十:爬虫-多线程
一:进程与线程
1.什么是进程?
电脑中时会有很多单独运行的程序,每个程序有一个独立的进程
而进程之间是相互独立存在的,比如下标中的QQ播放器、小鹅通等等
2.什么是线程?
进程可以简单的理解为一个可以独立运行的程序单位,它是线程的集合,进程就是有一个或多个线程构成的。
而线程是进程中的实际运行单位,是操作系统进行运算调度的最小单位。
可理解为线程是进程中的一个最小运行单元。
3.什么是多进程?
同理,多进程就是指计算机同时执行多个进程,一般是同时运行多个软件
4.什么是多线程?
提到多线程这里要说两个概念,就是串行和并行搞清楚这个,我们才能更好地理解多线程:
串行:
所谓串行,其实是相对于单条线程来执行多个任务来说的,
我们就拿下载文件来举个例子:当我们下载多个文件时,在串行中它是按照一定的顺序去进行下载的,
也就是说,必须等下载完A之后才能开始下载B,它们在时间上是不可能发生重叠的。
并行:
下载多个文件,开启多条线程,多个文件同时进行下载,
这里是严格意义上的,在同一时刻发生的,并行在时间上是重叠的。
#简单了解了这两个概念之后,我们再来说说到底什么什么是多线程?
举个例子,我们打开腾讯管家,腾讯管家本身就是一个程序,也就是说它就是一个进程,它里面有很多的功能,我们可以看下图,能查杀病毒、清理垃圾、电脑加速等众多功能。
按照单线程来说,无论你想要清理垃圾、还是病毒查杀,那么你必须先做完其中的一件事,才能做下一件事,这里面是有一个执行顺序的。
如果是多线程的话,我们其实在清理垃圾的时候,还可以进行查杀病毒、电脑加速等等其他的操作,这个是严格意义上的同一时刻发生的,没有执行上的先后顺序。
简单理解为:多线程就是指一个进程中同时有多个线程正在执行。
二:多线程爬虫
由于外部网络不稳定,在使用单线程爬取网页数据时,如果有一个网页响应速度慢或者卡住了,那整个程序都要等待下去,这显然是无效率的。因此,我们可以使用多线程、多进程、协程技术来实现并发下载网页。
那么,在Python中多线程、多进程和协程应该如何选择呢?
一般来说,多进程适用于CPU密集型的代码,例如各种循环处理、大量的密集并行计算等。多线程适用于I/O密集型的代码,例如文件处理、网络交互等。协程无需通过操作系统调度,没有进程、线程之间的切换和创建等开销,适用于大量不需要CPU的操作,例如网络I/O等。
实际上,限制爬虫程序发展的瓶颈就在于网络I/O,原因是网络I/O的速度赶不上CPU的处理速度。结合多线程、多进程和协程的特点和用途,我们一般采用多线程和协程技术来实现爬虫程序。
1.多任务基本介绍
有很多的场景中的事情是同时进行的,如开车的时候 手和脚共同来驾驶汽车,再比如唱歌跳舞也是同时进行的
程序中模拟多任务:
import time
def sing():
for i in range(3):
print("正在唱歌... %d"%i)
time.sleep(1)
def dance():
for i in range(3):
print("正在跳舞...%d"%i)
time.sleep(1)
if __name__ == '__main__':
sing()
dance()
2.多线程的创建
(1)通过函数来创建
1 通过函数来创建
通过threading模块当中的一个Thread类,有一个target参数。这个参数需要我们传递一个函数对象。这个函数就可以实现多线程的逻辑
def Demo01():
print('hello 子线程')
if __name__ == "__main__":
for i in range(5):
t = threading.Thread(target=Demo01)
time.sleep(1)
t.start()
(2)通过类来创建
2 通过类来创建
自定义一个类,需要继承父类 threading.Thread 并重写run()方法
class Demo02(threading.Thread):
def run(self) -> None:
for i in range(5):
print("hello 子线程")
if __name__ == "__main__":
d = Demo02()
d.start()
3.主线程和子线程的执行关系
- 主线程会等待子线程结束之后在结束
join()等待子线程结束之后,主线程继续执行setDaemon()守护线程,不会等待子线程结束
3 主线程和子线程的执行关系
主线程会等子线程结束之后再结束!考试例子画图
打印的结果有很多种 可以来猜一猜?
def Demo01():
for i in range(5):
print('hello 子线程')
time.sleep(1)
if __name__ == "__main__":
t = threading.Thread(target=Demo01)
t.setDaemon(True) # 守护线程,不会等待子线程结束
t.start()
# 第一种sleep(5秒)
# t.join() # 等待子线程结束之后,主线程继续执行
print(123)
(1)查看线程数量
threading.enumerate():查看当前线程的数量
# 查看线程数量会用到enumerate()方法 enumerate() 函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中
# name = ["嘟嘟1", '嘟嘟2', '嘟嘟3']
# for index, i in enumerate(name):
# print(index, i)
import threading
import time
def demo1():
for i in range(5):
print(f"demo1---{i}")
time.sleep(1)
def demo2():
for i in range(10): # 作为区别将5改成10
print(f"demo2---{i}")
time.sleep(1)
def main():
t1 = threading.Thread(target=demo1)
t2 = threading.Thread(target=demo2)
t1.start()
t2.start()
# print(threading.enumerate()) # 线程是存活的
while True:
print(threading.enumerate())
if len(threading.enumerate()) <= 1:
break
time.sleep(1)
if __name__ == '__main__':
main()
(2)验证子线程的创建与执行
# 验证子线程的创建与执行
def demo3():
for i in range(5):
print(f"demo1---{i}")
time.sleep(1)
def main():
print(threading.enumerate())
t1 = threading.Thread(target=demo3) # 这里并没有创建线程
print(threading.enumerate())
t1.start() # 当我们的调用start方法之后才成功的创建了这个子线程
print(threading.enumerate())
if __name__ == '__main__':
main()
(3)线程中的资源竞争问题
# a = 20
# def fun1():
# # 希望在函数内部修改全局变量的值 那就需要使用到一个关键字 global
# global a
# a = 10
# print("函数内部:a = ", a)
# fun1()
# print('函数外部: a = ', a)
import threading
import time
# num = 100
# def demo1():
# global num
# num += 1
# print(f'demo1--num--{num}')
# def demo2():
# print(f'demo2--num--{num}')
# def main():
# t1 = threading.Thread(target=demo1)
# t2 = threading.Thread(target=demo2)
# t1.start()
# t2.start()
# print(f'main--num--{num}')
# if __name__ == '__main__':
# main()
import threading
import time
num = 0
def demo1(nums):
global num
for i in range(nums):
num += 1
print(f'demo1--num--{num}')
def demo2(nums):
global num
for i in range(nums):
num += 1
print(f'demo2--num--{num}')
def main():
t1 = threading.Thread(target=demo1, args=(1000000,))
t2 = threading.Thread(target=demo2, args=(1000000,))
t1.start()
t2.start()
time.sleep(1)
print(f'main--num--{num}')
if __name__ == '__main__':
main()
4.线程锁
当多个线程几乎同时修改某一个共享数据的时候,需要进行同步控制
某个线程要更改共享数据时,先将其锁定,此时资源的状态为"锁定",其他线程不能改变,只到该线程释放资源,将资源的状态变成"非锁定",其他的线程才能再次锁定该资源。互斥锁保证了每次只有一个线程进行写入操作,从而保证了多线程情况下数据的正确性。
创建锁
mutex = threading.Lock()
锁定
mutex.acquire()
解锁
mutex.release()
5.Queue线程
在线程中,访问一些全局变量,加锁是一个经常的过程。如果你是想把一些数据存储到某个队列中,那么Python内置了一个线程安全的模块叫做queue模块。Python中的queue模块中提供了同步的、线程安全的队列类,包括FIFO(先进先出)队列Queue,LIFO(后入先出)队列LifoQueue。这些队列都实现了锁原语(可以理解为原子操作,即要么不做,要么都做完),能够在多线程中直接使用。可以使用队列来实现线程间的同步
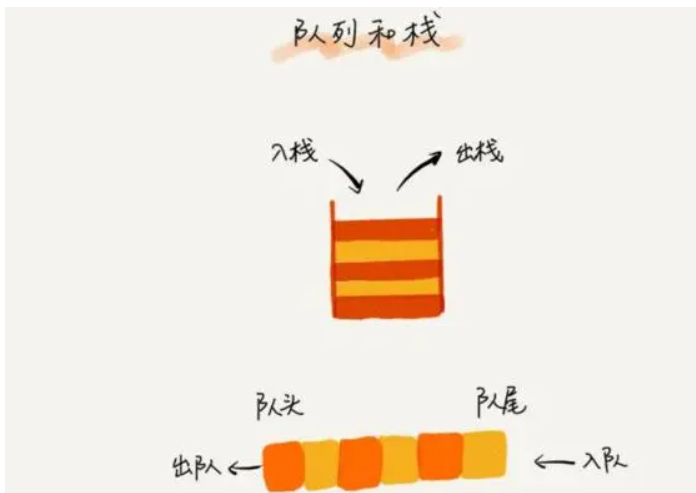
初始化Queue(maxsize):创建一个先进先出的队列。
empty():判断队列是否为空。
full():判断队列是否满了。
get():从队列中取最后一个数据。
put():将一个数据放到队列中。
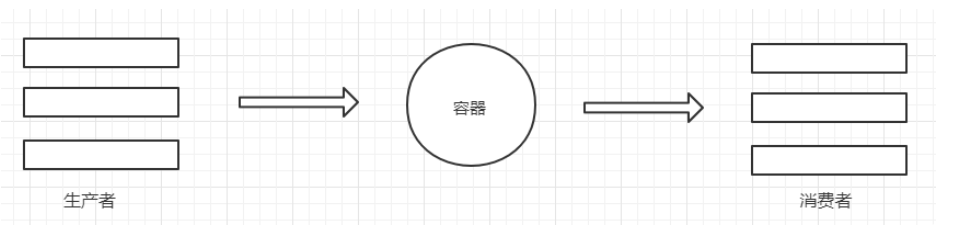
6.生产者与消费者模式
生产者和消费者模式是多线程开发中常见的一种模式。通过生产者和消费者模式,可以让代码达到高内聚低耦合的目标,线程管理更加方便,程序分工更加明确
生产者的线程专门用来生产一些数据,然后存放到容器中(中间变量)。消费者在从这个中间的容器中取出数据进行消费
使用单线程下载表情包:
import re
import requests
from urllib.request import urlretrieve
from lxml import etree
"""
将http://www.godoutu.com/face/hot/page/1.html下10页数据的表情包全部抓取
print(45*1801) 8w多条数据
图片数据 二进制
保存
with open wb模式
urllib
找到图片的路径 图片名字
"""
for i in range(1,2):
url = f'http://www.godoutu.com/face/hot/page/{i}.html'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36'
}
response = requests.get(url, headers=headers)
response.encoding = 'utf-8'
html = response.text
# print(html)
# xpath对象
element = etree.HTML(html)
alldiv = element.xpath('//div[@class="ui segment imghover"]/div[@class="tagbqppdiv"]')
# print(alldiv,len(alldiv))
for j in alldiv:
everyhref = j.xpath('./a/img/@data-original')[0]
# print(everyhref)
title = j.xpath('./a/@title')[0] # 必须要是合法的
# print(title)
newtitle = re.sub('[\/:*?<>|]','',title)
# print(type(newtitle),type(everyhref))
# 保存 jpg gif
if str(everyhref).endswith('jpg'):
urlretrieve(everyhref,f'images/{newtitle}.jpg')
print(f'{newtitle}.jpg下载成功!')
else:
urlretrieve(everyhref, f'images/{newtitle}.gif')
print(f'{newtitle}.gif下载成功!')
使用生产者与消费者模式下载表情包:
import threading
import time
import re
import requests
from lxml import etree
from queue import Queue
from urllib.request import urlretrieve
# 生产者模型
class Producer(threading.Thread):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.127 Safari/537.36'
}
def __init__(self, page_queue,img_queue ): # RuntimeError: thread.__init__() not called
# 在自写的类中的init中,先初始化Thread
threading.Thread.__init__(self) # 或则 super().__init__()
self.page_queue = page_queue
self.img_queue = img_queue
def run(self):
while True: # 让我们创建的三个生产者一直工作
if self.page_queue.empty():
break
else:
url = self.page_queue.get()
print(url)
# 获取到了url就可以去解析数据了
self.Parse_html(url)
def Parse_html(self,url):
# 上锁
lock.acquire()
# 发请求,获取响应
res = requests.get(url, headers=self.headers)
text = res.text
# 随机延迟
# time.sleep(random.random())
# 解析数据,拿真的图片地址
element = etree.HTML(text)
# 将获取的所有img标签放到列表里面
alldiv = element.xpath('//div[@class="ui segment imghover"]/div[@class="tagbqppdiv"]')
# 解锁
lock.release()
# 取出每一个图片的地址
for j in alldiv:
everyhref = j.xpath('./a/img/@data-original')[0]
print(everyhref)
title = j.xpath('./a/@title')[0] # 必须要是合法的
print(title)
newtitle = re.sub('[\/:*?<>|]', '', title)
# 将获取到的img_url和title数据存放在另一个队列种然后再交给消费者进行处理
self.img_queue.put((everyhref,newtitle)) # 用元组打包作为整体进行处理
# 检测我获取的数据量是否正确
print(self.img_queue.qsize())
# 消费者模型
class Consumer(threading.Thread):
def __init__(self, img_queue): # RuntimeError: thread.__init__() not called
# 在自写的类中的init中,先初始化Thread
threading.Thread.__init__(self) # 或则 super().__init__()
self.img_queue = img_queue
def run(self):
while True: # 让我们创建的三个生产者一直工作
if self.img_queue.empty():
break
else:
img_data = self.img_queue.get() # 元组类型数据
# 解包
img_url, filename = img_data
# 下载操作
if str(img_url).endswith('jpg'):
urlretrieve(img_url, f'imagesss/{filename}.jpg')
print(f'{filename}.jpg下载成功!')
else:
urlretrieve(img_url, f'imagesss/{filename}.gif')
print(f'{filename}.gif下载成功!')
# 程序主入口
if __name__ == '__main__':
# 创建一把锁
lock = threading.Lock()
# 1 将所有的url存放在队列中
page_queue = Queue() # 创建一个队列 然后通过put方法存放进去
# 创建一个存放数据的队列
img_queue = Queue() # 同样将这个队列通过init初始化传到生产者模型中
for i in range(1, 11):
url = f'http://www.godoutu.com/face/hot/page/{i}.html'
page_queue.put(url)
p_list = []
# 2 创建生产者对象 三个
for i in range(3):
t = Producer(page_queue,img_queue) # 将队列传给生产者处理 那再创建对象进行传参的过程中我们需要进行接收 init
t.start() # 开启多线程 执行的是run方法
p_list.append(t)
for p in p_list:
p.join()
# 创建三个消费者
for j in range(3):
t = Consumer(img_queue)
t.start()
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!