TextDiffuser-2:超越DALLE-3的文本图像融合技术
概述
近年来,扩散模型在图像生成领域取得了显著进展,但在文本图像融合方面依然存在挑战。TextDiffuser-2的出现,标志着在这一领域的一个重要突破,它成功地结合了大型语言模型的能力,以实现更高效、多样化且美观的文本图像融合。

-
Huggingface模型下载:https://huggingface.co/JingyeChen22/textdiffuser2_layout_planner
-
AI快站模型免费加速下载:https://aifasthub.com/models/JingyeChen22/textdiffuser2_layout_planner
技术革新
-
布局生成的自动化与灵活性:TextDiffuser-2采用了vicuna-7b-v1.5模型进行微调,有效解决了布局生成的自动化问题。用户通过简单的指令即可引导模型生成所需的文本布局,大大提高了操作的便捷性。
-
布局编码机制的优化:TextDiffuser-2在Stable Diffusion 1.5模型的基础上,引入了额外的坐标token和字符token,使得模型能够更准确地学习特定位置的文本内容。这一机制的改进,为生成更精确且多样的文本图像提供了可能。
-
高质量数据集的应用:使用了MARIO-10M数据集进行微调,通过实验探索了文本行的不同表示方式,包括单点表示和角度条件,进一步丰富了文本渲染的多样性。

性能比较
-
与DALLE-3的对比:TextDiffuser-2在处理复杂的文字提示方面表现出色,与DALLE-3相比,它在渲染文本内容的准确性和背景区域的协调一致性方面具有明显优势。
-
风格字体生成能力:TextDiffuser-2特别擅长生成特定风格的字体,如手写体和艺术体等。在可视化对比分析中,TextDiffuser-2的表现最为出色。
-
Text Inpainting任务性能:TextDiffuser-2在Text Inpainting任务上展现了明显的优势,生成的文本与背景的搭配更为协调,文本的风格与周围环境更加吻合。

定量评估
在定量实验中,TextDiffuser-2在多数评估指标上均展现出优异的性能。具体的评分数据显示,TextDiffuser-2在不同的视觉渲染任务中均取得了领先地位。
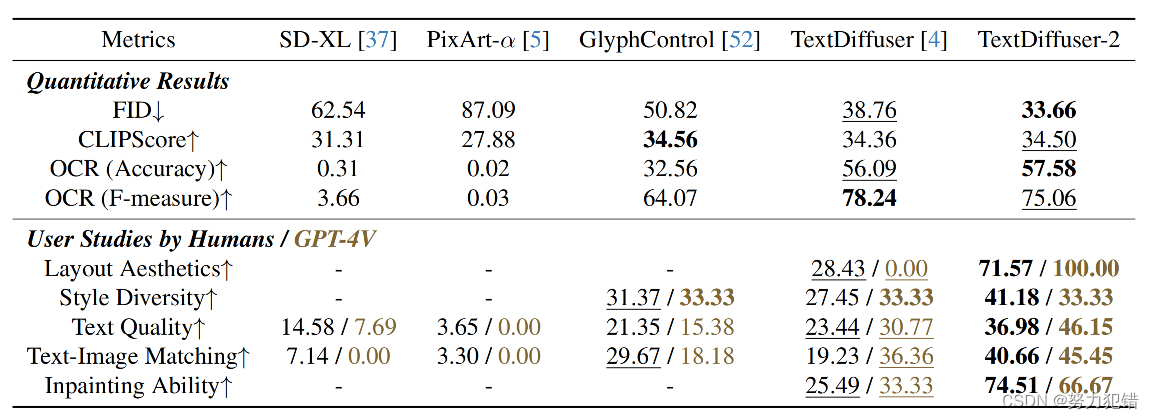
用户评测
我们采用GPT-4V进行用户评测。根据用户反馈,GPT-4V对TextDiffuser-2生成的图像进行了评估,结果表明其具有优异的识图识字能力,并总结的理由合理。
结论
TextDiffuser-2的推出,不仅在技术层面上实现了重大突破,也为未来的多模态AI研究提供了新的方向。通过将先进的语言模型与图像生成技术相结合,TextDiffuser-2在文本图像融合领域设置了新的标准,其应用前景广阔。
未来展望
TextDiffuser-2虽已取得显著成就,但在复杂语言渲染的挑战面前,仍有进一步提升的空间。未来的工作将着重于探索多种语言字符的渲染能力,并提高生成文本图像的分辨率,以满足更多样化的应用需求。
模型下载
Huggingface模型下载
https://huggingface.co/JingyeChen22/textdiffuser2_layout_planner
AI快站模型免费加速下载
https://aifasthub.com/models/JingyeChen22/textdiffuser2_layout_planner
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!