计算机原理(1)计算机寄存器 汇编语言 内存访问
文章目录
前言
这一篇文章主要是想和大家探讨以下几个问题:
1、汇编语言与机器码的前世今生
2、8086计算机中的通用寄存器,段寄存器,代码段,数据段,内存的物理地址这些奇奇怪怪的概念是什么?
怎么得来的?
3、CPU如何区分指令与数据,指令与数据的概念是怎样产生的?
4、计算机中的特定概念,有的是从内存角度出发的,有的是从处理器角度出发的,出发角度不同,
硬件结构就不同,相应的在硬件结构之上的软件应用就不同,概念如何影响硬件,硬件又是如何影
响软件的呢?
一、汇编语言与机器码的前世今生?

1、CPU为什么只对0和1情有独钟?
在CPU的神秘世界里,唯一的语言就是0和1,CPU除了0和1谁也不认识,这里的认识是要划上引号的,认识是我们人类世界的语言,对于CPU来说它认识0和1,是因为CPU本身就是由若干个晶体管组成,这些晶体管之间的连接关系决定了CPU的功能,晶体管就是一个开关,晶体管到底是导通还是截止就是由我们输入的0或者1决定的,我们就是在已知CPU功能的前提下,通过输入改变晶体管的状态,进而通过CPU实现我们的功能。这里的0和1并不是我们的阿拉伯数字0和1,指的一个电压范围,例如:若逻辑电平“1”的范围是2.0V-3.3V,那落在这个区间内的电压都是1。

这个过程就好比做饭炒菜,CPU就相当于炒菜锅,我们所输入的0/1的组合就相当于是炒菜的原材料,比如西红柿、鸡蛋,又或者是青椒,猪肉片,但是总不能把生米放进去,希望可以像电饭锅一样,蒸出一锅香香的大米饭,毕竟功能不允许,所以CPU只认0/1,0/1指的就是引脚所接的高低电平。
2、汇编与机器码的关联
机器码是CPU的语言,但是咱们读起来费劲啊,因为它并不符合我们的思考习惯,而且我们如果直接输入机器码,非常容易错,比如在显示器中输出“welcome to masm",机器码如下:


一旦一个1被误写成0,怎么去查找呢?太麻烦了,举个例子:你想吃好的猪肉,现在只需要认准几个知名的猪肉品牌,去买品牌猪肉质量基本就没有问题,难道我们还要去看猪的养殖过程,猪肉的运输过程嘛,这就是符号的作用,一个符号后面隐藏着很多信息,当我们选择这个符号时,也就自然获取了符号后的信息,汇编也一样,机器语言太麻烦,难于辨别和记忆,汇编与机器指令的本质区别就是指令的表示方法;

例如:机器指令1000100111011000代表把寄存器BX的内容送到AX中,汇编指令:
mov ax,bx;
机器指令:1000100111011000
两者对比,高下立见,这里强调一点:汇编语言的指令种类是依据CPU的硬件结构而来的,例如:100010这一组机器码代表加的操作,对应汇编语言中的关键字add,100010之所以能对应add是因为CPU有一个译码器,当译码器识别到100010这一组数据的时候,相应寄存器中的数据就会执行加法操作,从而实现了数据相加的操作,所以编程语言永远是依托于硬件来开发的!
二、CPU如何实现对内存的访问
8086CPU有20根地址总线,达到1MB寻址能力,但是从8086CPU的内部结构来看,如果将地址从内部简单地发出,那么它只能送出16位的地址,表现出的寻址能力只有64KB;所以8086CPU采用两个16位地址合成的方法来形成一个20位的物理地址。
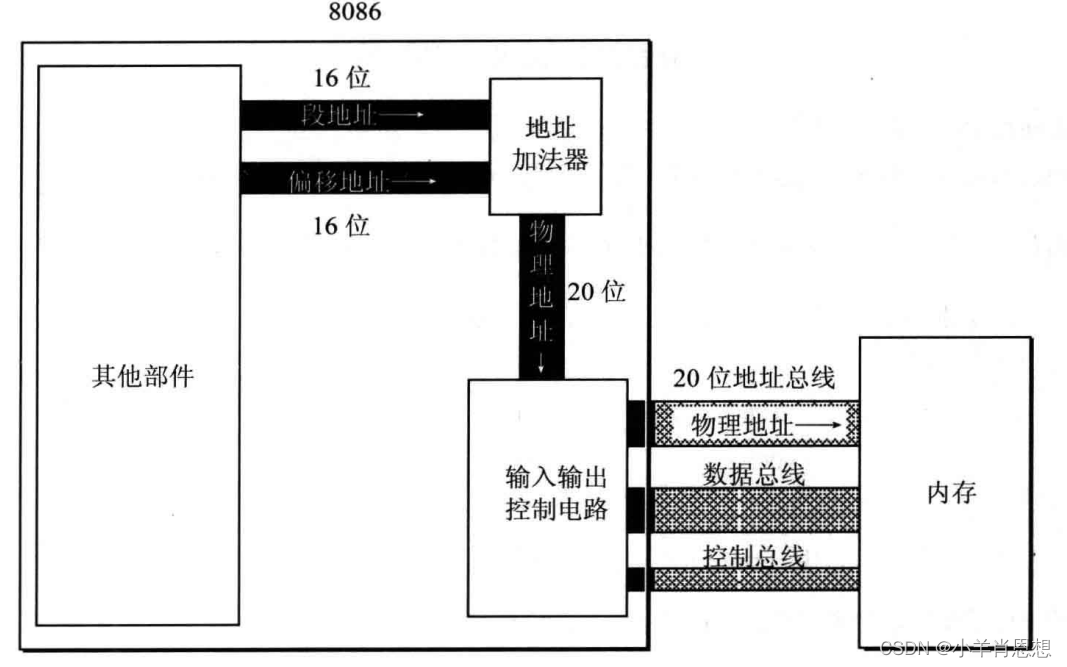
地址合成之所以能扩大寻址范围,是因为二进制计数这种计数方法的核心是采用高位在左、低位在右的位值计数法,位置决定数字的意义。如果不是采用这种计数方法,例如采用划计法,选举时候写的正字,那么通过地址合成来扩大寻址范围这个概念也就不存在了。
三、内存物理地址的实现原理在其他方面的体现
8086CPU内存物理地址的寻址模式本身就是由于寄存器位宽不够,采用物理地址=段地址x16+偏移地址的方式,实现内存的寻址需求,这种原理与Verilog的位拼接符原理一致,例如:想要输出一个8位宽的信号out,手里只有4位宽的信号in1/in2,采用拼接运算符进行拼接操作,assign out = {in1,in2};这个原理也与数字电子技术中存储容量的扩展类似;
例如:位扩展(增加存储字长),1Kx4位 存储芯片组成,1Kx8位的存储器,地址线共用,读写控制线和片选线连接在一起;
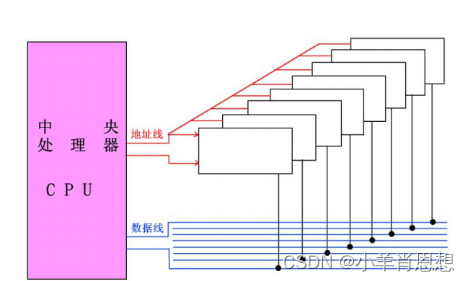
例如:字拓展是通过增加地址线实现了存储尺寸的拓展,一般来说是连多个芯片 (字扩展的芯片是互斥工作方式,每次访问时只有一个芯片工作)

四、CPU的寻址模式在生活中的体现
CPU的这种基础地址加上偏移地址寻址模式的原理在生活中也有体现,例如:人民币,你去超市买一瓶酱油,售价为5元,你可以
使用一张5元的人民币,也可以使用5张1元的人民币,或者是一张2元的与3张1元的,有多种方式可以实现,内存寻址也是一样,内存物理地址确定,可以有多种基础地址与偏移地址的组合方式。
五、CPU如何区分指令与数据,指令与数据的概念是怎样产生的?
指令、数据、代码段、这些概念我们肯定都听过,但是今天想要和大家探讨的是这些概念是相对于谁而言的!!!在我们使用计算机的过程中涉及到多个视角,例如:CPU视角、内存视角、用户视角等,以内存地址空间来说:就是CPU视角,内存地址空间是一个抽象的概念,会受到CPU寻址能力的限制,例如一个MCU的外设有uart、spi、flash等,CPU要访问这些外设就需要去区分这些外设,给每一个外设一个特有的标志,这个标志符号就代表这个外设,地址空间就是这个原理,例如uart:0x0000-0x0111,这个地址空间就代表了uart,再说指令与数据也是相对于CPU视角去阐述的,内存没有指令与数据这个概念,指令与数据是在CPU执行过程中出现的概念,再说代码段,代码段又是以用户视角来说的,我们在写程序的时候,指定某一段内存作为代码段的放置位置,这些概念一定要理解是从哪个视角,从哪个视角衍生出来的概念,我们就可以相应的学习到这个概念的本质原理,一句话从哪来的很重要!
六、结论
1、本文第一部分主要说明从机器码到汇编语言的演变,汇编语言的优点,这里没有过多介绍太多的汇编指令,因为我感觉汇编指令,用到什么去网上查找就好啦,汇编语言就是少的助记符代替更多的机器码,这个原理与C语言中的子函数类似,汇编指令的类型也是基于CPU的硬件结构设计的,软件是基于硬件的,汇编指令也便于我们理解与记忆;无论是汇编语言还是操作系统本质上都是为了方便我们机器进行沟通,不同地方的人对一个事物的理解都不一样,更别说人与机器了,所以才会逐渐演变出更高级的语言;
2、第二部分主要说明CPU访问内存的寻址模式,这部分是想和大家深入探讨这种地址合成寻址模式的本质原理,CPU有多种寻址模式,每一种都有自身的特点,希望以一种寻址模式的理解作为锚点,继续深入理解其他寻址模式;
3、第三部分主要说明一些计算机中的概念,例如指令、数据、地址空间这些概念是哪个视角衍生出来的,还是那句话只有了解它是从哪里来的,才有可能真正的理解它!
七、参考资料
本文主要参考了王爽老师的汇编语言,大话数据结构,计算机是怎样跑起来的,程序是怎样跑起来的等书籍,部分图来源于王爽老师的汇编语言;
八、交个朋友
说到计算机我是有一种深不可测的感觉,感觉这岂能是我等小菜鸟可以学懂,本文中插入了许多图片,博主希望大家想到计算机原理这部分知识的时候,可以想到这些图片,以这些图片作为锚点,不再是感觉计算机是那么的晦涩难懂,文中有一些内容是博主自己的理解,可能不太准确,欢迎大家批评指正!后续文章会详细深入介绍指令、数据、寄存器、中断等等,以这个文章的写作方式作为锚点,还是会从视角以及一个概念的诞生为主要内容去阐述,以一个概念作为一个文章的主题,详细介绍,希望能给大家带有有知识体系的计算机原理方面的文章!

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!