Kudu-架构与设计
一、背景
1.存储组件
大数据存储层主要是由HDFS和HBase两个组件支持。HDFS适用于高吞吐量的离线大数据分析场景,不支持随机的读写。HBase适用于大数据随机读写场景,批量读取吞吐量不如HDFS,不适合批量数据分析场景。
2.使用场景
现实中可以根据应用场景选择使用的存储组件。但是如果既需要大数据随机读写,又需要批量数据分析场景,因为没有单一组件满足此类业务要求。因此需要将HBase和HDFS来组合满足此类需求,也就是数据实时写入和更新到HBase,定时(通常T+1)将HBase数据导出到HDFS用于做分析。
3.多组件组合缺点
通过HBase和HDFS组合虽然满足了随机读写和OLAP分析场景,但是有以下缺点:
3.1 架构复杂
需要HBase和HDFS两个组件,并且涉及到数据在两个组件之间的流转,数据一致性和运维成本高。每个环节都需要保证高可用性,数据在两个组件都需要维护多副本,存储空间有一定浪费。
3.2 时效性低
数据写入到HBase后,需要等待一个周期后才能进入HDFS进行OLAP操作,因此时效性低。
3.3 应对数据更新
如果已经导入到HDFS数据后,又在HBase中进行了更新,这个针对数据的更新在HDFS中比较难以处理。一个方案就是将所有数据重新导出到HDFS,但是代价过高。
二、Kudu概述
Apache Kudu是由Cloudera开源的存储引擎,是一个满足随机读写、又支持OLAP分析的大数据存储引擎,同时避免上述组合架构缺点。
1.设计特点
- 与MapReduce,Spark以及Hadoop生态系统中其他组件进行友好集成
- 可与ClouderaImpala集成,替代目前Impala常用的HDFS+Parquet组合
- 灵活的一致性模型
- 顺序写和随机写并存的场景下,仍能达到良好的性能
- 高可用,使用Raft协议保证数据高可靠存储
- 结构化数据模型
2.框架适用场景
- 实时数据更新
- 时间序列相关的应用,海量历史数据查询,必须非常快地返回关于单个实体的细粒度查询。
- 实时预测模型的应用
3.框架不适用场景
只追求随机读写或者OLAP分析的场景,或者对OLAP分析容忍一定的延迟。
三、数据模型与存储
kudu表是列式存储,其中表是有结构表与关系型数据库类似。表中必须有一个唯一不重复主键。
kudu表根据hash或者range拆分成多个tablet。与kafka的partition类似,tablet也是采用副本机制来保障可靠性,由一个tablet leader和多个tablet follower组成。
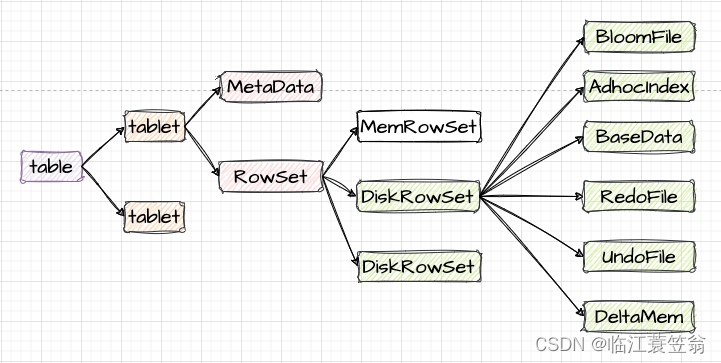
1.Table
kudu表是schema的、一个表有多行组成,每行有固定的列组成。列具有名称、数据类型、大小等。一行有一个唯一的铸剑列。
2.Tablet
一个表会按照Hash或者range分成多个tablet,每个tablet包含元数据MetaData和数据存储RowSet。tablet是调度和负责均衡的基本单位,表的tablet会有多个副本分布到多个TabletServer上,其中一个为tablet leader负责读和写操作,其他为tablet follower只负责读操作。
3.MetaData
MetaData文件记录的是DiskRowSet的元信息,主要包括哪些block及block在data中的位置。
4.RowSet
RowSet是进行数据存储的单元,包括一个MemRowSet和零到多个DiskRowSet。MemRowSet存储新增数据,当MemRowSet写满后会flush到磁盘生成一个或多个DiskRowSet。
5.MemRowSet
MemRowSet存储的是新增数据,数据采用行存储、基于Primary key有序。默认写满1G或者120s会刷新到磁盘DiskRowSet中。
6.DiskRowSet
DiskRowSet采用列存储并且是不可修改的,每个DiskRowSet又分为Base Data和Delta Stores。
6.1 Base Data
MemRowSet刷盘到DiskRowSet时,这时只包含Base Data,也就是保存的都是新增数据。
6.2 Delta Stores
如何对已经刷盘的数据进行修改和删除?每个DiskRowSet生成后,在内存中都会有一个DeltaMemStores负责记录此DiskRowSet数据的后续更新和删除操作。DeltaMemStores数据刷盘后会形成一个DeltaFile文件。
四、Kudu架构图
Kudu采用的是Master/Slave架构。Kudu由管理集群元数据的Master Server节点和负责数据存储的Tablet Server节点组成。为了高可用性两种节点都是多副本形式部署,采用Raft协议保证Master Server和Tablet Server数据的容错性和一致性。通过Rafe进行副本的leader选举,leader负责接受写请求并将数据写入到其他follower副本,一旦写入的数据在大多数副本中持久化后,就会向客户确认。
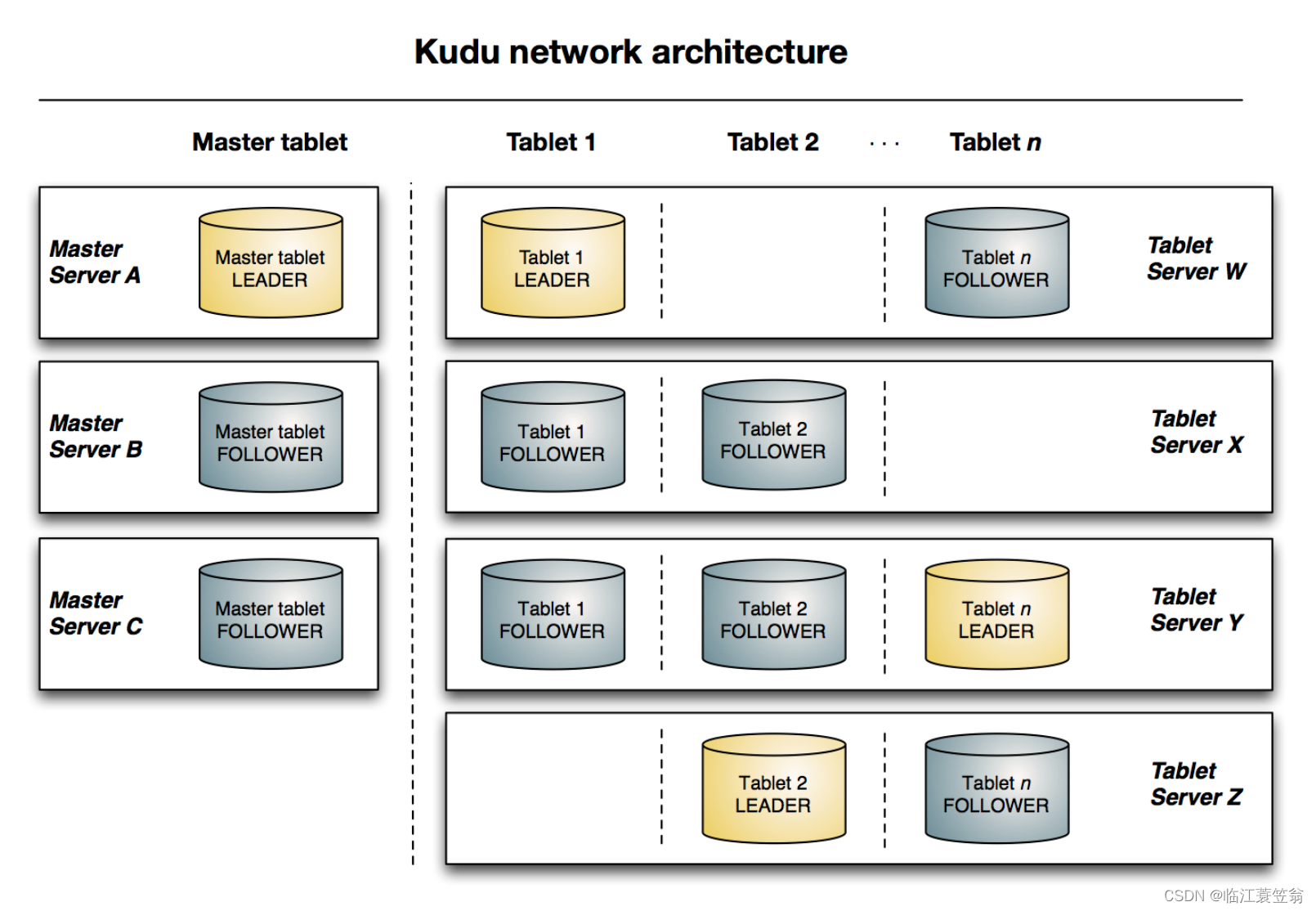
1.Master tablet
kudu的元数据表是使用一个tablet来进行管理和存储,为了与普通tablet区分,这个tablet称为Master tablet。为了保证可靠性所以基本都是一个leader和两个follower。每个Master tablet都由一个Master Server进行管理。
2.Master Server
Master Server负责管理和保存kudu元数据的tablet。实际部署中集群中会使用多个Master Server来保证可靠性,在系统运行期间同一时刻只能有一个Master Server中的Tablet是leader。
3.Tablet Server
Tablet Server负责管理和保存kudu中表多个tablet。实际部署中集群中会使用多个Tablet Server来保证可靠性,在系统运行期间同一时刻针对同一个tablet只能有一个是leader。由于tablet leader负责写服务,tablet leader和tablet follower负责读服务,因此为了负责均衡考虑,tablet的leader会均匀分布到Tablet Server节点。
五、数据新增流程
kudu新增数据需要根据主键先校验主键是否冲突,然后才会进行写入操作。
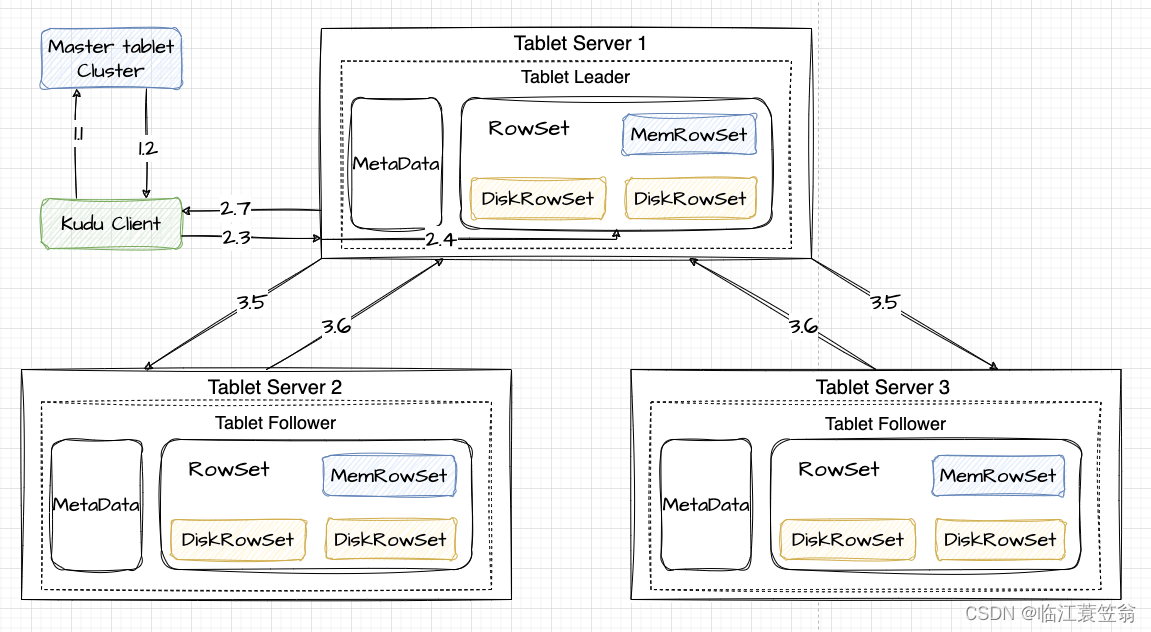
1.获取Tablet元数据
首先需要知道表的元数据,也就是要知道表的tablet信息,这个信息时维护在Master Tablet Cluster集群中。
1.1 client访问Master Tablet获取表相关信息
1.2 从Master Tablet节点返回表的分区信息和表的tablet信息
2.新增数据请求
从表的tablet信息,找到tablet leader所在的Tablet Server。
2.3 向tablet所在的Tablet Server发送写入请求
2.4 Tablet Server首先查找Tablet中的memRowSet和DiskRowSet是否有相同主键,如果没有则写入到MemRowSet,如果有则返回错误。
2.7 Tablet Server返回给Client告知写入成功
3.副本写入
kudu的存储和持久化不依赖外部组件,所以kudu采用多副本写入来解决可靠性问题。
3.5 Tablet leader通知Tablet follower进行信息的写入
3.6 Tablet follower将信息本地写入成功后,会告知Tablet leader,如果多数写入成功,则认为写入成功。
六、数据更新流程
kudu数据更新需要根据主键找到数据所在的DiskRowSet或者MemRowSet,然后将更新记录存入到对应的RowSet中。这样相同的主键数据和变更记录都是保存在同一个DiskRowSet,查询特定主键时不需要遍历所有DiskRowSet,提升了查询性能。
1.获取Tablet元数据
跟数据新增流程一致
2.数据更新请求
从表的tablet信息,找到tablet leader所在的Tablet Server。
2.3 向tablet所在的Tablet Server发送写入请求
2.4 Tablet Server首先待更新数据所在位置
- 位于MemRowSet
如果数据存在MemRowSet,会将更新操作记录在行中的一个mutation链表中。在刷新落盘时会更新合并到BaseData,并生成UNDO records用于查看历史版本的数据和MVCC,UNDO records实际上也是以DeltaFile的形式存放 - 位于DiskRowSet
找到待更新数据所在的DiskRowset,每个DiskRowset都会在内存中设置一个DeltaMemStore,将更新操作记录在DeltaMemStore中,在DeltaMemStore达到一定大小时,flush在磁盘,形成Delta并存在方DeltaFile中。
2.7 Tablet Server返回给Client告知写入成功
3.副本写入
跟数据新增流程一致
七、数据查询流程
kudu数据更新需要根据主键找到数据所在的DiskRowSet或者MemRowSet,然后将更新记录存入到对应的RowSet中。这样相同的主键数据和变更记录都是保存在同一个DiskRowSet,查询特定主键时不需要遍历所有DiskRowSet,提升了查询性能。
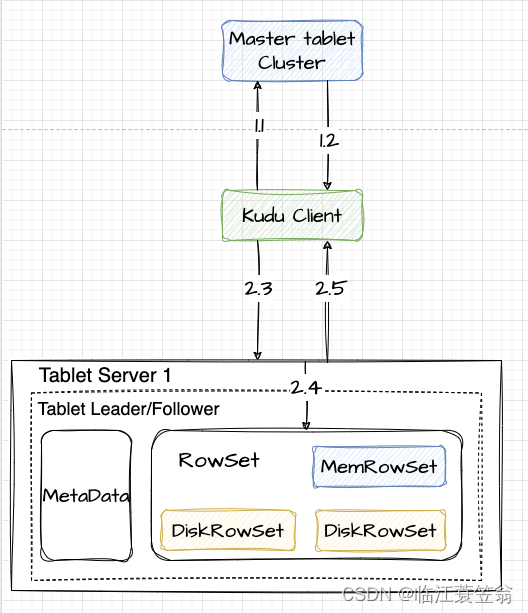
1.获取Tablet元数据
跟数据新增流程一致
2.数据更新请求
从表的tablet信息,找到tablet leader所在的Tablet Server。
2.3 向tablet所在的Tablet Server发送写入请求
2.4 Tablet Server首先查询数据所在位置
- 位于MemRowSet
根据读取操作中包含的timestamp信息将该timestamp前提交的更新操作合并到base data中,这个更新操作记录在该行数据对应的mutation链表中 - 位于DiskRowSet
在所有DeltaFile中找到所有目标数据相关的UNDO record和REDO records,REDO records可能位于多个DeltaFile中,根据读操作中包含的timestamp信息判断是否需要将base data进行回滚或者利用REDO records将base data进行合并更新。
2.5 Tablet Server返回给Client告知写入成功
八、持久化
1.MemRowSet刷盘
MemRowSet存储的是新增数据,当数据写满1G或者120s会刷盘一次,然后写入到一个或者多个DiskRowSet中。
2.DeltaMemStore刷盘
DeltaMemStore存储DisRowSet数据的更新和删除操作,当增长到一定大小的时候会刷盘一次,形成一个DeltaFile文件。
3.文件合并
由于以上刷盘机制,随着时间推移Kudu中小文件会越来越多,主要是DiskRowSet中的Base data和若干DeltaFile。为了提高性能,Kudu会定期进行合并,主要包含两部分:
3.1 DeltaFile合并
由于DeltaFile过多会影响读性能,所以会定期将DeltaFile合并回到Base data。
3.2 DiskRowSet合并
如果DiskRowSet过多也会影响性能,Kudu定期会将多个DiskRowSet进行合并以提升性能,合并时会将被删除的数据进行彻底删除并且减少了文件数量。
总结
Kudu是一个满足随机读写又满足大规模数据分析的大数据存储引擎,是HDFS和HBase两者性能的一个中和。一个引擎就可以满足之前需要HDFS和HBase两个组合的场景。架构采用极简模式没有引入其他组件,主要采用Raft进行协调,采用多副本保证可靠性。数据更新和修改时会在原有DiskRowSet中操作,并采用定期合并减少文件个数,提高读性能。
参考链接
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!