51-5 Transformer 论文精读
李沐(沐神)、朱毅讲得真的好,干货蛮多,醍醐灌顶。编码器、解码器、多头自注意力、自回归的概念没搞清楚的话,值得认真读很多遍,甚至可以当成多模态大模型基础课程学习。
今天我们将讲的是transformer这个模型,也就是大家投票分数最高的一篇模型。这篇文章可以认为是最近三年以来深度学习里面最重要的文章之一,他可以认为是开创了即MLP,CNN和RNN之后的第四大类模。斯坦福联合了100多名作者作了一两百页的综述文章,他们甚至提议说将这一类模型叫做基础模型,可以见它对整个领域的影响力是有多大。
首先我们看一下标题,标题是说attention is all you need,就是说你就需要注意力就行了。当然在英语中这也是一句合法的话,就是对小孩说,集中一下注意力,不要东看西看。这个标题成为了一个梗。你要出文章,就把这个词换成任何跟你想要的词,只要你换成这个词,基本上你的文章能够上头条。然后我们来看一下作者,这里面有八个作者,作者绝大部分都是在Google,然后有两个作者不在Google,他做了一个注释,注释上面写的是这个是这两位作者在Google应该是实习的时候完成的工作。另外比较有意思的是这篇文章每一个作者后面都打了一个星号,星号在论文里面我们一般叫做同样贡献,就是说一般来说我们会把前面一两三个作者的贡献是差不多的,因为在机器学习这一块,我们一般会按照作者对文章的贡献,从大排到小排序,也就是说第一作者通常对文章的贡献是比较大的,很多时候,在绝大部分文章里面,第一作者贡献了80%的事情,有一些情况是说第一个,第二个,第三个作者有同样贡献,这个也是常见的,但是说你整个文章八个作者对整个文章的贡献都是均等,这个情况是比较少见的。当你一篇文章有比较多作者的时候,能把每个作者对这个文章的贡献明明白白写出来,其实是一件很好的事情,这也是告诉大家说,我们这个名字也不是随便挂名的,然后每个人确实需要明明白白给这篇文章做出贡献才能挂名。
Abstract摘要
这个摘要的第一句话是说,在主流的序列转录模型里面,所谓的序列转录模型就是说我给你一个序列,你生成另外一个序列。机器翻译说给一句英文,生成一句中文。当然是一个序列转录模型这样子模型,主要是依赖于比较复杂的循环,或者是卷积神经网络。然后它一般是用一个叫做encoder和decoder的架构。这句话意思是说,你多多少少知道这个模型的Encoder、decoder的架构是什么样子,CNN、RNN是什么样子,当然你得假设你知道。然后第二句话是说,在性能最好的这些模型里面,通常也会在你的编码器和解码器之间,使用一个叫做注意力机制的东西。基本上就是说这篇文章讲的是我要做序列到序列的宣传,现在主流的模型是干什么东西。第三句话是说我这篇文章提出了一个新的简单的架构。所以现在比较有意思的是,之前我们都说我们提供一个Novel,就是比较有意思的架构,现在基本上因为我们的模型其实现在都挺复杂的,如果你能做一个simple的架构其实也挺好的,只要你的结果好,大家其实还是挺喜欢简单的架构。我们之前讲的ResNet其实也是一个比较简单的架构,所以大家挺喜欢的,这个也是整个研究氛围的一个转变。我们说simple这个词不再是一个贬义词,而是一个褒义词,这样的结果好。他说这个模型的名字叫transformer,中文翻译叫做变形金刚,这个也是比较有意思的起名方法。你当然可以说我把我的模型取得一些大家很熟知的一些名词,就很容易被记住。这个问题是说,如果你的文章没有出名,大家去搜你文章的时候,根本就搜不到你的文章,还是搜到的是变形金刚,取名字也是一个非常重要的事情。好的文章,一般有一个比较好的名字。我们之前讲过的ResNet,这个名字其实挺好的,很好记对吧。然后我们讲到第一篇文章Alex,其实那篇文章根本就没有提到AlexNet这个名字,他根本没有给自己的文章取个名字,也估计作者也没想到自己会那么火。他说我们做了一个神经网络,因为这篇文章是开创工作,大家要重复你的结果的时候,总要给你的模型取个名字,然后提到你的时候最好有个名字好,所以大家给了你一个名字叫做Alex。Alex来自于第一作者的名字,所以对于后面文章的作者来讲,如果不想让别人给你取名字的话,当然给自己取一个比较好的名字比较重要。然后他接着说,我这个模型,仅仅依赖于注意力机制,而没有用之前的循环或者是卷积,这就是他的贡献。他提出了一个新的模型,简单,然后跟之前大家表现很好的模型的架构都长得不一样。接下来说我做了两个机器翻译的实验,显示这个模型在性能上特别好,他说可以并行度更好,然后使用更少的时间来训练,他说我的模型达到了28.4的BLEU。BLEU是在机器翻译里面大家经常用的一个衡量标准。如果你不做机器翻译的话,你可能不一定明白BLEU score是干什么事情。没关系,他说我这个在英语到德语的一个翻译工作,比目前的最好的结果好了两个blue。然后在一个英语到法语的翻译的任务上面,他们做了一个单模型,比所有的模型都要效果要好。他只在8个GPU上训练了3.5天。最后transformer架构能够泛化到一些别的任物上面都很好。我提出了一个新的模型,主要用在是什么?在机器翻译这个任务上面,所以这篇文章一开始写的时候是针对机器翻译这个小任务写的。他整个写作的时候,他假设你前面是知道的,然后我提出一个模型,然后主要在机器翻译上,结果很好。这个也是比较有意思的工作,他一开始做的是机器翻译这个比较相对来说小一点的领域上面,之所以说小,是因为你会发现机器翻译就那么几家公司关心对吧,你能够提供器翻译的那些服务的公司,其实全世界范围来讲也就那么多家。随着之后BERT,GPT把这个架构用了起来,整个这个出圈了。最近大家都知道用在了图片上,用了视频上,几乎上什么东西都能用,所以这篇文章是真正的火出圈在这个地方。你第一次读这个文章的时候,你可能看到机器翻译这一块,你可能不那么感兴趣,当然了,现在我们知道这篇文章非常重要。我们就还是继续往下读,我们接下来直接跳到我们的结论,跟我们之前的做法是一样。结论的第一句话是说我们介绍了transformer这个模型,这是第一个做序列转录的模型,然后仅仅使用注意力,把以前所有的循环成全部换成了multi-headed self-attention。基本上可以看到这篇文章主要提出了是这样一个层。第二句话是说,在机器翻译这个任务上面,Transformer能够训练的比其他的架构都要快很多,而且,在实际的结果上确实是效果比较好。然后第三段是说他对于这种纯基于注意力机制的模型感到非常的激动,他想把它用在一些别的任务上面,他觉得可以用在文本以外的数据上,包括图片、语音、Video,然后他说使得生成不那么时序化,也是另外一个研究的方向。其实现在看起来,作者多多少少是预测到未来的,对吧?Transformer真的在各种别的数据上以及这一块做的是比较好。虽然这些工作基本上都不适于本篇文章作者完成的,都是由别人完成的。但是本文的作者,基本上是看准了大方向的。最后一句话是说,这篇文章所有代码放github.com/tensorflow/tensor2tensor这个库里面。这也是比较有意思的写法,他把整个代码放在了结论的最后。但是现在我们知道,如果你有代码的话,通常你会把这个代码放在你摘要的最后一句话。因为现在神经网络的文章里面细节通常是比较多的,简简单单单的一篇文章很难把所有的细节写清楚,所以你最好第一时间公布你的代码,让别人能够很方便的重复你的文章,然后这样能扩大你文章的影响力。
Introduction导言
接下来我们来看第一段导言,这里的导言写的是比较短的,基本上可以认为是前面摘要的前面一半的一个扩充。我们来看一下他第一段话是说在时序模型里面,当前最常用的是RNN,这是2017年,它包括了LSTM,GRU。然后接下来它当然是说,在这里面,有两个比较主流的模型,一个叫做语言模型,另外一个是当你的输出,结构化信息比较多的时候,大家会用一个叫做编码器解码器的架构。第二段话是讲RNN的特点是什么,同样也是它的缺点是什么。在RNN里面,给你一个序列的话,它的计算是把这个序列从左往右,一步一步往前做。假设你的一个序列是一个句子的话,它就是一个词一个词的看,对第t个词,它会计算一个输出,叫做ht,也叫它的隐藏状态。然后,它的ht是由前面一个词的隐藏状态叫ht-1和当前第t个词本身决定的。这样子的话,他就可以把前面学到的历史信息,通过ht-1放到当下,然后和当前的词做一些计算,然后得到输出。这也是RNN如何能够有效处理持续信息的一个关键之所在。他把之前的信息全部放在隐藏状态里面,然后一个一个放下去。但它的问题也来自于这里,第一个说它是一个时序,就是一步一步计算的过程,它比较难以并行。就是说你在算第t个词的时候,算ht的那个出处的时候,你必须要保证第前面那个词的ht-1输入完成了。假设你的句子有100个词的话,那么就是说你得持续的算100步,导致说你在这个时间上呀,你无法并行。现在在主流的GPU和那些加速器,比如说TPU样的,大家都是成千上万个线程,你无法在这个上面并行的话,导致你的并行度比较低,使得你在计算上性能比较差。第二个也是因为这个原因,你的历史信息,是一步一步的往后传递的,导致如果你的时序比较长的话,那么你在很早期那些时序信息,在后面的时候可能会丢掉。如果你不想丢掉的话,那你可能要得要ht要比较大,就说你得做一个比较大的ht。但是这个的问题是说,如果你做比较大的ht,你在每一个时间部都得把它存下来,导致你的内存开销是比较大的。当然他也提到过,这一块其实大家在过去一些年做了非常多的改进,不管是并行的改进,以及做一些分解的方法,使得我们能够提升并行度,但是,本质上还是没有解决太多问题。第三段,它其实讲是attention在RNN上的应用。在这篇文章之前,Attention已经被成功用在编码器和解码器里面了。它主要是用在怎么样把编码器的东西,很有效的传给解码器,主要是用在这一块,就是说你跟RNN是一起使用的。最后一段讲的是这篇文章提出来的transformer,这是一个新的模型,不再使用之前被大家使用的循环神经层,而是基于注意力机制了。他说我这个东西因为是可以并行的,因为之前你攻击的就是持续神经网络,主要是要按时序的做运算,现在你做了attention之后,你可以完全做并行。因为它现在纯用的attention,所以它的并行度是比较高的,这样子的话,他能够在比较短的时间之内,做到一个跟之前可能更好的结果。
这就是导言的事情,总体来看这个导言是写的比较短的,可以认为就是摘要的前面几句话的一个稍微的扩充版本,也对自己提出的方法,也就是一句话带过了。这么写的原因,我觉得应该是因为这篇文章提出来东西是比较多的,它是一个比较不一样的一个网络,里面有一些很新的东西在里面。然后是发表在NeurIPS上面,NeurIPS是一个篇幅比较短的一个会议,它是一个单列的,然后也就八页吧,所以导致说你要在这么一个短的模板里面写下很多东西,实际很难的,那你就得压缩掉一些东西。
Background背景
第二节是相关工作,首先它第一段提的是如何使用卷积审经网络来替换掉你的循环神经网络,使得减少你的时序计算。他提到了这个工作,主要的问题是说用卷积神经网络对于比较长的序列难以建模,这是因为我们知道卷积做计算的时候,每一次他去看一个一个比较小的一个窗口,比如说看一个3*3的一个像素块,如果你两个像素隔得比较远的话,你得需要用很多层卷积一层一层上去,才能够最后把这两个隔得远的像素给你融合起来。如果使用transformer里面的注意力机制的话,每一次我能看到所有的像素,所以我一层就能够把整个序列给你看到,相对来说就没有这个问题。但是他又提到说卷积它的一个比较好的地方是说可以做多个输出通道,一个输出通道可以认为是它可以去识别不一样的模式,所以他说我也想要这样子的多输出通道的效果。他提出了一个叫做multi-head attention,就是多头的注意力机制,所以可以模拟卷积神经网络多输出通道的一个效果。
接下来第二段他讲的是自主意力机制,其实这个是transformer里面一个关键性的点。但是他说,这个工作其实之前已经有人提出来了,并不是我这个工作的创新,所以是,所以我这个地方需要给大家说明白一下。另外他要提到一个叫做memory network的东西,这个在17年的时候也算是一个研究的重点吧。如果大家不知道的话,我们可以跳过。在我们best knowledge里面,我们的transformer是第一个只依赖于自注意力来做这种encoder的decoder的架构的模型。再就是相关工作的章节,关键是说你要讲清楚跟你论文相关的那些论文是谁,跟你的联系什么,以及说你跟他们的区别是什么。
Model Architecture模型架构
接下来是第三章模型架构,我们知道深度神经网络论文里面最重要的就这一章了。这一章怎么讲你这个神经网络长什么样子?我们来看一下,第一句话说这些序列模型里面,现在比较好的是一个叫做编码器和解码器的架构,然后他解释一下什么是编码器。解码器就对编码器来讲,它会将一个输入,就是一个长为n的一个x1,一直到xn的一个东西,假设你是一个句子的话,有n个词的话,那么第xt就表示你的第t个词。他说将这个序列,编码器会把它表示一个也是长为n,但是,其中每一个zt,它对应的是xt的一个向量的表示。假设你是一个句子的话,那么gt就表示你第t个词的一个向量的表示,这就是你的编码器的输入,就是这样一些,原始的一些输入变成一个机器学习可以理解的一系列的向量。那对解码器来讲,我会拿到编码器的输出,然后它会生成一个长为m的一个序列。首先注意到n和m是不一样长的,可以一样可以不一样,比如说你英文句子反应中文句子的话,那么两个句子很有可能是不一样长的,它跟编码器的一个大的不一样是说在解码器里面,你的这个词是一个一个生成的。因为对编编码器来讲,你很有可能是一次性能看出整个句子,就是说做翻译的时候,我可以把整个英语的句子给你,但是你在解码的时候,你只能一个一个的生成,这个东西叫做一个叫做自回归,auto-regressive模型。在这个里面,你的输入又是你的输出。具体的看一下是说在最开始我给定你的z,那么你要去生成第一个输出,叫做y1,在拿到y1之后,我就可以去生成我的y2,然后一般来说你要生成yt的话,你可以把之前所有的y1到yt-1全部拿到,也就是说你在翻译的时候,你是一个一个词的往外蹦。所以就是说你在过去时刻的输出也会作为你当前时刻的输入,所以这个叫做自回归。这就是第一段讲的事情,然后它又很简单,说transformer是使用了一个编码器、解码器的架构。具体来说,它是将一些自注意力和point-wise,full connected layer,然后把一个一个堆在一起的。我们在下面的图一给大家展现这个架构,这个图如果你讲transformer的话,很有可能你就是把这个图复制一下,然后放到你的PPT里面给大家讲。这就意味着是说,如果你写论文的话,有一张比较漂亮的,能够把整个全局画清楚的图是非常重要的,因为很有可能别人讲你的论文的时候,就是把这个图搬过去。如果你的图画的不够好的话,别人可能还要画半天来讲你的东西,如果你画的很好的话,就是一张图能够搞定所有东西。所以就是说在神经网络年代,会画图是一个很基础的技能。具体到这篇文章话,这张图画的是挺好的,但是如果你就读到这个地方的话,你会发现其实你看不懂这个图的,因为你什么东西都不知道,什么东西没解释这个东西是什么东西。当然我们可以现在可以做一个事后诸葛亮给大家来讲一下这个到底是在干什么事,当然每一个模块我们在后面会讲到。

首先你看到是它是一个编码器和解码器的架构,左边这个东西是你的编码器,右边这一块是你的解码器。这是编码器的输入,就是比如说你中文翻英文的话,那么这就是你的中文的句子。然后这是你解码器的输入,在解码器在做预测的时候是没有输入的,实际上它就是解码器在之前时刻的一些输出,作为输入在这个地方,所以这个地方写的是一个output。那他说shifted right,就是一个一个往后往右移。然后看到是你的输入进来,先进入一个嵌入层input embedding,就是大家都要干的事情。进来是一个一个词,我把它表示成一个向量。后面这个地方加了一个叫做position encoding。再后这个地方就是你的核心的一个编码器的架构了,这个Nx是说你这个层,有N个这样子层剁在一起叭,譬如说你在讲ResNet的时候,我们说的一个残差块是一个块,然后你把N个块剁在一起,最后剁的东西,在这个地方,你可认为这个叫做transformer block也是transformer的一个块。具体你进去看的话,你会发现是说第一个叫做multi-head attention的,然后再有一个前馈神经网络,然后它有一个残差的连接,然后这个Norm我们等会再讲。基本上可以看到是说一个注意力层再加上一个,基本就是一个MLP吧,然后在中间有一一点的残差连接,然后再有一些的normalization。然后你的编码器的输出,就会作为你的解码器的一个输入在这个地方放进来。这是比较有意思的一个东西,在解码器的话,跟编码器有点像,所以这一块是一样的,但是它多了一个叫做mask的一个多头注意力机制,当然我们等会会来讲。同样道理的话,你可以基本上可以认为就是解码其实就是这三块组成一个块,然后把它重复n次,会得到你最后的一个解码器,最后你的输出进入一个输出层,然后做一个soft max就会得到你的输出。这一块就是标准的神经网络的做法,它确实是一个比较标准的编码器,解码器的架构只是说你中中间的每一块,跟之前是一个不一样的地方在里面,但还有一个是说你怎么样,这个东西怎么过来,也是有一点的不一样的。
接下来我们看一下每一个具体模块是怎么实现的。
其实下面的文章跟上面写的很像,就是非常的简洁,所以你第一次读的话,很有可能会遇到一些困难,但没关系,我们这里会给大家仔细的讲一下。首先它给大家介绍了一下它的编码器,从编码器它是用一个N等于6个的一个完全一样的层,也就是之前我们画的这一块,给大家看一下,就是说,他把这个东西叫做layer,然后再用重复6个layer出来,他说每个layer里面,会有两个sub-layer就是一个子层,第一个sub-layer 叫做multi-head self-attention,这个词已经出现很多次了,但是现在还没有解释,他在之后才会解释。第二个子层,是用的名字很长,他说是simple,然后是position-wise full connected feed-forward network,后面这个词是一个词,他说白了就是一个MLP,然后所以他为什么加一个simple,在这里就是一个MLP,但是他为了写的fancy一点,就把名字搞得特别长,我们之后再来解释。他说对于每一个子层,他用了一个残差连接,我们上一期已经讲过残差连接了,他说最后我们再使用一个叫做layer normalization的东西。解释完这一些之后,他说我这个子层,其实它的公式要写出来,就是长成这个样子的。

给大家画个线,就是说你的输入X进来,然后先进入你的那个子层,你是自注意力也好,MLP也好,然后因为是残差连接,他就把输入和输出加在一起,最后进入他的layer Norm。然后说他说为了简单起见,,因为我的残差连接需要你的输入和输出是一样大小。如果不一样大小的话,你得做投影。所以为了简单起见,我就把每一个层它的输出的维度变成512。也就是说你对每一个词,你不管在哪一层,我都做了是512的这个长度的表示。这个我们之前的CNN是不一样的,或者我们之前做MLP的时候,经常会把维度往要么是往下减,要么CNN的话是空间维度往下减,但是channel维度往上拉。但是这个地方,其实它就是固定长度来表示,使得这个模型相对来说是比较简单的。然后调参,也就调一个参,另外一个参数,说你要复制多少块。这个简单设计影响到后面一系列网络,他说BERT怎么样,GPT怎么样,实际上也就是两个超参是可以调的。你就有多少层,然后每一层里面那个维度有多大,也就是这两个参数。接下来给大家解释一下什么是Layer Norm,可能你不做这一块的话,可能之前是不知道layer Norm,其实他也是因为transformer这篇文章被大家广为知道,所以给大家解释一下。另外一个是说,如果你写篇文章的话,你说我用了别人的东西,你最好在文章里面讲一下这是什么东西,你不能真的指望别人都知道所有的细节,能能够花几句话讲清楚是不错的,不然的话别人还得去点开那个链接去看一下到底是什么东西,是给大家带来了困难。接下来我们通过跟batch norm来对比,来解释一下什么是layer norm,以及说为什么我们在这些变长的应用里面不使用batch norm。首先我们考虑一个最简单的二维数的情况,二维数的话我就是输是一个矩阵,然后,我的每一行是一个样本,就是我的X,这个是我的Batch,然后我的每一列,是我的一个特征,那么我这写的就是一个feature Batch norm的时候干的事情。就是说每一次,我去把我的每一个列,就是每一个特征,把它在一个小mini Batch里面,它的均值变成零,方差变成1,你怎么把一个向量变成均值为零,方差为1?就是你把它的这个向量本身的均值减掉,然后再除以它的方差就行了。这个地方你算均值的时候,是在每一个小批量里面,就这条向量里面算出它的一个均值,算出它的一个方差。这个是在训练的时候,你可以做小批量,在在预测的时候,你会把一个全局的一个均值给算出来,这个你认为是一整个,整个数据扫一遍之后,在所有数据上,那些平均的那个均值方差存起来,在预测的时候再使用。当然了,Batch norm还会去学一个能把它一个伽马出来,就是说我可以把这个向量通过学习可以放成一个任意方差为某个值,均值为某个值的一个东西。Layer norm 跟batch norm在很多时候是几乎是一样的,除了他做的方法有点不一样之外。同样是我这一个二维数的话,Layer norm的事情就是对每个样本,他做normalization,不是对每一个特征做了。之前我是把每一个列它的均值变零,方差变1,现在是我把每一个行变成均值为零,方差为1。这个行就表示的是一个样本。所以你可以认为就是layer norm,就是整个把数据转置一下,放到batch norm里面出来的结果再转置回去一下,基本上可以得到自己的东西了。这个时输入是二维的时候最简单的情况,但是在我们的transformer里面,或者说正常的RNN里面,它的输入是一个三维的东西,因为它输入的是一个序列的样本,就是每一个样本其实是里面有很多很多个元素,对吧,它是一个序列,你给一个句子里面有N个词,对于每个词有个向量的话,还有一个batch的话,那么就是一个3D的东西,我们把它画出来,就是长成这个样子。这个地方还是你的batch还是你的样本,列不再是我的特征了,而是那个序列的长度,我们写成sequence。然后对每一个sequence,就是对每一个词,我当然是有自己的向量了,那我再画一个额外的维度,画在这个地方,这个就是我的feature了。如果在之前的话,Transformer里面,这个地方就是长这个东西长的就是n,那feature就是d。在刚刚我们设成了512,那如果你还是用batch normalization的话,(绿色)你每次是取一根特征。然后把它的每个样本里面所有的元素,就那个序列的元素,以及它的整个Batch,全部搞出来,把它的均值变成零,方差变成1。就是说我这么切一下,切一块出来,把它拉成个向量,然后跟之前作一样的计算。如果是layer norm的话,那么就是对每个样本就是这么切一下,(黄色表示),就这么横着切一下。就这两种切法不一样,但说切法不一样,它是会带来不一样的结果。具体来说为什么layer norm用的多一点,一个原因是说在时序的这些序列模型里面,你的每个样本的长度可能会发生变化。

比如说我们这个地方,我们可能会我们的样本是一个,(黄色)第一个样本的长度是,这样长的。第二个样本可能会长一点,第三个样本可能会短一点,第四个样本是中间长,可能是长度是这样子变换的。那些没有的东西,一般我们是把它放成零进去。那我们看一下这两种切法会有不一样什么的结果,如果是用Batch norm的话(绿色),我切出来的效果就是一个,跟你画出来结果一样,对,每一个特征你切出来东西会是一个这样子的东西,剩下的东西当然是填的是零了。如果是Layer norm的话,(黄色)第一个样本它切出来长度是一个怎样子的长度,第二个样本当然会长一点,是怎样子的长度,第三个是短一点,第四个是中等长度。这里的主要的问题是在算均值和方差的上面。对于batch norm来说,我算均值的时候其实是通过这样子来算的,对吧?但是我画线阴影的区域的值是有效值,别的值的话其实没什么太多用。你会发现你的如果你的样本长度变化比较大的时候,你每次做小批量的时候,你算出来的均值方差的抖动相对来说是比较大的。而且这个另外一个问题是说,因为我们记得我们在做预测的时候,我们要把这个全局的均值和方差记录下来。那么这个全局的均值方差,如果碰到一个新的预测样本,我特别特别长怎么办?我碰到一个那么那么长的东西,那么我是不是在训的时候没见过那么伸出去那么多,那么我在之前算的均值和方程可能是不那么好用的。但反过来讲,对layer norm相对来说没有太多这个问题线,是因为它是每个样本自己来算我的均值和房差,我也不需要存下一个全局的一个均值方差,因为这个东西是对每个样本来做的。所以相对来说你不管样本是长还是短,反正我算均值是在你自己里面算的,这样子的话相对来说候他稳定一些。这也是layer norm,大家去看那篇文章的时候,他是给大家这么解释的,当然实际上来说我们知道哈。一个很好用的一个东西,原文写的东西可能和之后大家理解释不一样的,在在之后有一篇文章来解释为什么layer norm有效是更多是从一个,对于梯度呀,对于输入的那一些normalization,然后,提升它的常数来解释的。

在讲完编码器的架构之后,我们来看一下解码器。解码器跟编码器是一个很像的东西,首先它跟编码器是由N=6个同样的层构成的。每个层里面,跟编码器有两个一样的子层,但是不一样的在于是说解码器里面用了一个第三个子层,它同样是一个多头的注意力机制。它说跟编码器一样,我们同样的用了残差连接,我们用了layer norm。另外一个是我们知道在解码器的时候,它做的是一个自回归。也就是说你当前的输出的输入,其实是上面一些时刻的输出。意味着是说你在做预测的时候,你当然不能看到之后的那些时刻的输出。但是我们知道在注意力机制里面,他每一次能看到整个完整的输入。所以这个地方我们要避免这个情况发生,也就是说在解码器训练的时候,在预测第t时刻的输出的时候,你不应该看到t以后的那些输入。它的做法是通过一个带掩码的注意力机制。如果你回过头来看这个图的话,你会发现这个地方是有一个masked,那些黄色的块都是多头的注意力。在这个地方是有个masked,保证你输入进来的时候,在t时间,是不会看到t时间以后的那些输入,从而保证你训练和预测的时候行为是一致的。看完我们的编码器和解码器的架构之后,我们来看一下每一个子层具体是怎么定义的。当然我们先要看到的是注意力层。第一段话就是一个对注意力的一个非常一般话的介绍,属于你懂的话,你看完之后就懂了。如果你不懂的话,你看完之后可能还是不懂。但不管怎么样,我们就按照这一段话给大家来解释一遍。首先他说注意力函数,是一个将一个query和一些key value对,映射成一个输出的一个函数。这里面所有的query,k,Value和output,它都是一些向量。具体来说你的output呀,是你的value的一个加权和。所以就导致说你的输出的维度跟你的value的维度是一样的。另外一个是说这个权重是怎么来的?对于每一个value的权重,它是这个value对应的key和你这个查询这个query的相似度算来的。这个相似度,或者叫做compatibility function,不同的注意力机制有不同的算法。如果我们画一个简单示意图,可以长成这样子。

假设我有3个value和3个对应的K。假设我们现在给一个query,这个query,跟第一个第二个K比较近。就是放在这个地方,那么你的输出,就是这三个V的相加,但是这个地方的权重会比较大一点,这个地方权重也可能比较大,但是这个地方的权重就会比较小一点。因为这个权重,是等价于你的query和你对应的K的那个相似度。同样道理,我假设再给你一个query,但是它是跟最后那一个K比较像的话,那么这样子你再去算它的V的时候,就会发现对后面的权重会比较高一点,中间权重也还不错,最后的权重是比较小一点,就会得到一个新的输出。虽然你的key value并没有变,但是随着你query的改变,因为权重的分配不一样,导致你的输出会有不一样,这就是注意力机制。因为不同的相似函数导致不一样的注意力的版本。
接下来这一章讲的是transformer自己用到的这个注意力机制是怎样计算的。

他起的名字叫做scaled dot-product attention。虽然名字比较长,实际上是最简单的注意力机制了。他说我这个里面,我的query和K它的长度是等长的,都等于dk。因为你可以不等长,不等长是有别的办法算的。然后它的value它的是dv,当然你的输出也一样的是dv了。他说我具体计算,对每一个query和K做内积,然后把它作为相似度。你可以认为两个向量做内积,如果两个向量内积的值越大,就是它的余弦值,那么就表示这两个向量的相似度就越高。如果你的内积为零,那就等于是这两个向量正交,就是没有相似度。然后算出来之后,它再除以根号dk,就是你这个向量的长度,然后再用一个soft max来得到你的权重。因为你给一个query,假设给n个k的话,那么就会算出n个值,对吧?因为这个query会跟每个K做内积,算出来之后再放进soft max,就会得到n个非负的,而且加起来和等于1的权重。对于权重我们觉得当然是非负,加起来来依就是比较好的权重,然后我们把这些权重作用在我们的value上面,就会得到我们的输出了。在实际中,当然我们不能一个一个这么做运算,算起来比较慢。所以下面给了一个在实际中的时候我们应该怎么样算,他说我的query,可以写成一个矩阵,就是我其实可能不止一个query,我有n个query,那我们画出来就是一个,假设是一个q是这个地方,那么你n行,然后你的维度,是等于dk的。同样道理的话,你的k,也是一个同样的东西,但你的可能会长一点或者短一点都没关系。假设你是m,就是你的query的个数和你的key value的个数可能是不一样的,但是它的长度一定是一样的,这样子我才能做内积。然后给定这两个矩阵,我把它一乘,就会得到一个N乘以M的一个东西,对吧?所以这个东西里面它的每一行,就这个蓝色的线,就是一个query对所有K的那一个内积值,然后我们再再除以这个根号dk,再做soft max。所谓的soft max就是对每一行做soft max,然后每行一行之间是独立的,这样子就会得到我的权重,然后再乘以我的V。我的V是有一个叫M行的,然后它的列数是dv的一个矩阵,这是v,然后这两个矩阵一乘的话,就会得到一个成为N*dv的一个东西,对吧,我们写在这个地方,n乘以dv。每一行就是我们要的一个输出了。所以这里你可以看到是说对于组key value,对,和你N个query的话,我可以通过两次矩阵乘法来把整个计算做掉这些query,K,Value。在实际中对应的就是我的序列,所以这样导致说我基本上可以并行的计算里面每一个元素。因为矩阵乘法是一个并行非常好的东西。
接下来一段,他说我提出来的注意力机制,跟别的的区别是什么样子?
他说一般有两种比较常见的注意力机制,一种叫做加型的注意力机制,它可以处理你的query和你的key不等长的情况。另外一个叫做点积的注意力机制,他说点积的注意力,跟我的其实一样的,除了我这里除了一个数字之外。所以你可以看到它的名字,它叫做scale的,就是除了那个东西的点积注意力机制。接下来他说这两种注意力机制,其实都差不多,但是他选用的是点乘。

这是因为这个实践起来比较简单,而且会比较高效,因为这就是两次矩阵乘法就能算好。当然你需要解释一下,你为什么不直接用最简单的点乘注意力,你为什么要这里要除以一个根号dk。当你的dk不是很大的时候,其实你出不出都没关系。但是当你的dk比较大的时候,也就是说两个向量,它的长度比较长的时候,那么你做点积的时候,那些值可能就会比较大,但也可能是比较小了。当你的值相对来说比较大的时候,你之间的相对的那些差距就会变大,就导致说你值最大的那一个值做soft max时候就会更加靠近于1,剩下那些值,就会更加靠近于零,就是你的值就会更加向两端靠拢。当你出现这样子情况的时候,你算梯度的时候,你会发现梯度比较小,因为soft max最后的结果是什么?最后的结果就是我希望我的预测值,置信的地方尽量靠近你,不置信的地方尽量靠近零,这样子的时候我说我的收敛就差不多了,这时候你的梯度就会变得比较小,那你就会跑不动。所以他说,我们在transformer里边一般用的dk比较大,之前说过是512,所以除以一个根号dk是一个不错的选择。整个这个注意力的计算,它在上面有张图给大家画了出来,可以看到你这里面有两个矩阵,一个是Q,一个K做矩阵乘法,然后再除以根号dk。这个地方我们一会讲,然后再做soft max做出来结果,最后跟你的值的那个矩阵做矩阵乘法,就会得到你的输出了,这个是通过计算图来展示你这个是怎么做的。
另外一个我们要讲到是怎么样做mask。
mask主要是为了避免你在第t时间的时候看到以后时间的东西。具体来说,我们假设我们的query和K是等长的,它们长度都为n,而且在时间上是能对应起来的。然后对于第t时间课的qt,就是我的query,那么我在做计算的时候,我应该只去看看k1,一直到kt-1,而不应该去看kt和它之后的东西,因为在当kt前时刻还没有。
但是我们知道在注意力机制的时候,其实你会看到所有你qt会跟所有K里面的东西全部做运算,就是k1,k2….kn。怎么办?就是说我们发现其实你算还是可以算的,就是说你把这些值全部给你算出来,然后在算出来之后,我们只要保证在计算权重的时候,我们不要用到后面这些东西就行了。具体来说它就在你这个地方,加了一个Mask(opt)。Mask的意思是说对于Qt和Kt和它之后的计算那些值,我给你换成一个非常大的负数,比如说负十次方。那么这一个那么大的负数在进入soft max做指数的时候,它就会变成零。导致soft max之后出来的这些东西,它对应的那些权重都会变成零,而只会前面这些出效果。这样子的话,我在算我的output的时候,我只用了V对应的V1,一直到Vt-1的结果就用上了它,而后面东西我没有看,所以这个mask效果是在我训练的时候,我让第t时间的只看我对应的前面那一些的K,使得我在做预测的时候,我跟现在这个是能够一一对应上的。
在讲完注意力机制的计算之后,我们来看一下multi-head是在干什么事情。

我们首先还是回到我们的文字那部分,他这里说,与其我做一个单个的注意力函数,不如说我把整个query key value投影到一个低维,投影H次,然后再做H次的注意力函数,然后每一个函数的输出,我把它并在一起,然后再投影回来,会得到我的最终的输出。上图是演示的效果,那我们就跳回看怎么做,这是原始的Value,Key,Query。然后在这地方,我们进入一个线性层,线性层就是把你投影的比较低的维度,然后再做一个scaled dot-product。全部放进来,然后我们这里做H次和得到H的输出,我们再把这些输出向量,全部合并在一起,最后做一次线性的投影,会回到我们的multi head attention。
为什么要做多头注意力机制?
如果我们回过头来看这一个dot product的注意力的话,你会发现里面没有什么可以学的参数,你的距离函数,就是你的内积,但有时候我为了识别不一样的那些模式,我希望你可能有一些不一样的计算相似的办法。如果你用的是加型的话,这里没有提到的,那里面其实还是有一个权重你来学的,你也许可以学到一些东西。他说我不用那个,那我用这个的话,我的一个做法是我先让你投影到一个低维,这个投影的w是可以学的,也就是说我给你一次机会,希望你能学到不一样的投影的方法,使得在那个投影进去的那个度量空间里面,能够去匹配不同模式它需要的一些相似函数,然后最后把这些东西回来,最后再做一次投影。所以跟我们之前说到的有点像,在卷积网络里面有多个输出通道的感觉。
我们看一下这个东西的具体的公式是怎么算的?

你会发现是在multi head的情况下,你还是以前的Q,K,V,但是,你的输出已经是你不同的头的那一个输出的Concat起来,在投影到一个Wo里面的。对每一个投影,把你的Q,K,V,然后通过一个不同的可以学习的Wq,Wk,Wv投影到一个低维上面,再做我们之前提到过的注意力函数,然后再出来就行了。这个地方你可以说每一个里面当时这么算的,他们在实际上来说,他用的H是等于8的,就是用8个头,而且我们知道你的注意力的时候,因为有残差连接的存在,使得你的输和输出的维度至少是一样的,所以它的做法是说你投影的时候,它投影的就是你的输出的维度除以H,因为我们之前我的输出维度是512,所以除以八8之后,就是每一次我们把它投影到一个64位的一个维度。然后在上面算你的注意力函数,然后再会投回来。虽然这个地方你看到是非常多的小矩阵的乘法,实际上你在实现的时候也可以通过一次的矩阵乘法来实现,这个可以。
在讲完多头注意力是如何实现了之后,在3.2章的最后一个小节里面讲的是在transformer这个模型里面是如何使用注意力的?
他这里讲了三种使用的情况,我们最简单的方法是回到我们之前那个架构图,看一看它到底是怎么被用的,我们回到我们的架构图。

我们看到的是黄色这个东西表示的是注意力的层,把这个地方一共有三种不一样的注力层,然后我们分别来看每个注意力层。首先我们看一下编码器的注意力是在干什么事情。
我们知道编码器的输入,这个地方,假设你的句子长度是N的话,它的输入其实是一个N个长为D的向量。假设大小设好,我们把它画出来,就是每一个输入它的词对应。那是一个长为D的向量,然后我们这里一共有N个这样子的东西。然后我们来看一下注意力层,它有三个输入,它分别表示的是key value和query。然后这个地方是你一根线过来,然后它复制成了三下。意思就是说同样一个东西,我既作为key,作为value,作为query,所以这个东西叫做自注意力机制。key,value和query其实就是一个东西,就是自己本身。
然后我们知道,那么这个地方我们输入了N个query,那么每个query会拿到一个输出,那么意味着我会有N个输出,而且这个输出和Value,因为长度是一样的话,那么我的输出的维度其实也是那个D,就是意味着我的输入和输出的大小其实是一个东西。那我们也可以把它画出来,画出来的话,其实就是你的输出也是跟它长度一样,长为N的一个东西,对每一个query我会计算一个这样子的输出。因为我们知道这个输出,其实就是你的value的一个加权和权重,是来自于query和key的一些东西,但它本身是一个东西,那么就意味着是说它的这个东西,实际上本身就是你的输入的一个加权和。这个绿色线代表权重的话,因为这个权重其实本身就是这一个向量,这个向量跟每一个输入的别的向量计算相似度,那么它跟自己算肯定是最大的就是说你这根线肯定是最粗的。假设这个线跟你最这边这个向量也相似度比较高的话,那么这个权重也会稍微高一点。假设我们不考虑多投投影的情况,你的输出,其实就是你的输入的一个加权和你的权重来自于你自己本身,跟各个向量之间的一个相似度。但如果我们说过有多头的话,因为有投影,其实我们在这个地方会学习H个不一样的距离空间出来,使得你出来东西当然是会有一点点不一样了。这个就是第一个注意力才是如何用的。

然后你看解码器是一回事,它这个地方一样的,是一个东西过来,然后复制成了三次,然后解码器的输入也是一样的,只是长度可能变成了一个长为M的样子,然后你的维度也是一样的,所以它跟编码器是一样的自注意力,唯一不一样的是这里有个mask。这个东西我们之前有解释过,在解码器的时候,比如你算query,它对应输出的时候,它是不应该看后面那些东西,所以意味着是说在解码器的时候,你的这些后面的东西,要设成零。我们用黄色的线表示一下,就是说后面这些东西,这些权重你要设成零,在解码器的时候,这就是mask它的一个作用。
然后我们看第三个注意力层

也就是在这个地方,这个地方你看到是它不再是自注意力了,而是你的key和你的value来自于你的编码器的输出。然后你的query,是来自于你下解码器下一个attention的输入,我们知道你的编码器最后一层的输出,就是N个长为D的向量。还是那么你的解码器的mask attention,就最下面那个attention,它的输出是M,也是长为D的向量。这里你的编码器的输出作为value和key进来,然后你的解码器下一层的输出,作为query进来,意味着是说对解码器的每一个输出,作为query,我要算一个我要的输出,假设我用蓝色来表示的话,那么你的输出是我们知道是来自于Value的一个加权和,那么就是来自于你的编码器它的输出的加权和。这个权重它的粗细程度,就是取决于我这个query跟这个东西的相似度。假设我这个东西,跟这个东西像素比较高的话,那么我的权重这个地方就会大一点,如果像似比较低的话,权重就会小一点。这就是这个attention干的事情。其实就是去有效的把你的编码器里面的一些输出,根据我想要的东西给它拎出来。举个具体的例子,假设你是在做英文翻译中文,我假设第一个词是hello,对应的向量是这个东西,然后我第二个词是hello word的话,那么你的中文它就是第一个当是你对吧 你好。所以你会知道说在算好的时候,如果它作为的时候,那么,去看哈的这个向量应该是会相近一点,给它一个比较大的权重,但是word这个是后面的词相关,我发现的word这个词跟我这个query相关度没那么高,在计算你的相似度的时候,那么就是说在算好的时候,我会给他一个比较大的权容在这一个上面。但是我在后面如果还有你好世界的话,如果是个世的话,那么在这个query的时候,我再去算它的输出这个东西的时候,它那么就会给第二个向量,给一个比较大的一个权重出来。意味着是说根据你在解码器的时候,你的输入的不一样,那么我会去根据你的当前的那一个向量去在编码器的输出里面去挑我感兴趣的东西,你就是你注意到你感兴趣的东西,那些没有跟你不那么感兴趣的东西,你就可以忽略掉它。
这个也是说attention是如何在编码器和解码器之间传递信息的时候起到的一个作用,这样我们就讲完了3个attention,它到底是在干什么事情。
接下来我们要去讲蓝色这个feed forward是在干什么东西。3.3节,讲的就是这个名字很长的position-wise feed-forward network,他说它其实就是一个full connected network,它就是一个MLP了。但是它不一样的是说它是apply each position separately and identically。position是什么东西?就是你输入的那一个序列,不是有很多个词,每一个词它就是一个点,它就是那一个position。那他就是把一个MLP对每一个词作元音词,然后对每一个词作用的是同样一个MLP,所以这个就是point wise的意思。它说白了就是MLP只是作用在最后一个维度,具体来看一下它是怎么写的。
![]()
这个地东西大家认识对吧,就是一个线性层,max到这个东西就是一个relu的激活层,然后再有一个线性层。我们知道在我们的注意力层,它的输入,每就每一个query,它对应的那一个输出,它是成为512。那么就是说这个xt,就是一个512的一个向量,他说w1我会把512投影成2048这个维度,就等于是我把它的维度扩大了四倍。因为最后你有一个参差连接,你还得投影回去,所以w2,又把2048投影回了512。所以这个东西说白了就是一个单隐藏层MLP,然后中间隐藏层把你的输入扩大四倍,最后输出的时候也回到你输入的大小。你用pytorch来实现的话,它其实就是把两个线性层放在一起,你都不需要改任何参数,因为输入是一个3D的时候,它默认就是要最后一个维度做计算。
为了更好的理解,我们用图把attention这个东西给大家画一下,以及说它跟我们之前的RNN它的区别在什么地方。
我们这里还是考虑一个最简单的情况,就是没有参差连接,也没有layer,然后你的attention,也是一个单头,然后没有投影,我我们知道我们的输入,就是一个长为N的一个一些向量,我们画在这个地方。在进入attention之后,我们就会得到同样长度的一些输出,在这个地方,在最简单的情况台,其实说白了就是对你的输入做一个加权的和,对吧。然后加权和之后,我们进入我们的MLP,就是那个position wise的MLP。我们把它画在这个地方,我们写个MLP。虽然我们画了几个东西,但其实它就一个,就是说每一个红色方块之间的权重是一样的,然后每个MLP对每一个输入的点做运算会得到一个输出,最后是得到整个transformer块的一个输出,是这样子。虽然它的输入和输出都是大小都是一样的,所以这个地方你看到的是说attention起的作用是什么东西,它就是把整个序列里面的信息抓取出来,做一次汇聚aggregation。

所以这个东西已经就有了我序列中感兴趣的东西,性已经抓取出来了。以至于我在做投影,在做MLP的时候,映射成我更想要的那个语义空间的时候,因为这个东西已经含有了我的序列信息,所以每个MLP只要在对每个点独立做就行了。因为历史信息,序列信息已经被汇聚完成,所以这个地方是可以分开做的,也就是整个transformer是如何抽取序列信息,然后把这些信息加工成我最后要的那个语义空间那个向量的过程。
作为对比,我们看一下RNN是怎么做的。我们知道RNN的输入跟你一样,就是一些向量。然后对于第一个点,说白了你也就是做一个线性层,我们做一个最简单的就是一个,没有隐藏层的MLP,就是一个呈线性的层,第一个点就是直接做出去就完事了。
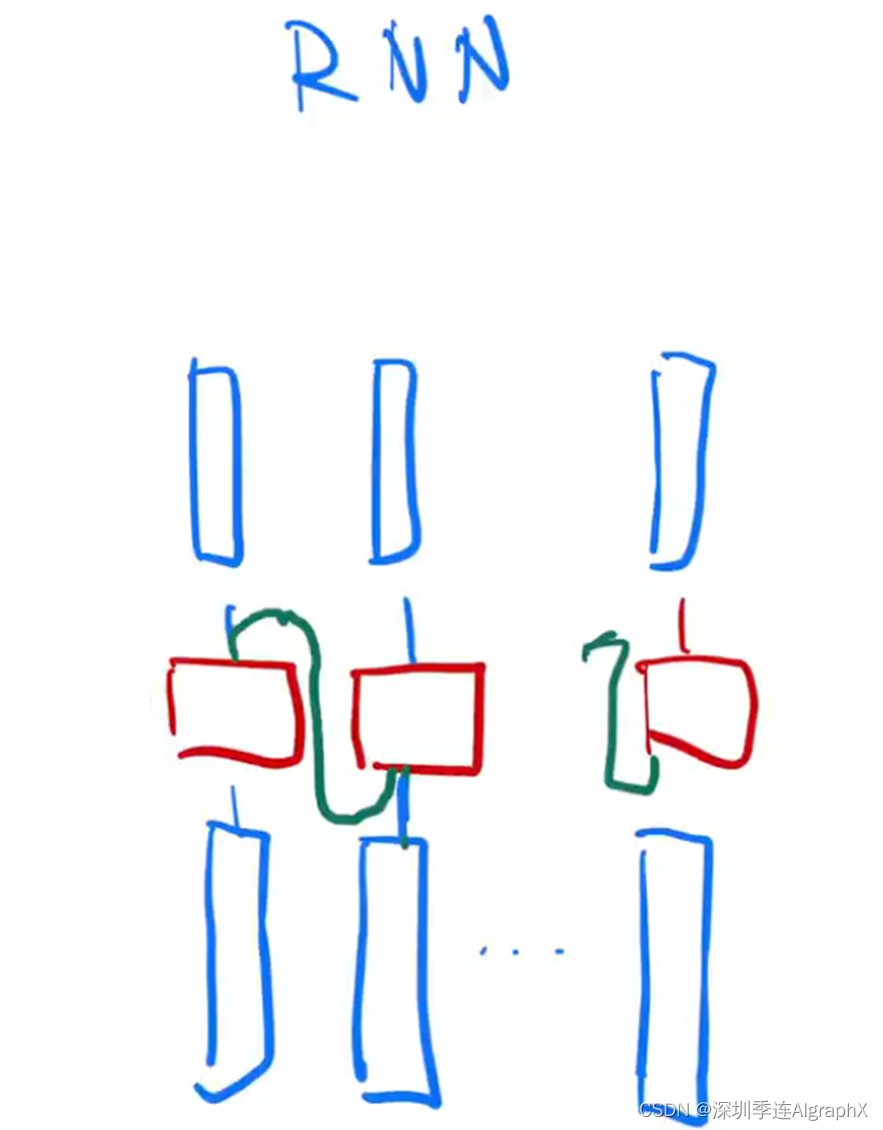
对于下一个点,我是怎么样利用我的序列信息的?我还是用MLP,它的权重跟之前是一样的。但是,我的时序信息,我用绿色表示,它就是把这个东西它的上一个时刻的输出放回来,作为跟输入一起并入进去,这样子我就完成了我信息的一个传递。然后用绿色的线表示的之前的信息,蓝色的线表示的是我当前的信息,这样子我会得到一个当前的一个输出。历史信息就是上一次的那个输出作为历史信息进来,然后得到我当前的一个输出。所以可以看到是说RNN跟transformer是一样的,都是用一个线性层,或者说一个MLP来做一个语义空间的一个转换,但是不一样的是你如何传递序列的信息。RNN是把上一个时刻的信息输出传入,到下一个时刻做输入。在transformer里面,它是通过一个attention层,然后在全局的去拿到整个序列面信息,然后再用MLP做语义的转换,这个是两个模式之间的区别。它的关注点都是在于你怎么有效的去使用你的序列的信息。
后续实验内容展示,现在大家都知道Transformer能做很多事情,本文不赘述。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!