(2023|CVPR,Custom Diffusion,概念微调,正则化数据集)文本到图像扩散的多概念定制
Multi-Concept Customization of Text-to-Image Diffusion
公和众和号:EDPJ(添加 VX:CV_EDPJ 或直接进 Q 交流群:922230617 获取资料)
目录
0. 摘要
生成模型能够生成从大规模数据库中学到的高质量概念的图像,但用户通常希望合成属于他们自己概念的实例(例如,家庭、宠物或物品)。我们是否能够教导一个模型快速学习新概念,只需提供一些示例?此外,我们是否能够将多个新概念组合在一起? 我们提出了自定义扩散(Custom Diffusion),这是一种用于增强现有文本到图像模型的高效方法。我们发现,仅优化文本到图像条件机制中的少数参数就足够强大,可以表示新概念,并实现快速调整(约 6 分钟)。此外,我们可以通过封闭形式的约束优化同时训练多个概念,或将多个经过微调的模型合并成一个模型。我们的微调模型生成多个新概念的变体,并在新颖的环境中将它们无缝地与现有概念组合。我们的方法在定性和定量评估中优于或与几个基线和同时进行的研究相当,同时具有内存和计算效率。

3. 方法
我们提出的微调模型的方法如图 2 所示,仅更新模型的交叉注意层中的一小部分权重。此外,我们使用一组真实图像作为正则化集,以防止在目标概念的少量训练样本上过拟合。在这一部分中,我们详细解释了我们的设计选择和最终算法。
3.1 单概念微调
给定一个预训练的文本到图像扩散模型,我们的目标是在模型中嵌入一个新概念,只给出四张图像和相应的文本描述。微调后的模型应该保留其先前的知识,允许基于文本提示进行新颖的生成。这可能具有挑战性,因为更新后的文本到图像映射可能会过拟合仅有的几张可用图像。
在我们的实验中,我们使用 Stable Diffusion [2] 作为我们的基础模型,该模型建立在 Latent Diffusion Model (LDM) [63] 的基础上。LDM 首先使用 VAE [36]、Patch-GAN [32] 和 LPIPS [88] 的混合目标将图像编码为潜在表示,以便通过运行编码器解码器可以恢复输入图像。然后,他们使用交叉注意将文本条件注入模型,用潜在表示对扩散模型 [29] 进行训练。
扩散模型的学习目标。扩散模型 [29, 71] 是一类旨在用 p_θ(x_0) 近似原始数据分布 q(x_0) 的生成模型:
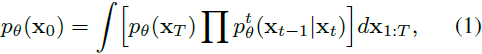
其中 x_1 到 x_T 是正向马尔可夫链的潜在变量,满足
![]()
该模型被训练来学习一个固定长度(通常为1000)的马尔可夫链的反向过程。给定时间步 t 的嘈杂图像 x_t,模型学习去噪输入图像以获得 x_(t?1)。扩散模型的训练目标可以简化为:?
![]()
其中 ?_θ 是模型的预测,w_t 是一个依赖于时间的损失权重。该模型以时间步 t 为条件,并可以进一步以任何其他模态 c(例如文本)为条件。在推断过程中,使用模型 [72] 对固定时间步进行随机高斯图像(或潜在图像)x_T 进行去噪。
微调目标的一个朴素的基线是更新所有层以最小化给定文本-图像对的等式 2 中的损失。这对于大规模模型来说可能计算效率低,而在训练时使用少量图像容易导致过拟合。因此,我们的目标是确定一组足够完成微调任务的最小权重。?
权重变化的速率。根据 Li 等人 [41],我们分析了目标数据集上微调模型中每一层参数的变化,使用等式 2 中的损失,即:
![]()
其中 θ′_𝑙 和 θ_𝑙 分别是层 𝑙 的更新和预训练模型参数。这些参数来自三种类型的层——(1) 交叉注意力(文本和图像之间),(2) 自注意力(图像内部),以及 (3) 其余参数,包括扩散模型 U-Net 中的卷积块和归一化层。图 3 显示了在 “moongate” 图像上微调模型时三个类别的平均 Δ_𝑙。我们观察到在其他数据集中也有类似的图表。正如我们所见,与其他参数相比,交叉注意力层的参数 Δ相对较高。而且,交叉注意层只占模型中总参数的 5%。这表明在微调过程中它起着重要作用,我们在我们的方法中利用了这一点。

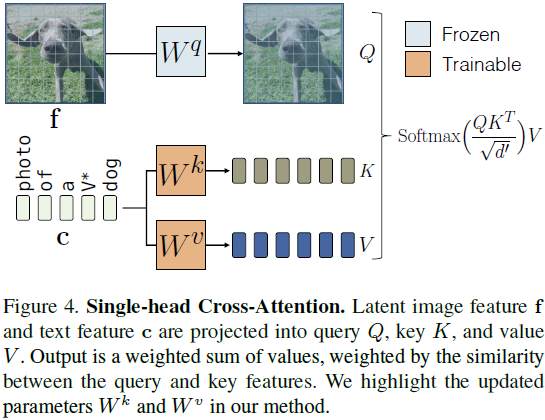
模型微调。交叉注意块根据条件特征(即,在文本到图像扩散模型的情况下的文本特征)修改网络的潜在特征。给定文本特征 c ∈ R^(s×d) 和潜在图像特征 f ∈ R^((h×w)×l),单头交叉注意力 [76] 操作包括
![]()
以及对值特征的加权和:

其中 W^q、W^k 和 W^v 分别将输入映射到查询、key 和值特征,d′ 是 key 和查询特征的输出维度。然后,潜在特征通过注意块输出进行更新。微调的任务旨在更新从给定文本到图像分布的映射,而文本特征仅作为交叉注意块中 W^k 和 W^v 投影矩阵的输入。因此,我们建议在微调过程中仅更新扩散模型的 W^k 和 W^v 参数。正如我们在实验中所示,这足以使用新的文本-图像配对概念更新模型。图 4 显示了交叉注意层和可训练参数的一个实例。
文本编码。给定目标概念图像,我们需要一个文本标题。如果存在文本描述,例如 moongate,我们将其用作文本标题。对于与个性化相关的用例,其中目标概念是通用类别的唯一实例,例如宠物狗,我们引入一个新的修饰符标记嵌入,即 V* dog。在训练过程中,V* 以稀有的标记嵌入进行初始化,并与交叉注意参数一起进行优化。在训练期间使用的一个示例文本标题是 “一只 V* 狗的照片”。

正则化数据集。在目标概念和文本标题对上进行微调可能会导致语言漂移(language drift)的问题 [39, 46]。例如,在 “moongate” 上的训练将导致模型忘记 “moon” 和 “gate” 与其先前训练的视觉概念的关联,如图 5 所示。类似地,在 V* 乌龟毛绒(tortoise plushy) 的个性化概念上进行训练可能会泄漏,导致所有带有毛绒的示例产生特定的目标图像。为了防止这种情况,我们从 LAION-400M [69] 数据集中选择了一组具有与目标文本提示高相似度的 200 个正则化图像,其在 CLIP [57] 文本编码器特征空间中相似度高于门限 0.85。

3.2 多概念组合微调
多概念联合训练。对于多概念的微调,我们将每个单独概念的训练数据集组合起来,与我们的方法一起进行联合训练。为了表示目标概念,我们使用不同的修饰符标记,V*_i,用不同的稀有标记初始化,并与每个层交叉注意力的 key 和值矩阵一起进行优化。如图 7 所示,将权重更新限制为交叉注意力 key 和值参数相比于像 DreamBooth 这样微调所有权重的方法,对于组合两个概念会产生显着更好的结果。
受限制的优化以合并概念。由于我们的方法只更新与文本特征对应的 key 和值投影矩阵,我们随后可以将它们合并以允许生成具有多个微调概念的图像。令
![]()
表示预训练模型中所有 L 个交叉注意力层的 key 和值矩阵
![]()
表示对应于添加的概念 n ∈ {1 · · ·N} 的更新矩阵。由于我们随后的优化适用于所有层和 key 和值矩阵,为了符号清晰起见,我们将省略上标 {k, v} 和层 𝑙。我们将组合目标制定为以下约束最小二乘问题:?

这里,C ∈ R^(s×d) 是维度为 d 的文本特征。这些特征由所有 N 个概念中的 s 个目标词组成,每个概念的所有标题都被展平并连接在一起。类似地,C_reg ∈ R^((s_reg)×d) 包括用于正则化的~1000 个随机抽样标题的文本特征。直观地说,上述公式旨在更新原始模型中的矩阵,使得 C 中目标标题中的单词一致地映射到来自微调概念矩阵的值。假设 C_reg 是非退化的且解存在,上述目标可以通过使用拉格朗日乘子法 [9] 在封闭形式下求解:

我们在附录 B 中展示了完整的推导过程。与联合训练相比,如果每个单独的微调模型存在,我们的基于优化的方法更快(~2 秒)。我们提出的方法导致在单个场景中一致生成两个新概念,如 4.2 节所示。
训练细节。我们使用我们的方法进行单概念训练 250 步,在两个概念的联合训练中进行 500 步,批大小为 8,学习率为 8 × 10^(?5)。在训练过程中,我们还随机调整目标图像的大小,范围从 0.4到 1.4 倍,并根据调整比例相应地附加提示 “非常小”、“远离” 或 “放大”、“特写” 到文本提示中。我们仅在有效区域上反向传播损失。这导致更快的收敛和改进的结果。我们在附录 E 中提供更多训练细节。
4. 实验


我们的方法在定量评估(CLIP 文本对齐和图像对齐)和人类评估中表现良好。?
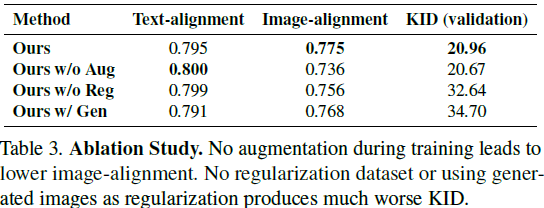
消融研究:完整模型与没有数据增强、没有检索的真实数据作为正则化、使用生成数据作为正则化的对比。?


5. 局限性
如图 11 所示,复杂的组合,例如宠物狗和宠物猫,仍然具有挑战性。在这种情况下,预训练模型也面临类似的困难,而我们的模型继承了这些局限性。此外,将三个或更多概念组合在一起也是具有挑战性的。我们在附录 C 中展示了更多的分析和可视化。
S. 总结
S.1 主要贡献
本文提出了自定义扩散(Custom Diffusion),仅优化少数参数就能表示新概念,并实现快速调整。此外,可通过封闭形式的约束优化同时训练多个概念,或将多个经过微调的模型合并成一个模型。微调模型可生成多个新概念的变体,并在新颖的环境中将它们无缝地与现有概念组合。
S.2 方法
单概念微调。
- 本文分析了数据集上微调模型中每一层参数(这些参数来自三种类型的层:交叉注意力(文本和图像之间)、自注意力(图像内部),以及其余参数,包括扩散模型 U-Net 中的卷积块和归一化层)的变化,发现交叉注意力层的参数变化相对较高,在微调过程中它起着重要作用。
- 此外,文本特征仅作为交叉注意块中的 key 和值矩阵的输入。
- 基于此, 为提高计算效率,可仅对交叉注意块中的 key 和值矩阵进行微调。
个性化:为实现个性化生成,引入一个新的修饰符标记嵌入,即 V*。在训练过程中,V* 以稀有的标记嵌入进行初始化,并与交叉注意参数一起进行优化。
正则化数据集:
- 在目标概念和文本标题对上进行微调可能会导致语言漂移(language drift)的问题。
- 为解决这个问题,在数据集中选择了一组具有与目标文本提示高相似度的 200 个正则化图像,其在 CLIP 文本编码器特征空间中相似度高于门限 0.85。
多概念组合微调:为了表示目标概念,使用不同的修饰符标记,V*_i,用不同的稀有标记初始化,并与每个层交叉注意力的 key 和值矩阵一起进行优化。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!