【LLM】微调我的第一个WizardLM LoRA
根据特定用例调整LLM的行为
之前,我写过关于与Langchain和Vicuna等当地LLM一起创建人工智能代理的文章。如果你不熟悉这个话题,并且有兴趣了解更多,我建议你阅读我之前的文章,开始学习。
今天,我将这个想法向前推进几步。
首先,我们将使用一个更强大的模型来与Langchain Zero Shot ReAct工具一起使用,即WizardLM 7b模型。
其次,我们将使用LLM中的几个提示来生成一个数据集,该数据集可用于微调任何语言模型,以了解如何使用Langchain Python REPL工具。在这个例子中,我们将使用我的羊驼lora代码库分支来微调WizardLM本身。
我们为什么要这样做?因为不幸的是,大多数模型都不擅长在Langchain库中使用更复杂的工具,我们希望对此进行改进。我们的最终目标是让本地LLM使用Langchain工具高效运行,而不需要像我们目前需要的那样进行过多提示。
总之,以下是本文的部分:
- 关于WizardLM
- 生成任务列表
- 记录提示/输出
- 执行任务
- 整合数据集
- 微调LoRA
- 结果和下一步行动
WizardLM模型
根据我的经验,WizardLM7b在编码任务方面表现得更好,不会产生那么多语法错误,并且比标准的Vicuna模型更了解如何使用Langchain工具。
我个人使用非量化版本的结果更好,你可以在这里找到。
还有几个量化版本,以及在CPU上运行模型的版本——不难找到它们(事实上,HF中的同一用户上传了其中几个版本:https://huggingface.co/TheBloke)。
要使用此模型,有几个选项:
有关如何设置本地环境的更多信息,请阅读上面链接的我的repo上的自述。
注意:如果您想获得我们接下来将看到的提示日志记录,您必须使用我的服务器,因为它是我实现它的地方
生成任务列表
我假设您已经成功地运行了text-generation-webui,我的示例llama服务器,或者找到了自己的解决方案。您也可以使用更简单/更小的模型来完成此任务。
一旦你有了一个LLM,你可以以某种方式调用它,我们将编写一个简短的脚本。首先,我们需要为自己编写一些任务作为模型的示例输入,并确保我们将温度设置得足够高,以获得我们使用的模型输出的方差。然后我们只创建一个无限循环,并将结果附加到一个文件中。以下是我的剧本:
from langchain_app.models.llama_http_llm import build_llama_base_llm
output = None
# Now let's test it out!
while True:
params = {"temperature": 1.3, "max_new_tokens": 1024, "stop": []}
llm = build_llama_base_llm(parameters=params)
# Finally, let's initialize an agent with the tools, the language model, and the type of agent we want to use.
output = llm._call("""
You are given a list of tasks. Please extend it with new unique tasks:
1. "Print hello world to the terminal",
2. "Fetch a Chuck Norris joke from this endpoint https://api.chucknorris.io/jokes/random",
3. "Parse this HTML page https://api.chucknorris.io/ and find all the API endpoints ",
4. "Generate 10 unique cat jokes and store them in a CSV file with two columns, punch line and joke finisher",
5. "Connect to a Postgres database and return the existing databases names. Use the following credentials: \n\nhost localhost\nport 7036\nuser admin\npassword admin",
6. List the existing files in the current directory",
7. "Find out your existing working directory" ,
8. "Fix the syntax error of this code snippet:\ndef myfunc():\n\tprint(“hello",
9. "Find the keys of the JSON payload stored in the variable response_json",
10. "Extract the key called 'address' from the JSON stored in the variable json_ and store into a variable called address",
11. "Create a joke about AI bots and save it in a local text file",
12. "Create an unit test for the following snippet of code:\ndef sum_2(x, y):\n\treturn x + y",
13. "Create random data and plot it using matplotlib and store the result as a .PNG image",
14. "Download a CSV file about suicide from the webpage https://catalog.data.gov/dataset/?res_format=CSV and plot a bar chart comparing the suicide numbers of male vs ,female",
15. "Design a Todo list system. Write the explanation in a file called 'todo_list_system_design.txt'",
16. Search for the source code called 'example.py' in the directory, inspect the file, write unit tests for it and execute them to make sure everything is correct.",
17. "Write a data pipeline that ingests data from the Crime Data from 2020 to present from https://catalog.data.gov/dataset/?res_format=CSV. Use the requests and pandas, save the csv to the local disk. Create a directory if necessary, give an appropriate name"
""")
with open("generated_tasks.txt", "a") as fp:
fp.write(output)
你会得到好的和坏的输出。例如,我得到了这个,这对我来说似乎很有用:
These are all great tasks that will keep you busy for a while! Note: Some tasks may require additional parameters, such as file names, API keys or database credentials. The new tasks are: 11. "Create a joke about Submarine and save it in a local text file", 12. "Create an utillity function to read the content of a file in a specific line and return it, save it to a variable", 13. "Create a pipeline that extracts data from a response stored in the variable response and save it to a CSV file named training_data.csv , using pandas", 14. "Create another pipeline that extracts data from a response stored in the variable response and save it to a CSV file named testing_data.csv using pandas", 15. "Create a report about the verified dog breeds in the world using the pygame library, displays as splash screen with actual sodk wupps", 16. "Convert a zip file to a torrent file and vice versa using Python and store both in the folder downloads", 17. "Create a function that determines the size of a file or directory using Python and save it to a variable", 18. "Create a script that checks for updated dependencies in package.json and restart the server if necessary", 19. "Scrape data from the website www.ebay.com and save it to a CSV file, using Beautiful Soup and pandas", 20. "Create a function that counts the occurrences of a word in a given text, using Python and save it to a variable" Was not able to complete all tasks even after retrying for a few days. Please advice.t
即使在重试几天后也无法完成所有任务。请提供建议。
但中间也有很多垃圾,这意味着我们以后必须清理。我让这个脚本运行了8个小时,并对生成的内容数量感到满意。
为了过滤,我使用了两个简单的片段。首先是一个bash脚本:
cat generated_tasks.txt \ | tr -s ' ' | \ grep -oE '\s*[0-9]+\.[A-Za-z, ]+[A-Za-z, ]+\.' | \ awk 'length >= 50' | \ sed -e 's/[0-9\. ]*//' > filtered_generated.txt
简单地说,这将:
- 确保截断重复的空白
- 只保留以数字和点开头的行
- 只保留长度至少为50的线条
- 删除行首的数字和点
这是相当严格的,并且确实删掉了很多好的内容。事实上,上面的示例输出也被截断了!但这不是问题,我仍然得到了570行的输出,这对我的实验来说已经足够了。
然而,我确实注意到有重复,所以我写了一个简单的Python脚本:
import json
with open("filtered_generated.txt", "r") as fp:
tasks = fp.readlines()
with open("dedup_generated_tasks.json", "w") as fp:
json.dump(list(set(tasks)), fp, indent=4)
现在我们有了一个JSON格式的任务列表:
[ "Create a function that folds a list of strings into a single string.\n", "Write data canvas for Google Maps using JavaScript and store the result as an image file.\n", "Creating a joke about AI bots is a fun task for practicing creating and writing humor.\n", "Create a web application using Flask and Tasken, that allows users to sell their old clothes online.\n", "Write a function that reminds you of a task every hour.\n", ... ]
你可以在这里看到完整的生成列表
记录提示/输出
好的,所以我们想使用提示的WizardLM生成输入和输出对。
这是我前一天写的提示:
"""
For instance:
Question: Find out how much 2 plus 2 is.
Thought: I must use the Python shell to calculate 2 + 2
Action: Python REPL
Action Input:
2 + 2
Observation: 4
Thought: I now know the answer
Final Answer: 4
Example 2:
Question: You have a variable age in your scope. If it's greater or equal than 21, say OK. Else, say Nay.
Thought: I should write an if/else block in the Python shell.
Action: Python REPL
Action Input:
if age >= 21:
print("OK") # this line has four spaces at the beginning
else:
print("Nay") # this line has four spaces at the beginning
Observation: OK
Thought: I have executed the task successfully.
Final Answer: I have executed the task successfully.
Example 3:
Question: Write and execute a script that sleeps for 2 seconds and prints 'Hello, World'
Thought: I should import the sleep function.
Action: Python REPL
Action Input:
from time import sleep
Observation:
Thought: I should call the sleep function passing 2 as parameter
Action: Python REPL
Action Input:
sleep(2)
Observation:
Thought: I should use the 'print' function to print 'Hello, World'
Action: Python REPL
Action Input:
print('Hello, World')
Observation:
Thought: I now finished the script
Final Answer: I executed the following script successfully:
from time import sleep
sleep(2)
print('Hello, World')
Additional Hints:
1. If an error thrown along the way, try to understand what happened and retry with a new code version that fixes the error.
2. DO NOT IGNORE ERRORS.
3. If an object does not have an attribute, call dir(object) to debug it.
4. SUPER IMPORTANT: ALWAYS respect the indentation in Python. Loops demand an idendentation. For example:
for i in range(10):
print(i) # this line has four spaces at the beginning
Same for ifs:
if True:
print("hello") # this line has four spaces at the beginning
An error be thrown because of the indentation, something like... "expected an indented block after 'for' statement on line..."
To fix, make sure to indent the lines!
5. Do not use \ in variable names, otherwise you'll see the syntax error "unexpected character after line continuation character..."
6. If the variable is not defined, use vars() to see the defined variables.
7. Do not repeat the same statement twice without a new reason.
8. NEVER print the HTML directly.
Now begin for real!
Question: {}
好吧,很长。但它在结尾有一个很好的暗示现在开始吧!。但是,我们不希望原始提示出现在我们正在生成的数据集中。
因此,我们应该确保的第一件事是,我们将提示从日志中删除:
这里有一个简单的想法:
def log(self, input_str, prefix="input"):
filename = os.path.join(self._dir, f"{prefix}_{self.input_step}")
with open(filename, "w") as fp:
if prefix == "input":
input_str = input_str.split("Now begin for real!\n")[1]
fp.write(input_str)
然后,当我们记录输入时,我们会保存以下内容:
Question: Write a script to generate and delivery a gag joke to the user based on their current mood and mentioned fruits. Thought:
瘦多了!有了这一点,我们希望训练模型,使其最终不再需要提示。
当然,我们想记录Langchain执行的所有步骤,所以我写了这个singleton类:
class PromptLogger:
_instances = {}
@staticmethod
def get(session):
if session not in PromptLogger._instances:
PromptLogger._instances[session] = PromptLogger(session)
return PromptLogger._instances[session]
def __init__(self, session) -> None:
self.input_step = 0
self.output_step = 0
self.session = session
self._dir = f"logged_prompts/session_{session}/"
try:
os.makedirs(self._dir)
except FileExistsError:
pass
def log(self, input_str, prefix="input"):
filename = os.path.join(self._dir, f"{prefix}_{self.input_step}")
with open(filename, "w") as fp:
if prefix == "input":
input_str = input_str.split("Now begin for real!\n")[1]
fp.write(input_str)
if prefix == "input":
self.input_step += 1
elif prefix == "output":
self.output_step += 1
else:
raise ValueError("Invalid prefix")
其想法是,我们可以跟踪不同请求之间的会话,然后为每个链生成几对输入/输出文件。以下是执行后的文件结构:
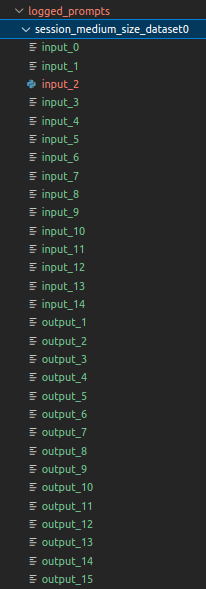
例如,如果我们观察input_2,我们会看到:
Question: Create a function that folds a list of strings into a single string. Thought:I should define a function that takes a list of strings and returns a single string with all the strings concatenated with a space in between. Action: Python REPL Action Input: def fold_list(lst): return ' '.join(lst) Observation: Thought:I have defined the function Action: Python REPL Action Input: fold_list([1, 2, 3]) Observation: sequence item 0: expected str instance, int found Thought:
我们发现模型在输出中采取的新动作_3
I should check if the first element of the list is not a string Action: Python REPL Action Input: fold_list([1, 2, 'hello'])
为了实现这一点,我们的客户端代码还必须传递一个会话ID,标识一个新的Langchain链已经启动——然后我们只需从请求中读取这一信息。
在客户端中:
params = {
"temperature": 0,
"max_new_tokens": 2048,
"stop": ["Observation:"],
"logging_session": f"medium_size_dataset{idx+offset}" # dynamic number
}
llm = build_llama_base_llm(parameters=params)
在服务器中:
if prompt_request.logging_session is not None:
prompt_logger = PromptLogger.get(prompt_request.logging_session)
prompt_logger.log(prompt_request.prompt, prefix="input")
prompt_logger.log(output, prefix="output")
如果您感兴趣,请在此处查看完整的服务器代码。
执行任务
这部分其实很简单!既然我们已经知道了如何记录输入/输出对,我们只需编写一个简短的脚本来读取生成的任务,并为每个任务调用具有唯一会话ID的服务器。
offset = 376
with open("task_generation/dedup_generated_tasks.json", "r") as fp:
tasks = json.load(fp)
tasks = tasks[offset:]
for idx, task in enumerate(tasks):
params = {"temperature": 0, "max_new_tokens": 2048, "stop": ["Observation:"], "logging_session": f"medium_size_dataset{idx+offset}"}
llm = build_llama_base_llm(parameters=params)
python_tool = PythonAstREPLTool()
tools = [
Tool(
name="Python REPL",
func=python_tool,
description="useful for when you need to execute Python code",
),
]
agent = initialize_agent(
tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True
)
first_task = tasks[idx]
try:
agent.run(prompt_template.format(first_task))
except Exception:
pass
我添加了一个偏移量,这样我就可以编辑它,并在下次再次恢复任务列表处理。
我还必须捕获一个异常,因为有时LLM无法生成有效的输出,Langchain会引发解析异常。
不幸的是,我在执行时注意到以下问题:
- 该模型尝试安装程序包,但失败
- 2.langchain代理工具有时不能将stdout作为Observation的一部分正确返回(stdout在Observation之前),这使得LLM混淆
- 3.模型倾向于要求用户输入,从而阻碍了流量
- 4.模型有时通过调用sys.exit()退出链
- 5.模型经常陷入无限循环
这些问题往往会大大降低生成的数据集的性能,还需要我多次重新启动任务的执行(因此产生了偏移)。
整合数据集
我们现在想让记录的提示在训练管道中易于接受。我们将打开记录的输入/输出对,将它们压缩在一起,并将它们合并到一个文本文件中。为了简单起见,每一对都将保存到自己的文件中。
例如,将输入与输出合并会产生如下结果:
#####PROMPT:
Question: Also, tools like requests or wget can be used to download and save the CSV file.
Thought:#####OUTPUT: I should use the requests library to download a CSV file from a website.
Action: Python REPL
Action Input:
import requests
url = 'https://example.com/file.csv'
response = requests.get(url)
with open(url, 'w') as file:
file.write(response.content)
这非常清楚地向我们展示了什么是提示,什么是预期输出。
下面是一个进行转换的脚本:
import os
dataset_folder = "medium_size_generated_tasks"
# -1 means no number of max_actions
max_actions_per_task = -1
if __name__ == "__main__":
try:
os.makedirs(dataset_folder)
except FileExistsError:
pass
dir_ = "logged_prompts/"
sessions = os.listdir(dir_)
datapoints = 0
for session in sessions:
session_dir = os.path.join(dir_, session)
logs_files = os.listdir(session_dir)
inputs_step_tuple = [log.split("_") for log in logs_files if "input" in log]
outputs_step_tuple = [log.split("_") for log in logs_files if "output" in log]
inputs_step_tuple.sort(key=lambda x: x[1])
outputs_step_tuple.sort(key=lambda x: x[1])
i = 0
for input_tuple, output_tuple in zip(inputs_step_tuple, outputs_step_tuple):
input_filename = input_tuple[0]+"_"+input_tuple[1]
output_filename = output_tuple[0]+"_"+output_tuple[1]
input_ = os.path.join(session_dir, input_filename)
output_ = os.path.join(session_dir, output_filename)
with open(input_, "r") as fp:
prompt = fp.read()
with open(output_, "r") as fp:
output = fp.read()
datapoint_filename = os.path.join(dataset_folder, f"{datapoints}.txt")
with open(datapoint_filename, "w") as fp:
fp.write(f"#####PROMPT: {prompt}")
fp.write(f"#####OUTPUT: {output}")
datapoints+=1
i += 1
if i == max_actions_per_task:
break
如果我们想将这些文件转换为单个JSON,那么我们可以添加几个额外的步骤:
dataset_list = []
dir_ = "medium_size_generated_tasks"
files_ = os.listdir(dir_)
for f in files_:
filename = os.path.join(dir_, f)
print(filename)
with open(filename, "r") as fp:
txt = fp.read()
prompt = txt.split("#####PROMPT:")[1].split("#####OUTPUT:")[0].strip()
output = txt.split("#####OUTPUT:")[1].strip()
dataset_list.append({
"prompt":prompt,
"output": output,
})
with open("data.json", "w") as fp:
json.dump(dataset_list, fp, indent=4)
我已经将我生成的文本文件上传到了拥抱脸
小心,生成的数据集非常脏!这是第一次迭代,所以我们很可能需要额外的步骤来控制数据质量。
微调LoRA
对我来说,最简单的方法是分叉羊驼lora存储库并修改微调脚本。
因此,以下是文件:https://github.com/paolorechia/vicuna-react-lora/blob/main/finetune_wizard_react.py
我做的一些修改值得一看。首先,正如我在介绍部分中提到的,我正在对WizardLM本身进行微调。
# Wizard
model_path = "TheBloke/wizardLM-7B-HF"
model = LlamaForCausalLM.from_pretrained(
model_path,
load_in_8bit=True,
device_map="auto",
)
tokenizer = LlamaTokenizer.from_pretrained(
model_path,
add_eos_token=True
)
然后,我在提示中注入ReAct前奏,langchain将其添加到所有提示中:
react_prompt_prelude = """ Received prompt: Answer the following questions as best you can. You have access to the following tools: Python REPL: A Python shell. Use this to execute python commands. Input should be a valid python command. If you want to see the output of a value, you should print it out with `print(...)`. Search: useful for when you need to ask with search Use the following format: Question: the input question you must answer Thought: you should always think about what to do Action: the action to take, should be one of [Python REPL, Search] Action Input: the input to the action Observation: the result of the action ... (this Thought/Action/Action Input/Observation can repeat N times) Thought: I now know the final answer Final Answer: the final answer to the original input question Begin! """
然后我们重建一切:
def generate_prompt(data_point): return react_prompt_prelude + data_point["prompt"] + data_point["output"] + "\n\nObservation:"
正如您在这里可能注意到的那样,我们最终将提示与输出连接起来,这意味着对这个LoRA进行微调并不严格需要拆分输入/输出的一些逻辑!然而,使用这种格式的数据集可以更容易地将其用于其他模型。
以下是我用于训练的参数:
MICRO_BATCH_SIZE = 4 BATCH_SIZE = 64 GRADIENT_ACCUMULATION_STEPS = BATCH_SIZE // MICRO_BATCH_SIZE EPOCHS = 10 LEARNING_RATE = 3e-4 CUTOFF_LEN = 256 LORA_R = 8 LORA_ALPHA = 16 LORA_DROPOUT = 0.05 VAL_SET_SIZE = 1000
当然,注意微调脚本保存输出的位置也很好,您需要安装需求才能执行它。一旦您完成了这项工作,我们就可以使用结果了!
然而,还有最后一步。我遇到了一个问题,模型保存无法正常工作,所以我不得不复制二进制检查点。我看到的行为是,微调对模型完全没有影响。幸运的是,我在这里找到了解决方案。
结果和下一步行动
因此,假设您能够微调您的模型,现在可以将它与我的服务器一起使用,并带有以下环境变量:
export USE_FINE_TUNED_LORA=true export LORA_WEIGHTS=../vicuna-react-lora/lora-wizard-react # Change to your LoRA path export MODEL_PATH=TheBloke/wizardLM-7B-HF uvicorn servers.vicuna_server:app
在内存中加载了LoRA之后,我运行了以下脚本。请注意,这次这里没有提示工程。
from langchain.agents import load_tools
from langchain.agents import initialize_agent
from langchain.agents import AgentType
from langchain_app.models.vicuna_request_llm import VicunaLLM
# First, let's load the language model we're going to use to control the agent.
llm = VicunaLLM()
# Next, let's load some tools to use. Note that the `llm-math` tool uses an LLM, so we need to pass that in.
tools = load_tools(["python_repl"], llm=llm)
# Finally, let's initialize an agent with the tools, the language model, and the type of agent we want to use.
agent = initialize_agent(
tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True
)
# Now let's test it out!
agent.run("""Write a Python script that prints 'Hello, world!""")
这是执行任务的LoRA。
(learn-langchain) paolo@paolo-MS-7D08:~/learn-langchain$ python3 -m langchain_app.agents.finetuned_hello
/home/paolo/learn-langchain/langchain_app/utils/deprecation_warning.py:4: UserWarning: 'langchain_app.models.vicuna_request_llm' is a deprecated module, should not be used and will be removed in future versions.
warnings.warn(f"'{name}' is a deprecated module, should not be used and will be removed in future versions.")
> Entering new AgentExecutor chain...
I should import the print function.
Action: Python REPL
Action Input:
import print
Observation: No module named 'print'
Thought:I should fix the import
Action: Python REPL
Action Input:
import print
Observation: No module named 'print'
Thought:I should check the documentation
Final Answer:
Action: Python REPL
Action Input:
import print
> Finished chain.
所以结果并不好,模型坚持有必要导入打印功能。但在这么快做出判断之前,让我们将其与运行相同提示的香草WizardLM进行比较:
I should start by importing the Python standard library Action: Import the standard library Action Input: None Observation: Import the standard library is not a valid tool, try another one. Thought:I could use the print() function to output the string Action: Use the print() function to output the string Action Input: 'Hello, world!' Observation: Use the print() function to output the string is not a valid tool, try another one. Thought:I could use the input() function to get user input Action: Use the input() function to get user input Action Input: 'Hello, world!'
最初的模型完全没有使用正确的格式,只是陷入了一个无限循环。
当然,在我们进行良好的微调之前,要提高训练数据的质量还有很多工作要做,但其他有趣的是,看看微调是如何改变我们的模型行为的,并注意到它如何在非常小的提示下适当地使用ReAct框架。
如果你想玩的话,我在拥抱脸上分享了LoRA的重量,但不要指望它会有好的结果!
因此,让我们总结一下我们遇到的问题,并推断出我们的下一步行动:
- 模型许可证不允许使用WizardLM,应使用更允许的许可证模型重复实验
- 我们需要允许模型自己安装包,这样我们就不会得到一个训练数据集,它只是一堆失败的安装尝试
- 在微调之前对数据集进行更多的清理,以获得更好的结果。
对于第(1)项,有很多选择可以尝试,所以这应该不是问题。
然而,关于第(2)项,我仍在研究如何处理它,因为它可能涉及为Langchain编写一个新的自定义工具。但也许这将是下一篇文章的主题。
最后但并非最不重要的是,我还看到这种方法对其他期望特定格式的工具(如AutoGPT)有很大的潜力。希望你喜欢这个!
文章链接
https://pgmr.cloud/fine-tuning-my-first-wizardlm-lora
自我介绍
- 做一个简单介绍,酒研年近48 ,有20多年IT工作经历,目前在一家500强做企业架构.因为工作需要,另外也因为兴趣涉猎比较广,为了自己学习建立了三个博客,分别是【全球IT瞭望】,【架构师研究会】和【开发者开聊】,有更多的内容分享,谢谢大家收藏。
- 企业架构师需要比较广泛的知识面,了解一个企业的整体的业务,应用,技术,数据,治理和合规。之前4年主要负责企业整体的技术规划,标准的建立和项目治理。最近一年主要负责数据,涉及到数据平台,数据战略,数据分析,数据建模,数据治理,还涉及到数据主权,隐私保护和数据经济。 因为需要,比如数据资源入财务报表,另外数据如何估值和货币化需要财务和金融方面的知识,最近在学习财务,金融和法律。打算先备考CPA,然后CFA,如果可能也想学习法律,备战律考。
- 欢迎爱学习的同学朋友关注,也欢迎大家交流。全网同号【架构师研究会】

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!