索引与优化原理(上)
作者简介:大家好,我是smart哥,前中兴通讯、美团架构师,现某互联网公司CTO
联系qq:184480602,加我进群,大家一起学习,一起进步,一起对抗互联网寒冬
上一篇,我们重走了一遍数据库索引的历史,认识了B+树结构,这一篇我们回归现实中的MySQL数据库,初步学习具体的SQL优化原则,并尝试从索引底层原理出发,分析为什么会有那么多的“规则”。
为什么要学习SQL优化
我的前东家是做招聘服务的,所以不可避免地要查询行业分类。通常来说,前端可以采用根据parentId分步加载的方式获取行业类别,但有些场景也需要全量嵌套查询:查询行业分类及其子分类。
这里我们就假定直接查询所有分类及其子分类:

我自己设计了一个简单版的表结构,大概如下:

表中有1106条数据:

我们很容易写出以下代码:
/**
* 查询行业分类及其子分类
*/
@Test
public void testCascade() {
// 查询数据库,得到所有行业类别
List<SysPosition> sysPositionList = sysPositionMapper.selectAll();
long start = System.currentTimeMillis();
Map<String, SysPosition> sysPositionMap = new HashMap<>();
List<SysPosition> result = new ArrayList<>();
// 第一步:List转Map
for (SysPosition sysPosition : sysPositionList) {
sysPositionMap.put(sysPosition.getCode(), sysPosition);
}
// 第二步:遍历List,利用Map完成嵌套
for (SysPosition sysPosition : sysPositionList) {
if ("-1".equals(sysPosition.getParentCode())) {
result.add(sysPosition);
} else {
SysPosition parent = sysPositionMap.get(sysPosition.getParentCode());
parent.getChildren().add(sysPosition);
}
}
long end = System.currentTimeMillis();
System.out.println("耗时:" + (end - start));
}我们分析过效率:List转Map这种方式会有2N次循环,也就是会循环2212次。
大家猜上面程序耗时多少?
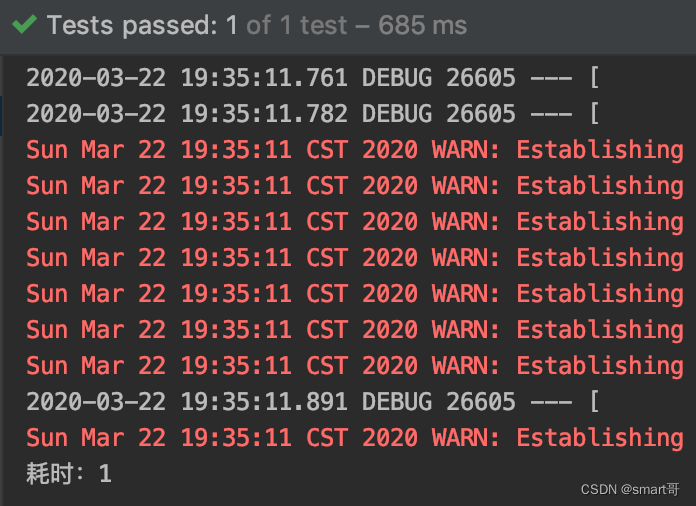
只需1毫秒。
对于CPU来说,计算内存中的数据是非常快的,几千次的循环基本可以忽略不计。
你们想知道之前我们测试的第一版算法耗时多少吗?测一下:
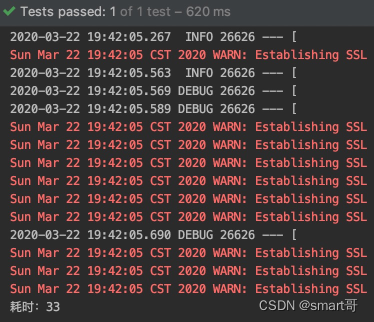
也只要33毫秒。
要知道,第一版算法在这种情况下可是循环了1106*1106 = 100w+次!!但是对于CPU来说,不足挂齿。当然,这是单次调用的差距,想象一下这个接口每天要被几十万、甚至几百万用户调用,累计差距还是很可观的。
通过上面的案例,我想说的是:绝大多数情况下,内存中数据的处理耗时几乎可以忽略不计。
大家有没有发现,上面的程序并没有把Mapper查询数据库的操作计入时间?数据库select操作会很耗时吗?
我在某网站的专栏中看到过关于数据库insert的一段话:
插入行所需的时间由以下因素决定(参考MySQL 5.7参考手册:8.2.4.1优化INSERT语句)
- 连接:30%
- 向服务器发送查询:20%
- 解析查询:20%
- 插入行:10% * 行的大小
- 插入索引:10% * 索引数
- 结束:10%
可发现大部分时间耗费在客户端与服务端通信的时间,因此可以使用 insert 包含多个值来减少客户端和服务器之间的通信。我们通过实验来验证下一次插入多行与一次插入一行的效率对比。
上面虽然说得是insert,但select的情况其实也差不多。现在我把Mapper查询的时间也包括进来:

竟然暴增到496毫秒!!
好了,这个例子告诉我们,网络请求(以及IO操作)是非常耗时的操作,我们应该尽量避免在循环中调用网络请求或进行IO操作,比如:
这是非常差劲的写法。
OK,到这里大家应该能形成一个认知:一次正常的请求,最可能出现性能瓶颈的地方就是网络请求及IO操作(通常而言性能瓶颈往往出现在数据库)。
要想优化数据的查询,大方向有两个:
- 优化关系型数据库本身,比如增加索引等
- 借助大数据和ES,转嫁查询压力(本质已经和关系型数据库无关了)
对于一般小公司而言,大数据和ES还是稀罕物,所以当我们讨论性能优化时,SQL优化几乎是重点!和SQL的性能提升相比,代码的优化有时是微不足道的。即使有优化,归根到底其实还是减少、减小对数据库的请求。大家应该要感到高兴,因为你们终于也将登堂入室,要去探索SQL优化了。
没有特殊情况的话,本文讨论的内容都是基于InnoDB引擎
在我看来,对于一般的Java开发而言,SQL优化分为几个层次:
- 索引优化 70%
- 事务及锁 20%
- 读写分离等 10%
其中,索引优化是最重要、也是一般Java开发人员最常用的手段。
索引的类型
索引的分类可能有不同维度,这里不追求特别准确的分类,毕竟不是做学术,只要感性认识几种即可。
打开Navicat,尝试创建索引时会发现有4种索引类型可以选择:
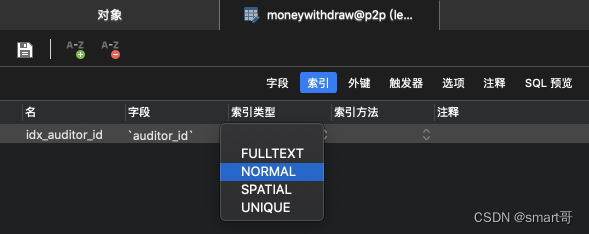
- 全文索引
- 普通索引
- 空间索引
- 唯一索引
普通索引就可以组织树结构了,而唯一索引在普通索引的基础上还要求索引列不能重复。比如,假设我们给student表的name列加了唯一索引,如果表中已经存在"张三",那么再次插入"张三"将会报错。
MySQL这种关系型数据库并不适合进行全文检索(考虑Elastic Search),所以全文索引一般很少使用。
至于空间索引,我也不知道是什么。
实际开发常用的索引只有普通索引和唯一索引,其他的可以不用理会(主键索引其实相当于唯一索引+非NULL)。
索引的实现方式
常见的索引实现方式有两种,通过B+树结构或hash算法实现。
特别注意,这里虽然写的是"BTREE",但MySQL确实使用的是B+Tree。
这个概念,其实和上面“索引的类型”并不冲突。
比如,对于普通索引,我们可以使用B+树的结构组织索引,也可以使用hash算法实现。经过上一篇的学习,我们对B+树结构已经比较了解,所以这里单独聊一下hash索引。
所谓hash索引,其实就是利用哈希算法为索引列计算得到唯一的存储地址,一般来说这个地址是不会重复的(重复的情况被称为哈希冲突)。
举个燕十八老师说的例子:

在墙上装一根弹性永不衰变的弹簧,每次拿不同的物件把弹簧压到极限后放开,不同的物件最终落点会不同。比如你上回存了一本书,那么下次想要找到这本书时,只需要拿一本一模一样的书重新弹一下,即可在本次落点处找到上次那本书。
数据库hash索引的设计也类似,假设你要存入id=10086的数据,就需要通过hash算法对id进行计算,得到一个存储位置后写入数据。下次拿着id=10086查询时,只要按同样的算法再次计算,就能马上找到对应的数据,是不是很快呢~
需要注意的是,弹簧的例子用来比喻hash算法虽然挺形象的,但可能会让人误以为越重的物品落点越近,越轻的物品落点越远,进而得出结论:hash索引可以进行范围查找。
其实并不是如此。
hash算法有个比较显著的特征:即使源数据具备一定的相关性,经过hash映射后得到的结果也会变得“很散”,没有规律可循。回到之前的例子中,你可以理解为重量并不是影响书本最终落点的唯一因素,书的材质、形状等都占有一定比例,最终体现到空气阻力上导致落点的不规则。

不知道大家还是否记得,在JavaSE阶段接触HashMap时,很多人会发现put的顺序和get的顺序并不一定相同。比如put的顺序是1000克、500克、300克,而get的顺序却是500克、300克、1000克。也就是说,经过hash计算后,数据的相关性会大大减弱。
所以,当你希望查找500g~1000g的书本时,就无法利用边界值进行范围查找。而B+树叶子节点是有序链表,范围查询非常方便。
hash索引除了无法进行范围查找外,还不能进行模糊搜索。
hash算法本身代表着精确定位,依赖于计算的入参得出“唯一”的值,所以无法进行模糊匹配。比如,你给我"bravo",我可以计算唯一的hash值,你给我"bra%",我会以为这人就叫"bra%",也计算一个值,而这个值代表着"bra%"计算得到的落点,而不是"所有以bra开头的数据"的落点,显然是不对的。
但B+树可以进行模糊搜索,你可以姑且认为因为它会顺着树查找,并在装有数据的节点内调用类似Java的String#startWith()方法进行比较。
hash索引的优劣势
- 优势:速度非常快,只需一次计算即可得到地址,时间复杂度O(1),而B+树是O(logn)
- 劣势:不支持模糊查询、范围查询、索引排序(本身就是不规则的,如何利用索引排序呢)
最后,List转HashMap的操作其实就是借鉴了hash索引!
索引的创建
索引的创建时机一般有两处:
- 起初,建表时顺便建立索引
- 后期,修改表结构创建索引(一般都是这样,因为很难未卜先知,提前优化等于瞎优化)
比如,一开始就创建索引:
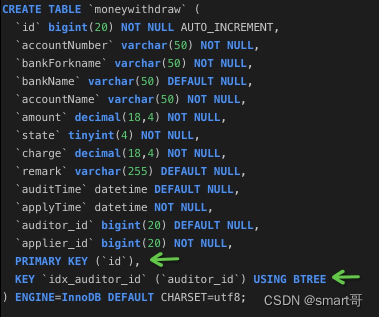
这张表有两个索引:主键索引、auditor_id普通索引。
主键索引并不属于上面介绍的4种索引类型之一,但所谓的Primary Key可以看做 唯一索引 + NOT NULL约束。
后期如果需要添加索引,可以通过两种方式:
- SQL语句
- Navicat图形界面
利用SQL语句添加索引:
-- 1.添加PRIMARY KEY(主键索引)
ALTER TABLE `table_name` ADD PRIMARY KEY (`column`) ;
-- 2.添加UNIQUE(唯一索引)
ALTER TABLE `table_name` ADD UNIQUE (`column`);
-- 3.添加INDEX(普通索引)
ALTER TABLE `table_name` ADD INDEX index_name (`column`);
-- 4.添加FULLTEXT(全文索引)
ALTER TABLE `table_name` ADD FULLTEXT (`column`);
-- 5.添加联合索引
ALTER TABLE `table_name` ADD INDEX index_name (`column1`, `column2`, `column3`);在本案例中,可以写:
ALTER TABLE `moneywithdraw` ADD INDEX idx_auditor_id (`auditor_id`);利用Navicat图形界面创建单列索引:

利用Navicat图形界面创建联合索引:

哦,对了,数据量太大的表,不要自己随便加索引,搞不好会锁表哦...后面有机会再说。总之,你可以“懂索引”,但要“动索引”前,最好三思。
索引的好与坏
提到索引,很多人就会说:哦,索引能提高查询速度。一般这么说的人,可能学得还不错,但绝对还没有完全掌握索引的底层原理。
如果你认为索引的优势只是加快查询,那就太小看索引了。
索引的优势是:
- 加快查询速度(包括关联查询)
- 加快排序速度(ORDER BY)
- 加快分组速度(GROUP BY)
虽然加快排序、加快分组最终还是体现在加快查询速度上,但能主动意识到这一点算是一种突破。只有当你意识到索引能加快排序和分组,你才会在写ORDER BY和GROUP BY时有意识地利用索引分组和排序(最左匹配原则),从而写出更优的SQL。
索引的劣势:
- 创建索引是需要付出代价的,主要体现在维护成本、空间成本和回表成本。也就是说索引能提高查询效率,但往往会降低增删改的速度(字典新增几百个字,需要额外编排目录吧,要多占几页纸吧)
- 如果使用了联合索引,还需要考虑索引失效问题(下篇介绍联合索引)
- 太多的索引会增加查询优化器的选择时间(选择太多也麻烦)
建索引的原则
很多人觉得SQL优化才是重中之重,创建索引只需要一行代码即可,没什么大不了的。但现在你已经知道了索引的优势与劣势,你会明白“在合适的时候、合适的字段建立索引”是多么空泛的口号。创建索引的判断依据究竟是什么呢?
创建索引有4个大原则:
- 索引并不是越多越好,联合索引应该优于多个单列索引
- 索引应该建立在区分度高的字段上
- 尽量给查询频繁的字段创建索引,避免为修改频繁的字段创建索引
- 避免重复索引
第一个原则背后的原因是,实际上数据库一次查询只会选择一棵索引树(不包括回表),更专业的说法是每次查询只会选择一个执行计划。即使你给a,b,c,d,e,f,g...所有列都加了索引,SELECT xx, xxx FROM table WHERE ...时,数据库也只会择优选择一个执行计划进行查询。
需要注意的是,每建一个索引,就需要维护一棵索引树,所以索引绝对不是越多越好,不合适的索引会增加数据库的负担。比如,你已经搞了一个根据拼音查找汉字的目录,又想根据偏旁部首来,那没辙了,只能劳烦您自己再搞一个目录了。
看到这,你可能会反问:我靠,那MySQL也太笨了吧,为什么这么死心眼一次只利用一个索引?
比较粗浅的理由是:你根据拼音查完汉字以后,还会根据偏旁部首再查一遍吗?
比较正经的理由是:按我个人的理解,索引本身的出发点是“走完一遍索引后,数据库应该返回精确的结果或很小的结果集”,从成本上考虑,此时再走一遍索引还不如直接遍历结果集来得快。当然,要想一次索引就得到精确的结果集,着实需要下一番苦功夫。给哪个字段加索引好呢?我建议,应该尽可能给区分度高的字段添加索引。
什么是区分度很高?这就是建索引的第二个原则啦。比如,表中有100w学生数据,你如果在sex列加索引,那么根据sex大概只能过滤掉50w数据,剩下的结果集仍然很大,说明这个索引建得不太合适,区分度太低了。
第三个原则就是字面意思。比如一本字典根据内容编好目录以后,隔三差五地就有新词汇要往里面加,或者经常要修改汉字读音,一顿操作后必然要连累目录,只能重新编排啦。也就是说,为了保证目录能正确指向对应的汉字,每次增删改后都要额外多一个操作:重新修订目录。
总之要意识到索引在加快查询的同时几乎必然会对修改产生负担,所以创建索引并没有那么简单,它绝对是一门“平衡的艺术”。
第四个原则是,比如已经建立a索引,又建立index(a,b,c)联合索引,此时单列索引a就是冗余的,因为联合索引已经可以保证符合条件时会利用a索引。在物理存储上,a单列索引和index(a, b, c)是两个独立的B+树,重复的索引会增加维护成本。
以上四个原则,后面的内容还会重新提到。
MySQL常用引擎
MySQL的引擎有很多种,但最常听到的就MyISAM和InnoDB,而实际开发几乎99%选择使用InnoDB,而且MySQL5.6还是哪个版本以后默认引擎就从MyISAM变成了InnoDB,所以这里着重介绍InnoDB,简略介绍MyISAM。

这里主要想和大家讨论MyISAM和InnoDB在索引组织上的区别。大家应该都已经知道,MyISAM和InnoDB存储数据的方式是不同的。
MyISAM的每张表在存储时会分为3个文件:
- 表结构
- 表数据
- 索引
也就是说,表数据和索引是分别独立存储的。
而InnoDB的表数据在存储时只分为2个文件:
- 表结构
- 表数据+索引
需要注意的是,InnoDB所有表的数据和索引都在同一个文件里(见下一个小节)。
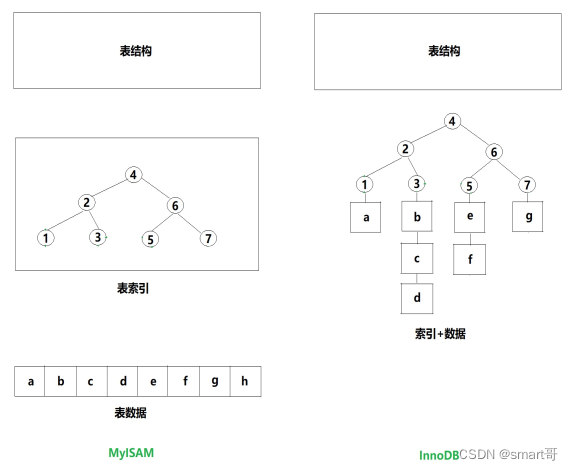
聚簇索引与非聚簇索引
对于BTREE索引而言,从数据的组织形式来看,索引又可以分为两大类:
- 聚簇索引
- 非聚簇索引
所谓聚簇索引,可以简单理解为索引和数据是“聚合”在一起的,而非聚簇索引的数据和索引是分开的。
根据InnoDB引擎的主键索引查询时无需回表,每一行完整的数据都直接挂在叶子节点下,可以直接返回。也就是说,对于InnoDB的主键索引而言,数据即索引,索引即数据。

MyISAM不是很重要,不提了。
InnoDB的索引也并不是都不需要回表,根据是否需要回表其实可以分为两类:主键索引、辅助索引(或者叫二级索引、普通索引)。
会什么要做这种区分呢?
假设一个场景:
新建一张表后,自然会产生主键索引。但后期发现name字段查询很频繁,于是加了name索引。
如果name索引也和主键索引一样挂着数据,那么两个索引数据就会重复。想象一下,现在磁盘中有一颗叫name的树和一棵叫id的树,一个以name为节点,一个以id为节点,相同的是最底层叶子节点都挂着完整的表数据。也就是说,磁盘中存了两份一模一样的student数据。且不说数据冗余,更新时还可能产生数据不一致(要同步数据,确保多张表的数据一致性)。
所以InnoDB的做法是,辅助索引只存储索引列+主键,必要时进行“回表”操作:
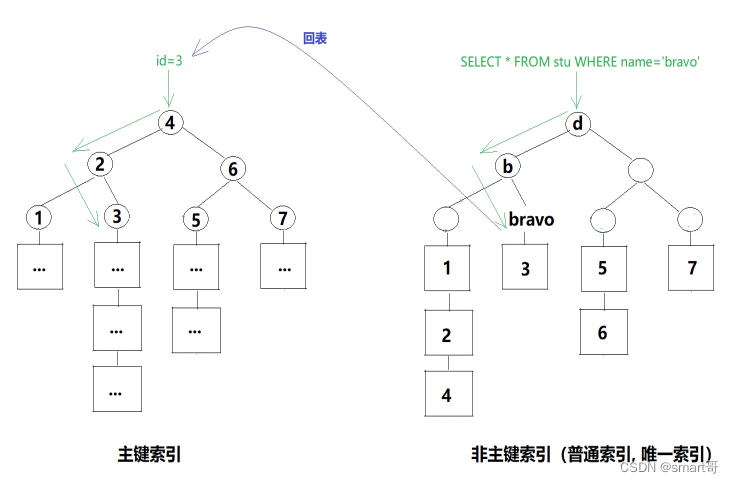
由于SELECT * FROM stu WHERE name='bravo'中,查询的数据是*,也就是整行数据。而上面的辅助索引只存了主键+name,所以必须回表:拿着主键再去跑一遍主键索引,最终返回整行数据。
现在,我们可以给MyISAM和InnoDB的索引分类做个简单的总结:
- MyISAM:非聚簇索引,需要回表
- InnoDB:
-
- 聚簇索引:主键索引,叶子节点是表数据,不需要回表
- 非聚簇索引:辅助索引(唯一索引、普通索引),叶子节点是主键,必要时需要根据主键回表查询

InnoDB每张表只能有一个主键索引,辅助索引则可以有多个。表数据只有一份,挂在主键索引下面。
需要注意的是,如有可能,应该尽量避免回表。SQL优化的本质其实就是减少/减小磁盘IO,而回表必然会增加磁盘IO次数。
举个例子,假设某张表总共就两棵索引树:主键索引+name辅助索引,两棵树高度都是3。由于只有主键索引下才挂着表数据,所以对于SELECT * FROM table WHERE name='xxx'来说,需要先走辅助索引取得id,再根据id走一遍主键索引。假设两棵树需要的数据都在第三层,那么这条SQL需要进行6次逻辑IO访问。而如果直接根据id查询,就可以直接走主键索引,IO次数为3。
所以,通常情况下辅助索引查询都是需要回表的,比主键索引查询多扫描一棵索引树(自身+主键索引),实际编写SQL时,应该尽量走主键索引。
那么,什么情况下辅助索引可以避免回表吗?
索引覆盖
索引覆盖这个名字,咋一听不知所云,所以很多初学者一直搞不明白什么意思,其实它最大的作用就是:避免回表。
下面通过一个案例来说明。
假设有个需求:前端需要支持根据用户名搜索订单,而页面需要的字段如下。
| id | productName | price | userName | userAge |
| 1 | iphone12 | 5999 | bravo1988 | 18 |
一个可行的方案是:
- 在t_user表中根据name搜索用户,得到user_id、user_name、user_age
- 在t_order表中根据user_id查询订单
- 在内存中根据user_id匹配order和user数据后返回
由于t_user表此时的查询条件是user_name,为了加快t_user表的查询速度,可以给user_name加普通索引。但,这样真的好吗?我劝!不要犯这样的聪明,小聪明啊。
你要知道,此时我们从t_user表查询的可不止user_name,还有user_age和id。如果只是给user_name加了索引,那么此时磁盘中产生的索引树是这样的:

这棵树的非叶子节点是user_name,叶子节点是id,也就是说从这棵树上我们只能得到user_name和user_id,至于user_age,MySQL底层只能跳出name索引树,然后跑到隔壁主键索引获取。整个过程被称为回表,而回表意味着多跑一趟。
此时我们可以给user_name和user_age加一个联合索引,这样就能产生所谓的“索引覆盖”:

当辅助索引上的字段完全满足本次查询的列时,就是所谓的索引覆盖,这是一个好消息,意味着不需要回表,查询效率将会大大提高。这也是为什么SQL优化原则中经常会强调:尽量只取必要的字段,避免SELECT *(提高索引覆盖的几率,查询的字段越多,几率越低)。
即使目前表中只有两个字段且已经索引覆盖,也不要写SELECT *。因为后期随着业务扩展,这张表会新增其他字段,此时SELECT *将不再覆盖索引!
为了方便记忆,大家可以把索引覆盖理解为 索引的字段 >= 查询需要的字段。比如联合索引的字段是index(a,b,c),那么此时查询a/b/c/id任意组合字段都会发生索引覆盖,索引覆盖最大的好处是避免回表。
需要强调的是,覆盖索引和联合索引没有必然关系。比如我只给user_name加单索引,而我查询语句是
SELECT id, user_name FROM t_user WHERE name='bravo';
此时也是索引覆盖。所以,能否索引覆盖不取决于索引单方面,需要查询配合。
关于联合索引,我们放在下一篇介绍。
重点总结
今天我们学习了索引的几种分类、索引的好与坏、创建的索引的几个原则,还介绍了聚簇索引和非聚簇索引,由此引出了回表的概念。而回表会产生额外的IO,为了提高效率我们又学习了“索引覆盖”。希望通过这篇文章,能让大家对索引有个大致印象。
但索引最难的部分还未到来,下一篇我们一起来学习联合索引,这是非常重要的一块知识点,由它引出的问题多不胜数,比如索引失效、最左匹配原则、ORDER BY排序失效等等。
作者简介:大家好,我是smart哥,前中兴通讯、美团架构师,现某互联网公司CTO
进群,大家一起学习,一起进步,一起对抗互联网寒冬
?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!