003 FeedForward前馈层
2023-12-13 13:57:15
一、环境
本文使用环境为:
- Windows10
- Python 3.9.17
- torch?1.13.1+cu117
- torchvision 0.14.1+cu117
二、前馈层原理
Transformer模型中的前馈层(Feed Forward Layer)是其关键组件之一,对于模型的性能起着重要作用。下面将用900字对Transformer的前馈层进行详细讲解。前馈层在网络中位置,如下图:
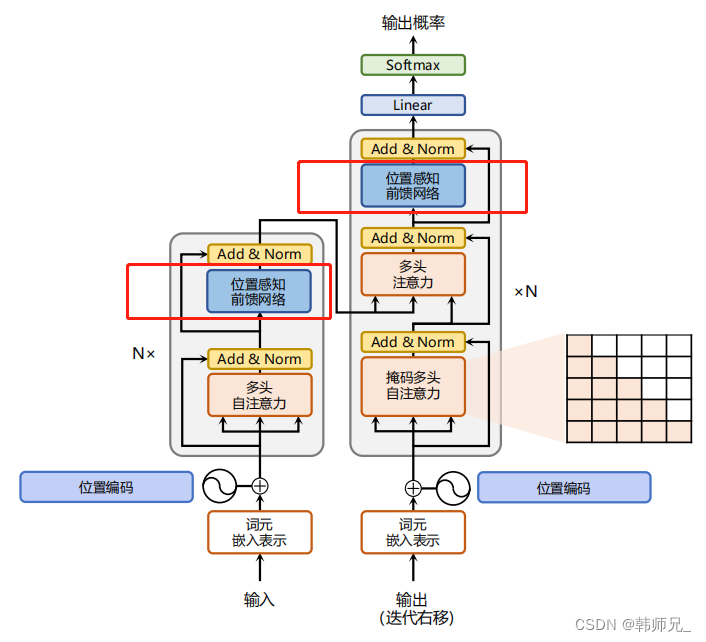
2.1 前馈层的基本概念
前馈层,又称为全连接层(Fully Connected Layer)或密集层(Dense Layer),是神经网络中最基础的组件之一。在Transformer模型中,前馈层通常出现在每一个Transformer编码器(Encoder)和解码器(Decoder)中的每一个自注意力(Self-Attention)层之后。
2.2 前馈层的结构
- 线性变换:前馈层的输入首先经过一个线性变换,将输入映射到一个高维空间。这个线性变换通常由一个权重矩阵和一个偏置向量实现。
- 激活函数:经过线性变换后,输入会通过一个激活函数,增加模型的非线性表达能力。常用的激活函数包括ReLU、Sigmoid、Tanh等。
- 线性变换与输出:经过激活函数后,再进行一次线性变换,将高维空间的特征映射回原始空间,得到前馈层的输出。
2.3 前馈层的作用
- 特征提取:前馈层通过线性变换和激活函数,可以提取输入数据的复杂特征,有助于模型更好地理解数据。
- 增加模型复杂度:通过增加前馈层的隐藏单元数量,可以增加模型的复杂度,提高模型的表达能力。
- 缓解梯度消失问题:在深度神经网络中,梯度消失是一个常见的问题。前馈层中的激活函数可以缓解这个问题,使得模型能够更好地训练。
三、完整代码
前馈层接受自注意力子层的输出作为输入,并通过一个带有 Relu 激活函数的两层全连接网络对输入进行更加复杂的非线性变换。实验证明,这一非线性变换会对模型最终的性能产生十分重要的影响。
![]()
其中 W1, b1,W2, b2 表示前馈子层的参数。实验结果表明,增大前馈子层隐状态的维度有利于提
升最终翻译结果的质量,因此,前馈子层隐状态的维度一般比自注意力子层要大。使用 Pytorch 实现的前馈层参考代码如下:
import torch.nn as nn
import torch.nn.functional as F
import torch
class FeedForward(nn.Module):
def __init__(self, d_model, d_ff=2048, dropout = 0.1):
super().__init__()
# d_ff 默认设置为 2048
self.linear_1 = nn.Linear(d_model, d_ff)
self.dropout = nn.Dropout(dropout)
self.linear_2 = nn.Linear(d_ff, d_model)
def forward(self, x):
x = self.dropout(F.relu(self.linear_1(x)))
x = self.linear_2(x)
return x
batch_size = 32
seq_len = 64
d_model = 512
ff = FeedForward(d_model=d_model)
x = torch.randn(batch_size, seq_len, d_model) # 32 x 64 x 512
ff.eval()
print(ff(x).shape) # torch.Size([32, 64, 512])
文章来源:https://blog.csdn.net/m0_72734364/article/details/134968678
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!