 | 元素序列。每个元素都是timestamp类型的完整值,包括类型代码,或者NULL。 |
Date数组
类型代码:22
日期数组。
结构:
| 字段 | 长度(字节) | 描述 |
|---|---|---|
length | 4 | 有符号整数,数组里的元素个数 |
elements | 可变长度,对于每个元素,Date为9,NULL为1 | 元素序列。每个元素都是date类型的完整值,包括类型代码,或者NULL。 |
Time数组
类型代码:37
时间数组。
结构:
| 字段 | 长度(字节) | 描述 |
|---|---|---|
length | 4 | 有符号整数,数组里的元素个数 |
elements | 可变长度,对于每个元素,Time为9,NULL为1 | 元素序列。每个元素都是time类型的完整值,包括类型代码,或者NULL。 |
Decimal数组
类型代码:31
数值数组。
结构:
| 字段 | 长度(字节) | 描述 |
|---|---|---|
length | 4 | 有符号整数,数组里的元素个数 |
elements | 可变长度,对于每个元素,数值为9 + 值长度,NULL为1 | 元素序列。每个元素都是decimal类型的完整值,包括类型代码,或者NULL。 |
#3.2.5.对象集合
对象数组
类型代码:23
任意类型对象数组。包括任意类型的标准对象、以及各种类型的复杂对象、NULL值及其它们的任意组合,这也意味着,集合可以包含其它的集合。
结构:
| 字段 | 长度(字节) | 描述 |
|---|---|---|
type_id | 4 | 包含对象的类型描述符,比如,Java中这个类型会用于反序列化为Type[],显然,数组中的所有对象都应该有个Type作为父类型,这是任意对象类型的父类型。比如,在Java中是java.lang.Object,这样的根对象类型的Type ID为-1,具体下面会详述。 |
length | 4 | 有符号整数,数组里的元素个数 |
elements | 可变长度,取决于对象的长度 | 元素序列。每个元素都是任意类型的完整值,或者NULL。 |
集合
类型代码:24
通用集合类型,和对象数组一样,包含对象,但是和数组不同,它有一个针对特定类型反序列化到平台特定集合的提示,不仅仅是个数组,它支持下面的集合类型:
USER_SET:-1,这是常规集合类型,无法映射到更具体的集合类型。不过,众所周知,它是固定的。将这样的集合反序列化为平台上基本和更广泛使用的集合类型是有意义的,例如哈希集合;USER_COL:0,这是常规集合类型,无法映射到更具体的集合类型。将这样的集合反序列化为平台上基本和更广泛使用的集合类型是有意义的,例如可变大小数组;ARR_LIST:1,这实际上是一种可变大小的数组类型;LINKED_LIST:2,这是链表类型;HASH_SET:3,这是基本的哈希集合类型;LINKED_HASH_SET:4,这是一个哈希集合类型,会维护元素的顺序;SINGLETON_LIST:5,这是一个只有一个元素的集合,可供平台用于优化目的。如果不适用,则可以使用任何集合类型。
注意
集合类型字节用作将集合反序列化为某平台最合适类型的提示。例如在Java中,HASH_SET会反序列化为java.util.HashSet,而LINKED_HASH_SET会反序列化为java.util.LinkedHashSet。建议瘦客户端实现在序列化和反序列化时尝试使用最合适的集合类型。但是,这只是一个提示,如果它与平台无关或不适用,可以忽略它。
结构:
| 字段 | 长度(字节) | 描述 |
|---|---|---|
length | 4 | 有符号整数,数组里的元素个数 |
type | 1 | 集合的类型 |
elements | 可变长度,取决于对象的大小 | 元素序列。每个元素都是任意类型的完整值,或者NULL。 |
映射
类型代码:25
类似Map的集合类型,包含成对的键和值对象,键和值可以为任意类型的对象,包括各种类型的标准对象、复杂对象以及组合对象。包含一个反序列化到具体Map类型的提示,支持下面的Map类型:
HASH_MAP:1,这是基本的哈希映射;LINKED_HASH_MAP:2,这也是一个哈希映射,但是会维护元素的顺序。
注意
映射类型字节用作将集合反序列化为某平台最合适类型的提示。建议瘦客户端实现在序列化和反序列化时尝试使用最合适的集合类型。但是,这只是一个提示,如果它与平台无关或不适用,可以忽略它。
结构:
| 字段 | 长度(字节) | 描述 |
|---|---|---|
length | 4 | 有符号整数,数组里的元素个数 |
type | 1 | 集合的类型 |
elements | 可变长度,取决于对象的大小 | 元素序列。这里的元素都有键和值,成对出现,每个元素都是任意类型的完整值或者NULL。 |
枚举数组
类型代码:29
枚举类型值数组,元素要么是枚举类型值,要么是NULL,所以,任意元素要么占用9字节,要么1字节。
结构:
| 字段 | 长度(字节) | 描述 |
|---|---|---|
type_id | 4 | 包含对象的类型描述符,比如,Java中这个类型会用于反序列化为EnumType[],显然,数组中的所有对象都应该有个EnumType作为父类型,这是任意枚举对象类型的父类型,具体下面会详述。 |
length | 4 | 有符号整数,数组里的元素个数 |
elements | 可变长度,取决于对象的长度 | 元素序列。每个元素都是枚举类型的完整值,或者NULL。 |
#3.2.6.复杂对象
类型代码:103
复杂对象由一个24位的头、一组字段(数据对象)以及一个模式(字段ID和位置)组成。根据操作和数据模型,一个数据对象可以为一个基础类型或者复杂类型(一组字段)。
结构:
| 字段 | 长度(字节) | 是否必须 |
|---|---|---|
version | 1 | 是 |
flags | 2 | 是 |
type_id | 4 | 是 |
hash_code | 4 | 是 |
length | 4 | 是 |
schema_id | 4 | 是 |
object_fields | 可变长度 | 否 |
schema | 可变长度 | 否 |
raw_data_offset | 4 | 否 |
version
这是一个字段,指示复杂对象布局的版本。它是必须向后兼容的。客户端应该检查这个字段并向用户指出错误(如果不知道对象布局版本),以防止数据损坏和不可预知的反序列化结果。
flags
这个字段是16位的低位优先的掩码。包含对象标志,该标志指示读取器应如何处理对象实例。有以下标志:
USER_TYPE = 0x0001:表示类型是用户类型,应始终为任何客户端类型设置,在反序列化时可以忽略;HAS_SCHEMA = 0x0002:表示对象布局在尾部是否包含模式;HAS_RAW_DATA = 0x0004:表示对象是否包含原始数据;OFFSET_ONE_BYTE = 0x0008:表示模式字段偏移量为一个字节长度;OFFSET_TWO_BYTES = 0x0010:表示模式字段偏移量为二个字节长度;COMPACT_FOOTER = 0x0020:表示尾部不包含字段ID,只有偏移量。
type_id
此字段包含唯一的类型标识符。它是低位优先的4个字节长度。默认情况下,Type ID是通过类型名称的Java风格的哈希值获得的。Type ID评估算法应该在集群中的所有平台上都相同,以便所有平台都能够使用此类型的对象进行操作。下面是所有瘦客户端推荐使用的默认Type ID计算算法:
- Java
- C
static int hashCode(String str) {
int len = str.length;
int h = 0;
for (int i = 0; i < len; i++) {
int c = str.charAt(i);
c = Character.toLowerCase(c);
h = 31 * h + c;
}
return h;
}
hash_code
值的哈希编码,它是低位优先的4字节长度,它由不包含头部的内容部分的Java风格的哈希编码计算得来,Ignite引擎用来作比较用,比如用作键的比较。下面是哈希值的计算算法:
- Java
- C
static int dataHashCode(byte[] data) {
int len = data.length;
int h = 0;
for (int i = 0; i < len; i++)
h = 31 * h + data[i];
return h;
}
length
这个字段为对象(包括头部)的整体长度,它为低位优先的4字节整型值,通过在当前数据流的位置上简单地增加本字段值的偏移量,可以轻易地忽略整个对象。
schema_id
对象模式标识符。它为低位优先4字节值,并由所有对象字段ID的哈希值计算得出。它用于复杂的对象大小优化。Ignite使用schema_id来避免将整个模式写入到每个复杂对象值的末尾。相反,它将所有模式存储在二进制元数据存储中,并且只向对象写入字段偏移量。这种优化有助于显著减少包含许多短字段(如整型值)的复杂对象的大小。
如果模式缺失(例如,以原始模式写入整个对象,或者没有任何字段),则schema_id字段为0。
注意
无法使用type_id确定schema_id,因为具有相同type_id的对象可以具有多个模式,即字段序列。
schema_id的计算算法如下:
- Java
- C
/** FNV1 hash offset basis. */
private static final int FNV1_OFFSET_BASIS = 0x811C9DC5;
/** FNV1 hash prime. */
private static final int FNV1_PRIME = 0x01000193;
static int calculateSchemaId(int fieldIds[])
{
if (fieldIds == null || fieldIds.length == 0)
return 0;
int len = fieldIds.length;
int schemaId = FNV1_OFFSET_BASIS;
for (size_t i = 0; i < len; ++i)
{
fieldId = fieldIds[i];
schemaId = schemaId ^ (fieldId & 0xFF);
schemaId = schemaId * FNV1_PRIME;
schemaId = schemaId ^ ((fieldId >> 8) & 0xFF);
schemaId = schemaId * FNV1_PRIME;
schemaId = schemaId ^ ((fieldId >> 16) & 0xFF);
schemaId = schemaId * FNV1_PRIME;
schemaId = schemaId ^ ((fieldId >> 24) & 0xFF);
schemaId = schemaId * FNV1_PRIME;
}
}
object_fields
对象字段。每个字段都是二进制对象,可以是复杂类型,也可以是标准类型。注意,一个没有任何字段的复杂对象也是有效的,可能会遇到。每个字段的名字可有可无。对于命名字段,在对象模式中会写入一个偏移量,通过该偏移量,可以在对象中将其定位,而无需对整个对象进行反序列化。没有名字的字段总是存储在命名字段之后,并以所谓的原始模式写入。
因此,以原始模式写入的字段只能按与写入相同的顺序通过顺序读取进行访问,而命名字段则可以按随机顺序读取。
schema
对象模式。复杂对象的模式可有可无,因此此字段是可选的。如果对象中没有命名字段,则对象中不存在模式。它还包括当对象根本没有字段时的情况。可以检查HAS_SCHEMA对象标志,以确定该对象是否具有模式。
模式的主要目的是可以对对象字段进行快速搜索。为此,模式在对象内容中包含对象字段的偏移序列。字段偏移本身的大小可能不同。这些字段的大小由最大偏移值在写入时确定。如果它在[24..255]字节范围内,则使用1字节偏移量;如果它在[256..65535]字节范围内,则使用2字节偏移量。其它情况使用4字节偏移量。要确定读取时偏移量的大小,客户端应该检查OFFSET_ONE_BYTE和OFFSET_TWO_BYTES标志。如果设置了OFFSET_ONE_BYTE标志,则偏移量为1字节长,否则如果设置了OFFSET_TWO_BYTES标志,则偏移量为2字节长,否则偏移量为4字节长。
支持的模式有两种:
完整模式方式:实现更简单,但使用更多资源;压缩尾部方式:更难实现,但提供更好的性能并减少内存消耗,因此建议新客户端用此方式实现。
具体下面会介绍。
注意,客户端应该校验COMPACT_FOOTER标志,来确定每个对象应该使用哪个方式。
完整模式方式
如果使用这个方式,COMPACT_FOOTER标志未配置,然后整个对象模式会被写入对象的尾部,这时只有复杂对象自身需要反序列化(schema_id字段会被忽略,并且不需要其它的数据),这时复杂对象的schema字段的结构如下:
| 字段 | 长度(字节) | 描述 |
|---|---|---|
field_id_0 | 4 | 索引值为0的字段的ID,低位优先4字节,这个ID是通过字段名字用和type_id一样的方式计算得来的。 |
field_offset_0 | 可变长度,依赖于对象的大小:1,2或4 | 低位优先无符号整数,对象中字段的偏移量,从完整对象值的第一个字节开始(即type_code的位置)。 |
field_id_1 | 4 | 索引值为1的字段的ID,低位优先4字节。 |
field_offset_1 | 可变长度,依赖于对象的大小:1,2或4 | 低位优先无符号整数,对象中字段的偏移量。 |
field_id_N | 4 | 索引值为N的字段的ID,低位优先4字节。 |
field_offset_N | 可变长度,依赖于对象的大小:1,2或4 | 低位优先无符号整数,对象中字段的偏移量。 |
压缩尾部方式
这个模式中,配置了COMPACT_FOOTER标志然后只有字段偏移量的序列会被写入对象的尾部。这时,客户端使用schema_id字段搜索以前存储的元数据中的对象模式,以查找字段顺序并将字段与其偏移量关联。
如果使用了这个方式,客户端需要在某个元数据中持有模式,然后将其发送/接收给/自Ignite服务端,具体可以看二进制类型元数据的相关章节。
这个场景中schema的结构如下:
| 字段 | 长度(字节) | 描述 |
|---|---|---|
field_offset_0 | 可变长度,依赖于对象的大小:1,2或4 | 低位优先无符号整数,对象中字段0的偏移量,从完整对象值的第一个字节开始(即type_code的位置)。 |
field_offset_1 | 可变长度,依赖于对象的大小:1,2或4 | 低位优先无符号整数,对象中字段1的偏移量。 |
field_offset_N | 可变长度,依赖于对象的大小:1,2或4 | 低位优先无符号整数,对象中字段N的偏移量。 |
raw_data_offset
可选字段。仅存在于对象中,如果有任何字段,则以原始模式写入。这时,设置了HAS_RAW_DATA标志并且存在原始数据偏移量字段,存储为低位优先4字节。该值指向复杂对象中的原始数据偏移量,从头部的第一个字节开始(即,此字段始终大于头部的长度)。
此字段用于用户以原始模式开始读取时对流进行定位。
#3.2.7.特殊类型
包装数据
类型代码:27
一个或多个二进制对象可以包装成一个数组,这样可以高效地读取、存储、传输和写入对象,而不需要理解它的内容,只进行简单的字节复制即可。
所有缓存操作都返回包装器内的复杂对象(不是基础类型)。
结构:
| 字段 | 长度(字节) | 描述 |
|---|---|---|
length | 4 | 低位优先的4字节有符号整数,以字节计算的包装后的数据的大小。 |
payload | length | 内容 |
offset | 4 | 低位优先的4字节有符号整数,数组内对象的偏移量,数组内可以包含一个对象图,这个偏移量指向根对象。 |
二进制枚举
类型代码:38
包装枚举类型,引擎可以返回此类型以替代普通枚举类型。当使用二进制API时,枚举应该以这种形式写入。
结构:
| 字段 | 长度(字节) | 描述 |
|---|---|---|
type_id | 4 | 低位优先的4字节有符号整数,具体可以看type_id相关章节的内容。 |
ordinal | 4 | 低位优先的4字节有符号整数,枚举值序号,即在枚举声明中的位置,这个序号的初始值为0 |
#3.2.8.序列化和反序列化示例
常规对象读
下面的代码模板,显示了如何从输入的字节流中读取各种类型的数据:
private static Object readDataObject(DataInputStream in) throws IOException {
byte code = in.readByte();
switch (code) {
case 1:
return in.readByte();
case 2:
return readShortLittleEndian(in);
case 3:
return readIntLittleEndian(in);
case 4:
return readLongLittleEndian(in);
case 27: {
int len = readIntLittleEndian(in);
// Assume 0 offset for simplicity
Object res = readDataObject(in);
int offset = readIntLittleEndian(in);
return res;
}
case 103:
byte ver = in.readByte();
assert ver == 1; // version
short flags = readShortLittleEndian(in);
int typeId = readIntLittleEndian(in);
int hash = readIntLittleEndian(in);
int len = readIntLittleEndian(in);
int schemaId = readIntLittleEndian(in);
int schemaOffset = readIntLittleEndian(in);
byte[] data = new byte[len - 24];
in.read(data);
return "Binary Object: " + typeId;
default:
throw new Error("Unsupported type: " + code);
}
}
Int
下面的代码片段显示了如何进行int类型的数据对象的读写,使用的是基于套接字的输出/输入流:
// Write int data object
DataOutputStream out = new DataOutputStream(socket.getOutputStream());
int val = 11;
writeByteLittleEndian(3, out); // Integer type code
writeIntLittleEndian(val, out);
// Read int data object
DataInputStream in = new DataInputStream(socket.getInputStream());
int typeCode = readByteLittleEndian(in);
int val = readIntLittleEndian(in);
String
下面的代码片段显示了如何进行String类型的读写,格式如下:
| 类型 | 描述 |
|---|---|
| byte | 字符串类型代码,0 |
| int | UTF-8字节模式的字符串长度 |
| bytes | 实际字符串 |
private static void writeString (String str, DataOutputStream out) throws IOException {
writeByteLittleEndian(9, out); // type code for String
int strLen = str.getBytes("UTF-8").length; // length of the string
writeIntLittleEndian(strLen, out);
out.writeBytes(str);
}
private static String readString(DataInputStream in) throws IOException {
int type = readByteLittleEndian(in); // type code
int strLen = readIntLittleEndian(in); // length of the string
byte[] buf = new byte[strLen];
readFully(in, buf, 0, strLen);
return new String(buf);
}
#8.3.键-值查询
本章节会描述可以对缓存进行的键值操作,该键值操作等同于Ignite原生的缓存操作,具体可以看IgniteCache的文档,每个操作都会有一个头信息及与该操作对应的数据。
关于可用的数据类型和数据格式规范的清单,可以参见数据格式章节的介绍。
#8.3.1.操作代码
与Ignite服务端节点成功握手后,客户端可以通过发送带有某个操作代码的请求(参见下面的请求/响应结构)来开始执行各种键值操作:
| 操作 | 操作代码 |
|---|---|
OP_CACHE_GET | 1000 |
OP_CACHE_PUT | 1001 |
OP_CACHE_PUT_IF_ABSENT | 1002 |
OP_CACHE_GET_ALL | 1003 |
OP_CACHE_PUT_ALL | 1004 |
OP_CACHE_GET_AND_PUT | 1005 |
OP_CACHE_GET_AND_REPLACE | 1006 |
OP_CACHE_GET_AND_REMOVE | 1007 |
OP_CACHE_GET_AND_PUT_IF_ABSENT | 1008 |
OP_CACHE_REPLACE | 1009 |
OP_CACHE_REPLACE_IF_EQUALS | 1010 |
OP_CACHE_CONTAINS_KEY | 1011 |
OP_CACHE_CONTAINS_KEYS | 1012 |
OP_CACHE_CLEAR | 1013 |
OP_CACHE_CLEAR_KEY | 1014 |
OP_CACHE_CLEAR_KEYS | 1015 |
OP_CACHE_REMOVE_KEY | 1016 |
OP_CACHE_REMOVE_IF_EQUALS | 1017 |
OP_CACHE_REMOVE_KEYS | 1018 |
OP_CACHE_REMOVE_ALL | 1019 |
OP_CACHE_GET_SIZE | 1020 |
注意上面提到的操作代码,是请求头的一部分,具体可以看头信息的相关内容。
#8.3.2.OP_CACHE_GET
通过键从缓存获得值,如果不存在则返回null。
| 请求类型 | 描述 |
|---|---|
| 头信息 | 请求头 |
| int | 缓存ID,Java风格的缓存名的哈希值 |
| byte | 0,该字段被废弃,未来会删除 |
| 数据对象 | 要返回的缓存条目的主键 |
| 响应类型 | 描述 |
|---|---|
| 头信息 | 响应头 |
| 数据对象 | 给定主键对应的值,如果不存在则为null |
- 请求
- 响应
DataOutputStream out = new DataOutputStream(socket.getOutputStream());
// Request header
writeRequestHeader(10, OP_CACHE_GET, 1, out);
// Cache id
writeIntLittleEndian(cacheName.hashCode(), out);
// Flags = none
writeByteLittleEndian(0, out);
// Data object
writeByteLittleEndian(3, out); // Integer type code
writeIntLittleEndian(key, out); // Cache key
#8.3.3.OP_CACHE_GET_ALL
从一个缓存中获得多个键-值对。
| 请求类型 | 描述 |
|---|---|
| 头信息 | 请求头 |
| int | 缓存ID,Java风格的缓存名的哈希值 |
| byte | 0,该字段被废弃,未来会删除 |
| int | 键数量 |
| 数据对象 | 缓存条目的主键,重复多次,次数为前一个参数传递的值 |
| 响应类型 | 描述 |
|---|---|
| 头信息 | 响应头 |
| int | 结果数量 |
| 键对象+值对象 | 返回的键-值对,不包含缓存中没有的条目,重复多次,次数为前一个参数返回的值 |
- 请求
- 响应
DataOutputStream out = new DataOutputStream(socket.getOutputStream());
// Request header
writeRequestHeader(19, OP_CACHE_GET_ALL, 1, out);
// Cache id
writeIntLittleEndian(cacheName.hashCode(), out);
// Flags = none
writeByteLittleEndian(0, out);
// Key count
writeIntLittleEndian(2, out);
// Data object 1
writeByteLittleEndian(3, out); // Integer type code
writeIntLittleEndian(key1, out); // Cache key
// Data object 2
writeByteLittleEndian(3, out); // Integer type code
writeIntLittleEndian(key2, out); // Cache key
#8.3.4.OP_CACHE_PUT
往缓存中写入给定的键-值对(会覆盖已有的值)。
| 请求类型 | 描述 |
|---|---|
| 头信息 | 请求头 |
| int | 缓存ID,Java风格的缓存名的哈希值 |
| byte | 0,该字段被废弃,未来会删除 |
| 数据对象 | 键 |
| 数据对象 | 值 |
| 响应类型 | 描述 |
|---|---|
| 头信息 | 响应头 |
- 请求
- 响应
DataOutputStream out = new DataOutputStream(socket.getOutputStream());
// Request header
writeRequestHeader(15, OP_CACHE_PUT, 1, out);
// Cache id
writeIntLittleEndian(cacheName.hashCode(), out);
// Flags = none
writeByteLittleEndian(0, out);
// Cache key data object
writeByteLittleEndian(3, out); // Integer type code
writeIntLittleEndian(key, out); // Cache key
// Cache value data object
writeByteLittleEndian(3, out); // Integer type code
writeIntLittleEndian(value, out); // Cache value
#8.3.5.OP_CACHE_PUT_ALL
往缓存中写入给定的多个键-值对(会覆盖已有的值)。
| 请求类型 | 描述 |
|---|---|
| 头信息 | 请求头 |
| int | 缓存ID,Java风格的缓存名的哈希值 |
| byte | 0,该字段被废弃,未来会删除 |
| int | 键-值对数量 |
| 键对象+值对象 | 键-值对,重复多次,次数为前一个参数传递的值 |
| 响应类型 | 描述 |
|---|---|
| 头信息 | 响应头 |
- 请求
- 响应
DataOutputStream out = new DataOutputStream(socket.getOutputStream());
// Request header
writeRequestHeader(29, OP_CACHE_PUT_ALL, 1, out);
// Cache id
writeIntLittleEndian(cacheName.hashCode(), out);
// Flags = none
writeByteLittleEndian(0, out);
// Entry Count
writeIntLittleEndian(2, out);
// Cache key data object 1
writeByteLittleEndian(3, out); // Integer type code
writeIntLittleEndian(key1, out); // Cache key
// Cache value data object 1
writeByteLittleEndian(3, out); // Integer type code
writeIntLittleEndian(value1, out); // Cache value
// Cache key data object 2
writeByteLittleEndian(3, out); // Integer type code
writeIntLittleEndian(key2, out); // Cache key
// Cache value data object 2
writeByteLittleEndian(3, out); // Integer type code
writeIntLittleEndian(value2, out); // Cache value
#8.3.6.OP_CACHE_CONTAINS_KEY
判断缓存中是否存在给定的键。
| 请求类型 | 描述 |
|---|---|
| 头信息 | 请求头 |
| int | 缓存ID,Java风格的缓存名的哈希值 |
| byte | 0,该字段被废弃,未来会删除 |
| 数据对象 | 缓存条目的主键 |
| 响应类型 | 描述 |
|---|---|
| 头信息 | 响应头 |
| bool | 主键存在则为true,否则为false |
- 请求
- 响应
DataOutputStream out = new DataOutputStream(socket.getOutputStream());
// Request header
writeRequestHeader(10, OP_CACHE_CONTAINS_KEY, 1, out);
// Cache id
writeIntLittleEndian(cacheName.hashCode(), out);
// Flags = none
writeByteLittleEndian(0, out);
// Cache key data object
writeByteLittleEndian(3, out); // Integer type code
writeIntLittleEndian(key, out); // Cache key
#8.3.7.OP_CACHE_CONTAINS_KEYS
判断缓存中是否存在给定的所有键。
| 请求类型 | 描述 |
|---|---|
| 头信息 | 请求头 |
| int | 缓存ID,Java风格的缓存名的哈希值 |
| byte | 0,该字段被废弃,未来会删除 |
| int | 键数量 |
| 数据对象 | 缓存条目的主键,重复多次,次数为前一个参数传递的值 |
| 响应类型 | 描述 |
|---|---|
| 头信息 | 响应头 |
| bool | 主键存在则为true,否则为false |
- 请求
- 响应
DataOutputStream out = new DataOutputStream(socket.getOutputStream());
// Request header
writeRequestHeader(19, OP_CACHE_CONTAINS_KEYS, 1, out);
// Cache id
writeIntLittleEndian(cacheName.hashCode(), out);
// Flags = none
writeByteLittleEndian(0, out);
//Count
writeIntLittleEndian(2, out);
// Cache key data object 1
int key1 = 11;
writeByteLittleEndian(3, out); // Integer type code
writeIntLittleEndian(key1, out); // Cache key
// Cache key data object 2
int key2 = 22;
writeByteLittleEndian(3, out); // Integer type code
writeIntLittleEndian(key2, out); // Cache key
#8.3.8.OP_CACHE_GET_AND_PUT
往缓存中插入一个键-值对,并且返回与该键对应的原值,如果缓存中没有该键,则会创建一个新的条目并返回null。
| 请求类型 | 描述 |
|---|---|
| 头信息 | 请求头 |
| int | 缓存ID,Java风格的缓存名的哈希值 |
| byte | 0,该字段被废弃,未来会删除 |
| 数据对象 | 要更新的键 |
| 数据对象 | 给定键对应的新值 |
| 响应类型 | 描述 |
|---|---|
| 头信息 | 响应头 |
| 数据对象 | 给定键的原有值,或者为null |
- 请求
- 响应
DataOutputStream out = new DataOutputStream(socket.getOutputStream());
// Request header
writeRequestHeader(15, OP_CACHE_GET_AND_PUT, 1, out);
// Cache id
writeIntLittleEndian(cacheName.hashCode(), out);
// Flags = none
writeByteLittleEndian(0, out);
// Cache key data object
writeByteLittleEndian(3, out); // Integer type code
writeIntLittleEndian(key, out); // Cache key
// Cache value data object
writeByteLittleEndian(3, out); // Integer type code
writeIntLittleEndian(value, out); // Cache value
#8.3.9.OP_CACHE_GET_AND_REPLACE
替换缓存中给定键的值,然后返回原值,如果缓存中该键不存在,该操作会返回null而缓存不会有改变。
| 请求类型 | 描述 |
|---|---|
| 头信息 | 请求头 |
| int | 缓存ID,Java风格的缓存名的哈希值 |
| byte | 0,该字段被废弃,未来会删除 |
| 数据对象 | 要更新的键 |
| 数据对象 | 给定键对应的新值 |
| 响应类型 | 描述 |
|---|---|
| 头信息 | 响应头 |
| 数据对象 | 给定键的原有值,如果该键不存在则为null |
- 请求
- 响应
DataOutputStream out = new DataOutputStream(socket.getOutputStream());
// Request header
writeRequestHeader(15, OP_CACHE_GET_AND_REPLACE, 1, out);
// Cache id
writeIntLittleEndian(cacheName.hashCode(), out);
// Flags = none
writeByteLittleEndian(0, out);
// Cache key data object
writeByteLittleEndian(3, out); // Integer type code
writeIntLittleEndian(key, out); // Cache key
// Cache value data object
writeByteLittleEndian(3, out); // Integer type code
writeIntLittleEndian(value, out); // Cache value
#8.3.10.OP_CACHE_GET_AND_REMOVE
删除缓存中给定键对应的数据,然后返回原值,如果缓存中该键不存在,该操作会返回null。
| 请求类型 | 描述 |
|---|---|
| 头信息 | 请求头 |
| int | 缓存ID,Java风格的缓存名的哈希值 |
| byte | 0,该字段被废弃,未来会删除 |
| 数据对象 | 要删除的键 |
| 响应类型 | 描述 |
|---|---|
| 头信息 | 响应头 |
| 数据对象 | 给定键的原有值,如果该键不存在则为null |
- 请求
- 响应
DataOutputStream out = new DataOutputStream(socket.getOutputStream());
// Request header
writeRequestHeader(10, OP_CACHE_GET_AND_REMOVE, 1, out);
// Cache id
writeIntLittleEndian(cacheName.hashCode(), out);
// Flags = none
writeByteLittleEndian(0, out);
// Cache key data object
writeByteLittleEndian(3, out); // Integer type code
writeIntLittleEndian(key, out); // Cache key
#8.3.11.OP_CACHE_PUT_IF_ABSENT
在条目不存在时插入一个新的条目。
| 请求类型 | 描述 |
|---|---|
| 头信息 | 请求头 |
| int | 缓存ID,Java风格的缓存名的哈希值 |
| byte | 0,该字段被废弃,未来会删除 |
| 数据对象 | 要插入的键 |
| 数据对象 | 给定键对应的值 |
| 响应类型 | 描述 |
|---|---|
| 头信息 | 响应头 |
| bool | 插入成功为true,条目已存在为false |
- 请求
- 响应
DataOutputStream out = new DataOutputStream(socket.getOutputStream());
// Request header
writeRequestHeader(15, OP_CACHE_PUT_IF_ABSENT, 1, out);
// Cache id
writeIntLittleEndian(cacheName.hashCode(), out);
// Flags = none
writeByteLittleEndian(0, out);
// Cache key data object
writeByteLittleEndian(3, out); // Integer type code
writeIntLittleEndian(key, out); // Cache key
// Cache value data object
writeByteLittleEndian(3, out); // Integer type code
writeIntLittleEndian(value, out); // Cache Value
#8.3.12.OP_CACHE_GET_AND_PUT_IF_ABSENT
在条目不存在时插入一个新的条目,否则返回已有的值。
| 请求类型 | 描述 |
|---|---|
| 头信息 | 请求头 |
| int | 缓存ID,Java风格的缓存名的哈希值 |
| byte | 0,该字段被废弃,未来会删除 |
| 数据对象 | 要插入的键 |
| 数据对象 | 给定键对应的值 |
| 响应类型 | 描述 |
|---|---|
| 头信息 | 响应头 |
| 数据对象 | 如果缓存没有该条目则返回null(这时会创建一个新条目),或者返回给定键对应的已有值。 |
- 请求
- 响应
DataOutputStream out = new DataOutputStream(socket.getOutputStream());
// Request header
writeRequestHeader(15, OP_CACHE_GET_AND_PUT_IF_ABSENT, 1, out);
// Cache id
writeIntLittleEndian(cacheName.hashCode(), out);
// Flags = none
writeByteLittleEndian(0, out);
// Cache key data object
writeByteLittleEndian(3, out); // Integer type code
writeIntLittleEndian(key, out); // Cache key
// Cache value data object
writeByteLittleEndian(3, out); // Integer type code
writeIntLittleEndian(value, out); // Cache value
#8.3.13.OP_CACHE_REPLACE
替换缓存中已有键的值。
| 请求类型 | 描述 |
|---|---|
| 头信息 | 请求头 |
| int | 缓存ID,Java风格的缓存名的哈希值 |
| byte | 0,该字段被废弃,未来会删除 |
| 数据对象 | 键 |
| 数据对象 | 给定键对应的值 |
| 响应类型 | 描述 |
|---|---|
| 头信息 | 响应头 |
| bool | 表示是否替换成功 |
- 请求
- 响应
DataOutputStream out = new DataOutputStream(socket.getOutputStream());
// Request header
writeRequestHeader(15, OP_CACHE_REPLACE, 1, out);
// Cache id
writeIntLittleEndian(cacheName.hashCode(), out);
// Flags = none
writeByteLittleEndian(0, out);
// Cache key data object
writeByteLittleEndian(3, out); // Integer type code
writeIntLittleEndian(key, out); // Cache key
// Cache value data object
writeByteLittleEndian(3, out); // Integer type code
writeIntLittleEndian(value, out); // Cache value
#8.3.14.OP_CACHE_REPLACE_IF_EQUALS
当在缓存中给定的键已存在且值等于给定的值时,才会用新值替换旧值。
| 请求类型 | 描述 |
|---|---|
| 头信息 | 请求头 |
| int | 缓存ID,Java风格的缓存名的哈希值 |
| byte | 0,该字段被废弃,未来会删除 |
| 数据对象 | 键 |
| 数据对象 | 用于和给定的键对应的值做比较的值 |
| 数据对象 | 给定键对应的值 |
| 响应类型 | 描述 |
|---|---|
| 头信息 | 响应头 |
| bool | 表示是否替换成功 |
- 请求
- 响应
DataOutputStream out = new DataOutputStream(socket.getOutputStream());
// Request header
writeRequestHeader(20, OP_CACHE_REPLACE_IF_EQUALS, 1, out);
// Cache id
writeIntLittleEndian(cacheName.hashCode(), out);
// Flags = none
writeByteLittleEndian(0, out);
// Cache key data object
writeByteLittleEndian(3, out); // Integer type code
writeIntLittleEndian(key, out); // Cache key
// Cache value data object
writeByteLittleEndian(3, out); // Integer type code
writeIntLittleEndian(value, out); // Cache value to compare
// Cache value data object
writeByteLittleEndian(3, out); // Integer type code
writeIntLittleEndian(newValue, out); // New cache value
#8.3.15.OP_CACHE_CLEAR
清空缓存而不通知监听器或者缓存写入器,具体可以看对应方法的文档。
| 请求类型 | 描述 |
|---|---|
| 头信息 | 请求头 |
| int | 缓存ID,Java风格的缓存名的哈希值 |
| byte | 0,该字段被废弃,未来会删除 |
| 响应类型 | 描述 |
|---|---|
| 头信息 | 响应头 |
- 请求
- 响应
DataOutputStream out = new DataOutputStream(socket.getOutputStream());
// Request header
writeRequestHeader(5, OP_CACHE_CLEAR, 1, out);
// Cache id
writeIntLittleEndian(cacheName.hashCode(), out);
// Flags = none
writeByteLittleEndian(0, out);
#8.3.16.OP_CACHE_CLEAR_KEY
清空缓存键而不通知监听器或者缓存写入器,具体可以看对应方法的文档。
| 请求类型 | 描述 |
|---|---|
| 头信息 | 请求头 |
| int | 缓存ID,Java风格的缓存名的哈希值 |
| byte | 0,该字段被废弃,未来会删除 |
| 数据对象 | 缓存条目的键 |
| 响应类型 | 描述 |
|---|---|
| 头信息 | 响应头 |
- 请求
- 响应
DataOutputStream out = new DataOutputStream(socket.getOutputStream());
// Request header
writeRequestHeader(10, OP_CACHE_CLEAR_KEY, 1, out);;
// Cache id
writeIntLittleEndian(cacheName.hashCode(), out);
// Flags = none
writeByteLittleEndian(0, out);
// Cache key data object
writeByteLittleEndian(3, out); // Integer type code
writeIntLittleEndian(key, out); // Cache key
#8.3.17.OP_CACHE_CLEAR_KEYS
清空缓存的多个键而不通知监听器或者缓存写入器,具体可以看对应方法的文档。
| 请求类型 | 描述 |
|---|---|
| 头信息 | 请求头 |
| int | 缓存ID,Java风格的缓存名的哈希值 |
| byte | 0,该字段被废弃,未来会删除 |
| int | 键数量 |
| 数据对象×键数量 | 缓存条目的键 |
| 响应类型 | 描述 |
|---|---|
| 头信息 | 响应头 |
- 请求
- 响应
DataOutputStream out = new DataOutputStream(socket.getOutputStream());
// Request header
writeRequestHeader(19, OP_CACHE_CLEAR_KEYS, 1, out);
// Cache id
writeIntLittleEndian(cacheName.hashCode(), out);
// Flags = none
writeByteLittleEndian(0, out);
// key count
writeIntLittleEndian(2, out);
// Cache key data object 1
writeByteLittleEndian(3, out); // Integer type code
writeIntLittleEndian(key1, out); // Cache key
// Cache key data object 2
writeByteLittleEndian(3, out); // Integer type code
writeIntLittleEndian(key2, out); // Cache key
#8.3.18.OP_CACHE_REMOVE_KEY
删除给定键对应的数据,通知监听器和缓存的写入器,具体可以看相关方法的文档。
| 请求类型 | 描述 |
|---|---|
| 头信息 | 请求头 |
| int | 缓存ID,Java风格的缓存名的哈希值 |
| byte | 0,该字段被废弃,未来会删除 |
| 数据对象 | 键 |
| 响应类型 | 描述 |
|---|---|
| 头信息 | 响应头 |
| bool | 表示是否删除成功 |
- 请求
- 响应
DataOutputStream out = new DataOutputStream(socket.getOutputStream());
// Request header
writeRequestHeader(10, OP_CACHE_REMOVE_KEY, 1, out);
// Cache id
writeIntLittleEndian(cacheName.hashCode(), out);
// Flags = none
writeByteLittleEndian(0, out);
// Cache key data object
writeByteLittleEndian(3, out); // Integer type code
writeIntLittleEndian(key1, out); // Cache key
#8.3.19.OP_CACHE_REMOVE_IF_EQUALS
当给定的值等于当前值时,删除缓存中给定键对应的条目,然后通知监听器和缓存写入器。
| 请求类型 | 描述 |
|---|---|
| 头信息 | 请求头 |
| int | 缓存ID,Java风格的缓存名的哈希值 |
| byte | 0,该字段被废弃,未来会删除 |
| 数据对象 | 要删除条目的键 |
| 数据对象 | 用于和当前值比较的值 |
| 响应类型 | 描述 |
|---|---|
| 头信息 | 响应头 |
| bool | 表示是否删除成功 |
- 请求
- 响应
DataOutputStream out = new DataOutputStream(socket.getOutputStream());
// Request header
writeRequestHeader(15, OP_CACHE_REMOVE_IF_EQUALS, 1, out);
// Cache id
writeIntLittleEndian(cacheName.hashCode(), out);
// Flags = none
writeByteLittleEndian(0, out);
// Cache key data object
writeByteLittleEndian(3, out); // Integer type code
writeIntLittleEndian(key, out); // Cache key
// Cache value data object
writeByteLittleEndian(3, out); // Integer type code
writeIntLittleEndian(value, out); // Cache value
#8.3.20.OP_CACHE_GET_SIZE
获取缓存条目的数量,该方法等同于IgniteCache.size(CachePeekMode... peekModes)。
| 请求类型 | 描述 |
|---|---|
| 头信息 | 请求头 |
| int | 缓存ID,Java风格的缓存名的哈希值 |
| byte | 0,该字段被废弃,未来会删除 |
| int | 要请求的PEEK模式数值。当设置为0时,将使用CachePeekMode.ALL。当设置为正值时,需要在以下字段中指定应计数的条目类型:全部、备份、主或近缓存条目。 |
| byte | 表示要统计哪种类型的条目:0:所有,1:近缓存条目,2:主条目,3:备份条目,该字段的重复次数应等于上一个参数的值 |
| 响应类型 | 描述 |
|---|---|
| 头信息 | 响应头 |
| long | 缓存大小 |
- 请求
- 响应
DataOutputStream out = new DataOutputStream(socket.getOutputStream());
// Request header
writeRequestHeader(10, OP_CACHE_GET_SIZE, 1, out);
// Cache id
writeIntLittleEndian(cacheName.hashCode(), out);
// Flags = none
writeByteLittleEndian(0, out);
// Peek mode count; '0' means All
writeIntLittleEndian(0, out);
// Peek mode
writeByteLittleEndian(0, out);
#8.3.21.OP_CACHE_REMOVE_KEYS
删除给定键对应的条目,通知监听器和缓存写入器,具体可以看相关方法的文档。
| 请求类型 | 描述 |
|---|---|
| 头信息 | 请求头 |
| int | 缓存ID,Java风格的缓存名的哈希值 |
| byte | 0,该字段被废弃,未来会删除 |
| int | 要删除的键数量 |
| 数据对象 | 要删除条目的键,如果该键不存在,则会被忽略,该字段必须提供,重复次数为前一个参数的值 |
| 响应类型 | 描述 |
|---|---|
| 头信息 | 响应头 |
- 请求
- 响应
DataOutputStream out = new DataOutputStream(socket.getOutputStream());
// Request header
writeRequestHeader(19, OP_CACHE_REMOVE_KEYS, 1, out);
// Cache id
writeIntLittleEndian(cacheName.hashCode(), out);
// Flags = none
writeByteLittleEndian(0, out);
// key count
writeIntLittleEndian(2, out);
// Cache key data object 1
writeByteLittleEndian(3, out); // Integer type code
writeIntLittleEndian(key1, out); // Cache key
// Cache value data object 2
writeByteLittleEndian(3, out); // Integer type code
writeIntLittleEndian(key2, out); // Cache key
#8.3.22.OP_CACHE_REMOVE_ALL
从缓存中删除所有的条目,通知监听器和缓存写入器,具体可以看相关方法的文档。
| 请求类型 | 描述 |
|---|---|
| 头信息 | 请求头 |
| int | 缓存ID,Java风格的缓存名的哈希值 |
| byte | 0,该字段被废弃,未来会删除 |
| 响应类型 | 描述 |
|---|---|
| 头信息 | 响应头 |
- 请求
- 响应
DataOutputStream out = new DataOutputStream(socket.getOutputStream());
// Request header
writeRequestHeader(5, OP_CACHE_REMOVE_ALL, 1, out);
// Cache id
writeIntLittleEndian(cacheName.hashCode(), out);
// Flags = none
writeByteLittleEndian(0, out);
#3.4.SQL和扫描查询
#3.4.1.操作代码
与Ignite服务端节点成功握手后,客户端就可以通过发送带有某个操作代码的请求(请参见下面的请求/响应结构)来执行各种SQL和扫描查询了:
| 操作 | 操作代码 |
|---|---|
OP_QUERY_SQL | 2002 |
OP_QUERY_SQL_CURSOR_GET_PAGE | 2003 |
OP_QUERY_SQL_FIELDS | 2004 |
OP_QUERY_SQL_FIELDS_CURSOR_GET_PAGE | 2005 |
OP_QUERY_SCAN | 2000 |
OP_QUERY_SCAN_CURSOR_GET_PAGE | 2001 |
OP_RESOURCE_CLOSE | 0 |
注意上面提到的操作代码,是请求头的一部分,具体可以看头信息的相关内容。
#3.4.2.OP_QUERY_SQL
在集群存储的数据中执行SQL查询,查询会返回所有的结果集(键-值对)。
| 请求类型 | 描述 |
|---|---|
| 头信息 | 请求头 |
| int | 缓存ID,Java风格的缓存名的哈希值 |
| byte | 0,该字段被废弃,未来会删除 |
| string | 类型或者SQL表名 |
| string | SQL查询字符串 |
| int | 查询参数个数 |
| 数据对象 | 查询参数,重复多次,次数为前一个参数传递的值 |
| bool | 分布式关联标志 |
| bool | 本地查询标志 |
| bool | 复制标志,查询是否只包含复制表 |
| int | 游标页面大小 |
| long | 超时时间(毫秒),应该为非负值,值为0会禁用超时功能 |
响应只包含第一页的结果。
| 响应类型 | 描述 |
|---|---|
| 头信息 | 响应头 |
| long | 游标ID,可以被OP_RESOURSE_CLOSE关闭 |
| int | 第一页的行数 |
| 键数据对象+值数据对象 | 键-值对形式的记录,重复多次,次数为前一个参数返回的行数值 |
| bool | 指示是否有更多结果可通过OP_QUERY_SQL_CURSOR_GET_PAGE获取。如果为false,则查询游标将自动关闭。 |
- 请求
- 响应
String entityName = "Person";
int entityNameLength = getStrLen(entityName); // UTF-8 bytes
String sql = "Select * from Person";
int sqlLength = getStrLen(sql);
DataOutputStream out = new DataOutputStream(socket.getOutputStream());
// Request header
writeRequestHeader(34 + entityNameLength + sqlLength, OP_QUERY_SQL, 1, out);
// Cache id
String queryCacheName = "personCache";
writeIntLittleEndian(queryCacheName.hashCode(), out);
// Flag = none
writeByteLittleEndian(0, out);
// Query Entity
writeString(entityName, out);
// SQL query
writeString(sql, out);
// Argument count
writeIntLittleEndian(0, out);
// Joins
out.writeBoolean(false);
// Local query
out.writeBoolean(false);
// Replicated
out.writeBoolean(false);
// cursor page size
writeIntLittleEndian(1, out);
// Timeout
writeLongLittleEndian(5000, out);
#3.4.3.OP_QUERY_SQL_CURSOR_GET_PAGE
通过OP_QUERY_SQL的游标ID,查询下一个游标页。
| 请求类型 | 描述 |
|---|---|
| 头信息 | 请求头 |
| long | 游标ID |
| 响应类型 | 描述 |
|---|---|
| 头信息 | 响应头 |
| long | 游标ID |
| int | 行数 |
| 键数据对象+值数据对象 | 键-值对形式的记录,重复多次,次数为前一个参数返回的行数值 |
| bool | 指示是否有更多结果可通过OP_QUERY_SQL_CURSOR_GET_PAGE获取。如果为false,则查询游标将自动关闭。 |
- 请求
- 响应
DataOutputStream out = new DataOutputStream(socket.getOutputStream());
// Request header
writeRequestHeader(8, OP_QUERY_SQL_CURSOR_GET_PAGE, 1, out);
// Cursor Id (received from Sql query operation)
writeLongLittleEndian(cursorId, out);
#3.4.4.OP_QUERY_SQL_FIELDS
执行SQLFieldQuery。
| 请求类型 | 描述 |
|---|---|
| 头信息 | 请求头 |
| int | 缓存ID,Java风格的缓存名的哈希值 |
| byte | 0,该字段被废弃,未来会删除 |
| string | 查询的模式,可以为空,默认为PUBLIC模式 |
| int | 查询游标页面大小 |
| int | 最大行数 |
| string | SQL |
| int | 参数个数 |
| 数据对象 | 重复多次,重复次数为前一个参数值 |
| byte | 语句类型。ANY:0,SELECT:1,UPDATE:2 |
| bool | 分布式关联标志 |
| bool | 本地查询标志 |
| bool | 复制标志,查询涉及的表是否都为复制表 |
| bool | 是否强制关联的顺序 |
| bool | 数据是否并置标志 |
| bool | 是否延迟查询的执行 |
| long | 超时(毫秒) |
| bool | 是否包含字段名 |
| 响应类型 | 描述 |
|---|---|
| 头信息 | 响应头 |
| long | 游标ID,可以被OP_RESOURCE_CLOSE关闭 |
| int | 字段(列)数量 |
| string(可选) | 只有请求中的IncludeFieldNames标志为true时才是必须的,列名,重复多次,重复次数为前一个参数的值 |
| int | 第一页行数 |
| 数据对象 | 字段(列)值,字段个数重复次数为前述字段数量参数值,行数重复次数为前一个参数的值 |
| bool | 表示是否还可以通过OP_QUERY_SQL_FIELDS_CURSOR_GET_PAGE获得更多结果 |
- 请求
- 响应
String sql = "Select id, salary from Person";
int sqlLength = sql.getBytes("UTF-8").length;
String sqlSchema = "PUBLIC";
int sqlSchemaLength = sqlSchema.getBytes("UTF-8").length;
DataOutputStream out = new DataOutputStream(socket.getOutputStream());
// Request header
writeRequestHeader(43 + sqlLength + sqlSchemaLength, OP_QUERY_SQL_FIELDS, 1, out);
// Cache id
String queryCacheName = "personCache";
int cacheId = queryCacheName.hashCode();
writeIntLittleEndian(cacheId, out);
// Flag = none
writeByteLittleEndian(0, out);
// Schema
writeByteLittleEndian(9, out);
writeIntLittleEndian(sqlSchemaLength, out);
out.writeBytes(sqlSchema); //sqlSchemaLength
// cursor page size
writeIntLittleEndian(2, out);
// Max Rows
writeIntLittleEndian(5, out);
// SQL query
writeByteLittleEndian(9, out);
writeIntLittleEndian(sqlLength, out);
out.writeBytes(sql);//sqlLength
// Argument count
writeIntLittleEndian(0, out);
// Statement type
writeByteLittleEndian(1, out);
// Joins
out.writeBoolean(false);
// Local query
out.writeBoolean(false);
// Replicated
out.writeBoolean(false);
// Enforce join order
out.writeBoolean(false);
// collocated
out.writeBoolean(false);
// Lazy
out.writeBoolean(false);
// Timeout
writeLongLittleEndian(5000, out);
// Replicated
out.writeBoolean(false);
#3.4.5.OP_QUERY_SQL_FIELDS_CURSOR_GET_PAGE
通过OP_QUERY_SQL_FIELDS的游标ID,获取下一页的查询结果。
| 请求类型 | 描述 |
|---|---|
| 头信息 | 请求头 |
| long | 从OP_QUERY_SQL_FIELDS获取的游标ID |
| 响应类型 | 描述 |
|---|---|
| 头信息 | 响应头 |
| int | 行数 |
| 数据对象 | 字段(列)值,字段个数重复次数为前述字段数量参数值,行数重复次数为前一个参数的值 |
| bool | 指示是否有更多结果可通过OP_QUERY_SQL_FIELDS_CURSOR_GET_PAGE获取。 |
- 请求
- 响应
DataOutputStream out = new DataOutputStream(socket.getOutputStream());
// Request header
writeRequestHeader(8, QUERY_SQL_FIELDS_CURSOR_GET_PAGE, 1, out);
// Cursor Id
writeLongLittleEndian(1, out);
#3.4.6.OP_QUERY_SCAN
执行扫描查询。
| 请求类型 | 描述 |
|---|---|
| 头信息 | 请求头 |
| int | 缓存ID,Java风格的缓存名的哈希值 |
| byte | 标志,0为默认值,或者1为保持值的二进制形式 |
| 数据对象 | 过滤器对象,如果不打算在集群中过滤数据可以为null,过滤器类应该加入服务端节点的类路径中 |
| byte | 过滤器平台。JAVA:1,DOTNET:2,CPP:3,过滤器对象非空时,需要这个参数 |
| int | 游标页面大小 |
| int | 要查询的分区数(对于查询整个缓存为负数) |
| bool | 本地标志,查询是否只在本地节点执行 |
| 响应类型 | 描述 |
|---|---|
| 头信息 | 响应头 |
| long | 游标ID |
| int | 行数 |
| 键数据对象+值数据对象 | 键-值对形式的记录,重复多次,次数为前一个参数返回的行数值 |
| bool | 指示是否有更多结果可通过OP_QUERY_SCAN_CURSOR_GET_PAGE获取。如果为false,则查询游标将自动关闭。 |
- 请求
- 响应
DataOutputStream out = new DataOutputStream(socket.getOutputStream());
// Request header
writeRequestHeader(15, OP_QUERY_SCAN, 1, out);
// Cache id
String queryCacheName = "personCache";
writeIntLittleEndian(queryCacheName.hashCode(), out);
// flags
writeByteLittleEndian(0, out);
// Filter Object
writeByteLittleEndian(101, out); // null
// Cursor page size
writeIntLittleEndian(1, out);
// Partition to query
writeIntLittleEndian(-1, out);
// local flag
out.writeBoolean(false);
#3.4.7.OP_QUERY_SCAN_CURSOR_GET_PAGE
通过OP_QUERY_SCAN获取的游标,查询下一页的数据。
| 请求类型 | 描述 |
|---|---|
| 头信息 | 请求头 |
| long | 游标ID |
| 响应类型 | 描述 |
|---|---|
| 头信息 | 响应头 |
| long | 游标ID |
| int | 行数 |
| 键数据对象+值数据对象 | 键-值对形式的记录,重复多次,次数为前一个参数返回的行数值 |
| bool | 指示是否有更多结果可通过OP_QUERY_SCAN_CURSOR_GET_PAGE获取。如果为false,则查询游标将自动关闭。 |
#3.4.8.OP_RESOURCE_CLOSE
关闭一个资源,比如游标。
| 请求类型 | 描述 |
|---|---|
| 头信息 | 请求头 |
| long | 资源ID |
| 响应类型 | 描述 |
|---|---|
| 头信息 | 响应头 |
- 请求
- 响应
DataOutputStream out = new DataOutputStream(socket.getOutputStream());
// Request header
writeRequestHeader(8, OP_RESOURCE_CLOSE, 1, out);
// Resource id
long cursorId = 1;
writeLongLittleEndian(cursorId, out);
#8.5.二进制类型元数据
#8.5.1.操作代码
与Ignite服务端节点成功握手后,客户端就可以通过发送带有某个操作代码的请求(请参见下面的请求/响应结构)来执行与二进制类型有关的各种操作了:
| 操作 | 操作代码 |
|---|---|
OP_GET_BINARY_TYPE_NAME | 3000 |
OP_REGISTER_BINARY_TYPE_NAME | 3001 |
OP_GET_BINARY_TYPE | 3002 |
OP_PUT_BINARY_TYPE | 3003 |
注意上面提到的操作代码,是请求头的一部分,具体可以看头信息的相关内容。
#8.5.2.OP_GET_BINARY_TYPE_NAME
通过ID取得和平台相关的完整二进制类型名,比如,.NET和Java都可以映射相同的类型Foo,但是在.NET中类型是Apache.Ignite.Foo,而在Java中是org.apache.ignite.Foo。
名字是使用OP_REGISTER_BINARY_TYPE_NAME注册的。
| 请求类型 | 描述 |
|---|---|
| 头信息 | 请求头 |
| byte | 平台ID。Java:0,DOTNET:1 |
| int | 类型ID,Java风格类型名字的哈希值 |
| 响应类型 | 描述 |
|---|---|
| 头信息 | 响应头 |
| string | 二进制类型名 |
- 请求
- 响应
String type = "ignite.myexamples.model.Person";
int typeLen = type.getBytes("UTF-8").length;
DataOutputStream out = new DataOutputStream(socket.getOutputStream());
// Request header
writeRequestHeader(5, OP_GET_BINARY_TYPE_NAME, 1, out);
// Platform id
writeByteLittleEndian(0, out);
// Type id
writeIntLittleEndian(type.hashCode(), out);
#8.5.3.OP_REGISTER_BINARY_TYPE_NAME
通过ID注册平台相关的完整二进制类型名,比如,.NET和Java都可以映射相同的类型Foo,但是在.NET中类型是Apache.Ignite.Foo,而在Java中是org.apache.ignite.Foo。
| 请求类型 | 描述 |
|---|---|
| 头信息 | 请求头 |
| byte | 平台ID。Java:0,DOTNET:1 |
| int | 类型ID,Java风格类型名字的哈希值 |
| string | 类型名 |
| 响应类型 | 描述 |
|---|---|
| 头信息 | 响应头 |
- 请求
- 响应
String type = "ignite.myexamples.model.Person";
int typeLen = type.getBytes("UTF-8").length;
DataOutputStream out = new DataOutputStream(socket.getOutputStream());
// Request header
writeRequestHeader(20 + typeLen, OP_PUT_BINARY_TYPE_NAME, 1, out);
//Platform id
writeByteLittleEndian(0, out);
//Type id
writeIntLittleEndian(type.hashCode(), out);
// Type name
writeString(type, out);
#8.5.4.OP_GET_BINARY_TYPE
通过ID获取二进制类型信息。
| 请求类型 | 描述 |
|---|---|
| 头信息 | 请求头 |
| int | 类型ID,Java风格类型名字的哈希值 |
| 响应类型 | 描述 |
|---|---|
| 头信息 | 响应头 |
| bool | false:二进制类型不存在,响应结束,true:二进制类型存在,内容如下 |
| int | 类型ID,Java风格类型名字的哈希值 |
| string | 类型名 |
| string | 关联键字段名 |
| int | BinaryField计数 |
| BinaryField*count | BinaryField结构。String:字段名;int:类型ID,Java风格类型名哈希值;int:字段ID,Java风格字段名哈希值 |
| bool | 是否枚举值,如果为true,则需要传入下面两个参数,否则会被忽略 |
| int | 只有在enum参数为true时才是必须,枚举字段数量 |
| string+int | 只有在enum参数为true时才是必须,枚举值,枚举值是一对字面量值(字符串)和一个数值(整型)组成。重复多次,重复次数为前一个参数的值 |
| int | BinarySchema计数 |
| BinarySchema | BinarySchema结构。int:唯一模式ID;int:模式中字段数;int:字段ID,Java风格字段名哈希值,重复多次,重复次数为模式中字段数量,BinarySchema重复次数为前一个参数数值 |
- 请求
- 响应
String type = "ignite.myexamples.model.Person";
DataOutputStream out = new DataOutputStream(socket.getOutputStream());
// Request header
writeRequestHeader(4, OP_BINARY_TYPE_GET, 1, out);
// Type id
writeIntLittleEndian(type.hashCode(), out);
#8.5.5.OP_PUT_BINARY_TYPE
在集群中注册二进制类型信息。
| 请求类型 | 描述 |
|---|---|
| 头信息 | 请求头 |
| int | 类型ID,Java风格类型名字的哈希值 |
| string | 类型名 |
| string | 关联键字段名 |
| int | BinaryField计数 |
| BinaryField | BinaryField结构。String:字段名;int:类型ID,Java风格类型名哈希值;int:字段ID,Java风格字段名哈希值;重复多次,重复次数为前一个参数传递的值 |
| bool | 是否枚举值,如果为true,则需要传入下面两个参数,否则会被忽略 |
| int | 只有在enum参数为true时才是必须,枚举字段数量 |
| string+int | 只有在enum参数为true时才是必须,枚举值,枚举值是一对字面量值(字符串)和一个数值(整型)组成。重复多次,重复次数为前一个参数的值 |
| int | BinarySchema计数 |
| BinarySchema | BinarySchema结构。int:唯一模式ID;int:模式中字段数;int:字段ID,Java风格字段名哈希值,重复多次,重复次数为模式中字段数量,BinarySchema重复次数为前一个参数数值 |
| 响应类型 | 描述 |
|---|---|
| 头信息 | 响应头 |
- 请求
- 响应
String type = "ignite.myexamples.model.Person";
DataOutputStream out = new DataOutputStream(socket.getOutputStream());
// Request header
writeRequestHeader(120, OP_BINARY_TYPE_PUT, 1, out);
// Type id
writeIntLittleEndian(type.hashCode(), out);
// Type name
writeString(type, out);
// Affinity key field name
writeByteLittleEndian(101, out);
// Field count
writeIntLittleEndian(3, out);
// Field 1
String field1 = "id";
writeBinaryTypeField(field1, "long", out);
// Field 2
String field2 = "name";
writeBinaryTypeField(field2, "String", out);
// Field 3
String field3 = "salary";
writeBinaryTypeField(field3, "int", out);
// isEnum
out.writeBoolean(false);
// Schema count
writeIntLittleEndian(1, out);
// Schema
writeIntLittleEndian(657, out); // Schema id; can be any custom value
writeIntLittleEndian(3, out); // field count
writeIntLittleEndian(field1.hashCode(), out);
writeIntLittleEndian(field2.hashCode(), out);
writeIntLittleEndian(field3.hashCode(), out);
private static void writeBinaryTypeField (String field, String fieldType, DataOutputStream out) throws IOException{
writeString(field, out);
writeIntLittleEndian(fieldType.hashCode(), out);
writeIntLittleEndian(field.hashCode(), out);
}
#8.6.缓存配置
#8.6.1.操作代码
与Ignite服务端节点成功握手后,客户端就可以通过发送带有某个操作代码的请求(请参见下面的请求/响应结构)来执行各种缓存配置操作了:
| 操作 | 操作代码 |
|---|---|
OP_CACHE_GET_NAMES | 1050 |
OP_CACHE_CREATE_WITH_NAME | 1051 |
OP_CACHE_GET_OR_CREATE_WITH_NAME | 1052 |
OP_CACHE_CREATE_WITH_CONFIGURATION | 1053 |
OP_CACHE_GET_OR_CREATE_WITH_CONFIGURATION | 1054 |
OP_CACHE_GET_CONFIGURATION | 1055 |
OP_CACHE_DESTROY | 1056 |
注意上面提到的操作代码,是请求头的一部分,具体可以看头信息的相关内容。
#8.6.2.OP_CACHE_CREATE_WITH_NAME
通过给定的名字创建缓存,如果缓存的名字中有*,则可以应用一个缓存模板,如果给定名字的缓存已经存在,则会抛出异常。
| 请求类型 | 描述 |
|---|---|
| 头信息 | 请求头 |
| string | 缓存名 |
| 响应类型 | 描述 |
|---|---|
| 头信息 | 响应头 |
- 请求
- 响应
DataOutputStream out = new DataOutputStream(socket.getOutputStream());
String cacheName = "myNewCache";
int nameLength = cacheName.getBytes("UTF-8").length;
DataOutputStream out = new DataOutputStream(socket.getOutputStream());
// Request header
writeRequestHeader(5 + nameLength, OP_CACHE_CREATE_WITH_NAME, 1, out);
// Cache name
writeString(cacheName, out);
// Send request
out.flush();
#8.6.3.OP_CACHE_GET_OR_CREATE_WITH_NAME
通过给定的名字创建缓存,如果缓存的名字中有*,则可以应用一个缓存模板,如果给定名字的缓存已经存在,则什么也不做。
| 请求类型 | 描述 |
|---|---|
| 头信息 | 请求头 |
| string | 缓存名 |
| 响应类型 | 描述 |
|---|---|
| 头信息 | 响应头 |
- 请求
- 响应
DataOutputStream out = new DataOutputStream(socket.getOutputStream());
String cacheName = "myNewCache";
int nameLength = cacheName.getBytes("UTF-8").length;
DataOutputStream out = new DataOutputStream(socket.getOutputStream());
// Request header
writeRequestHeader(5 + nameLength, OP_CACHE_GET_OR_CREATE_WITH_NAME, 1, out);
// Cache name
writeString(cacheName, out);
// Send request
out.flush();
#8.6.4.OP_CACHE_GET_NAMES
获取已有缓存的名字。
| 请求类型 | 描述 |
|---|---|
| 头信息 | 请求头 |
| 响应类型 | 描述 |
|---|---|
| 头信息 | 响应头 |
| int | 缓存数量 |
| string | 缓存名字,重复多次,重复次数为前一个参数的返回值 |
- 请求
- 响应
DataOutputStream out = new DataOutputStream(socket.getOutputStream());
// Request header
writeRequestHeader(5, OP_CACHE_GET_NAMES, 1, out);
#8.6.5.OP_CACHE_GET_CONFIGURATION
获取指定缓存的配置信息。
| 请求类型 | 描述 |
|---|---|
| 头信息 | 请求头 |
| int | 缓存ID,Java风格的缓存名的哈希值 |
| type | 标志 |
| 响应类型 | 描述 |
|---|---|
| 头信息 | 响应头 |
| int | 以字节计算的配置信息的长度(所有的配置参数) |
| CacheConfiguration | 缓存配置的结构,具体见下表 |
CacheConfiguration
| 类型 | 描述 |
|---|---|
| int | 备份数量 |
| int | CacheMode。LOCAL:0;REPLICATED:1;PARTITIONED:2 |
| bool | CopyOnRead标志 |
| string | 内存区名字 |
| bool | EagerTTL标志 |
| bool | 指标统计标志 |
| string | 缓存组名 |
| bool | 无效标志 |
| long | 默认锁超时时间(毫秒) |
| int | 最大查询迭代数 |
| string | 缓存名 |
| bool | 堆内缓存开启标志 |
| int | 分区丢失策略。READ_ONLY_SAFE:0;READ_ONLY_ALL:1;READ_WRITE_SAFE:2;READ_WRITE_ALL:3;IGNORE:4 |
| int | QueryDetailMetricsSize |
| int | QueryParellelism |
| bool | 是否从备份读取标志 |
| int | 再平衡缓存区大小 |
| long | 再平衡批处理预取计数 |
| long | 再平衡延迟时间(毫秒) |
| int | 再平衡模式。SYNC:0;ASYNC:1;NONE:2 |
| int | 再平衡顺序 |
| long | 再平衡调节(毫秒) |
| long | 再平衡超时(毫秒) |
| bool | SqlEscapeAll |
| int | SqlIndexInlineMaxSize |
| string | SQL模式 |
| int | 写同步模式。FULL_SYNC:0;FULL_ASYNC:1;PRIMARY_SYNC:2 |
| int | CacheKeyConfiguration计数 |
| CacheKeyConfiguration | CacheKeyConfiguration结构。String:类型名;String:关联键字段名。重复多次,重复次数为前一参数返回值 |
| int | QueryEntity计数 |
| QueryEntity | QueryEntity结构,具体见下表 |
QueryEntity
| 类型 | 描述 |
|---|---|
| string | 键类型名 |
| string | 值类型名 |
| string | 表名 |
| string | 键字段名 |
| string | 值字段名 |
| int | QueryField计数 |
| QueryField | QueryField结构。String:名字;String:类型名;bool:是否键字段;bool:是否有非空约束。重复多次,重复次数为前一参数对应值 |
| int | 别名计数 |
| string+string | 字段名别名 |
| int | QueryIndex计数 |
| QueryIndex | QueryIndex结构。String:索引名;byte:索引类型,(SORTED:0;FULLTEXT:1;GEOSPATIAL:2);int:内联大小;int:字段计数;(string + bool):字段(名字+是否降序) |
- 请求
- 响应
String cacheName = "myCache";
DataOutputStream out = new DataOutputStream(socket.getOutputStream());
// Request header
writeRequestHeader(5, OP_CACHE_GET_CONFIGURATION, 1, out);
// Cache id
writeIntLittleEndian(cacheName.hashCode(), out);
// Flags = none
writeByteLittleEndian(0, out);
#8.6.6.OP_CACHE_CREATE_WITH_CONFIGURATION
用给定的配置创建缓存,如果该缓存已存在会抛出异常。
| 请求类型 | 描述 |
|---|---|
| 头信息 | 请求头 |
| int | 按字节计算的配置的长度(所有的配置参数) |
| short | 配置参数计数 |
| short + 属性类型 | 配置属性数据。重复多次,重复次数为前一参数对应值 |
配置参数的个数没有要求,但是Name必须提供。
缓存的配置数据是以键-值对的形式提供的,这里键是short类型的属性ID,而值是与键对应的数据,下表描述了所有可用的参数:
| 属性代码 | 属性类型 | 描述 |
|---|---|---|
| 2 | int | CacheAtomicityMode。TRANSACTIONAL:0;ATOMIC:1 |
| 3 | int | 备份数量 |
| 1 | int | CacheMode。LOCAL:0;REPLICATED:1;PARTITIONED:2 |
| 5 | bool | CopyOnRead |
| 100 | String | 内存区名 |
| 405 | bool | EagerTtl |
| 406 | bool | StatisticsEnabled |
| 400 | String | 缓存组名 |
| 402 | long | 默认锁超时时间(毫秒) |
| 403 | int | MaxConcurrentAsyncOperations |
| 206 | int | MaxQueryIterators |
| 0 | String | 缓存名 |
| 101 | bool | 堆内缓存启用标志 |
| 404 | int | PartitionLossPolicy。READ_ONLY_SAFE:0;READ_ONLY_ALL:1;READ_WRITE_SAFE:2;READ_WRITE_ALL:3;IGNORE:4 |
| 202 | int | QueryDetailMetricsSize |
| 201 | int | QueryParallelism |
| 6 | bool | ReadFromBackup |
| 303 | int | 再平衡批处理大小 |
| 304 | long | 再平衡批处理预读计数 |
| 301 | long | 再平衡延迟时间(毫秒) |
| 300 | int | RebalanceMode。SYNC:0;ASYNC:1;NONE:2 |
| 305 | int | 再平衡顺序 |
| 306 | long | 再平衡调节(毫秒) |
| 302 | long | 再平衡超时(毫秒) |
| 205 | bool | SqlEscapeAll |
| 204 | int | SqlIndexInlineMaxSize |
| 203 | String | SQL模式 |
| 4 | int | WriteSynchronizationMode。FULL_SYNC:0;FULL_ASYNC:1;PRIMARY_SYNC:2 |
| 401 | int+CacheKeyConfiguration | CacheKeyConfiguration计数+CacheKeyConfiguration。CacheKeyConfiguration结构。String:类型名;String:关联键字段名 |
| 200 | int+QueryEntity | QueryEntity计数+QueryEntity。QueryEntity结构如下表 |
QueryEntity
| 类型 | 描述 |
|---|---|
| string | 键类型名 |
| string | 值类型名 |
| string | 表名 |
| string | 键字段名 |
| string | 值字段名 |
| int | QueryField计数 |
| QueryField | QueryField结构。String:名字;String:类型名;bool:是否键字段;bool:是否有非空约束。重复多次,重复次数为前一参数对应值 |
| int | 别名计数 |
| string+string | 字段名别名 |
| int | QueryIndex计数 |
| QueryIndex | QueryIndex结构。String:索引名;byte:索引类型,(SORTED:0;FULLTEXT:1;GEOSPATIAL:2);int:内联大小;int:字段计数;(string + bool):字段(名字+是否降序) |
| 响应类型 | 描述 |
|---|---|
| 头信息 | 响应头 |
- 请求
- 响应
DataOutputStream out = new DataOutputStream(socket.getOutputStream());
// Request header
writeRequestHeader(30, OP_CACHE_CREATE_WITH_CONFIGURATION, 1, out);
// Config length in bytes
writeIntLittleEndian(16, out);
// Number of properties
writeShortLittleEndian(2, out);
// Backups opcode
writeShortLittleEndian(3, out);
// Backups: 2
writeIntLittleEndian(2, out);
// Name opcode
writeShortLittleEndian(0, out);
// Name
writeString("myNewCache", out);
#8.6.7.OP_CACHE_GET_OR_CREATE_WITH_CONFIGURATION
根据提供的配置创建缓存,如果该缓存已存在则什么都不做。
| 请求类型 | 描述 |
|---|---|
| 头信息 | 请求头 |
| CacheConfiguration | 缓存配置的结构,具体见前述 |
| 响应类型 | 描述 |
|---|---|
| 头信息 | 响应头 |
- 请求
- 响应
DataOutputStream out = new DataOutputStream(socket.getOutputStream());
writeRequestHeader(30, OP_CACHE_GET_OR_CREATE_WITH_CONFIGURATION, 1, out);
// Config length in bytes
writeIntLittleEndian(16, out);
// Number of properties
writeShortLittleEndian(2, out);
// Backups opcode
writeShortLittleEndian(3, out);
// Backups: 2
writeIntLittleEndian(2, out);
// Name opcode
writeShortLittleEndian(0, out);
// Name
writeString("myNewCache", out);
#8.6.8.OP_CACHE_DESTROY
销毁指定的缓存。
| 请求类型 | 描述 |
|---|---|
| 头信息 | 请求头 |
缓存ID,Java风格的缓存名的哈希值
| 响应类型 | 描述 |
|---|---|
| 头信息 | 响应头 |
- 请求
- 响应
String cacheName = "myCache";
DataOutputStream out = new DataOutputStream(socket.getOutputStream());
// Request header
writeRequestHeader(4, OP_CACHE_DESTROY, 1, out);
// Cache id
writeIntLittleEndian(cacheName.hashCode(), out);
// Send request
out.flush();
7.数据建模
#1.介绍
精心设计的数据模型可以提高应用的性能,高效地利用资源,并助力实现业务目标。在设计数据模型时,了解数据在Ignite集群中的分布方式以及访问数据的不同方式非常重要。
本章节会介绍Ignite数据分布模型的关键部分,包括分区和关联并置,以及用于访问数据的两个不同接口(键-值API和SQL)。
#1.1.概述
为了了解数据在Ignite中的存储和使用,有必要区分集群中数据的物理组织和逻辑表示,即用户将如何在应用中查看其数据。
在物理层,每个数据条目(缓存条目或表数据行)都以二进制对象的形式存储,然后整个数据集被划分为多个较小的集合,称为分区。分区均匀地分布在所有节点上。数据和分区之间以及分区和节点之间的映射方式都由关联函数控制。
在逻辑层,数据应该以易于使用的方式表示,并方便用户在其应用中使用。Ignite提供了两种不同的数据逻辑表示:键-值缓存和SQL表(模式)。尽管这两种表示形式可能看起来有所不同,但实际上它们是等效的,并且可以表示同一组数据。
提示
注意,在Ignite中,SQL表和键-值缓存的概念是相同(内部)数据结构的两个等效表示,可以使用键-值API或SQL语句或同时使用两者来访问数据。
#1.2.键-值缓存与SQL表
缓存是键-值对的集合,可以通过键-值API对其进行访问。Ignite中的SQL表与传统RDBMS中表的概念相对应,但有一些附加约束。例如每个SQL表必须有一个主键。
具有主键的表可以表示为键-值缓存,其中主键列用作键,其余的表列代表对象的字段(值)。

这两种表示形式之间的区别在于访问数据的方式。键-值缓存可以通过支持的编程语言来处理对象。SQL表支持传统的SQL语法,并且有助于从现有数据库进行迁移。开发者可以根据业务场景,灵活使用一种或两种方法。
缓存API支持以下功能:
- 支持JCache(JSR 107)规范;
- ACID事务;
- 持续查询;
- 事件。
提示
即使集群启动并运行后,也可以动态地创建键-值缓存和SQL表。
#1.3.二进制对象格式
Ignite以称为二进制对象的特定格式存储数据条目,这种序列化格式具有以下优点:
- 可以从序列化的对象读取任意字段,而无需把对象完全反序列化,这完全消除了在服务端节点的类路径上部署键和值类的要求;
- 可以从相同类型的对象中添加或删除字段。考虑到服务端节点没有模型类的定义,此功能允许动态更改对象的结构,甚至允许多个客户端共存不同版本的类定义;
- 可以基于类型名称构造新对象,而完全不需要类定义,因此可以动态创建类型;
- 在Java、.NET和C++平台之间可以互操作。
仅当使用默认的二进制编组器(即在配置中未设置其他编组器)时,才可以使用二进制对象。
有关如何配置和使用二进制对象的更多信息,请参见使用二进制对象章节。
#1.4.数据分区
数据分区是一种将大型数据集细分为较小的块,然后在所有服务端节点之间平均分配的方法。数据分区将在数据分区章节中详细介绍。
#2.数据分区
数据分区是一种将大型数据集细分为较小的块,然后在所有服务端节点之间平均分配的方法。
分区由关联函数控制,关联函数确定键和分区之间的映射。每个分区由一组有限的数字(默认为0到1023)标识。分区集合分布在当前可用的服务端节点上。因此,每个键都会映射到某个节点,并存储在该节点上。当集群中节点的数量发生变化时,将通过称为再平衡的过程在新的节点集之间重新分配分区。

关联函数将关联键作为参数。关联键可以是缓存中存储的对象的任何字段(SQL表中的任何列)。如果未指定关联键,则默认使用键(对于SQL表,它是PRIMARY KEY列)。
提示
关于数据分区的更多信息,请参见Ignite数据分区深度解读。
分区通过将读写操作分布式化来提高性能。此外还可以设计数据模型,以使同一类数据条目存储在一起(即存储在一个分区中)。当请求该数据时,仅扫描少量分区,这种技术称为关联并置。
分区实际上可以在任何规模上实现线性可伸缩性。随着数据集的增长,可以向集群添加更多节点,Ignite会确保数据在所有节点间“平均”分布。
#2.1.关联函数
关联函数控制数据条目和分区以及分区和节点之间的映射。默认的关联函数实现了约会哈希算法。它在分区到节点的映射中允许一些差异(即某些节点可能比其他节点持有的分区数量略多)。但是,关联函数可确保当拓扑更改时,分区仅迁移到新加入的节点或从离开的节点迁移,其余节点之间没有数据交换。
#2.2.分区/复制模式
创建缓存或SQL表时,可以在缓存操作的分区模式和复制模式之间进行选择。两种模式设计用于不同的场景,并提供不同的性能和可用性优势。
#2.2.1.PARTITIONED
在这种模式下,所有分区在所有服务端节点间平均分配。此模式是可扩展性最高的分布式缓存模式,可以在所有节点上的总内存(RAM和磁盘)中存储尽可能多的数据,实际上节点越多,可以存储的数据就越多。
与REPLICATED模式不同,该模式下更新成本很高,因为集群中的每个节点都需要更新。而在PARTITIONED模式下,更新成本很低,因为每个键只需要更新一个主节点(以及可选的一个或多个备份节点)。但是读取成本会高,因为只有某些节点才缓存有该数据。
提示
当数据集很大且更新频繁时,分区缓存是理想的选择。
下图说明了分区缓存的分布,可以看出,将键A分配给在JVM1中运行的节点,将键B分配给在JVM3中运行的节点,等等。

#2.2.2.REPLICATED
在REPLICATED模式下,所有数据(每个分区)都将复制到集群中的每个节点。由于每个节点上都有完整的数据,此缓存模式提供了最大的数据可用性。但是每次数据更新都必须传播到所有其他节点,这可能会影响性能和可扩展性。
提示
当数据集较小且不经常更新时,复制缓存非常理想。
在下图中,在JVM1中运行的节点是键A的主要节点,但它也存储了所有其他键(B,C,D)的备份副本。

因为相同的数据存储在所有集群节点上,所以复制缓存的大小受节点上可用内存(RAM和磁盘)的数量限制。对于缓存读多写少且数据集较小的场景,此模式是理想的。如果业务系统确实在80%的时间内都在进行缓存查找,那么应该考虑使用REPLICATED缓存模式。
#2.3.备份分区
Ignite默认会保存每个分区的单个副本(整个数据集的单个副本)。这时如果一个或多个节点故障,存储在这些节点上的分区将无法访问,为避免这种情况,Ignite可以配置为每个分区维护备份副本。
警告
备份默认是禁用的。
备份副本的配置是缓存(表)级的,如果配置2个备份副本,则集群将为每个分区维护3个副本。其中一个分区称为主分区,其他两个分区称为备份分区,主分区对应的节点称为该分区中存储的键的主节点,否则称为备份节点。
当某些键的主分区对应的节点离开集群时,Ignite会触发分区映射交换(PME)过程,PME会将键的某个备份分区(如果已配置)标记为主分区。
备份分区提高了数据的可用性,在某些情况下还会提高读操作的速度,因为如果本地节点可用,Ignite会从备份分区中读取数据(这是可以禁用的默认行为,具体请参见缓存配置章节)。但是备份也会增加内存消耗或持久化存储的大小(如果启用)。
提示
备份分区只能在PARTITIONED模式下配置,请参见配置分区备份章节。
#2.4.分区映射交换
分区映射交换(PME)是共享整个集群分区分布(分区映射)的信息的过程,以便每个节点都知道在哪里寻找某个键。无论是应用户请求还是由于故障,每当缓存的分区分配发生更改时(例如新节点加入拓扑或旧节点离开拓扑)都需要PME。
包括但不限于会触发PME的事件:
- 一个新节点加入/离开拓扑;
- 新的缓存开始/停止;
- 创建索引。
当发生PME触发事件时,集群将等待所有正在进行的事务完成,然后启动PME。同样在PME期间,新事务将推迟直到该过程完成。
PME过程的工作方式是:协调器节点向所有节点请求其拥有的分区信息,然后每个节点将此信息反馈给协调器。协调器收到所有节点的消息后,会将所有信息合并为完整的分区映射,并将其发送给所有节点。当协调器接收了所有节点的确认消息后,PME过程就完成了。
#2.5.再平衡
有关详细信息,请参见数据再平衡章节的内容。
#2.6.分区丢失策略
在整个集群的生命周期中,由于某些拥有分区副本的主节点和备份节点的故障,一些数据分区可能丢失。这种情况会导致部分数据丢失,需要根据具体业务场景进行处理。有关分区丢失策略的详细信息,请参见分区丢失策略。
#3.关联并置
在许多情况下,如果不同的条目经常一起访问,则将它们并置在一起就很有用,即在一个节点(存储对象的节点)上就可以执行多条目查询,这个概念称为关联并置。
关联函数将条目分配给分区,具有相同关联键的对象将进入相同的分区,这样就可以设计将相关条目存储在一起的数据模型,这里的“相关”是指处于父子关系的对象或经常一起查询的对象。
例如,假设有Person和Company对象,并且每个人都有一个companyId字段,该字段表示其所在的公司。通过将Person.companyId和Company.ID作为关联键,可以保证同一公司的所有人都存储在同一节点上,该节点也存储了公司对象,这样查询在某公司工作的人就可以在单个节点上处理。
还可以将计算任务与数据并置,具体请参见计算和数据并置。
#3.1.配置关联键
如果未明确指定关联键,则将缓存键用作默认的关联键,如果使用SQL语句将缓存创建为SQL表,则PRIMARY KEY是默认的关联键。
如果要通过不同的字段并置来自两个缓存的数据,则必须使用复杂的对象作为键。该对象通常包含一个唯一地标识该缓存中的对象的字段,以及一个要用于并置的字段。
下面会介绍自定义键中配置自定义关联键的几种方法。
以下示例说明了如何使用自定义键类和@AffinityKeyMapped注解将人对象与公司对象并置:
- Java
- C#/.NET
- SQL
public class AffinityCollocationExample {
static class Person {
private int id;
private String companyId;
private String name;
public Person(int id, String companyId, String name) {
this.id = id;
this.companyId = companyId;
this.name = name;
}
public int getId() {
return id;
}
}
static class PersonKey {
private int id;
@AffinityKeyMapped
private String companyId;
public PersonKey(int id, String companyId) {
this.id = id;
this.companyId = companyId;
}
}
static class Company {
private String id;
private String name;
public Company(String id, String name) {
this.id = id;
this.name = name;
}
public String getId() {
return id;
}
}
public void configureAffinityKeyWithAnnotation() {
CacheConfiguration<PersonKey, Person> personCfg = new CacheConfiguration<PersonKey, Person>("persons");
personCfg.setBackups(1);
CacheConfiguration<String, Company> companyCfg = new CacheConfiguration<>("companies");
companyCfg.setBackups(1);
try (Ignite ignite = Ignition.start()) {
IgniteCache<PersonKey, Person> personCache = ignite.getOrCreateCache(personCfg);
IgniteCache<String, Company> companyCache = ignite.getOrCreateCache(companyCfg);
Company c1 = new Company("company1", "My company");
Person p1 = new Person(1, c1.getId(), "John");
// Both the p1 and c1 objects will be cached on the same node
personCache.put(new PersonKey(p1.getId(), c1.getId()), p1);
companyCache.put("company1", c1);
// Get the person object
p1 = personCache.get(new PersonKey(1, "company1"));
}
}
}
也可以使用CacheKeyConfiguration类在缓存配置中配置关联键:
- Java
- C#/.NET
public void configureAffinityKeyWithCacheKeyConfiguration() {
CacheConfiguration<PersonKey, Person> personCfg = new CacheConfiguration<PersonKey, Person>("persons");
personCfg.setBackups(1);
// Configure the affinity key
personCfg.setKeyConfiguration(new CacheKeyConfiguration("Person", "companyId"));
CacheConfiguration<String, Company> companyCfg = new CacheConfiguration<String, Company>("companies");
companyCfg.setBackups(1);
Ignite ignite = Ignition.start();
IgniteCache<PersonKey, Person> personCache = ignite.getOrCreateCache(personCfg);
IgniteCache<String, Company> companyCache = ignite.getOrCreateCache(companyCfg);
Company c1 = new Company("company1", "My company");
Person p1 = new Person(1, c1.getId(), "John");
// Both the p1 and c1 objects will be cached on the same node
personCache.put(new PersonKey(1, c1.getId()), p1);
companyCache.put(c1.getId(), c1);
// Get the person object
p1 = personCache.get(new PersonKey(1, "company1"));
}
除了自定义键类,还可以使用AffinityKey类,其是专门为使用自定义关联映射设计的。
- Java
- C#/.NET
public void configureAffinitKeyWithAffinityKeyClass() {
CacheConfiguration<AffinityKey<Integer>, Person> personCfg = new CacheConfiguration<AffinityKey<Integer>, Person>(
"persons");
personCfg.setBackups(1);
CacheConfiguration<String, Company> companyCfg = new CacheConfiguration<String, Company>("companies");
companyCfg.setBackups(1);
Ignite ignite = Ignition.start();
IgniteCache<AffinityKey<Integer>, Person> personCache = ignite.getOrCreateCache(personCfg);
IgniteCache<String, Company> companyCache = ignite.getOrCreateCache(companyCfg);
Company c1 = new Company("company1", "My company");
Person p1 = new Person(1, c1.getId(), "John");
// Both the p1 and c1 objects will be cached on the same node
personCache.put(new AffinityKey<Integer>(p1.getId(), c1.getId()), p1);
companyCache.put(c1.getId(), c1);
// Get the person object
p1 = personCache.get(new AffinityKey(1, "company1"));
}
#4.二进制编组器
#4.1.基本概念
二进制对象是Ignite中表示数据序列化的组件,有如下优势:
- 它可以从对象的序列化形式中读取任意的属性,而不需要将该对象完整地反序列化,这个功能消除了将缓存的键和值类部署到服务端节点类路径的必要性;
- 它可以为同一个类型的对象增加和删除属性,给定的服务端节点不需要有模型类的定义,这个功能允许动态改变对象的结构,甚至允许多个客户端以共存的模式持有类定义的不同版本;
- 它可以根据类型名构造一个新的对象,不需要类定义,因此允许动态类型创建;
二进制对象只可以用于使用默认的二进制编组器时(即没有在配置中显式设置其它编组器)。
限制
BinaryObject格式实现也带来了若干个限制:
- 在内部Ignite不会写属性以及类型的名字,而是使用一个小写的名字哈希来标示一个属性或者类型,这意味着属性或者类型不能有同样的名字哈希。即使序列化不会在哈希冲突时立即生效,但Ignite在配置级别提供了一种方法来解决此冲突;
- 同样的原因,
BinaryObject格式在类的不同层次上也不允许有同样的属性名; - 如果类实现了
Externalizable接口,Ignite会使用OptimizedMarshaller,OptimizedMarshaller会使用writeExternal()和readExternal()来进行类对象的序列化和反序列化,这需要将实现Externalizable的类加入服务端节点的类路径中。
二进制对象的入口是IgniteBinary,可以从Ignite实例获得,包含了操作二进制对象的所有必要的方法。
自动化哈希值计算和Equals实现
BinaryObject格式实现隐含了一些限制:
如果对象可以被序列化到二进制形式,那么Ignite会在序列化期间计算它的哈希值并且将其写入最终的二进制数组。另外,Ignite还为二进制对象的比较提供了equals方法的自定义实现。这意味着不需要为在Ignite中使用自定义键和值覆写GetHashCode和Equals方法,除非它们无法序列化成二进制形式。比如,Externalizable类型的对象无法被序列化成二进制形式,这时就需要自行实现hashCode和equals方法,具体可以看上面的限制章节。
#4.2.配置二进制对象
在绝大多数情况下不需要额外地配置二进制对象。
但是,如果需要覆写默认的类型和属性ID计算或者加入BinarySerializer,可以为IgniteConfiguration定义一个BinaryConfiguration对象,这个对象除了为每个类型指定映射以及序列化器之外还可以指定一个全局的名字映射、一个全局ID映射以及一个全局的二进制序列化器。对于每个类型的配置,通配符也是支持的,这时提供的配置会适用于匹配类型名称模板的所有类型。
<bean id="ignite.cfg" class="org.apache.ignite.configuration.IgniteConfiguration">
<property name="binaryConfiguration">
<bean class="org.apache.ignite.configuration.BinaryConfiguration">
<property name="nameMapper" ref="globalNameMapper"/>
<property name="idMapper" ref="globalIdMapper"/>
<property name="typeConfigurations">
<list>
<bean class="org.apache.ignite.binary.BinaryTypeConfiguration">
<property name="typeName" value="org.apache.ignite.examples.*"/>
<property name="serializer" ref="exampleSerializer"/>
</bean>
</list>
</property>
</bean>
</property>
</bean>
#4.3.BinaryObject API
Ignite默认使用反序列化值作为最常见的使用场景,要启用BinaryObject处理,需要获得一个IgniteCache的实例然后使用withKeepBinary()方法。启用之后,如果可能,这个标志就会确保从缓存返回的对象都是BinaryObject格式的。将值传递给EntryProcessor和CacheInterceptor也是同样的处理。
平台类型
注意当通过withKeepBinary()方法启用BinaryObject处理时并不是所有的对象都会表示为BinaryObject,会有一系列的平台类型,包括基本类型、String、UUID、Date、Timestamp、BigDecimal、Collections、Maps和这些类型的数组,它们不会被表示为BinaryObject。
注意在下面的示例中,键类型为Integer,它不会被修改,因为它是平台类型。
// Create a regular Person object and put it to the cache.
Person person = buildPerson(personId);
ignite.cache("myCache").put(personId, person);
// Get an instance of binary-enabled cache.
IgniteCache<Integer, BinaryObject> binaryCache = ignite.cache("myCache").withKeepBinary();
// Get the above person object in the BinaryObject format.
BinaryObject binaryPerson = binaryCache.get(personId);
#4.4.使用BinaryObjectBuilder修改二进制对象
BinaryObject实例是不可变的,要更新属性或者创建新的BinaryObject,必须使用BinaryObjectBuilder的实例。
BinaryObjectBuilder的实例可以通过IgniteBinary入口获得。它可以使用类型名创建,这时返回的对象不包含任何属性,或者它也可以通过一个已有的BinaryObject创建,这时返回的对象会包含从该BinaryObject中拷贝的所有属性。
获取BinaryObjectBuilder实例的另外一个方式是调用已有BinaryObject实例的toBuilder()方法,这种方式创建的对象也会从BinaryObject中拷贝所有的数据。
限制
- 无法修改已有字段的类型;
- 无法变更枚举值的顺序,也无法在枚举值列表的开始或者中部添加新的常量,但是可以在列表的末尾添加新的常量。
下面是一个使用BinaryObjectAPI来处理服务端节点的数据而不需要将程序部署到服务端以及不需要实际的数据反序列化的示例:
// The EntryProcessor is to be executed for this key.
int key = 101;
cache.<Integer, BinaryObject>withKeepBinary().invoke(
key, new CacheEntryProcessor<Integer, BinaryObject, Object>() {
public Object process(MutableEntry<Integer, BinaryObject> entry,
Object... objects) throws EntryProcessorException {
// Create builder from the old value.
BinaryObjectBuilder bldr = entry.getValue().toBuilder();
//Update the field in the builder.
bldr.setField("name", "Ignite");
// Set new value to the entry.
entry.setValue(bldr.build());
return null;
}
});
#4.5.BinaryObject类型元数据
如前所述,二进制对象结构可以在运行时进行修改,因此获取一个存储在缓存中的一个特定类型的信息也可能是有用的,比如属性名、属性类型名,关联属性名,Ignite通过BinaryType接口满足这样的需求。
这个接口还引入了一个属性getter的更快的版本,叫做BinaryField。这个概念类似于Java的反射,可以缓存BinaryField实例中读取的属性的特定信息,如果从一个很大的二进制对象集合中读取同一个属性就会很有用。
Collection<BinaryObject> persons = getPersons();
BinaryField salary = null;
double total = 0;
int cnt = 0;
for (BinaryObject person : persons) {
if (salary == null)
salary = person.type().field("salary");
total += salary.value(person);
cnt++;
}
double avg = total / cnt;
#4.6.BinaryObject和CacheStore
在缓存API上调用withKeepBinary()方法对于将用户对象传入CacheStore的方式不起作用,这么做是故意的,因为大多数情况下单个CacheStore实现要么使用反序列化类,要么使用BinaryObject表示。要控制对象传入CacheStore的方式,需要使用CacheConfiguration的storeKeepBinary标志,当该标志设置为false时,会将反序列化值传入CacheStore,否则会使用BinaryObject表示。
下面是一个使用BinaryObject的CacheStore的伪代码示例:
public class CacheExampleBinaryStore extends CacheStoreAdapter<Integer, BinaryObject> {
@IgniteInstanceResource
private Ignite ignite;
/** {@inheritDoc} */
@Override public BinaryObject load(Integer key) {
IgniteBinary binary = ignite.binary();
List<?> rs = loadRow(key);
BinaryObjectBuilder bldr = binary.builder("Person");
for (int i = 0; i < rs.size(); i++)
bldr.setField(name(i), rs.get(i));
return bldr.build();
}
/** {@inheritDoc} */
@Override public void write(Cache.Entry<? extends Integer, ? extends BinaryObject> entry) {
BinaryObject obj = entry.getValue();
BinaryType type = obj.type();
Collection<String> fields = type.fieldNames();
List<Object> row = new ArrayList<>(fields.size());
for (String fieldName : fields)
row.add(obj.field(fieldName));
saveRow(entry.getKey(), row);
}
}
#4.7.二进制Name映射器和二进制ID映射器
在内部,为了性能Ignite不会写属性或者类型名字的完整字符串,而是为类型和属性名写一个整型哈希值。经过测试,在类型相同时,属性名或者类型名的哈希值冲突实际上是不存在的,为了性能使用哈希值是安全的。对于当不同的类型或者属性确实冲突的场合,BinaryNameMapper和BinaryIdMapper可以为该类型或者属性名覆写自动生成的哈希值。
BinaryNameMapper:映射类型/类和属性名到不同的名字;
BinaryIdMapper:映射从BinaryNameMapper来的类型和属性名到ID,以便于Ignite内部使用。
Ignite直接支持如下的映射器实现:
BinaryBasicNameMapper:BinaryNameMapper的一个基本实现,对于一个给定的类,根据使用的setSimpleName(boolean useSimpleName)属性值,会返回一个完整或者简单的名字;BinaryBasicIdMapper:BinaryIdMapper的一个基本实现,它有一个lowerCase配置属性,如果属性设置为false,那么会返回一个给定类型或者属性名的哈希值,如果设置为true,会返回一个给定类型或者属性名的小写形式的哈希值。
如果仅仅使用Java或者.NET客户端并且在BinaryConfiguration中没有指定映射器,那么Ignite会使用BinaryBasicNameMapper并且simpleName属性会被设置为false,使用BinaryBasicIdMapper并且lowerCase属性会被设置为true。
如果使用了C++客户端并且在BinaryConfiguration中没有指定映射器,那么Ignite会使用BinaryBasicNameMapper并且simpleName属性会被设置为true,使用BinaryBasicIdMapper并且lowerCase属性会被设置为true。
如果使用Java、.Net或者C++,默认是不需要任何配置的,只有当需要平台协同、名字转换复杂的情况下,才需要配置映射器
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!