论文阅读: Semantics-guided Triplet Loss
ICCV 2021
Abstract
- 一个度量学习方法,通过浏览语义引导的局部集合去优化内在深度表示。
- 一个新颖的特征融合模块能有效利用跨模态特异质特征。
Senantics-guided Triplet Loss
基本假设:
- 在场景语义分割图像中,目标内部相邻像素拥有同样的深度值,而跨目标边界上深度值变化很大。
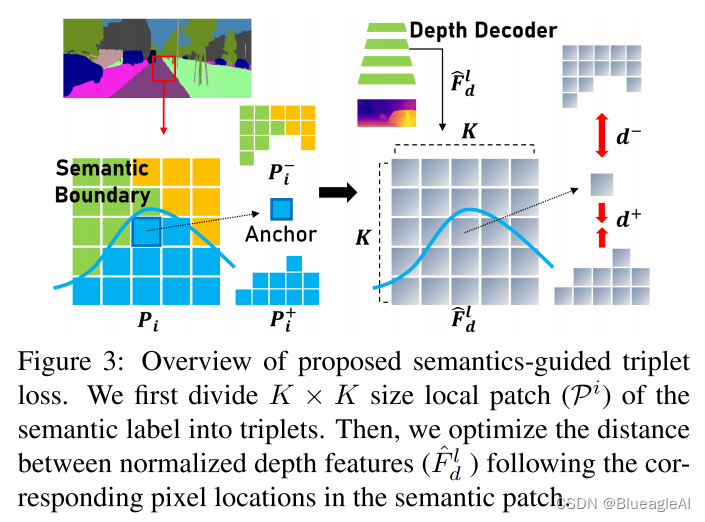
方法:
-
将语义图像分割成KxK大小的块,stride为1。在每一个块,中心点为anchor,与anchor有相同标签的点为positive 像素 P i + P_i^+ Pi+?,反之为Negative像素 P i ? P_i^- Pi??。
-
如果 ∣ P i ? ∣ |P_i^-| ∣Pi??∣=0,则 P i P_i Pi?位于目标内部,若 ∣ P i ? ∣ |P_i^-| ∣Pi??∣和 ∣ P i + ∣ |P_i^+| ∣Pi+?∣都大与0,意味着 P i P_i Pi?跨域了边界。
-
对正负距离的定义:
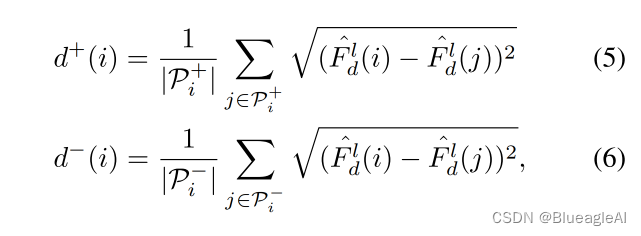
-
目的在于减少anchor与正样本的距离增加与负样本的距离。
-
然而目标间的深度变化并非必然的远,因此当负距离超过正距离一定程度,设置一个超参:
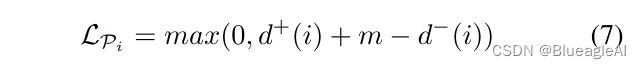
-
semantics-guided triplet los L S G T L_{SGT} LSGT?是 L p i L_{p_i} Lpi??的均值,但只包含满足条件: ∣ P i ? ∣ |P_i^-| ∣Pi??∣和 ∣ P i + ∣ |P_i^+| ∣Pi+?∣都大于T。
(To be continued)
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!