(Python + Selenium4)Web自动化测试自学Day1
2024-01-09 17:30:12
目录
文章声明???
- 该文章为我(有编程语言基础,非编程小白)的 Python Selenium4 Web自动化测试自学笔记
- 知识来源为 B站UP主(软件测试老白)的Python Selenium4课程视频,归纳为自己的语言与理解记录于此并加以实践
- 不出意外的话,我大抵会 持续更新
- 想要了解前端开发(技术栈大致有:Vue2/3、微信小程序、uniapp、HarmonyOS、NodeJS、Typescript)与Python的小伙伴,可以关注我!谢谢大家!
让我们开始今天的学习吧!
自动打开Chrome浏览器
运行代码,自动打开Chrome浏览器并进入B站,持续两秒,代码如下:
# 相关导入
import time
from selenium.webdriver import Chrome
if __name__ == '__main__':
# 实例化浏览器对象
web = Chrome()
# 全屏
web.maximize_window()
# 使用get方法进入网站
web.get('https://www.bilibili.com/')
# 持续两秒
time.sleep(2)
# 关闭浏览器,selenium4加不加close方法都会关闭浏览器
web.close()
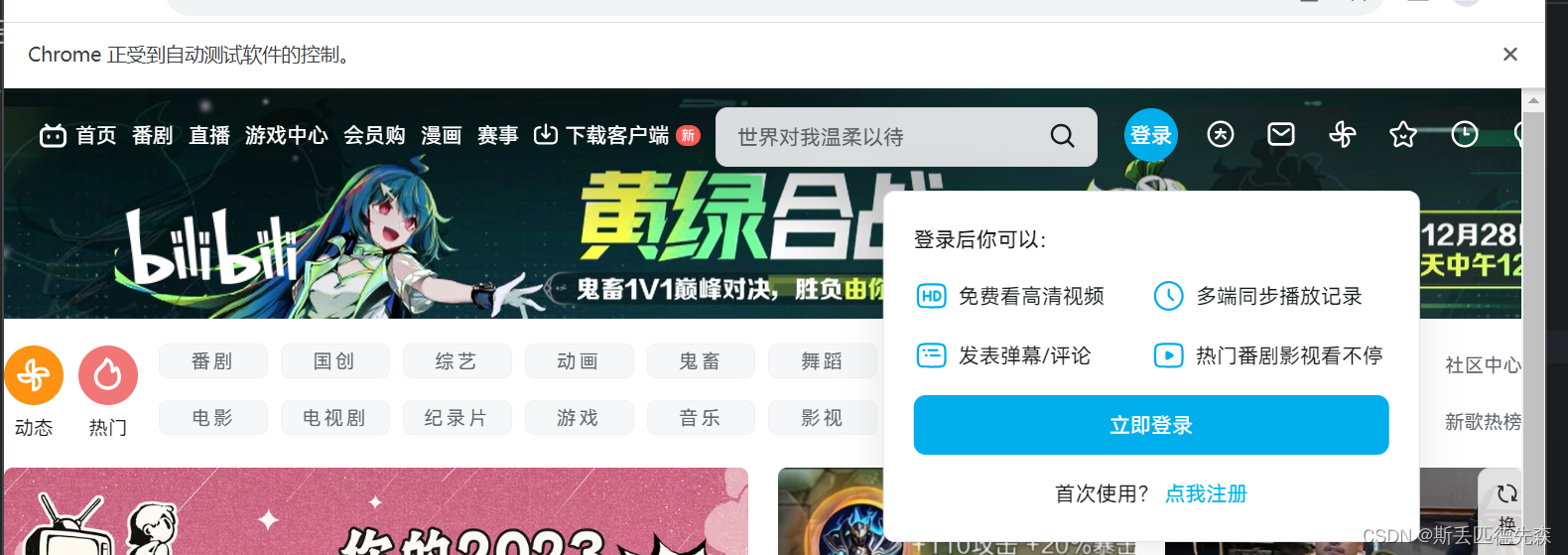
不出意外,浏览器自动打开并停留在了B站首页两名后,自动关闭,浏览器顶部还提示:Chrome正受到自动测试软件的控制,如下图所示:
实现自动搜索
我们的需求是:打开Chrome浏览器,并在搜索输入框输入Python关键词进行搜索,代码如下:
# 相关导入
import time
from selenium.webdriver import Chrome
from selenium.webdriver.common.by import By
if __name__ == '__main__':
# 实例化浏览器对象
web = Chrome()
# 全屏
web.maximize_window()
# 使用get方法进入网站
web.get('https://www.bilibili.com/')
# 找到输入框的位置,然后输入关键词:Python
web.find_element(By.CLASS_NAME, 'nav-search-input').send_keys('Python')
# 找到搜索按钮的位置,点击搜索
web.find_element(By.CLASS_NAME, 'nav-search-btn').click()
# 持续五秒
time.sleep(5)
# 关闭浏览器,selenium4加不加close方法都会关闭浏览器
web.close()
元素定位
常用的元素定位方式
- By.ID
- By.CLASS_NAME
- By.TAG_NAME
- By.NAME
- By.LINK_TEXT
- By.PARTIAL_LINK_TEXT
- By.CSS_SELECTOR
- By.XPATH
By.ID
# 相关导入
import time
from selenium.webdriver import Chrome
from selenium.webdriver.common.by import By
if __name__ == '__main__':
# 实例化浏览器对象
web = Chrome()
# 全屏
web.maximize_window()
# 使用get方法进入网站
web.get('https://www.baidu.com/')
# 通过ID,定位到输入框
element = web.find_element(By.ID, 'kw')
# 输入框输入内容
element.send_keys('selenium')
# 持续五秒
time.sleep(5)
# 关闭浏览器,selenium4加不加close方法都会关闭浏览器
web.close()
By.CLASS_NAME
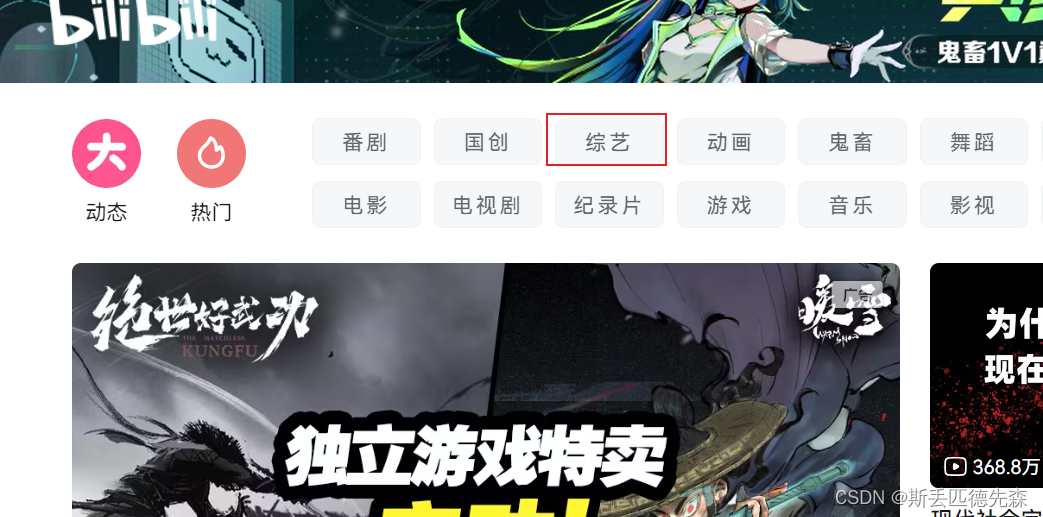
想要定位到如图按钮:
使用 find_element(By.CLASS_NAME) 进行第一次尝试:
# 相关导入
import time
from selenium.webdriver import Chrome
from selenium.webdriver.common.by import By
if __name__ == '__main__':
# 实例化浏览器对象
web = Chrome()
# 全屏
web.maximize_window()
# 使用get方法进入网站
web.get('https://www.bilibili.com/')
# 因为很多标签大概率会拥有相同的class
# 而通过find_element(By.CLASS_NAME)定位到多个拥有相同class的元素时,默认选取第一个
# 所以下面这一行代码不可取
web.find_element(By.CLASS_NAME, 'channel-link').click()
# 持续五秒
time.sleep(5)
# 关闭浏览器,selenium4加不加close方法都会关闭浏览器
web.close()
使用 find_elements(By.CLASS_NAME) 成功运行:
# 相关导入
import time
from selenium.webdriver import Chrome
from selenium.webdriver.common.by import By
if __name__ == '__main__':
# 实例化浏览器对象
web = Chrome()
# 全屏
web.maximize_window()
# 使用get方法进入网站
web.get('https://www.bilibili.com/')
# 定位到综艺按钮并点击
web.find_elements(By.CLASS_NAME, 'channel-link')[4].click()
# 持续五秒
time.sleep(5)
# 关闭浏览器,selenium4加不加close方法都会关闭浏览器
web.close()
途中我通过Debug查询到了索引值:

注意,当遇到有多个class值的标签时,例如:

不可以使用整个"recommended-swipe grid-anchor"作为 find_elements() 方法的第二个参数使用,会报错
By.TAG_NAME
- 不常用,常用于定位在整个页面中数量极其少的元素
- 可以配合F12的Console使用,即先查询该标签在整个页面的数量多或少、索引值为多少,再使用 By.TAG_NAME 去定位该元素
- 用法同 By.CLASS_NAME,这里就不予演示
By.NAME
- name属性常出现于HTML里的表单元素
- 用法同 By.CLASS_NAME 一样,这里就不予演示
By.LINK_TEXT
适用于查询链接元素
定位如下图元素:
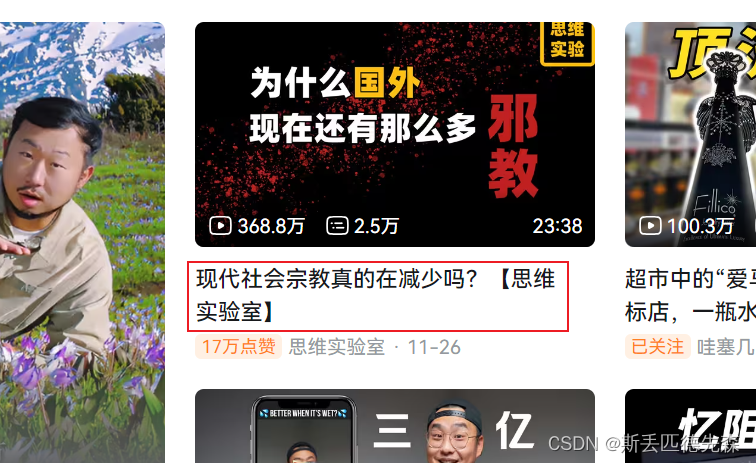
标签如图:

代码如下:
# 相关导入
import time
from selenium.webdriver import Chrome
from selenium.webdriver.common.by import By
if __name__ == '__main__':
# 实例化浏览器对象
web = Chrome()
# 全屏
web.maximize_window()
# 使用get方法进入网站
web.get('https://www.bilibili.com/')
# 定位元素并点击,第二个参数只需要链接文本即可
web.find_element(By.LINK_TEXT, '现代社会宗教真的在减少吗?【思维实验室】').click()
# 持续五秒
time.sleep(5)
# 关闭浏览器,selenium4加不加close方法都会关闭浏览器
web.close()
By.PARTIAL_LINK_TEXT
使用方法同 By.LINK_TEXT ,只不过 find_element() 和 find_elements() 第二个参数:链接文本,变为了模糊查询,即网页里的链接文本包含该参数的值即可查询定位,用 By.LINK_TEXT 的例子来演示:
代码如下:
# 相关导入
import time
from selenium.webdriver import Chrome
from selenium.webdriver.common.by import By
if __name__ == '__main__':
# 实例化浏览器对象
web = Chrome()
# 全屏
web.maximize_window()
# 使用get方法进入网站
web.get('https://www.bilibili.com/')
# 定位元素并点击,这里的第二个参数包含在链接文本里即可
web.find_element(By.PARTIAL_LINK_TEXT, '现代社会宗教真的在减少吗').click()
# 持续五秒
time.sleep(5)
# 关闭浏览器,selenium4加不加close方法都会关闭浏览器
web.close()
By.CSS_SELECTOR
根据id定位
# 输入框标签:<input id="kw" name="wd" class="s_ipt" value="" maxlength="255" autocomplete="off">
# 搜索按钮标签:<input type="submit" id="su" value="百度一下" class="bg s_btn">
# 根据id定位输入框和搜索按钮,并输入内容后点击搜索按钮
web.find_element(By.CSS_SELECTOR, '#kw').send_keys('Python')
web.find_element(By.CSS_SELECTOR, '#su').click()
根据class定位
# 输入框标签(属性筛选了一部分):<input class="nav-search-input">
# 搜索按钮标签(属性筛选了一部分):<div class="nav-search-btn"></div>
# 根据class定位输入框和搜索按钮,并输入内容后点击搜索按钮
web.find_element(By.CSS_SELECTOR, '.nav-search-input').send_keys('Python')
web.find_element(By.CSS_SELECTOR, '.nav-search-btn').click()
根据属性定位
# 输入框标签:<input id="kw" name="wd" class="s_ipt" value="" maxlength="255" autocomplete="off">
# 根据name属性定位输入框
web.find_element(By.CSS_SELECTOR, '[name="wd"]')
# a标签(属性筛选了一部分):<a href="http://image.baidu.com/">图片</a>
# 根据href属性定位
web.find_element(By.CSS_SELECTOR, 'a[href="http://image.baidu.com/"]')
# 根据href属性模糊匹配-包含
web.find_element(By.CSS_SELECTOR, 'a[href*="baidu.com/"]')
# 根据href属性模糊匹配-匹配开头
web.find_element(By.CSS_SELECTOR, 'a[href^="http://image"]')
# 根据href属性模糊匹配-匹配结尾
web.find_element(By.CSS_SELECTOR, 'a[href$="baidu.com/"]')
组合定位
# 输入框标签(属性筛选了一部分):<input class="nav-search-input">
# 组合定位class
web.find_element(By.CSS_SELECTOR, 'input.nav-search-input')
# 输入框标签(属性筛选了一部分):<input id="nav-search-input">
# 组合定位id
web.find_element(By.CSS_SELECTOR, 'input#nav-search-input')
By.XPATH
# 绝对路径,从根节点开始选取
# web.find_element(By.XPATH, '/html/body/div/div/div[3]/a').click()
# 相对路径,从任意节点开始选取,经常配合属性定位选取标签,格式如下:
# web.find_element(By.XPATH, '//input[@id="kw"]').send_keys('ok')
# 多属性组合定位
# web.find_element(By.XPATH, '//input[@id="kw" and @name="wd" and @class="s_ipt"]').send_keys('ok')
# 多组数据使用下标定位
# web.find_element(By.XPATH, '//div[@id="s-top-left"]/a[4]').click()
# 定位某元素的父元素,使用/..表示某标签的父标签
# web.find_element(By.XPATH, '//div[@id="s-top-left"]/..').click()
# 文本等于
# web.find_element(By.XPATH, '//a[text()="文库"]').click()
# 文本包含
# web.find_element(By.XPATH, '//a[contains(text(),"文")]').click()
# 同级下方标签
# web.find_element(By.XPATH, '//a[text()="文库"]/following-sibling::a[3]').click()
# 同级上方标签
# web.find_element(By.XPATH, '//a[text()="文库"]/preceding-sibling::a[3]').click()
文章来源:https://blog.csdn.net/Richieeea/article/details/135290586
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!