Qlib从入门到精通
前面谈到了简单的一个示例代码,实际上里面的策略源码和模型回测源码都需要好好了解,他这个回测系统和我之前用到的回测策略代码有不一样的地方,作为一个量化策略攻城狮,掌握源码是基本的技能。
Qlib内置了A股、美股两个市场的历史数据,上一篇文章也谈到过,可以通过运行如下的脚本把数据自动获取到本地。
# get 1d data
python -m qlib.run.get_data qlib_data --target_dir ~/.qlib/qlib_data/cn_data --region cn
# get 1min data
python -m qlib.run.get_data qlib_data --target_dir ~/.qlib/qlib_data/cn_data_1min --region cn --interval 1min而且支持从yahoo finance对数据进行日更,使用的脚本在scripts/data_collector。
但我们希望使用ETF做投资,那么就需要自己来扩展数据源。Qlib提供了相应的工具scripts/dump_bin.py
dump_bin是把csv格式的数据转换为qlib的格式,这样qlib就可以使用。
#注意要修改成自己的路径
python scripts/dump_bin.py dump_all --csv_path ?~/.qlib/csv_data/my_data --qlib_dir ~/.qlib/qlib_data/my_data --include_fields open,close,high,low,volume,factor
#--csv_path指定本地路径上csv目录
#--qlib_dir是qlib的数据目录
#--include_fields 包含的字段,OHLCV 好理解,就是常规的价量数据,factor是复权因子,通常factor = adjusted_price / original_priceQlib内置的数据采集里,已经支持了采集基金数据,是网上收集公募基金的数据,由于我们量化仅需要ETF的数据,所以可以从三方下载对应数据(简单写了一个脚本拉取基金数据的历史数据):
import akshare as ak
fund_inner = ak.fund_exchange_rank_em()
for i in range(len(fund_inner['基金代码'])):
fund_hist = ak.fund_etf_hist_em(symbol=fund_inner['基金代码'][i], period="daily", start_date=fund_inner['成立日期'][i], end_date="20231231", adjust="hfq")
fund_hist.rename(columns={'日期':'date','开盘':'open','收盘':'close','最高':'high','最低':'low','成交量':'volume'}, inplace=True)
name = 'C:/Users/59980/funddata/'+ fund_inner['基金代码'][i] + '.csv'
fund_hist.to_csv(name,index = False)然后使用前面提及的dump_bin工具,可以把这个csv目录转为qlib可以使用的数据存储格式。
python C:\Users\59980\qlib\scripts\dump_bin.py dump_all --csv_path C:\Users\59980\funddata --qlib_dir ~/.qlib/qlib_data/fund_data --date_field_name date --include_fields open,close,high,low,vol
需要注意的点:bin转换默认需要一个date字段,如果csv里的字段名称不一样,可以使用—date_field_name来指定。Include_fields是默认要处理的字段,比如你的csv里有PE,PB可以在这里指定。运行之后的结果为:
?数据的加载与使用按照下面方式操作:
在qlib.qlib子文件夹下创建一个文件(如fundceshi.py),内容如下:
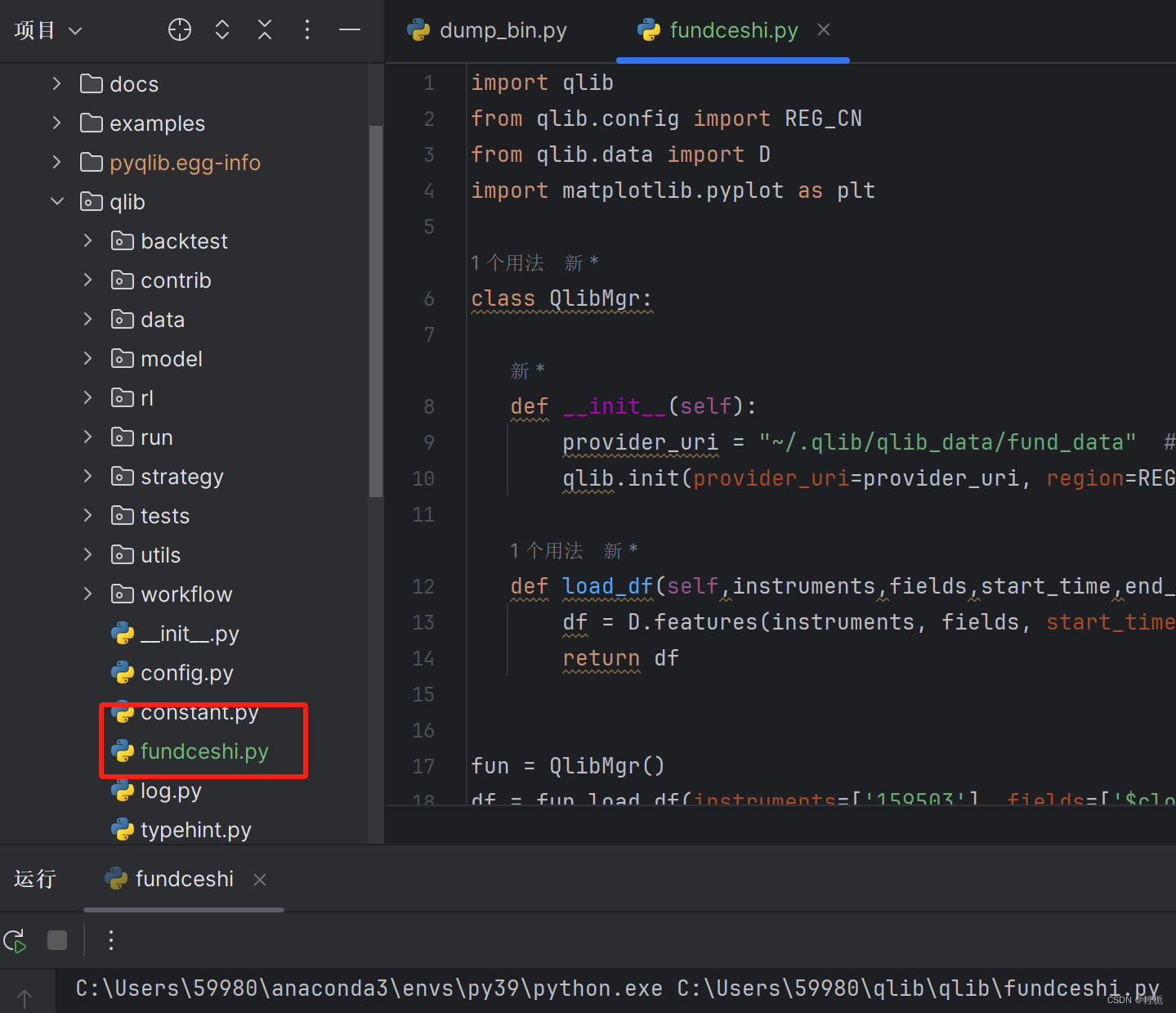
import qlib
from qlib.config import REG_CN
from qlib.data import D
import matplotlib.pyplot as plt
class QlibMgr:
#初始化要加载数据的目录
def __init__(self):
provider_uri = "~/.qlib/qlib_data/fund_data" # target_dir
qlib.init(provider_uri=provider_uri, region=REG_CN)
#加载数据
def load_df(self,instruments,fields,start_time,end_time):
df = D.features(instruments, fields, start_time=start_time,end_time=end_time, freq='day')
return df
#实例化,这里要确认好起止日期内对应的基金有数据,后面其他股票也可按照这种方式加载进qlib平台进行回测
fun = QlibMgr()
df = fun.load_df(instruments=['159503'], fields=['$close'], start_time='2023-07-01', end_time='2023-12-31')
# print(df.columns)
# print(df.index)
# print(df.head(3))
se = df.loc['159503']['$close']
se.plot()
plt.show()
运行后得到的结果为:
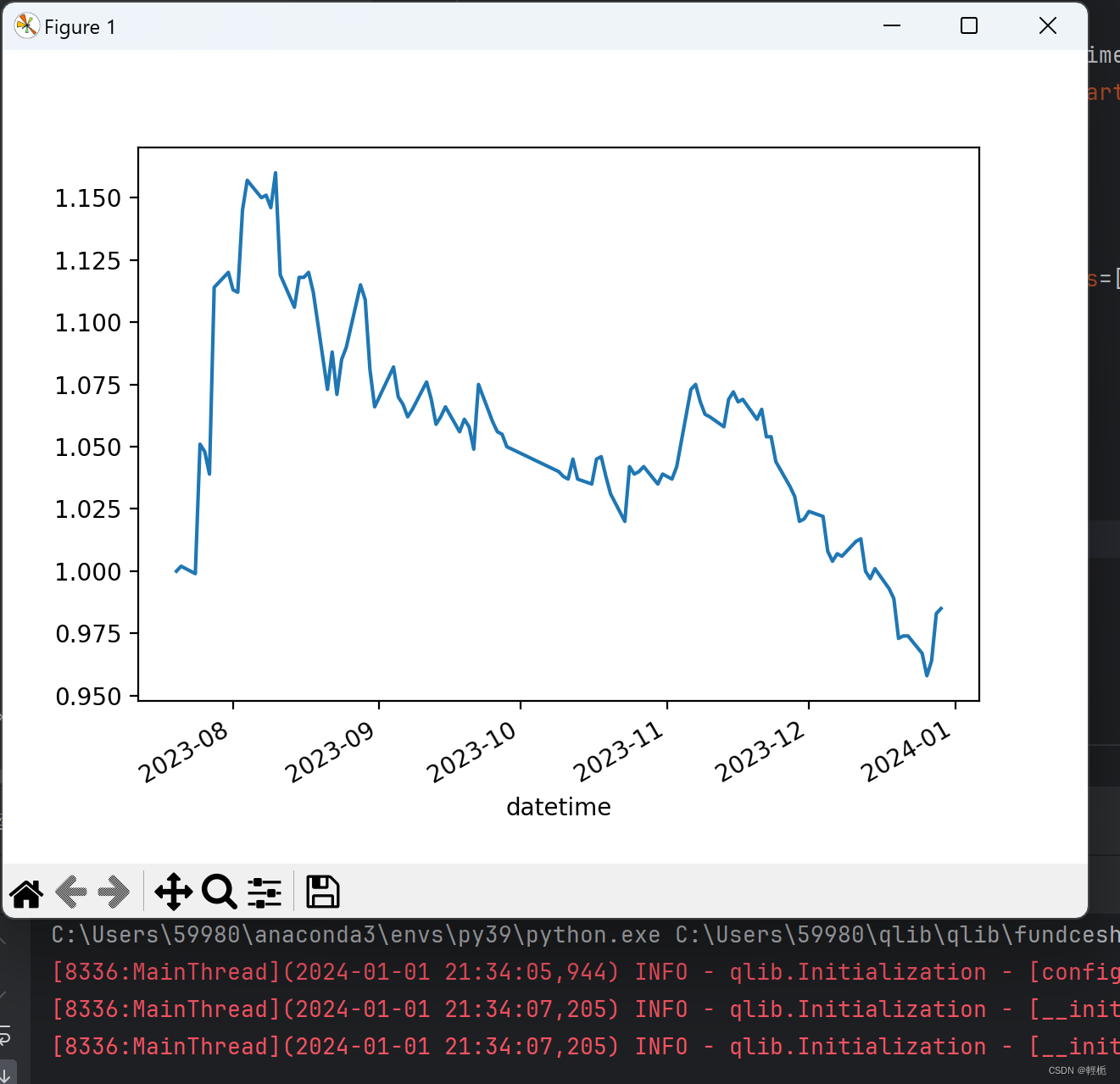
后面对数据的使用,计算指标,可视化都可以按照自己的意愿展开。Qlib是一个设计完整但松耦合的框架,这一点非常好。比如一个常见的回测框架Backtrader,你要扩展自己的东西,非常难。
学会将数据加载进qlib后,接下来使用Qlib进行数据标注与自定义指标计算。
数据标注:我们已经加载的OHLCV数据,并进行了时间序列相关分析,要从价量数据里进一步计算特征,传统技术分析指标,如均线、MACD,RSI,布林带都是衍生指标,也是特征之一。传统量化系统,需要自己写指标公式或者借助Talib这样的工具包。这对于传统技术分析,指标比较少,通常就2-3个是比较容易实现和管理的。但对于机器学习,我们可以同步计算上百个特征,那么如果有这种方式就难以管理了。
Qlib内置了表达式引擎,可以通过'$high-$low',这样的表达式来计算衍生指标。更复杂的指标,比如计算MACD:
MACD_EXP = '(EMA($close,12) - EMA($close,26))/$close - EMA((EMA($close,12) - EMA($close,26))/$close,9)/$close'$close是取dataframe里已有的字段,EMA是表达式引擎内置的函数。Qlib的表达式引擎里预置了很多常用的,时间序列计算的有效函数。
from qlib.data.dataset.loader import QlibDataLoaderQlibDataloader比D.features更高层的API,用法类似,定义fields就是原始字段及衍生的表达式,而且可以定义labels。
Label是机器学习的标签,Ref($close,-2)是T+2的收盘价,这里使用的label是T+2天的收益率,也就是未来2天的收益率——这是考虑A股市场T+1的机制,在T+1天买入,T+2天卖出。
?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!